什么是 transformer?它能用来做什么?
Transformer 是一种完全基于“自注意力机制”构建的神经网络架构,是当前几乎所有顶尖大模型(如 GPT、BERT、LLaMA)的核心引擎。它的革命性在于用纯注意力机制取代了传统的循环(RNN)和卷积(CNN)结构,从而能高效并行处理整个序列,并捕获长距离依赖关系。
Transformer 是 Google 于 2017 年提出的、完全基于「自注意力机制」的深度学习架构,它放弃了传统 RNN/LSTM 的串行结构,能并行计算、捕捉长距离依赖,是当前大语言模型(GPT、BERT 等)与多模态模型的核心基础。
一、它是什么(核心原理)
1. 整体结构:Encoder + Decoder
- Encoder(编码器):负责理解输入(如原文、图片),提取上下文特征。
- Decoder(解码器):负责生成输出(如译文、回答、图片),逐词 / 逐像素生成结果。
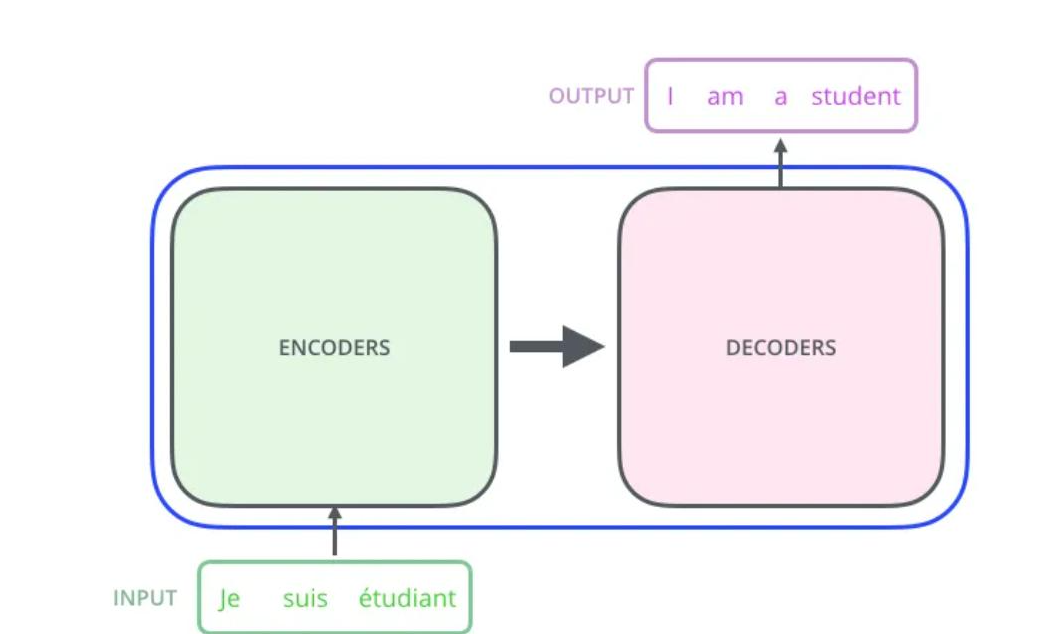
2. 灵魂:自注意力(Self-Attention)
让每个元素(如每个词)直接关注序列中所有其他元素,计算关联权重,从而:
- 捕获长距离依赖(比如长句子中前后词的关系);
- 支持并行计算(RNN 必须从头往后算,Transformer 可全局同时算)。通俗理解:
- 每个词生成 3 个向量:Q(我要找什么)、K(我有什么)、V(我输出什么);
- 计算 Q 与所有 K 的相似度 → 加权求和 V → 得到该词的新表示。
3. 关键组件
- 多头注意力(Multi-Head Attention):并行多个注意力头,捕捉不同类型的依赖(语法、语义、指代)。
- 位置编码(Positional Encoding):给元素加上位置信息,弥补自注意力本身无顺序的缺陷。
- 残差连接 + 层归一化:稳定深层网络训练,避免梯度消失。
二、它能用来做什么(核心应用)
Transformer 已从 NLP 扩展到CV、语音、多模态等几乎所有 AI 领域。
1. 自然语言处理(NLP)—— 最成熟
- 文本生成:GPT、LLaMA、ChatGPT(写文章、聊天、代码生成);
- 理解类任务:BERT(情感分析、问答、实体识别);
- 机器翻译:Google Translate、DeepL;
- 摘要 / 改写 / 润色:自动生成摘要、扩写、改写。
2. 计算机视觉(CV)
- 图像分类 / 检测 / 分割:ViT(Vision Transformer)、Swin Transformer;
- 多模态检索:CLIP(文搜图、图搜文);
- 图像生成:DALL・E、Midjourney(底层用 Transformer + Diffusion)。
3. 多模态(文本 + 图像 + 语音 + 视频)
- GPT-4V、Gemini、通义千问:图文对话、看图推理、视频理解;
- 语音识别 / 合成:Whisper、TTS 模型;
- 时序预测:股票、天气、设备故障预测。
4. 其他领域
- 推荐系统:捕捉用户 - 物品的复杂关联;
- 生物医学:蛋白质结构预测(AlphaFold2)、药物分子建模。
三、为什么它这么重要
- 并行高效:训练速度远快于 RNN/LSTM,支撑大模型规模化;
- 长距离建模:能处理超长文本(如 GPT-4 支持 128k 上下文);
- 通用灵活:一套架构适配文本、图像、语音、视频,催生多模态统一模型;
- 可扩展性强:参数可从亿级扩展到万亿级,能力随数据 / 算力持续提升。
想象你在读一句话:“The animal didn’t cross the street because it was too tired”。当你看到 it时,模型如何知道它指的是 animal而不是 street?自注意力机制会让模型在编码 it时,去“注意”句子中的所有其他词,并为每个词分配一个权重分数,从而确定 it和 animal的关系最紧密。
核心公式:
自注意力 = Softmax( (QK^T) / √d_k ) V
这里 Q, K, V分别是“查询”、“键”、“值”矩阵,均由输入通过线性变换得到。这个公式的本质是用每个词去查询(Query)所有词的关键信息(Key),然后根据相关性权重汇总值(Value)。
下面是一个完整的、可运行的简易 Transformer 模型,用于“序列到序列”任务(如机器翻译)。它包含了编码器、解码器、多头注意力等核心组件。
import torch
import torch.nn as nn
import torch.nn.functional as F
import math
class MultiHeadAttention(nn.Module):
""" 多头自注意力机制 """
def __init__(self, d_model, num_heads):
super().__init__()
self.d_model = d_model
self.num_heads = num_heads
self.d_k = d_model // num_heads
# 线性变换层,用于生成 Q, K, V
self.W_q = nn.Linear(d_model, d_model)
self.W_k = nn.Linear(d_model, d_model)
self.W_v = nn.Linear(d_model, d_model)
self.W_o = nn.Linear(d_model, d_model)
def scaled_dot_product_attention(self, Q, K, V, mask=None):
# 计算注意力分数: (Q * K^T) / sqrt(d_k)
scores = torch.matmul(Q, K.transpose(-2, -1)) / math.sqrt(self.d_k)
# 应用掩码(用于解码器)
if mask is not None:
scores = scores.masked_fill(mask == 0, -1e9)
# Softmax 得到权重
attn_weights = F.softmax(scores, dim=-1)
# 加权求和
output = torch.matmul(attn_weights, V)
return output, attn_weights
def forward(self, Q, K, V, mask=None):
batch_size = Q.size(0)
# 1. 线性变换并分头
Q = self.W_q(Q).view(batch_size, -1, self.num_heads, self.d_k).transpose(1, 2)
K = self.W_k(K).view(batch_size, -1, self.num_heads, self.d_k).transpose(1, 2)
V = self.W_v(V).view(batch_size, -1, self.num_heads, self.d_k).transpose(1, 2)
# 2. 计算注意力
attn_output, attn_weights = self.scaled_dot_product_attention(Q, K, V, mask)
# 3. 合并多头
attn_output = attn_output.transpose(1, 2).contiguous().view(
batch_size, -1, self.d_model
)
# 4. 输出线性变换
output = self.W_o(attn_output)
return output, attn_weights
class TransformerEncoderLayer(nn.Module):
""" 单个Transformer编码器层 """
def __init__(self, d_model, num_heads, d_ff, dropout=0.1):
super().__init__()
self.self_attn = MultiHeadAttention(d_model, num_heads)
self.feed_forward = nn.Sequential(
nn.Linear(d_model, d_ff),
nn.ReLU(),
nn.Linear(d_ff, d_model)
)
self.norm1 = nn.LayerNorm(d_model)
self.norm2 = nn.LayerNorm(d_model)
self.dropout = nn.Dropout(dropout)
def forward(self, x, mask=None):
# 1. 多头自注意力 + 残差连接 + 层归一化
attn_output, _ = self.self_attn(x, x, x, mask)
x = self.norm1(x + self.dropout(attn_output))
# 2. 前馈网络 + 残差连接 + 层归一化
ff_output = self.feed_forward(x)
x = self.norm2(x + self.dropout(ff_output))
return x
class SimpleTransformer(nn.Module):
""" 一个简易的Transformer(仅编码器)"""
def __init__(self, vocab_size, d_model=512, num_layers=6,
num_heads=8, d_ff=2048, dropout=0.1, max_len=100):
super().__init__()
self.embedding = nn.Embedding(vocab_size, d_model)
self.pos_encoding = self.create_positional_encoding(max_len, d_model)
# 堆叠多层编码器
self.layers = nn.ModuleList([
TransformerEncoderLayer(d_model, num_heads, d_ff, dropout)
for _ in range(num_layers)
])
self.fc_out = nn.Linear(d_model, vocab_size)
def create_positional_encoding(self, max_len, d_model):
""" 创建正弦位置编码 """
pe = torch.zeros(max_len, d_model)
position = torch.arange(0, max_len, dtype=torch.float).unsqueeze(1)
div_term = torch.exp(torch.arange(0, d_model, 2).float() *
-(math.log(10000.0) / d_model))
pe[:, 0::2] = torch.sin(position * div_term)
pe[:, 1::2] = torch.cos(position * div_term)
return pe.unsqueeze(0) # (1, max_len, d_model)
def forward(self, x):
# 词嵌入 + 位置编码
x = self.embedding(x) + self.pos_encoding[:, :x.size(1), :]
# 通过多层编码器
for layer in self.layers:
x = layer(x)
# 输出层
output = self.fc_out(x)
return output
# ==================== 示例:如何使用 ====================
if __name__ == "__main__":
# 超参数
vocab_size = 10000 # 假设词汇表大小
d_model = 512 # 模型维度
seq_len = 20 # 输入序列长度
# 1. 实例化模型
model = SimpleTransformer(vocab_size, d_model, num_layers=3)
print(f"模型参数量: {sum(p.numel() for p in model.parameters()):,}")
# 2. 创建模拟输入
input_ids = torch.randint(0, vocab_size, (4, seq_len)) # (batch_size, seq_len)
print(f"输入形状: {input_ids.shape}")
# 3. 前向传播
output = model(input_ids)
print(f"输出形状: {output.shape}") # 应为 (4, 20, 10000)
# 4. 计算损失(模拟训练)
target_ids = torch.randint(0, vocab_size, (4, seq_len))
loss_fn = nn.CrossEntropyLoss()
loss = loss_fn(output.view(-1, vocab_size), target_ids.view(-1))
print(f"损失值: {loss.item():.4f}")四、关键组件说明
|
组件 |
作用 |
类比 |
|---|---|---|
|
位置编码 |
为模型提供词的顺序信息(因注意力机制本身无视顺序)。 |
给每个词加上“座位号”。 |
|
多头注意力 |
让模型从多个角度(语义、语法、指代等)同时理解关系。 |
多个专家从不同角度分析句子。 |
|
前馈网络 |
对注意力后的信息进行非线性变换,增强表达能力。 |
大脑对信息进行深度加工。 |
|
残差连接 |
缓解深层网络梯度消失,让模型更容易训练。 |
保留原始信息,只学习差异。 |
|
层归一化 |
稳定训练过程,加速收敛。 |
保持每层输出的稳定分布。 |
运行结果示例:
模型参数量: 13,828,104
输入形状: torch.Size([4, 20])
输出形状: torch.Size([4, 20, 10000])
损失值: 9.2103这个简易模型涵盖了 Transformer 的核心思想。在实际中,完整的 Transformer 还包含解码器、掩码机制、更复杂的位置编码等。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 5
5 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)