Playwright CLI × Claude Code 自动化测试实战
本项目源于团队在日常 Web 业务测试中遇到的痛点:随着核心业务流程(如项目立项、OA 审批提交等)日益复杂,人工回归测试成本急剧上升,覆盖率难以保证。为此,我们探索引入 playwright-cli 工具,结合 AI Agent 能力,将自然语言测试意图自动转化为可执行的浏览器自动化脚本,从而沉淀测试资产、降低回归成本、提升整体测试效率。
基于真实项目,我们在每天都要面临以下诸多场景:
-
• 项目立项流程:需要手动填写立项信息、逐步点击提交,涉及多个页面跳转,人工回归一次耗时 5~10 分钟。
-
• OA 审批提交:在上一步基础上还要登录 OA 页面,完成流程干预,提交通过等多个步骤,每次版本迭代后都需要重复执行,测试成本高。
-
• 权限验证测试:不同角色用户登录后页面访问控制差异化验证,需要来回切换账号执行,重复劳动量大。
以上场景均具备“步骤固定、可重复、需频繁执行”的特点,是自动化测试的理想切入点。
随着 AI 辅助编程能力的成熟,我们尝试将 AI Agent 引入测试工作流:测试人员不再需要手写操作代码,而是用自然语言描述测试意图,由 AI 调用 playwright-cli 完成实际浏览器操作、输出测试报告。这将测试人员从"执行者"升级为"设计者",显著提升单人覆盖的测试场景数与回归效率。
什么是 Playwright-CLI?
Playwright-CLI 是 Microsoft 基于 Playwright 推出的命令行浏览器自动化工具,专为 AI 编程助手(如 Claude Code、GitHub Copilot)设计。它将 Playwright 的浏览器控制能力封装为一组可在终端直接调用的命令--open、goto、click、fill、snapshot、screenshot、run-code 等,核心特点是 token 高效:每条命令返回精简的 YAML 页面快照(含元素 ref 引用),而非将整个页面 DOM 塞入模型上下文,大幅降低 AI Agent 的推理成本。
这也是本方案的技术基础:让 AI Agent 通过 playwright-cli 操控浏览器,形成一套从探索到自动化的闭环能力。
设计路径
如果想直接了解使用方式,请跳转到操作步骤章节。
完整的架构并非一开始就设计好的,而是从真实的使用中一步步迭代出来的。每个阶段都有具体的痛点在驱动,每个解决方案都来自真实踏平的坑。所以不同于别的教程,在正式介绍这个自动化测试功能前,本文会先以一个测试小白的真实视角,按以下按阶段复盘整个演进过程。

第一阶段:初识 playwright-cli,手动跑第一个用例
开始时我甚至不知道 playwright-cli 是什么。看到它可以通过命令行控制浏览器后,第一反应是"这不就是一个可以被 AI 调用的浏览器工具吗",十年前咱们也写过浏览器的自动化能有什么不同。于是在 Claude Code 里手写了第一条甚至有点不太完整的指令:导航到 DPMS 首页,登录,关闭指引反馈弹框,看看能不能点到。
AI Agent(Opus 4.6)就这样直接开始执行了:通过 Playwright 开启浏览器、goto 登录页、自动 fill 输入账号密码、click 登录按鈕。不到 30 秒登录成功。再获取一份 snapshot,找到反馈关闭按鈕的 ref,点击,成功关闭了反馈窗口。最终跑通了。
整个过程让我有点恍惚--虽然执行速度慢了点(每一步后 AI 都会卡),但我没有告诉它页面结构、元素定位,甚至连按钮在哪都没说清楚,它却像“理解了意图”一样把流程走通了。于是我欣喜若狂,我立马就想把我们的核心业务流用它全部建立起来。
冷静思索发现,刚才的执行其实是"一次性的":没有任何步骤被沉淀、没有脚本被保存。如果下次还要复现同样的流程,一切都要从头再来。这也引出了第一个真正的问题:测试资产无法沉淀。
第二阶段:尝试把执行过程整理成文件--第一个用例 。md 诞生
第一次跑通之后,我开始思考如何将这些步骤保存下来。最直观的想法是写一个 markdown 文件,把每一步用到的命令写进去 -- 用 markdown 这种对人和 AI 都比较友好的格式(用轻量标记提供清晰层次,纯文本编辑跨平台无障碍,还能标准化指令减少歧义),后续可以直接作为上下文继续让 AI 接着执行。
于是手动将第一个用例整理成 tests/01-login-feedback.md,里面按顺序写下了:当前是什么用例、有什么前置配置(比如平台地址、登录账号、密码)、每步用什么命令、期望验证什么。第一版 。md 非常粗糙,毕竟不知道标准是什么。
随后尝试让 AI Agent 直接读取这个 。md 文件并重新执行。难受的问题出现了:
Agent 开始自由发挥,把 。md 里写的步骤当做"参考"而不是"指令",帧带加进去了一堆额外的 snapshot 、额外的 grep 、甚至重写了命令。结果是每次执行路径不一致、Tool 调用次数暴增。这就好比,软件工程里的需求蔓延问题,我的需求在层层传递过程中被层层扭曲了(可能我的需求描述都有问题,这也是很常见的)。那么我的需求越复杂,可能导致最后的偏差就越大。
这是第二个痛点:文档只是"建议",不是"契约" -- Agent 自由发挥导致执行路径不可控(可重复)、成本不可预测(效率)、结果不可信(真实性)。
第三阶段:加入强制约束,用例开始可靠重复执行
问题的根源在于:Agent 对 。md 文件没有"严格执行"的核心约束。于是在 。md 用例文件中加入了一段强制约束 (CRITICAL RULES) 规则,明确写出一系列严格禁止行为:
每一项都来自真实踩过的坑。以 01-login-feedback.md 为例,当时加入的规则包含:
-
• 不要对 。yml 快照文件使用 Read 工具(用 Grep 更快,Read 浪费 Token 导致成本翻倍)
-
• close 后立刻停止,不要再拓展任何操作(测试任务已完成,继续操作纯属多余)
-
• 不要使用 waitForTimeout,用 waitForURL 或 waitForSelector(固定延时不可靠,事件等待更精确否则网络波动失败率 30%+)
-
• .md 里已写的命令一字不改直接执行,不要重写或内联(已验证命令路径改动=路径漂移,每次重新验证)
-
• 不要自起名目进行 ls / find / glob 文件系统探索(用例已说明位置,无关遍历让 Tool 调用暴增 5 倍+)
加入这些规则后,测试执行变得非常干净:Agent 从上到下读 。md 命令、原样执行、检查 URL 包含关键字即 PASS(登录成功)、关闭浏览器结束。Tool 调用次数从 20+降到 9 次。
这个解决思路很快被复制到了其他用例,tests/02-navigate-myproject.md 和 tests/03-sidebar-toggle.md 也如此完成,每个用例自带一个 CRITICAL RULES 块,并针对自身场景最容易踩的坑做了补充说明。比如 03-sidebar-toggle.md 里则写明:"切换按钮是图片元素,需用 force: true 点击"。
第四阶段:用例变复杂,Batch 分组与前置依赖
前三个用例都是单系统、单页面的简单场景用来验证当前技术路线是否可行。真正的挑战来自第四个用例:04-pre-project-initiation.md--DPMS 项目立项全流程,几十个步骤,跨两个系统(DPMS + OA)。
第一个困境来得很快:把全部命令在一个 Bash 块里跑,Agent 一旦某个步骤失败,整个链就断了,且无法居中定位到具体哪一步出的问题。于是实验将命令按语义分组:将导航、填写项目表单基本信息分为 Batch 1,完成项目计划、TB iframe 新增任务分为 Batch 2,提交验证为 Batch 3。这样假如任意 Batch 失败,范围就很明确。
第二个困境来自 OA 审批流程:测试需要先在 DPMS 创建立项,再切到 OA 系统(SSO 登录)完成审批,最后再回 DPMS 验证结果。两个系统间需要传递一个关键数据:当前测试的项目名称。这个问题先促生了 localStorage 方案:在 DPMS 创建项目时把项目名写入 localStorage.TESTPROJECTNAME,OA 侧脚本再读取这个值用于搜索审批单。
并且我很快意识到,这段「在 OA 中完成审批」的流程和登录一样,是后面许多用例都会反复使用的公共步骤。如果把这整段逻辑写死在每个用例里,一旦流程变动,就要在一堆 。md 里逐个修改,出错概率极高。于是把这部分从主用例里抽离出来,重写成一个独立的前置依赖文件:00-oa-approve-prerequisite.md 和 00-login-feedback.md--它们可以既负责跨系统的数据传递,也以一个可复用模块的形式存在,后续任何用例只要声明依赖它,就等于"插入" 同一段流程,维护和复用都简单很多。
第三个困境来自复杂 JS 和 Windows 编码问题:iframe 内的任务操作、下拉选择等复杂 JS 逻辑如果直接内联写入 run-code,在 Windows 上会报 SyntaxError: Invalid or unexpected token。解决方法是把这些逻辑抽离到 scripts/ 目录下的独立 。js 文件中,用例里只保留一行:run-code cat scripts/04-step2-basic-info.js--既规避编码问题,也顺便把前端操作脚本模块化。
就这样,该用例在反复调试后最终形成了现在的 5 个 Batch 结构,再配上独立的 login 和 OA 的 。md + scripts 目录下多份 JS 脚本,用例本身只保留“业务流程骨架”,具体的通用步骤和复杂逻辑都下沉到可复用的模块里。
第五阶段:创建用例的经验沉淀--Skill 1 诞生
经过前四个阶段的摸索,我们已经积累了一套完整的用例编写方法论:markdown 格式存储、CRITICAL RULES 约束 agent 行为、Batch 分组链式执行、前置依赖抽离复用、复杂 JS 外置到 scripts/ 目录。但这些经验全部停留在我的脑子里--每次新增测试场景,都要从零开始手动走一遍「开浏览器 → 探索页面 → 记录 ref → 编写 。md → 调试验证」的流程,效率不高且标准不一致。
这个痛点驱动了 Skill 1(adding-playwright-cli-tests)的诞生。核心思路是:把前四个阶段踩过的所有坑和总结出的最佳实践,全部固化为一个 Claude Code Skill--当测试人员输入添加测试场景:xxx 时,Skill 1 自动激活,引导 AI Agent 完成标准化流程。
有了 Skill 1 之后,新增一个测试场景的时间从半天手动摸索缩短到十几分钟自动生成 + 验证,且生成的用例质量一致、格式统一,为后续 Skill 2 的并发执行奠定了基础。
第六阶段:用例多了,执行需标准化
当用例积累到 4 个( 01~04)后,新的问题出现了:每次回归测试都需要手动指定"先跑哪个、分配哪个 session、要加前置还是直接跑"。最关键的是每次几个用例的执行顺序和测试报告指标也不一致。
这个痛点驱动了 Skill 2 的诞生。核心设计决策是:用 haiku 模型而非主 agent 直接执行,为每个用例启动一个独立的子 agent 并行运行。理由有两点:一是 haiku 成本远低于 sonnet/opus,适合大量重复执行;二是复杂用例不适合在一个 agent 里串行塞太多流程,否则子 agent 内部的多步操作会直接拖垮主 agent 的调度层。
Skill 2 的执行模式定下来之后,每次回归只需输入「执行所有用例」(你可以进一步按场景归类),Skill 2 自动为 所有用例分配 session、逐一启动 haiku 子 agent、并行跑完、最终按照固定的标准输出每个用例的 PASS/FAIL 和 Tool/Token/耗时指标。回归效率起到质的几个跳跃。
第七阶段:指标暴露了新问题-- 自动优化循环应运而生
Skill 2 带来的副产品是:每次执行结束后都有准确的指标。就是在这些数据里,发现了问题:04-pre-project-initiation.md 的首次跑通 Tool、Token、耗时 -- 全部超标。
当时的第一反应是去看执行日志、一条一条检查命令。发现问题高度重复:写了过多 snapshot、用了 waitForTimeout、Bash 命令没有批量化、登录 ref 由于已知稳定(固化布局)但还是每次跟着 grep 一遍。每次修改后需要重新跑一遍验证,要回归 3~4 轮才收敛。
这个重复劳动直接驱动了 Skill 3 的设计:让 Agent 帮我做这件事。核心设计是写一个 parse-agent-log.py 脚本,分析 Claude Code 就如 jsonl 日志文件,从中提取 Tool 调用次数、Token 消耗、各步耗时,再由 Agent 对比阈值、定位问题、生成优化方案。
以 04 用例为例,第一轮 Skill 3 分析后给出了 4 条优化建议,我一条条确认并应用。Skill 3 随即重新跑 04 验证。就这样迭代 4 轮,指标平均降低 30%+。通过这种自优化流程,测试用例会越跑越顺畅,最终趋向一个稳定的快速过程。

至此,三个 Skill 全部就位,架构正式形成闭环。从一个小白手动跑第一条命令,到现在这一套「创建 → 执行 → 自动优化」的全自动化架构,总共经历了六个阶段、踏平了十多个具体的坑。
与传统方案的对比
本方案并非替换 Playwright,而是将 playwright-cli 作为执行层,AI Agent 作为调度层,将写代码这一门槛降至最低。测试人员只需关心测什么,而非怎么写。
|
维度 |
传统 Playwright(.spec.ts) |
Playwright MCP |
本方案(playwright-cli + Skill) |
|
本质 |
开发者手写自动化测试代码 |
AI 通过 MCP 协议实时操控浏览器 |
AI 按预定义的 .md 脚本批量执行 |
|
编写门槛 |
需要 JS/TS 编程能力 |
无需编码,自然语言即可 |
无需编码,自然语言即可 |
|
用例格式 |
.spec.ts 代码文件 |
无持久化用例,每次对话即用即走 |
.md Markdown 文档,人机双可读 |
|
执行一致性 |
高(代码固定) |
低(每次 AI 自由推理,路径可能不同) |
高(CRITICAL RULES 约束,命令原样执行) |
|
执行成本 |
固定(CI 资源) |
高(每一步都是一次 LLM 推理) |
低(haiku 批量执行,token 可量化优化) |
|
资产沉淀 |
代码即资产,可版本管理 |
无沉淀,对话结束即丢失 |
.md + .js 文件沉淀,可版本管理、跨团队复用 |
|
可重复性 |
完全可重复 |
不可重复(AI 每次可能走不同路径) |
完全可重复(命令原样执行) |
|
自优化能力 |
无,需人工 review |
无 |
有,Skill 3 自动分析日志并生成优化建议 |
|
跨系统能力 |
需手动编排多个 spec |
支持,但需每次重新描述 |
天然支持多 Tab、多系统、localStorage 传参 |
|
维护成本 |
元素变化需改代码 |
无需维护(也无法维护) |
Agent 自动适配 + snapshot 重定位 |
|
适用场景 |
有专职自动化测试工程师的团队 |
一次性探索、临时验证、快速原型 |
需要长期回归的核心业务流程 |
市面上与浏览器自动化测试相关的方案主要有三类:传统 Playwright 代码级测试、Playwright MCP(通过 Model Context Protocol 让 AI 直接操控浏览器)、以及本方案。三者的定位和适用场景有本质区别。
三者关系的核心理解:
-
• Playwright MCP 的优势在于零门槛即时探索--你说一句话,AI 立刻操控浏览器帮你看看。但它的致命问题是不可重复、不可沉淀、不可优化:每次执行都是 AI 的一次性自由发挥,路径不一致,成本不可控,执行完对话关闭就什么都没留下。适合临时性验证,不适合长期回归。
-
• 本方案 恰恰是为了解决 MCP 模式的这三个问题而设计的。它用 Skill 1 将探索过程固化为 。md 用例文件(沉淀),用 CRITICAL RULES 约束 agent 严格按脚本执行(可重复),用 Skill 3 持续分析优化(可优化)。同时用 haiku 模型替代 opus/sonnet 执行,单次成本降低 98%。
-
• 传统 Playwright 则是最稳定的方案,但门槛最高(需要编程),维护成本也最高(元素变化需改代码)。本方案的定位不是替换它,而是为不具备编程能力的测试团队提供一条同样可靠的路径。
技术方案概览
架构共分为五层,自上而下构成完整的自动化测试闭环,每一层都有明确的职责边界。下面逐层展开说明,并结合三个 Skill 的实际实现细节阐述各层的具体工作机制。
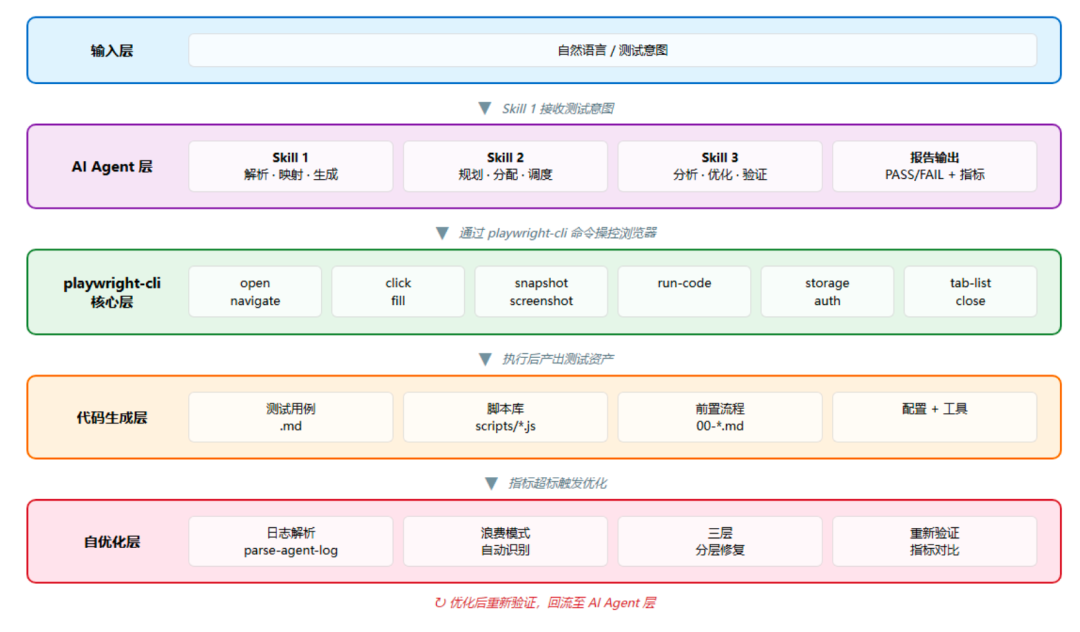
输入层:自然语言 / 测试意图
测试人员以自然语言作为输入,无需编写任何代码,是整个流程的起点。例如:
-
• 输入「添加测试场景:项目立项提交流程」→ 触发 Skill 1
-
• 输入「执行所有用例」或「跑 04 用例」→ 触发 Skill 2
-
• 输入「优化用例」或指标自动超标 → 触发 Skill 3
输入层的设计哲学是:测试人员只需关心测什么,而非怎么写或怎么跑。Claude Code 的 Skill 机制会根据输入的关键词自动识别并激活对应的 Skill,测试人员不需要记忆任何命令。
AI Agent 层:三个 Skill 协同调度
这是整个架构的核心调度层,由三个 Claude Code Skill 协同工作,每个 Skill 内部又包含多个子能力:
Skill 1(adding-playwright-cli-tests)-- 自然语言解析 + 意图映射 + 用例生成
接收测试人员的自然语言输入后,Skill 1 完成三项核心工作:
-
1. 自然语言解析:将「项目立项提交流程」这类描述拆解为具体的操作语义--需要登录、需要填写哪些表单字段、需要跨系统操作、最终验证什么状态。
-
2. 意图映射:将操作语义对应到具体的 playwright-cli 命令组合。例如「登录」映射为 goto → fill e13 → fill e15 → click e18 → waitForURL;「填写表单」映射为一系列 run-code "$(cat scripts/xxx.js)" 调用。
-
3. 用例生成:按照标准化模板生成 。md 文件,包含 session 声明、前置依赖引用、Batch 分组、CRITICAL RULES、预期结果验证点。同时将复杂 JS 逻辑抽离到 scripts/*。js 文件中,中文字符用 \uXXXX 转义避免 Windows 编码问题。
Skill 1 在生成用例前,会先用 playwright-cli open --headed 开启有头浏览器进行探索式操作:执行 snapshot 获取页面元素的 ref 值和 DOM 结构,通过 click、fill 等命令验证操作路径的可行性,最终将验证通过的命令序列沉淀到 。md 文件中。这确保了生成的用例生成的准确性且开箱即用。
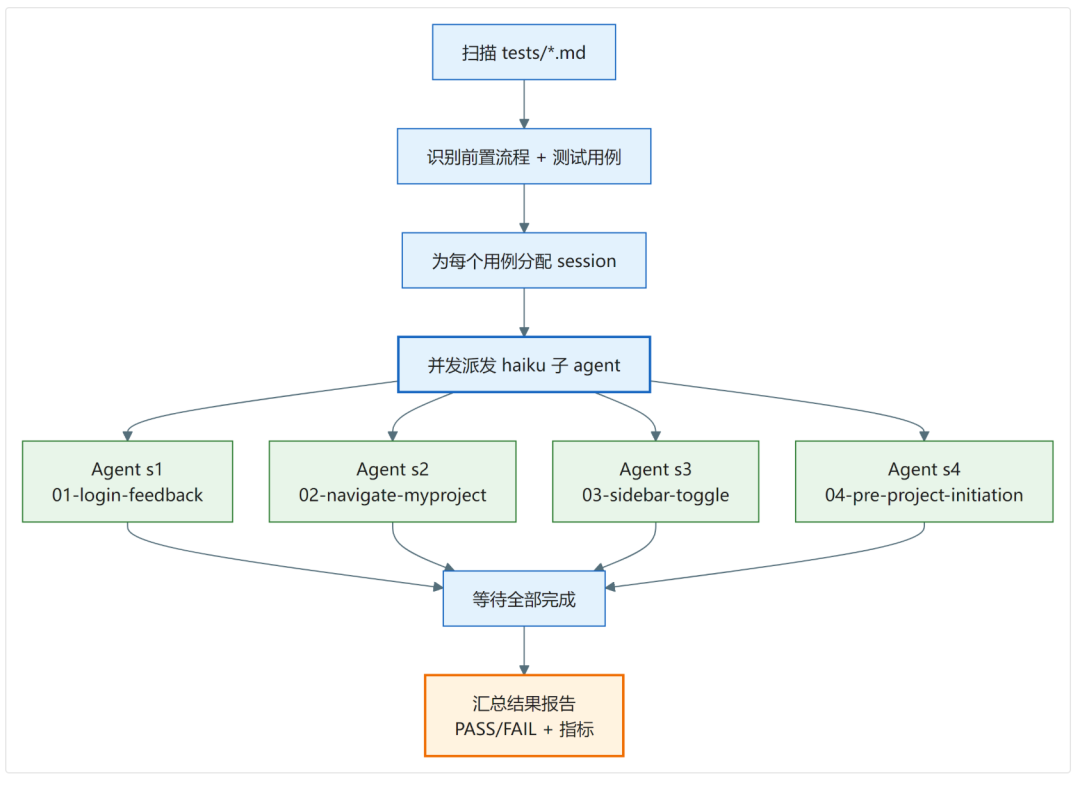
Skill 2(running-playwright-cli-tests)-- 步骤规划 + session 分配 + 并发调度
Skill 2 是执行调度的核心,其内部工作流程为:
-
1. 扫描识别:读取 tests/ 目录(或手动指定),将 00--prerequisite.md 识别为前置流程文件,将 01-。md、02-*.md 等识别为测试用例文件,忽略非测试文档。
-
2. session 分配:为每个测试用例分配独立的命名 session(01-xxx.md → s1,02-xxx.md → s2),确保多用例并发执行时浏览器实例互不干扰。
-
3. 并发派发:关键设计--使用 haiku 模型为每个用例启动一个独立的子 agent,所有 agent 在同一条消息中并发派发(而非串行启动),确保真正的并行执行。每个子 agent 的 Prompt 中包含:
-
1. CRITICAL RULES(置顶):禁止 Read 。yml 文件、禁止 waitForTimeout、禁止文件系统探索、close 后立即停止等强制约束
-
2. 已知稳定信息:登录 ref(e13/e15/e18)、Tour 弹窗 JS 移除方案、force click 处理策略
-
3. 明确的执行指令:先 Read 两个 。md 文件(前置 + 用例),然后严格按 Batch 块执行 Bash 命令,命令原样复制不得重写
-
-
4. 结果汇总:所有子 agent 完成后,从返回的用例标签中提取耗时、Tool 调用数、Token 消耗,按固定格式输出汇总表格。
选择 haiku 而非 opus/sonnet 执行测试的理由:测试执行是机械性操作--读 。md → 逐条执行命令 → 检查结果,不需要深度推理;haiku 的响应速度更快(减少推理延迟)、成本低 10 倍以上(适合高频回归)、不会占用主 agent 的上下文窗口。
Skill 3(optimizing-playwright-cli-tests)-- 日志分析 + 浪费模式识别 + 分层修复
Skill 3 是「事后优化器」,不介入主测试流程,而是在指标超标后被激活。其内部工作流程为:
-
1. 日志解析:调用日志分析脚本,读取子 agent 的 jsonl 执行日志,逐行提取每次 Tool 调用的类型、参数、耗时,生成可分析的调用序列。
-
2. 浪费模式识别:将调用序列与 14 类已知浪费模式逐一比对,按影响程度排序。例如:
-
1. 发现连续 3 次 snapshot 但中间没有需要检查输出的步骤 → 判定为冗余 snapshot;
-
2. 发现 waitForTimeout(3000) → 判定为固定等待可替代;
-
3. 发现 7 条独立 Bash 调用可合并 → 判定为命令未批量化(否则每一轮都要等待 LLM 思考调用)。
-
-
3. 分层修复建议:按三个层次生成优化方案
-
1. 用例文件:消除冗余步骤、添加已知稳定 ref 作为快速路径、用条件等待替代固定等待、按 Batch 链式执行减少推理延迟
-
2. 前置流程:稳定化部分流程直接用 JS 处理、减少度化流程的探索步骤、明确禁止浪费行为
-
3. Agent Prompt 模板:CRITICAL RULES 置顶、预置已知信息、明确终止条件
-
-
4. 人工确认 + 重新验证:优化建议由人工逐条确认后应用到 。md 文件(不会自动修改),然后可以调用 Skill 2 重新执行测试,对比优化前后指标。若仍超标则进入下一轮迭代,直至所有指标达标。
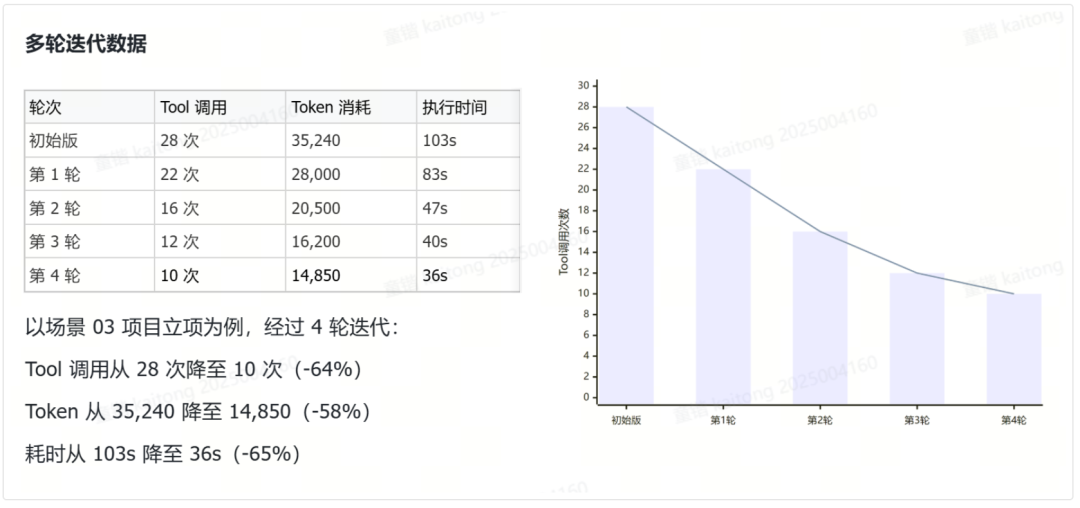
多轮迭代数据
|
轮次 |
Tool 调用 |
Token 消耗 |
执行时间 |
主要优化措施 |
|
初始版 |
28 次 |
35,240 |
103s |
— |
|
第 1 轮 |
22 次 |
28,000 |
83s |
删除冗余 snapshot |
|
第 2 轮 |
16 次 |
20,500 |
47s |
Bash 命令批量化 |
|
第 3 轮 |
12 次 |
16,200 |
40s |
waitForURL 替代 waitForTimeout |
|
第 4 轮 |
10 次 |
14,850 |
36s |
合并同页面步骤 + 已知 ref 硬编码 |
以场景 03 项目立项为例,经过 4 轮迭代:
Tool 调用从 28 次降至 10 次(-64%)
Token 从 35,240 降至 14,850(-58%)
耗时从 103s 降至 36s(-65%)
playwright-cli 核心层:浏览器原子能力
实际驱动测试浏览器的执行层。AI Agent 通过命令行调用 playwright-cli,不直接操作浏览器。playwright-cli 提供六类原子能力:
|
能力类别 |
核心命令 |
用途 |
在测试中的典型用法 |
|
页面导航 |
open、goto |
启动浏览器、导航到目标 URL |
open --headed --browser chrome --config playwright-cli-config.json |
|
交互操作 |
click、fill、select |
点击元素、填写输入框、选择下拉项 |
fill e13 username(通过 snapshot ref 定位元素) |
|
快照采集 |
snapshot、screenshot |
获取页面 DOM 结构和 ref、截图保存 |
snapshot 获取 ref → click 操作元素 |
|
自定义 JS |
run-code |
执行任意 JavaScript 代码 |
run-code "$(cat scripts/04-step2-basic-info.js)"(外置 JS 文件) |
|
状态复用 |
run-code |
跨页面、跨系统传递测试数据 |
localStorage.setItem('TEST_PROJECT_NAME', name) |
|
多 Tab 管理 |
tab-list、close |
查看所有标签页、关闭浏览器 |
tab-list 检查 URL 做断言、close 结束测试 |
所有命令通过 参数绑定到特定的浏览器会话,支持多个 session 并行运行互不干扰。浏览器配置通过 playwright-cli-config.json 统一管理:
{
"browser": {
"contextOptions": {"ignoreHTTPSErrors": true,"viewport": null},
"launchOptions": {"args": ["--ignore-certificate-errors", "--start-maximized"]}
}
}其中 ignoreHTTPSErrors: true 解决内网自签名证书问题,viewport: null + --start-maximized 确保浏览器以最大化窗口运行(避免元素被遮挡或不在视口内)。
代码生成层:测试资产沉淀
测试执行完成后自动产出四类可复用资产:
|
资产类型 |
文件格式 |
存放位置 |
说明 |
|
测试用例文档 |
.md |
tests/ |
符合规范的 Markdown 文件,包含 session 声明、Batch 分组、CRITICAL RULES、预期结果,可被 AI Agent 直接读取执行 |
|
步骤脚本库 |
.js |
scripts/ |
复杂 JS 逻辑的模块化文件,中文用 \uXXXX 转义,通过 run-code "$(cat scripts/xxx.js)" 引用,支持独立调试和维护 |
|
前置流程模块 |
.md |
tests/00-*-prerequisite.md |
公共前置步骤的可复用模块(如 SSO 登录、OA 审批),任何用例声明依赖即可插入同一段流程 |
|
配置与工具 |
.json / .py / .js |
scripts/ |
浏览器配置(playwright-cli-config.json)、日志分析(parse-agent-log.py)、录屏检测(detect-viewport.js) |
代码生成层的核心设计原则是业务骨架与技术实现分离:。md 用例文件只保留业务流程的步骤骨架(Batch 分组 + 命令序列),具体的表单操作、iframe 交互、DOM 操作等复杂逻辑全部下沉到 scripts/*.js 文件中。这种分离带来三个好处:
-
1. .md 文件对业务人员可读,便于评审和维护
-
2. .js 脚本可独立调试,修改不影响流程骨架
-
3. 规避了 Windows 环境下 run-code 内联中文的编码问题
优化层:指标驱动的持续改进
以指标超标为触发条件,自动开启优化循环。触发阈值基于实际优化经验设定:
|
指标 |
目标值(达标) |
警告阈值(触发优化) |
来源 |
|
Tool 调用数/用例 |
≤ 15 |
> 20 |
2 次 Read(md 文件)+ md 中定义的 Bash 命令数 + ≤2 次冗余调用 |
|
Token/Tool 调用 |
≤ 1,200 |
> 1,500 |
每次调用的平均 token,衡量单步效率 |
|
耗时/Tool 调用 |
≤ 8s |
> 12s |
每次调用的平均耗时,含网络 + 推理延迟 |
|
冗余调用数 |
≤ 2 |
> 5 |
总调用 - 必要调用(2 Read + Bash 命令数) |
自优化层的四个子流程形成内循环:
-
1. 测试失败分析:parse-agent-log.py 解析 jsonl 日志,输出每一步的 Tool 类型、参数、耗时索引,定位具体出错或浪费的步骤
-
2. 步骤自动修复:Agent 将日志分析结果与 14 类已知浪费模式比对,生成针对性优化方案(如「第 5 步的 snapshot 是冗余的,上一步 goto 的返回已包含快照路径」)
-
3. 用例迭代更新:优化方案经人工确认后应用到 。md 文件和 scripts/*。js 脚本中
-
4. 回流验证:更新后的用例通过 Skill 2 重新执行,对比优化前后指标,输出对比表格。若仍超标则进入下一轮迭代(如果以 --dangerously-skip-permissions 启动 claude 就可以一直自优化循环直到效果符合指标)
这种数据驱动的优化模式,确保了每一次修改都有量化的效果验证,避免了凭经验优化却无法衡量收益的问题。
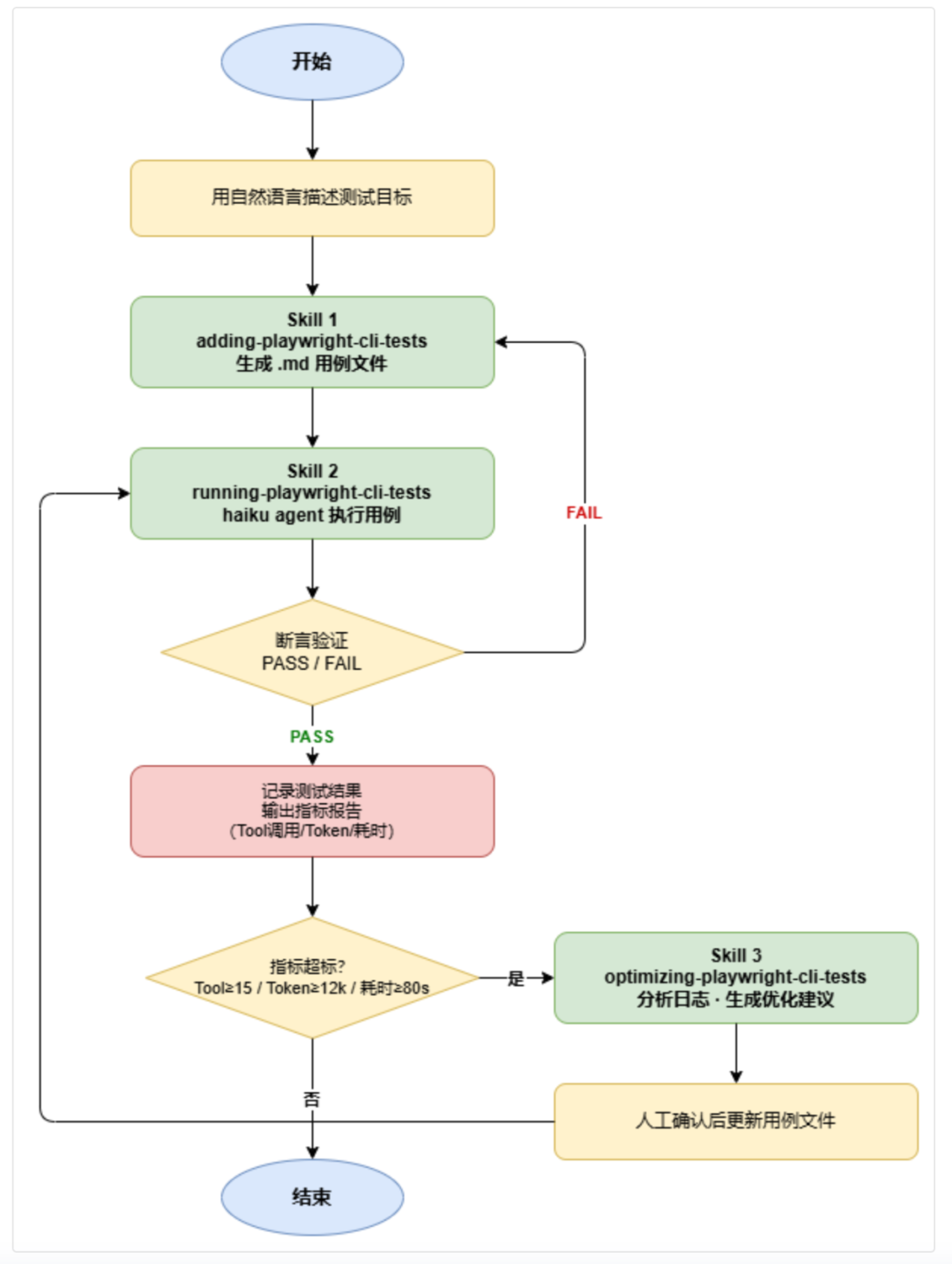
操作步骤:三句话完成自动化测试
整个自动化测试日常操作围绕三个 Skill 展开,对应「创建 → 执行 → 优化」三个阶段。
你不需要了解 playwright-cli 的任何命令,不需要写任何代码。只需要在 Claude Code 中输入一句自然语言,对应的 Skill 会自动完成所有工作。
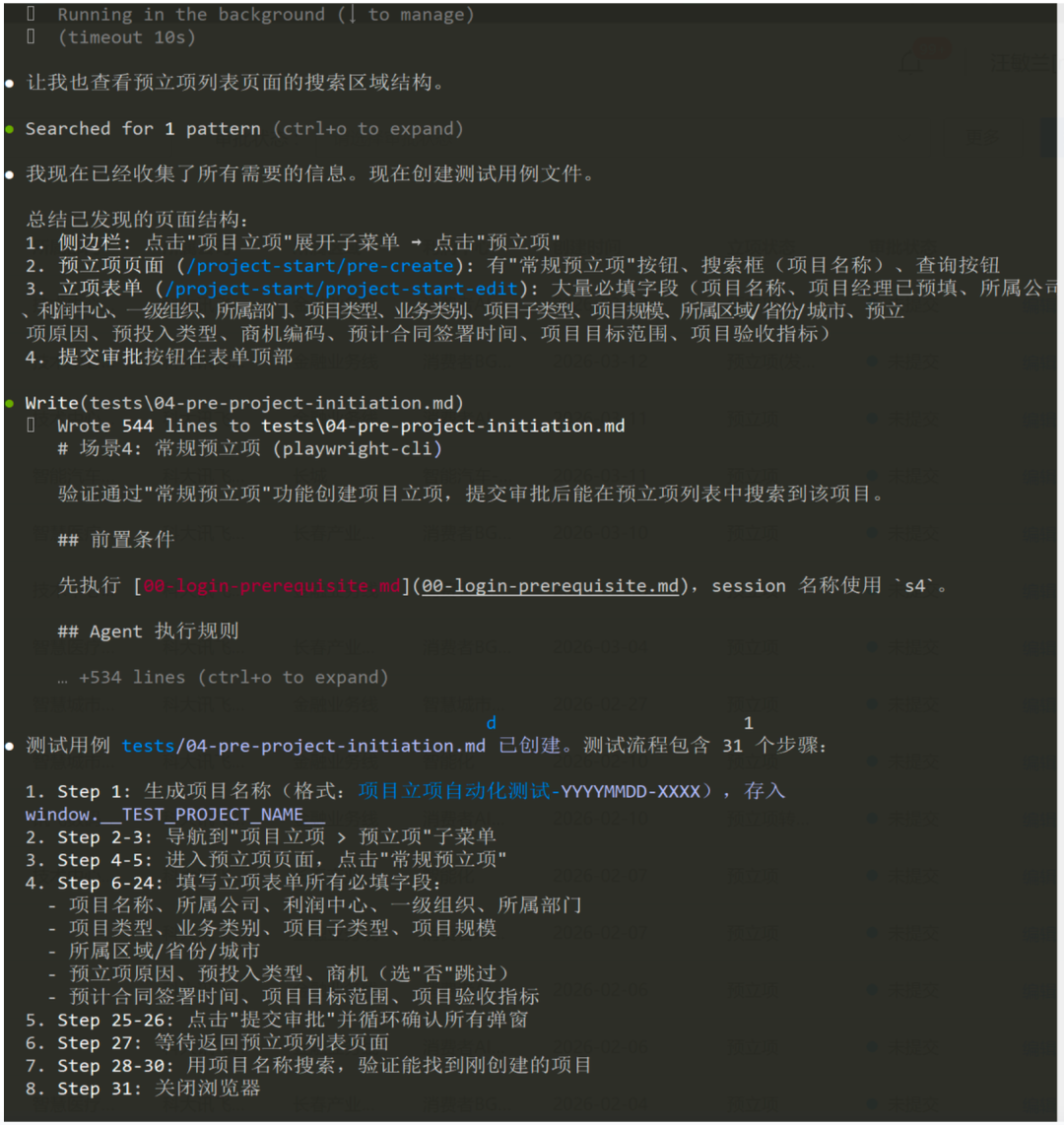
创建用例
当你需要为一个新的业务流程建立自动化测试时,只需输入类似以下内容(此处为添加 OA 审批的真实案例):
添加测试场景:增加后续的 OA 审批通过场景(还是用 04同一个用例)。打开新的OA浏览器标签页,地址是xx。使用之前登录一样的账号密码,进来后进入流程监控页面。在流程监控页,使用刚才新建的项目名进行搜索,鼠标悬浮到过滤到项目行,通过行下拉菜单,点击流程干预,进入流程干预页面。进入后页面直接滚动到下方流程干预模块,流转至节点选择集团EMT分管管理者。流转至节点操作者,选择我自己(登录的人),并通过穿梭框添加,最后完成提交。完成流程干预后,通过侧边栏切换到代办事宜页面,再次搜索创建的项目名,通过行标题名称进入详情页。之后完成项目通过,即完成 OA 审批。
最后,返回 dpms系统,再次搜索创建的项目,项目状态应该从 审批中,变为执行中。至此该 OA 审批通过流程全部完成。注意这个 OA 审批公用的审批流程。再看一个案例,这是测试人员直接写的测试步骤,一次性跑通:
1、登录dpms系统-合同交底合同收入拆分页面,选择合同进行拆分,拆分成功后
2、进入合同交底-合同生成项目页面,点击生成项目按钮,选择刚才拆分的合同,点击确定,进入合同生成项目详情页面,选择合同产品,点击生成新项目,输入生成项目的项目类型,子类型,项目成本,保存之后,点击提交
3、进入进入合同交底-合同内容交底页面,将生成项目的合同进行交底
4、进入项目立项-正式立项页面
5、选择刚才生成的项目点击发起立项按钮
6、输入项目内容后,点击提交审批按钮
7、提交审批后,登陆OA页面,进行oa审批Skill 1 自动激活后会完成以下工作(你只需要观察和确认):
-
1. 开启浏览器,导航到目标页面
-
2. 自动探索页面结构,识别表单元素、按钮、链接
-
3. 生成标准化的
.md用例文件(保存在tests/目录下) -
4. 如果涉及复杂表单操作,自动将 JS 逻辑抽离到
scripts/目录 -
5. 执行一遍验证用例可用
生成的用例开箱即用,你随时可以用文本编辑器打开
.md文件查看和修改测试步骤。
创建用例实际场景(提交立项场景):
执行用例
用例创建好之后,需要跑测试时输入:
执行所有用例 # 并发执行全部测试
执行 04 用例 # 只跑某一个场景
跑 01 和 03 # 跑指定的几个场景Skill 2 自动激活后,你什么都不用做,等待执行完成即可。它会:
-
1. 自动为每个用例分配独立浏览器会话,并发执行
-
2. 自动处理弹窗遮挡、页面超时、元素变化等常见异常
-
3. 执行完成后输出一份汇总报告:
如果需要在执行时看到浏览器画面(比如排查问题),可以说「有头模式执行 04 用例」。
优化用例
当你发现某个用例跑得慢、消耗高,或者报告中指标标红时,输入优化用例 xx:
优化 04 用例 # 指定优化某个用例
优化用例 # 优化所有超标用例Skill 3 自动激活后会:
-
1. 分析上次执行日志,找到具体哪些步骤在浪费时间或 Token
-
2. 给出优化建议(如「删除多余的 snapshot」「合并 Bash 命令」)
-
3. 等你确认后才修改用例文件(不会自动改)
-
4. 修改后自动重跑验证效果
当用例的 Tool 调用 > 15 次、Token > 12000、耗时 > 80s 时,Skill 3 也会在执行结束后自动提示你需要优化。
场景速查表
|
你想做什么 |
输入什么 |
|
新增一个测试场景 |
添加测试场景:xxx(描述你要测试的业务流程) |
|
跑全部测试 |
执行所有用例 |
|
跑某一个测试 |
执行 04 用例 或 跑 01 |
|
看着浏览器跑 |
有头模式执行 04 用例 |
|
测试跑得慢想优化 |
优化 04 用例 |
|
录制执行过程 |
录屏执行 04 用例 |
总结与展望
降低门槛:测试人员无需编程,用自然语言即可创建和执行自动化测试
资产沉淀:每次测试自动产出可复用的 。md 用例文件和 。js 脚本
成本可控:haiku 模型 + 自优化迭代,Token 消耗持续下降
闭环自治:创建 → 执行 → 优化三个 Skill 形成自动化闭环
在这样的能力组合之上,本方案特别适合这些场景:
-
• 步骤固定、需频繁回归的核心业务流程
-
• 跨系统、多 Tab、iframe 嵌套等复杂端到端场景
-
• 团队中测试人员编程能力有限但业务理解深厚
-
• 希望在不先搭一整套重型框架的前提下,短时间内迅速拉升测试覆盖范围的项目
后续方向:
-
• CI/CD 集成:将 Skill 2 的执行能力接入 CI 流水线,实现每次提交自动回归
-
• 智能断言增强:结合截图对比和 DOM diff,自动发现 UI 回归问题
-
• 结合更多场景,持续迭代 Skills
-
• 用例自动生成:
-
• 基于用户操作录制,自动产出 。md 用例文件
-
• 基于现有代码,ai 生成路径自动生成代码(无法覆盖覆盖业务流程)
-
• 基于需求文档,ai 生成完整业务场景(最看好的方案,结合基于代码逆向生成 PRD 项目仍在探索中)
-
-
• 测试报告可视化:集成历史执行趋势展示、指标变化追踪
项目结构
playwright-test/
├── tests/ # 测试用例(Markdown)
│ ├── 00-login-prerequisite.md # 公共前置:SSO 登录 + Tour 弹窗处理
│ ├── 00-oa-approve-prerequisite.md # 公共前置:OA 审批流程(跨系统)
│ ├── 01-login-feedback.md # 场景1:登录反馈功能验证
│ └── 04-pre-project-initiation.md # 场景4:项目立项全流程 + OA 审批
│
├── scripts/ # 自动化脚本(JS + 工具)
│ ├── 04-step1-navigate.js # 导航到立项页
│ ├── 04-step2-basic-info.js # 填写基本信息(53行,含日期选择)
│ ├── 04-step3-project-plan.js # 项目计划(含重试逻辑)
│ ├── 04-step4-iframe-task.js # iframe 任务操作(双层嵌套)
│ ├── 04-step5-submit.js # 提交审批
│ ├── 04-step6-verify.js # 验证状态「审批中」
│ ├── 04-step11-dpms-verify.js # 验证状态「审批完成」
│ ├── 00-oa-step1-login.js # OA 登录(新 Tab + SSO)
│ ├── 00-oa-step2-search-intervene.js # OA 搜索干预(含三点菜单)
│ ├── 00-oa-step3-intervene-config.js # OA 干预配置(128行,全 evaluate)
│ ├── 00-oa-step4-approve.js # OA 审批通过(含轮询等待)
│ ├── parse-agent-log.py # 日志分析脚本(提取 Tool/Token/耗时)
│ └── detect-viewport.js # 录屏分辨率自动检测
│
├── .claude/skills/ # Claude Code Skills
│ ├── adding-playwright-cli-tests/ # Skill 1:创建用例
│ ├── running-playwright-cli-tests/ # Skill 2:执行用例
│ └── optimizing-playwright-cli-tests/ # Skill 3:优化用例
│
├── playwright-cli-config.json # 浏览器配置(忽略 HTTPS + 最大化)
├── screenshots/ # 测试截图输出
└── videos/ # 录屏文件输出(.webm 或 .mp4,支持 playwright 录制或桌面录制)
AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 8
8 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)