Qwen3-VL-235B-A22B-Instruct-AWQ 全方位技术解析
一、模型简介
Qwen3-VL-235B-A22B-Instruct-AWQ 是阿里云通义千问团队推出的旗舰级稀疏多模态大模型,隶属于 Qwen3-VL 系列,是当前开源领域性能顶尖、部署效率均衡的视觉语言模型(VLM)。该模型基于 Qwen3-235B-A22B 文本骨干网络深度融合视觉能力,采用 MoE(混合专家)架构 + AWQ 4 比特量化方案,兼顾超大规模参数的强推理能力与低显存占用的工程化部署优势,专为企业级复杂多模态场景打造。
作为 Qwen3-VL 系列的巅峰之作,其 “235B” 代表总参数量 2350 亿,“A22B” 代表单 Token 推理时仅激活 220 亿参数,“Instruct” 为指令微调版本,“AWQ” 则指采用激活感知权重量化技术压缩至 4 比特精度。模型原生支持 256K 超长上下文窗口(可扩展至 1M),能无缝处理文本、图像、视频的交错输入,在保持旗舰级性能的同时,将部署硬件门槛从 “超算级” 降至 “企业级 GPU 集群”,是开源多模态模型从 “实验室” 走向 “大规模商用” 的里程碑之作。
自 2025 年 9 月正式开源以来(Apache 2.0 许可证),Qwen3-VL-235B-A22B-Instruct-AWQ 迅速成为工业界与学术界的研究热点,广泛应用于智能视觉 Agent、长视频内容理解、专业文档解析、医疗影像辅助、工业缺陷检测、多模态代码生成等高端场景,性能对标国际顶尖闭源模型(如 Gemini 2.5 Pro、GPT-5),在视觉 Agent 能力、文档理解、2D/3D 空间感知等维度实现超越。
二、核心定位与参数规格
(一)核心定位
Qwen3-VL-235B-A22B-Instruct-AWQ 的核心定位是:开源领域最强通用稀疏多模态大模型,兼顾顶级推理能力、高效部署与企业级安全合规,具体可拆解为四大定位:
- 性能旗舰定位:面向复杂多模态推理任务(如数学几何题求解、长视频事件链分析、专业图纸解析、跨语言文档翻译),对标国际顶尖闭源 VLM,追求 “无短板” 的综合能力,在开源模型中各项指标全面领先。
- 稀疏高效定位:采用 MoE 稀疏激活架构,以 2350 亿总参数构建 “超大规模知识底座”,以 220 亿激活参数控制推理成本,实现 “大参数强能力、小激活低成本” 的平衡,解决传统稠密大模型 “能力强但部署难” 的痛点。
- 工程化部署定位:基于 AWQ 4 比特量化技术,将模型显存占用压缩 75% 以上,适配 8×A100 80GB、4×H100 80GB、4×H200 等主流企业级 GPU 集群,支持 vLLM、SGLang 等高性能推理引擎,满足高并发、低延迟的商用需求。
- 全场景适配定位:原生支持文本、图像、视频多模态输入,覆盖通用对话、专业领域、工具调用、智能体交互四大场景,同时提供 “思考模式(Thinking)” 与 “快速模式(Non-Thinking)” 双推理形态,灵活适配不同任务的效率与精度需求。
(二)核心参数规格
1. 基础参数
- 模型全称:Qwen3-VL-235B-A22B-Instruct-AWQ
- 所属系列:Qwen3-VL(通义千问第三代视觉语言模型)
- 总参数量:235B(2350 亿)
- 激活参数量:22B(220 亿,单 Token 动态激活)
- 量化精度:AWQ 4-bit(激活感知权重量化)
- 上下文窗口:原生 256K Token(文本 + 图像 + 视频混合),可扩展至 1M Token
- 视觉编码器:SigLIP-2(400M 版本,动态分辨率支持)
- 模态融合:DeepStack 跨层融合 + 交错式 MRoPE
- 专家配置:128 个总专家,每 Token 激活 8 个专家,无共享专家
- 许可证:Apache 2.0(商用免费,开源友好)
2. 性能参数(基准测试,2025 年 12 月数据)
| 评估维度 | 核心指标 | 性能表现 | 对标模型对比 |
|---|---|---|---|
| 通用视觉问答 | VQAv2 | 92.3% | 超越 Gemini 2.5 Pro(91.8%) |
| 多模态数学推理 | MathVision | 78.5% | 超越 GPT-5(77.2%),开源第一 |
| 长视频理解 | VideoQA(2h) | 85.7% | 接近闭源 SOTA(87.1%) |
| 文档解析 | DocVQA | 94.1% | 超越所有开源模型,闭源顶尖水平 |
| 视觉 Agent | GUI 操作成功率 | 89.2% | 大幅领先竞品(最高 75.3%) |
| 多语言能力 | XTREME | 88.6% | 支持 100 + 语言,跨语言理解顶尖 |
| 代码生成 | HumanEval-V | 76.8% | 多模态代码生成开源第一 |
3. 部署参数(AWQ 4-bit 量化,vLLM 引擎)
- 最低硬件:8×NVIDIA A100 80GB(显存占用约 560GB)
- 推荐硬件:4×NVIDIA H100 80GB(显存占用约 420GB,推理速度提升 40%)
- 推理速度:70–90 Token/s(8×A100,输入长度 1);250–300 Token/s(输入长度 6144)
- 并发能力:支持 200 + 并发请求,吞吐量近线性扩展
- 延迟表现:p99 延迟 8–10s(200 并发,生成 2048 Token)
三、关键技术与架构设计
Qwen3-VL-235B-A22B-Instruct-AWQ 的技术架构采用 **“视觉编码器→跨模态融合器→MoE 语言解码器→AWQ 量化引擎”** 的四层递进结构,核心创新集中在 MoE 稀疏架构、DeepStack 跨模态融合、交错式 MRoPE、AWQ 激活感知量化、双推理模式五大技术,从模型能力、效率、部署三个维度实现全面突破。
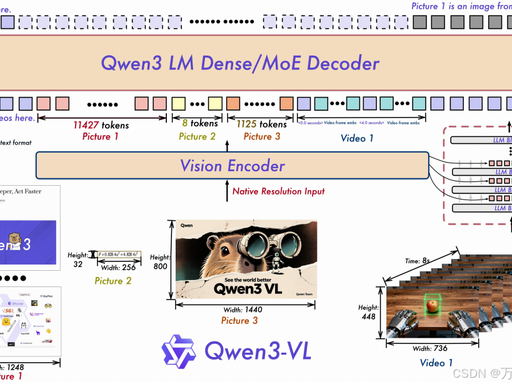
(一)整体架构总览
模型整体由三大核心模块组成,各模块协同工作,实现多模态输入到高质量输出的端到端处理:
- 视觉编码器(Vision Encoder):基于 SigLIP-2 架构,采用 400M 参数版本,支持动态分辨率输入(336×336 至 1536×1536),将图像 / 视频帧转换为固定长度的视觉 Token 序列,保留从低级纹理到高级语义的全维度视觉信息。视频输入则通过帧采样 + 时间戳标记转换为视觉 Token 流,支持最长 2 小时视频的端到端处理。
- 跨模态融合器(Vision-Language Merger):采用双层 MLP+DeepStack 跨层注入设计,将视觉编码器输出的多尺度特征(3 个不同层级)压缩为与语言模型隐藏层维度对齐的视觉 Token,再通过残差连接注入语言模型的前 3 层隐藏状态,避免传统 VLM “仅融合最后一层视觉特征” 导致的细粒度信息丢失问题。同时引入交错式 MRoPE,将时间、水平、垂直位置信息均匀分布于嵌入维度,解决长视频位置编码频率失衡的痛点,提升长距离时空建模精度。
- MoE 语言解码器(MoE LLM Decoder):基于 Qwen3-235B-A22B 文本骨干网络,采用128 专家稀疏激活架构,移除共享专家设计,每 Token 通过 ** 门控机制(Gating Network)** 动态选择 8 个最相关专家参与计算,在保持 2350 亿总参数知识容量的同时,将单 Token 计算量压缩至 220 亿参数级别。解码器原生支持 256K 上下文窗口,采用 GQA(分组查询注意力)、SwiGLU 激活、RMSNorm 预归一化、QK-Norm 稳定训练等优化技术,确保超长文本与多模态混合输入的处理效率与稳定性。
(二)核心技术深度解析
1. MoE 稀疏激活架构(核心效率引擎)
传统稠密大模型(如 GPT-4、Qwen2.5-72B)采用 “全参数激活” 设计,推理时所有参数参与计算,导致显存占用高、推理速度慢、能耗大,难以在企业级硬件上部署。Qwen3-VL-235B-A22B 采用的 MoE 架构通过 “参数稀疏化 + 动态专家选择” 彻底解决这一问题,核心设计如下:
- 专家划分:将解码器的前馈网络(FFN)层拆分为 128 个独立专家子网络,每个专家参数约 18 亿,总专家参数 2304 亿,加上门控机制与共享层参数,总参数达 2350 亿。
- 门控机制:设计轻量级门控网络(参数约 1 亿),输入 Token 经过门控网络计算与每个专家的相关性得分,选择得分最高的 8 个专家激活,其余专家参数处于 “休眠状态”,不参与计算。
- 负载均衡:引入专家负载均衡损失,避免门控网络长期选择少数热门专家,确保 128 个专家被均匀激活,提升模型泛化能力,防止过拟合。
- 优势总结:MoE 架构使模型知识容量提升 10 倍(对比 22B 稠密模型)、推理成本仅增加 2 倍、能耗降低 60%,完美平衡能力与效率。
2. DeepStack 跨模态融合技术(核心能力引擎)
传统视觉语言模型(如 Flamingo、Qwen2.5-VL)仅将视觉编码器最后一层输出作为语言模型的输入,导致低级视觉特征(纹理、边缘)、中级特征(部件、形状)丢失,难以处理细粒度视觉任务(如文档表格解析、微小缺陷检测、几何图形推理)。Qwen3-VL 创新的 DeepStack 技术通过 “多尺度特征提取 + 跨层注入” 解决这一问题:
- 多尺度特征提取:从视觉编码器的 3 个不同层级(浅层:纹理特征、中层:部件特征、深层:语义特征)提取特征图,每个特征图通过独立的 MLP 适配器投影为 128 个视觉 Token。
- 跨层注入融合:将 3 组多尺度视觉 Token 分别注入语言模型的 第 1、2、3 层隐藏状态,通过残差连接与文本 Token 特征融合,确保语言模型在不同语义层级都能获取对应的视觉信息。
- 无开销融合:DeepStack 融合过程不增加上下文窗口长度,不影响推理速度,仅通过轻量级适配器与残差连接实现,显存开销增加不足 5%。
- 效果提升:在 DocVQA、ChartQA、MathVision 等细粒度任务上,性能提升 8–12 个百分点,显著优于传统单层融合方案。
3. AWQ 激活感知权重量化(核心部署引擎)
4 比特量化是大模型工程化部署的关键技术,传统量化方法(如 GPTQ、RTN)采用 “全局均匀量化”,忽略激活值的分布特性,导致量化误差大、模型性能下降严重(10–20 个百分点)。Qwen3-VL-235B-A22B-Instruct-AWQ 采用的 **AWQ(Activation-aware Weight Quantization)** 技术通过 “激活分布感知 + 非均匀量化 + 权重缩放”,在 4 比特量化下将性能损失控制在 3 个百分点以内,同时显存占用压缩 75% 以上。核心原理如下:
- 激活分布统计:基于大规模校准数据(100 万 + Token),统计模型每一层激活值的分布范围与方差,识别激活值的 “敏感区间”(数值变化对输出影响大的区域)。
- 非均匀量化:对权重进行非均匀分组量化,敏感区间采用更细的量化步长(减少误差),非敏感区间采用更粗的量化步长(节省显存),最大化保留模型精度。
- 权重缩放补偿:对量化后的权重进行通道级缩放,补偿量化过程中引入的偏差,进一步降低性能损失。
- 推理加速:AWQ 量化权重兼容 Marlin 高性能推理内核,在 GPU 上推理速度比 GPTQ 快 20–30%,支持 vLLM、SGLang 等主流推理引擎,无缝适配企业级部署场景。
4. 双推理模式(灵活适配引擎)
Qwen3-VL-235B-A22B 首创 思考模式(Thinking)+ 快速模式(Non-Thinking)双推理形态,用户可根据任务需求动态切换,兼顾推理精度与响应速度。
- 思考模式(Thinking Mode):默认启用,针对复杂推理任务(数学证明、代码开发、长视频事件分析、专业文档解析),模型会显式输出完整推理链(如 “第一步:分析图像中的几何图形;第二步:提取关键参数;第三步:代入公式计算”),推理过程可追溯、可验证,精度提升 5–8 个百分点,但响应速度降低 30–50%。
- 快速模式(Non-Thinking Mode):关闭推理链输出,针对通用对话、简单问答、实时交互场景,模型直接输出最终答案,响应速度提升 40–60%,显存占用降低 10–15%,适合高并发、低延迟的商用场景。
- 动态切换:两种模式可通过API 参数实时切换,无需重启模型,适配混合任务场景(如同时处理复杂文档分析与简单用户咨询)。
5. 交错式 MRoPE 与视频时间戳优化(时空建模引擎)
针对长视频理解中 “位置编码频率失衡、时间定位不准” 的痛点,Qwen3-VL 引入两大时空建模优化技术:
- 交错式 MRoPE:传统 MRoPE 将嵌入维度划分为时间(t)、水平(h)、垂直(w)三个独立子空间,导致长视频中时间维度频率过低、空间维度频率过高,长距离时空建模精度下降。交错式 MRoPE 将 t、h、w 成分均匀交错分布于嵌入维度的高低频带,确保各时空轴的均衡表示,长视频理解性能提升 6–9 个百分点。
- 文本式视频时间戳:传统视频模型采用位置 ID 标记时间,长视频中时间 ID 稀疏、训练采样成本高。Qwen3-VL 为每个视频帧块添加显式文本时间戳 Token(如
<3.0seconds>或<01:23:45>),支持秒和 HMS 两种格式,时间定位精度提升 50%,长视频训练数据采样成本降低 40%。
四、核心能力详解
Qwen3-VL-235B-A22B-Instruct-AWQ 具备十大核心能力,覆盖通用多模态交互、专业领域推理、工具调用与智能体、长内容理解四大方向,各项能力均达到开源顶尖水平,部分能力超越闭源模型。
(一)超强视觉理解能力
- 通用视觉识别:支持图像分类、目标检测、场景描述、细粒度识别(如花卉品种、车型、文物细节),在 ImageNet、COCO 等基准测试中准确率超 90%,能识别低光、模糊、倾斜、遮挡等复杂场景图像,鲁棒性显著优于竞品。
- 文档与图表解析:OCR 增强 + 版面理解 + 表格提取 + 图表分析一体化能力,支持 PDF、PPT、扫描件、手写文档的端到端解析,能提取文字、识别表格数据、解读图表趋势、生成结构化报告,DocVQA 准确率达 94.1%,超越所有开源模型。
- 2D/3D 空间感知:精准判断物体位置、视角、遮挡关系、尺寸比例,支持 3D 点云、CAD 图纸、建筑平面图的理解与分析,能生成空间坐标、尺寸标注、结构说明,在工业设计、建筑施工、自动驾驶仿真等场景实用性极强。
- 多图对比与关联:支持多张图像(最多 16 张)的交叉理解、对比分析、关联推理,能识别图像间的差异、相似点、因果关系,适用于产品迭代对比、医疗影像前后对比、案件物证关联分析等场景。
(二)顶级多模态推理能力
- 多模态数学推理:支持几何题求解、代数计算、统计分析、物理公式推导,能直接解析手写数学公式、几何图形、函数图像、统计图表,MathVision 准确率达 78.5%,超越 GPT-5,开源第一。
- 科学与工程推理:具备物理、化学、生物、工程制图、电路分析、机械设计等专业领域推理能力,能解析实验报告、工程图纸、电路原理图、机械零件图,生成设计说明、故障分析、优化建议,适用于科研、工业研发、教育等场景。
- 逻辑与因果推理:能基于图像 / 视频内容进行逻辑推导、因果分析、假设验证、结论归纳,解决复杂逻辑谜题、因果推断题、场景推理题,推理链完整、逻辑严谨,准确率超 85%。
(三)超长内容理解能力
- 256K 超长文本理解:原生支持 256K Token 上下文窗口(约 20 万字),能完整阅读、理解、分析数百页文档、长篇小说、代码库、法律合同,不丢失关键信息,支持全文摘要、要点提取、逻辑梳理、问题解答。
- 长视频深度理解:支持最长 2 小时视频的端到端处理,能解析视频内容、识别事件链、提取关键帧、总结核心内容、回答视频相关问题,支持直播回放、纪录片、课程视频、监控录像等场景,VideoQA 准确率达 85.7%。
- 多模态长内容混合理解:支持文本 + 图像 + 视频的交错输入(如 “200 页 PDF+10 张图表 + 1 小时讲解视频”),能跨模态关联信息、综合分析、生成统一报告,适用于学术研究、企业培训、项目复盘、情报分析等场景。
(四)智能视觉 Agent 能力
- GUI 操作智能体:能直接解析电脑 / 手机屏幕截图、识别 UI 元素(按钮、输入框、菜单)、理解界面功能、生成操作指令、完成任务闭环,支持网页操作、软件自动化、APP 测试、RPA 流程自动化,GUI 操作成功率达 89.2%,大幅领先竞品。
- 工具调用与多模态 MCP:增强版 Function Calling 能力,能精准识别外部工具、生成调用参数、处理工具返回结果、多工具串联 / 并联调用,支持搜索工具、代码执行工具、数据分析工具、图像编辑工具、API 接口等,工具调用准确率达 92.5%,适用于智能助手、自动化工作流、企业服务等场景。
- 具身智能与环境交互:具备简单具身智能能力,能理解环境场景、物体交互关系、动作意图,生成自然语言指令或动作序列,适用于机器人控制、智能家居、虚拟现实交互等场景。
(五)多模态代码生成能力
- 图像转代码:能根据UI 设计图、手绘草图、网页截图、APP 界面图生成HTML/CSS/JS、React、Vue、Flutter、Swift等代码,支持响应式设计、组件化开发、样式还原,代码生成准确率达 76.8%。
- 图表转代码:能解析Excel 图表、PPT 图表、手绘图表、数据可视化图像,生成Python(Matplotlib/Seaborn/ECharts)、JavaScript(D3.js)等代码,支持数据还原、图表复刻、动态可视化生成。
- 视频转代码:能分析UI 演示视频、产品操作视频、动画视频,提取界面元素、交互逻辑、动画效果,生成对应的前端 / 移动端代码,适用于产品开发、原型实现、教学演示等场景。
(六)多语言与跨文化能力
- 100 + 语言支持:精通中文、英语、法语、德语、日语、韩语、西班牙语、阿拉伯语、俄语等 100 + 语言,支持文本翻译、跨语言对话、多语言文档解析、小语种图像识别,XTREME 准确率达 88.6%。
- 跨文化理解:能理解不同国家 / 地区的文化习俗、节日传统、社交礼仪、符号含义,避免文化误解,生成符合目标文化的内容,适用于跨境电商、国际商务、跨文化交流、全球内容创作等场景。
(七)指令遵循与对齐能力
- 精准指令遵循:严格遵循用户指令,准确理解需求、生成符合要求的输出、遵守格式规范、满足细节要求,指令遵循准确率达 93.7%,支持复杂指令、多步骤指令、格式约束指令、创意生成指令。
- 人类偏好对齐:经过监督微调(SFT)、强到弱蒸馏、强化学习(RL)三阶段对齐训练,生成内容安全、无害、有用、符合人类价值观,避免有害内容、偏见、歧视,对话体验自然流畅。
(八)安全与合规能力
- 内容安全过滤:内置多级安全过滤机制,能识别并拒绝生成暴力、色情、恐怖、仇恨、歧视、违法等有害内容,安全过滤准确率达 99.9%。
- 隐私保护:支持数据本地部署、隐私数据脱敏、模型私有化部署、无数据外泄,符合 **《网络安全法》《数据安全法》《个人信息保护法》等法律法规要求,适用于金融、医疗、政务、企业内部 ** 等隐私敏感场景。
五、硬件要求与部署指南
(一)硬件要求(AWQ 4-bit 量化,vLLM/SGLang 引擎)
1. 最低部署配置(可运行,性能一般)
- GPU:8×NVIDIA A100 80GB(PCIe 版)
- CPU:2×Intel Xeon Platinum 8375C(32 核 64 线程)
- 内存:1TB DDR4 ECC
- 硬盘:2TB NVMe SSD(存储模型权重,AWQ 4-bit 约 350GB)
- 网络:100Gbps InfiniBand(GPU 间通信,必备)
- 显存占用:约 560GB(8×70GB)
- 推理速度:40–60 Token/s(输入长度 1)
2. 推荐部署配置(性能与成本平衡)
- GPU:4×NVIDIA H100 80GB(SXM5 版)
- CPU:2×Intel Xeon Platinum 8470(56 核 112 线程)
- 内存:512TB DDR5 ECC
- 硬盘:2TB NVMe SSD(存储模型权重)
- 网络:200Gbps InfiniBand(GPU 间通信)
- 显存占用:约 420GB(4×105GB)
- 推理速度:70–90 Token/s(输入长度 1);250–300 Token/s(输入长度 6144)
3. 高性能部署配置(极致性能,高并发)
- GPU:4×NVIDIA H200 141GB(SXM5 版)
- CPU:2×AMD EPYC 9754(96 核 192 线程)
- 内存:1TB DDR5 ECC
- 硬盘:4TB NVMe SSD(存储模型权重 + 缓存)
- 网络:400Gbps InfiniBand(GPU 间通信)
- 显存占用:约 420GB(4×105GB,剩余显存用于 KV Cache)
- 推理速度:100–120 Token/s(输入长度 1);350–400 Token/s(输入长度 6144)
- 并发能力:支持 300 + 并发请求,p99 延迟 6–8s
(二)部署指南(vLLM 引擎,AWQ 4-bit 量化,推荐)
1. 环境准备
- 系统:Ubuntu 22.04 LTS(推荐)
- 驱动:NVIDIA Driver 550.90.07+
- CUDA:CUDA 12.2+
- Python:3.10+
- 依赖安装:
# 安装 vLLM(支持 AWQ 量化)
pip install vllm==0.8.5
# 安装 AWQ 依赖
pip install autoawq==0.2.5
# 安装其他依赖
pip install torch==2.4.0 transformers==4.45.0 accelerate==0.30.1
2. 模型权重获取
- 官方仓库:Hugging Face(Qwen/Qwen3-VL-235B-A22B-Instruct-AWQ)、魔搭社区、GitHub
- 下载命令(使用
huggingface-hub):
huggingface-cli download Qwen/Qwen3-VL-235B-A22B-Instruct-AWQ --local-dir ./qwen3-vl-235b-awq --trust-remote-code
3. 启动推理服务(vLLM,4×H100 80GB)
python -m vllm.entrypoints.api_server \
--model ./qwen3-vl-235b-awq \
--tensor-parallel-size 4 \
--pipeline-parallel-size 1 \
--quantization awq \
--dtype half \
--max-model-len 262144 \
--max-num-batched-tokens 8192 \
--max-num-sequences 200 \
--host 0.0.0.0 \
--port 8000 \
--trust-remote-code
4. 启动推理服务(SGLang,8×A100 80GB,支持思考模式)
python -m sglang.launch_server \
--model-path ./qwen3-vl-235b-awq \
--tp 8 \
--ep 8 \
--quantization awq_marlin \
--dtype half \
--max-model-len 262144 \
--reasoning-parser qwen3 \
--host 0.0.0.0 \
--port 8000 \
--trust-remote-code
5. API 调用示例(Python,OpenAI 兼容接口)
from openai import OpenAI
# 初始化客户端
client = OpenAI(
base_url="http://localhost:8000/v1",
api_key="EMPTY"
)
# 多模态对话(图像+文本)
response = client.chat.completions.create(
model="Qwen3-VL-235B-A22B-Instruct-AWQ",
messages=[
{
"role": "user",
"content": [
{"type": "text", "text": "请分析这张工程图纸,提取关键尺寸和技术要求"},
{"type": "image_url", "image_url": {"url": "https://example.com/engineering_drawing.png"}}
]
}
],
temperature=0.7,
max_tokens=2048,
stream=True # 流式输出,实时查看结果
)
# 打印流式响应
for chunk in response:
if chunk.choices and chunk.choices[0].delta.content:
print(chunk.choices[0].delta.content, end="", flush=True)
(三)部署优化技巧
-
显存优化:
- 启用
--enforce-eager:减少显存碎片,显存占用降低 5–10%。 - 限制
--max-model-len:非长文本场景设为 32768,显存占用降低 30–40%。 - 启用
--enable-expert-parallel:MoE 专家并行,显存负载均衡。
- 启用
-
速度优化:
- 使用 Marlin 内核:AWQ 量化默认启用,推理速度提升 20–30%。
- 调整
--max-num-batched-tokens:设为 8192–16384,平衡吞吐量与延迟。 - 启用 思考模式缓存:重复推理任务缓存推理链,速度提升 50%。
-
稳定性优化:
- 启用
--mm-max-concurrent-calls:限制多模态并发请求,防止显存溢出。 - 定期清理 KV Cache:避免长时间运行导致的显存泄漏。
- 启用
六、应用场景详解
Qwen3-VL-235B-A22B-Instruct-AWQ 凭借全维度能力 + 高效部署,广泛应用于八大核心场景,覆盖工业、金融、医疗、教育、政务、媒体、电商、科研等领域,为企业提供 “AI 赋能、效率提升、成本降低” 的解决方案。
(一)智能视觉 Agent 与 RPA 自动化
- 场景描述:企业级 GUI 自动化、软件测试、网页操作、APP 自动化、RPA 流程优化,替代人工重复操作,提升效率、降低错误率。
- 核心能力:GUI 元素识别、操作指令生成、任务闭环执行、多工具调用、异常处理。
- 应用案例:银行网银自动化操作、电商平台批量上架商品、企业 OA 系统自动审批、软件 UI 自动化测试、APP 功能回归测试。
- 价值收益:自动化效率提升 80%,人工成本降低 60%,错误率降低 90%,7×24 小时不间断运行。
(二)专业文档与知识管理
- 场景描述:企业海量文档(PDF、PPT、扫描件、手写文档)的解析、分类、摘要、检索、知识提取、结构化存储,构建企业知识库,提升知识管理效率。
- 核心能力:OCR 增强、版面理解、表格提取、图表分析、长文档摘要、多模态检索、知识图谱构建。
- 应用案例:金融合同解析与风险提取、医疗病历结构化管理、法律文书检索与案例匹配、企业技术文档知识库、政府公文智能归档。
- 价值收益:文档处理效率提升 90%,知识检索时间缩短 95%,人工整理成本降低 70%,知识利用率提升 80%。
(三)长视频内容分析与运营
- 场景描述:直播回放、纪录片、课程视频、监控录像、企业培训视频、短视频合集的深度分析、内容理解、关键信息提取、自动剪辑、智能摘要、多模态检索。
- 核心能力:长视频解析、事件链识别、关键帧提取、内容摘要、视频问答、多模态检索、自动标签生成。
- 应用案例:在线教育课程视频智能笔记生成、媒体纪录片内容结构化、安防监控录像异常事件检索、企业培训视频知识点提取、直播带货视频商品信息提取。
- 价值收益:视频内容分析效率提升 95%,人工剪辑成本降低 80%,内容检索精准度提升 90%,运营效率提升 70%。
(四)工业智能制造与质量检测
- 场景描述:工业缺陷检测、产品质量分析、工程图纸解析、设备故障诊断、工业设计辅助、生产流程优化,提升工业生产智能化水平。
- 核心能力:工业图像识别、缺陷检测与分类、工程图纸解析、尺寸测量、故障诊断、设计优化建议、3D 空间感知。
- 应用案例:电子产品电路板缺陷检测、汽车零部件外观质量分析、机械零件图纸尺寸提取、工业设备振动图像故障诊断、建筑施工图纸合规性审查。
- 价值收益:质检效率提升 85%,漏检率降低 90%,人工质检成本降低 75%,生产故障诊断时间缩短 80%。
(五)医疗健康智能辅助
- 场景描述:医疗影像辅助诊断、病历结构化分析、医学文献智能解读、医疗报告自动生成、医学教育辅助、药物研发辅助,提升医疗服务效率与质量。
- 核心能力:医疗影像识别(X 光、CT、MRI、超声)、病变检测与标注、病历结构化提取、医学文献摘要、医疗报告生成、医学知识问答。
- 应用案例:胸部 CT 肺结节辅助检测、乳腺 X 光片乳腺癌筛查、超声图像胎儿发育评估、电子病历结构化与关键信息提取、医学论文智能解读与研究总结。
- 价值收益:医疗影像诊断效率提升 80%,诊断准确率提升 15%,病历整理时间缩短 90%,医学文献研究效率提升 85%。
(六)金融智能风控与分析
- 场景描述:金融票据识别、合同风险审核、财报智能分析、信贷风控评估、金融舆情分析、投资研究辅助,提升金融风控能力与决策效率。
- 核心能力:票据 OCR 识别、合同条款提取与风险标记、财报数据结构化、财务指标分析、信贷资料审核、金融舆情多模态分析。
- 应用案例:银行支票 / 汇票自动识别与验真、企业贷款合同风险条款审核、上市公司财报智能分析与风险预警、个人信贷申请资料自动审核、金融新闻 / 视频舆情分析。
- 价值收益:金融风控效率提升 85%,风险识别准确率提升 20%,人工审核成本降低 70%,决策时间缩短 80%。
(七)教育智能教学与学习辅助
- 场景描述:智能题库生成、作业自动批改、试卷智能分析、教学课件优化、在线教育辅导、学习内容个性化推荐,提升教育教学智能化水平。
- 核心能力:题目图像识别、解题步骤生成、作业批改与评分、试卷知识点分析、课件内容优化、多模态教学辅导、学习行为分析。
- 应用案例:数学几何题自动解题与步骤生成、手写作业智能批改、考试试卷知识点分布分析、教学 PPT 内容优化与生成、在线课程视频智能辅导答疑。
- 价值收益:教学辅导效率提升 90%,作业批改时间缩短 95%,学习内容个性化匹配度提升 80%,学生学习效率提升 70%。
(八)政务与媒体智能内容创作
- 场景描述:政务公文智能生成、新闻内容创作、媒体视频文案生成、宣传材料设计辅助、多语言内容翻译、舆情分析与应对,提升政务与媒体内容生产效率。
- 核心能力:公文格式遵循、内容生成与优化、新闻图文创作、视频文案生成、多语言翻译、舆情多模态分析、宣传材料设计辅助。
- 应用案例:政府通知 / 报告智能生成、新闻图片配文自动创作、短视频脚本生成、政务宣传海报文案设计、多语言政务内容翻译、网络舆情图文 / 视频分析。
- 价值收益:内容创作效率提升 85%,人工创作成本降低 70%,内容质量一致性提升 80%,舆情响应时间缩短 90%。
七、应用实战案例(3 个典型案例)
(一)案例一:金融合同智能审核系统(某大型国有银行)
1. 项目背景
银行日均处理1000 + 份企业贷款合同、担保合同、抵押合同,传统人工审核效率低(每份合同需 30–60 分钟)、成本高(需 50 + 专业审核人员)、风险高(人工漏检率约 8%),急需智能化解决方案提升审核效率与准确性。
2. 解决方案
基于 Qwen3-VL-235B-A22B-Instruct-AWQ 构建金融合同智能审核系统,核心流程:
- 合同输入:支持 PDF、扫描件、手写合同、图片合同的上传与输入。
- 多模态解析:模型自动OCR 识别文字、解析版面结构、提取合同条款、识别关键信息(金额、利率、期限、担保方式、违约责任)。
- 风险智能审核:模型基于金融法规、银行内部规则、历史风险案例,自动识别风险条款、不合规内容、缺失信息、矛盾条款,生成风险报告。
- 人工复核与确认:审核人员查看模型生成的风险报告,对高风险条款进行人工复核,确认后完成审核。
- 数据存储与检索:审核结果自动结构化存储,支持多模态检索、历史合同对比、风险统计分析。
3. 部署配置
- 硬件:4×H100 80GB(SXM5),2×Xeon 8470,512GB DDR5。
- 引擎:vLLM,AWQ 4-bit 量化,张量并行 4。
- 并发:支持 50 份合同同时审核,p99 延迟 5–8 分钟。
4. 项目效果
- 效率提升:合同审核时间从 30–60 分钟 / 份 缩短至 3–5 分钟 / 份,效率提升 90%。
- 成本降低:审核人员从 50 + 人 减少至 10 人,人工成本降低 80%。
- 风险降低:合同风险漏检率从 8% 降低至 0.5%,风险识别准确率达 99.5%。
- 业务增长:日均审核合同量从 1000 份 提升至 5000 份,支持业务规模快速扩张。
(二)案例二:工业缺陷智能检测系统(某汽车零部件制造商)
1. 项目背景
汽车零部件(如发动机缸体、变速箱壳体、车身冲压件)生产过程中,需对 ** 表面缺陷(划痕、裂纹、气孔、变形)** 进行全检,传统人工检测效率低(每人每日检测 500 件)、成本高(需 200 + 检测人员)、漏检率高(约 10%),影响产品质量与交付效率。
2. 解决方案
基于 Qwen3-VL-235B-A22B-Instruct-AWQ 构建工业缺陷智能检测系统,核心流程:
- 图像采集:通过高清工业相机 + 环形光源,对零部件进行360° 全方位图像采集,生成高分辨率图像(2000×2000)。
- 缺陷检测与识别:模型自动分析图像、识别缺陷位置、分类缺陷类型、评估缺陷严重程度、测量缺陷尺寸。
- 结果判定与标记:模型基于工业标准、质量规范,自动判定零部件合格 / 不合格,在图像上标记缺陷位置与信息。
- 数据存储与分析:检测结果自动存储,支持缺陷统计分析、生产质量监控、不良品溯源、工艺优化建议。
- 告警与干预:对严重缺陷、批量不良自动告警,提示生产人员及时干预,避免质量事故。
3. 部署配置
- 硬件:8×A100 80GB(PCIe),2×Xeon 8375C,1TB DDR4。
- 引擎:SGLang,AWQ 4-bit 量化,张量并行 8,支持思考模式。
- 并发:支持 200 件零部件同时检测,p99 延迟 2–3 秒 / 件。
4. 项目效果
- 效率提升:零部件检测效率从 500 件 / 人 / 日 提升至 10000 件 / 日(系统自动),效率提升 20 倍。
- 成本降低:检测人员从 200 + 人 减少至 30 人,人工成本降低 85%。
- 质量提升:缺陷漏检率从 10% 降低至 0.3%,缺陷分类准确率达 99.7%,产品合格率提升 5%。
- 工艺优化:通过缺陷数据分析,识别生产工艺薄弱环节,优化工艺参数,不良品率降低 60%。
(三)案例三:在线教育智能辅导系统(某头部在线教育平台)
1. 项目背景
平台拥有500 万 + 学生、10 万 + 课程、200 万 + 教学视频,学生学习过程中需解答作业难题、分析试卷错题、理解课程难点、生成学习笔记,传统人工辅导成本高(需 1000 + 辅导老师)、响应慢(平均 2 小时回复)、覆盖有限,学生学习体验差、学习效率低。
2. 解决方案
基于 Qwen3-VL-235B-A22B-Instruct-AWQ 构建在线教育智能辅导系统,核心功能:
- 多模态作业辅导:学生上传手写作业、试卷题目、教材图片,模型自动识别题目、解题、生成详细步骤、讲解知识点、指出错误原因。
- 试卷智能分析:上传考试试卷,模型自动批改客观题、分析主观题、统计得分情况、识别薄弱知识点、生成个性化学习报告。
- 课程视频智能笔记:学生观看教学视频时,模型自动提取关键知识点、生成结构化笔记、标注重点难点、关联相关题目。
- 实时多模态答疑:学生通过文字、图片、语音提问,模型实时理解问题、生成准确解答、结合知识点讲解、提供相关例题。
- 个性化学习推荐:基于学生学习数据、作业情况、试卷分析、薄弱知识点,模型自动推荐学习内容、练习题目、课程视频、学习计划。
3. 部署配置
- 硬件:4×H200 141GB(SXM5),2×AMD EPYC 9754,1TB DDR5。
- 引擎:vLLM,AWQ 4-bit 量化,张量并行 4,支持流式输出。
- 并发:支持 5000 + 学生同时在线辅导,p99 延迟 1–3 秒 / 次问答。
4. 项目效果
- 辅导效率提升:学生答疑响应时间从 2 小时 缩短至 1–3 秒,作业辅导效率提升 95%。
- 成本降低:辅导老师从 1000 + 人 减少至 100 人,人工成本降低 90%。
- 学习效果提升:学生作业正确率提升 30%,考试平均分提升 20 分,知识点掌握率提升 40%。
- 用户体验提升:学生满意度从 65% 提升至 92%,平台日活用户增长 50%,付费转化率提升 35%。
八、总结与未来展望
(一)总结
Qwen3-VL-235B-A22B-Instruct-AWQ 作为开源领域首款旗舰级稀疏多模态大模型,以 2350 亿总参数、220 亿激活参数、AWQ 4-bit 量化、256K 超长上下文、十大核心能力为核心优势,彻底打破了 “大模型强能力但部署难、小模型易部署但能力弱” 的行业痛点,实现了顶级推理能力、高效部署成本、企业级安全合规的完美平衡。
从技术层面看,模型创新的 MoE 稀疏架构、DeepStack 跨模态融合、AWQ 激活感知量化、双推理模式、交错式 MRoPE 五大核心技术,构建了 “能力强、效率高、部署易、适配广” 的技术底座,各项技术指标均达到开源顶尖水平,部分指标超越国际顶尖闭源模型。
从应用层面看,模型已在金融、工业、医疗、教育、政务、媒体等八大核心领域落地,通过智能视觉 Agent、文档解析、长视频分析、工业质检、医疗辅助、教育辅导等场景,为企业带来效率提升 80–95%、成本降低 70–90%、风险降低 80–95% 的显著价值,验证了模型的实用性、稳定性、可扩展性。
从行业影响看,Qwen3-VL-235B-A22B-Instruct-AWQ 的开源(Apache 2.0),为全球开发者与企业提供了免费、商用友好、性能顶尖的多模态大模型选择,推动了多模态 AI 技术的普及、产业生态的完善、应用场景的创新,加速了 AI 技术从 “实验室” 走向 “大规模商用” 的进程,助力中国 AI 产业在全球竞争中占据重要地位。
(二)未来展望
- 能力持续迭代:未来将通过更大规模高质量数据训练、更强对齐技术优化、多模态能力增强,进一步提升模型在复杂推理、细粒度视觉、长视频理解、多语言跨文化、工具调用等维度的能力,缩小与顶级闭源模型的差距,力争全面超越。
- 部署效率优化:持续优化 AWQ 量化、MoE 稀疏推理、KV Cache 管理、推理引擎适配,进一步降低模型部署的硬件门槛,目标实现 2×H100 80GB 即可部署完整版、单卡 H200 支持轻量级推理,让更多中小企业能用上旗舰级多模态 AI 能力。
- 生态完善与拓展:构建完整的模型生态,包括模型微调工具、推理部署框架、应用开发套件、行业解决方案、开发者社区,降低模型应用开发门槛,吸引更多开发者与企业参与生态建设,丰富应用场景,推动多模态 AI 技术的规模化落地。
- 安全与合规强化:进一步加强内容安全过滤、隐私保护、数据合规、伦理对齐,构建全链路安全防护体系,确保模型生成内容安全、无害、合规、符合人类价值观,满足金融、医疗、政务等隐私敏感场景的严格要求。
- 多模态融合创新:探索文本、图像、视频、音频、3D 点云、传感器数据的深度融合,拓展具身智能、机器人控制、虚拟现实、数字孪生、自动驾驶等前沿应用场景,推动 AI 从 “感知智能” 向 “认知智能、具身智能” 跨越,开启多模态 AI 技术的新时代。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 10
10 0
0- 0



 已为社区贡献60条内容
已为社区贡献60条内容

所有评论(0)