人工智能篇---MoE模型架构
一、什么是 MoE 模型架构?
MoE(Mixture of Experts,混合专家模型) 是一种通过稀疏激活来扩展模型容量的神经网络架构设计。
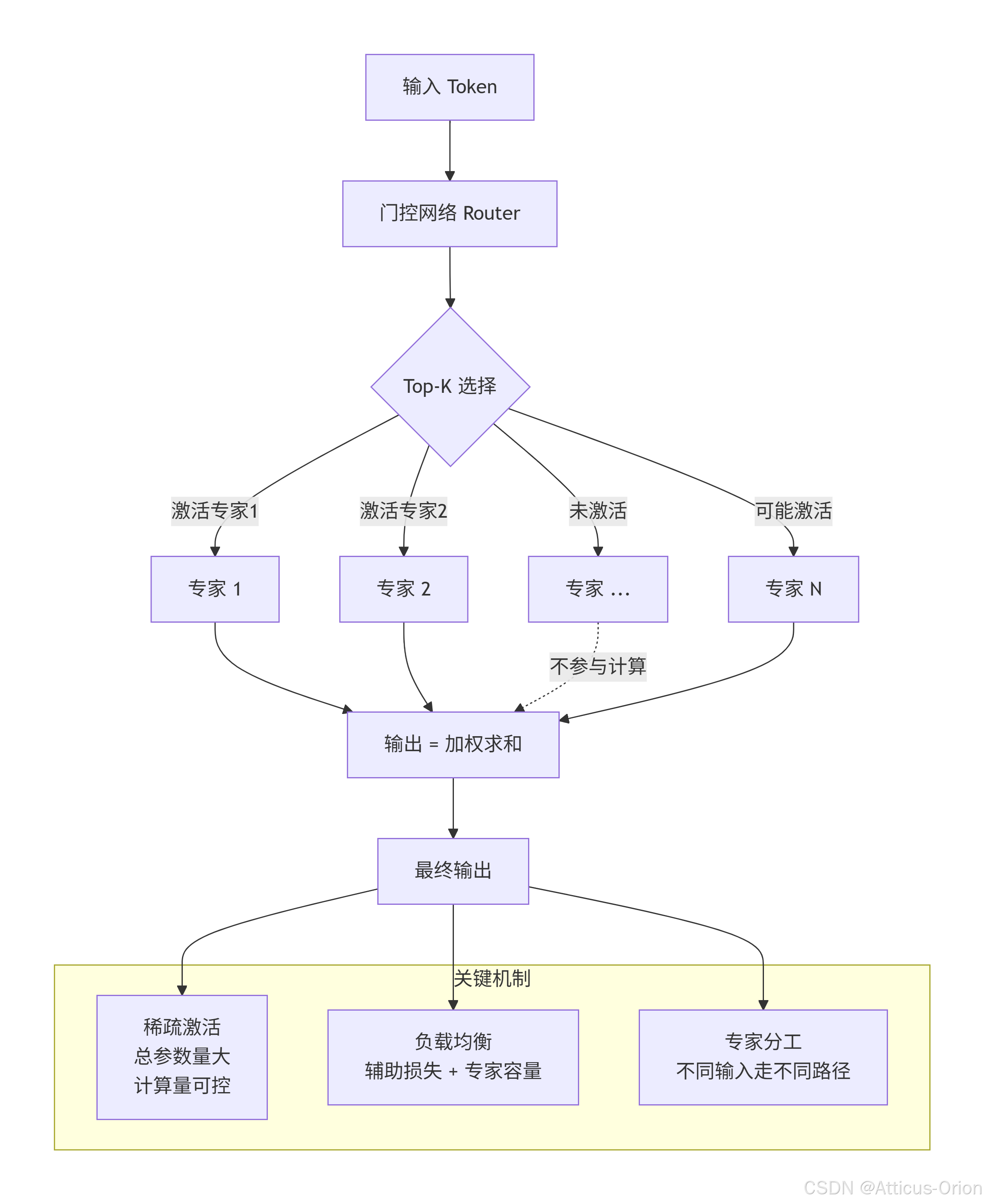
核心思想是:不用一个“全才”网络处理所有输入,而是让多个“专家子网络”各自擅长不同领域,再由一个路由机制(门控网络)为每个输入动态选择最合适的少数专家进行计算。
关键特点:
-
总参数量巨大(可以做到万亿级别)
-
每次前向传播只激活一小部分专家(计算量可控)
-
不同输入走不同路径(条件计算)
二、为什么需要 MoE?
| 传统密集模型的瓶颈 | MoE 的突破 |
|---|---|
| 增加参数量 → 计算量等比例增加 | 参数量暴涨,计算量仅缓慢增长 |
| 所有 token 平等消耗算力 | 简单 token 轻量处理,复杂 token 动用更多专家 |
| 模型容量受限于训练/推理成本 | 千亿/万亿参数部署成为可能 |
| 单一网络难以覆盖海量异构知识 | 不同专家学习不同模式/领域 |
一句话:MoE 让你拥有一个“超级大脑”,但每次思考只用其中几个“最擅长的脑区”。
三、MoE 的核心组件
1. 专家网络(Experts)
-
通常是相同的 FFN(前馈网络)结构
-
每个专家独立学习数据的不同子空间/模式
-
数量从几个到数千个不等(如 Mixtral 8×7B 用了 8 个专家)
2. 门控网络 / 路由(Gating Network / Router)
-
一个可训练的小型网络
-
输入:当前 token 的表示
-
输出:每个专家的权重分数(通常用 Softmax)
-
决定 token 分配给哪些专家(Top-K 选择)
3. 负载均衡机制(Load Balancing)
-
防止少数专家被过度使用,多数专家闲置
-
常用技术:
-
辅助损失(auxiliary loss)惩罚不均衡分配
-
专家容量限制(expert capacity)
-
随机路由 / 噪声注入
-
四、MoE 的计算流程
对于一个输入 token x:
-
路由计算:
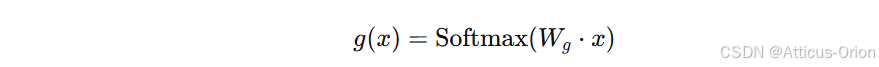
得到每个专家的权重 g1,g2,...,gE
-
选择 Top-K 专家(K 通常为 1、2 或 4):
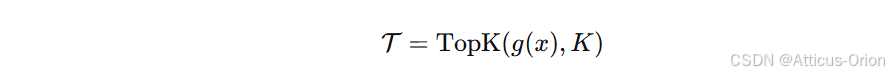
-
加权求和输出:
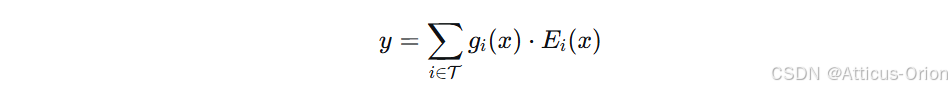
其中 Ei(x) 是第 i 个专家的输出
未选中的专家不参与计算 → 稀疏激活
五、MoE 在 Transformer 中的应用(主流方案)
现代大模型通常将 MoE 应用在 FFN 层(替换原来的单一 FFN):
Token → Attention → MoE-FFN(多个专家,每次选 2 个)→ 下一层
代表模型:
-
Mixtral 8×7B(Mistral AI):8 个专家,每次选 2 个,总参数 46.7B,激活参数 12.9B
-
DeepSeek-MoE:细粒度专家分割 + 共享专家隔离
-
GShard(Google):MoE 在 Transformer 中的经典实现
-
Switch Transformer:每次只选 1 个专家(极稀疏)
-
Qwen-MoE(阿里):集成 MoE 的千问系列
六、MoE 的关键挑战与解决方案
| 挑战 | 解决方案 |
|---|---|
| 专家负载不均衡 | 辅助损失 + 专家容量 + 专家丢弃(dropped tokens) |
| 训练不稳定 | 梯度裁剪、路由器 Softmax 温度调节 |
| 推理内存大 | 专家并行 + 模型量化 + 推测性专家加载 |
| 通信开销大(多卡) | 专家并行 + All-to-All 通信优化 |
| 微调困难 | Router 冻结 + 专家微调 / MoE-LoRA |
七、与传统密集模型的对比
| 维度 | 密集模型 | MoE 模型 |
|---|---|---|
| 总参数量 | N | N × E(E 专家数) |
| 激活参数(每 token) | N | N × K/E(K 为激活专家数) |
| 计算量 | 高 | 可控(远低于总参数量) |
| 知识容量 | 受限 | 极大(专家分工) |
| 训练难度 | 较低 | 较高(需要负载均衡) |
| 推理成本 | 随参数量线性增长 | 远低于同等总参数模型 |
八、Mermaid 总结框图
九、实际应用场景
-
超大语言模型(Mixtral、DeepSeek-MoE)
— 以可控成本达到更大参数量的效果 -
多语言模型
— 不同专家处理不同语言族,避免干扰 -
多任务学习
— 专家自然分化到不同任务类型 -
代码生成 + 自然语言
— 语法专家 vs 语义专家分工协作 -
推荐系统
— 用户/物品专家切分,实时路由
十、总结一句话
MoE 是一种“人多力量大但每次只派精锐”的模型架构,它将模型容量与计算成本解耦,让万亿参数大模型的训练和部署成为可能。
如果你愿意,我可以继续为你画一个 MoE 在一个 Transformer 层内部的详细结构图,或者对比 MoE 与 Dense 模型在训练推理时的显存/计算差异表。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 15
15 0
0- 0



 已为社区贡献65条内容
已为社区贡献65条内容

所有评论(0)