人工智能篇---超轻量适配器
一、什么是超轻量适配器?
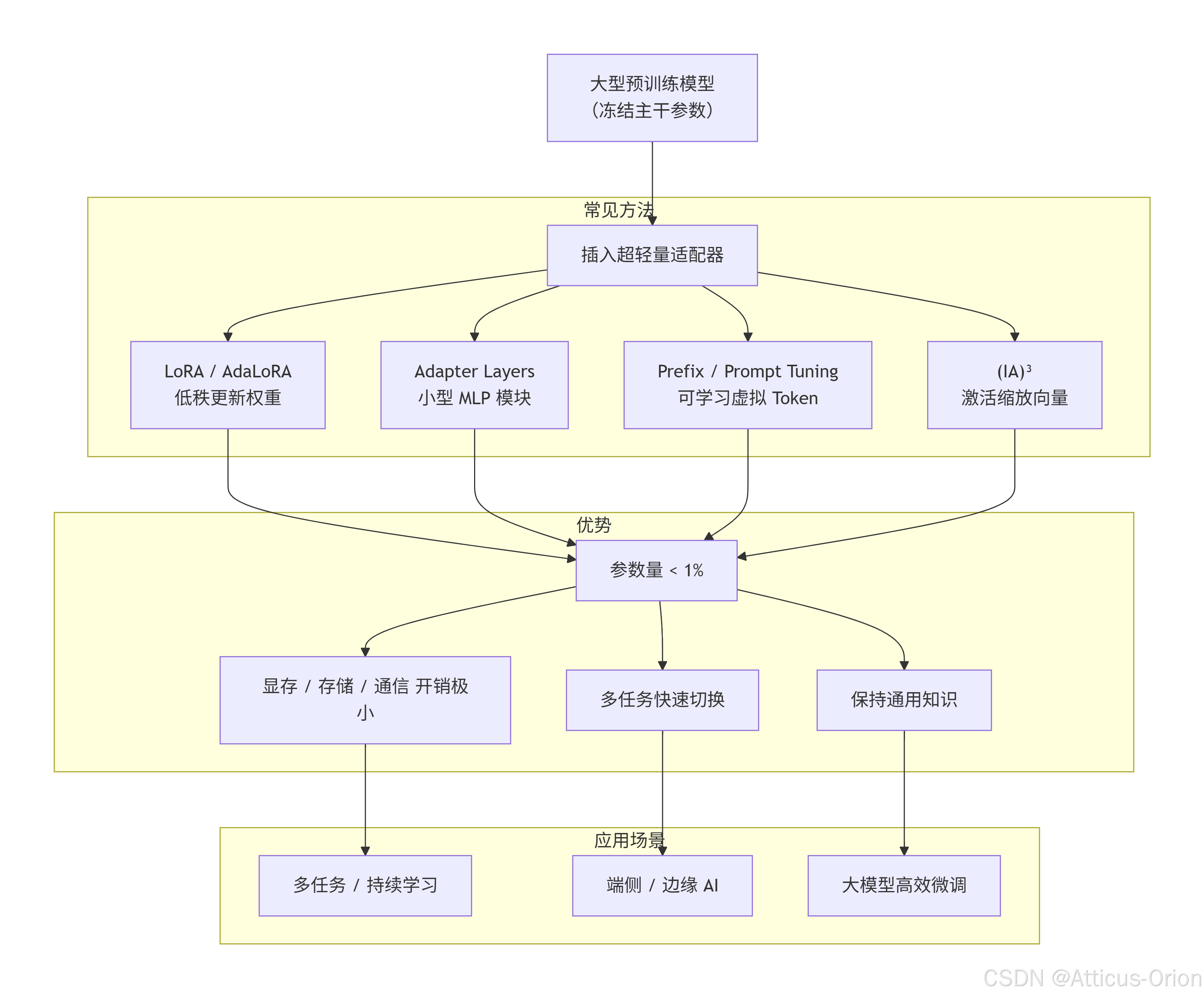
超轻量适配器(Ultra-Light Adapter) 是一种在大型预训练模型(PLM)基础上进行参数高效微调(PEFT)的技术。
其核心思想是:不修改原模型的大部分参数,而是在模型内部插入极少量可训练的小模块(适配器),通过只训练这些模块来使模型适应下游任务。
“超轻量”主要体现在:
-
相比全量微调,参数量极少(通常 < 1% 原模型参数)
-
存储、传输、切换任务非常轻便
-
训练显存和计算需求大幅降低
二、为什么需要超轻量适配器?
| 传统微调问题 | 超轻量适配器的解决方式 |
|---|---|
| 每个任务存一份完整模型(如 7B~175B 参数) | 只需存一个小适配器文件(MB 级别) |
| 训练需要大量 GPU 显存 | 冻结主干模型,只更新适配器层,显存大幅降低 |
| 多任务部署麻烦 | 一个主干模型 + 多个任务适配器,动态切换 |
| 容易灾难性遗忘 | 主干参数不变,始终保持通用能力 |
因此,超轻量适配器特别适合:
-
多任务、多场景的 AI 系统
-
边缘计算 / 端侧部署
-
快速实验多种下游任务
三、常见实现方法对比
| 类型 | 代表方法 | 参数量 | 原理 |
|---|---|---|---|
| Adapter-based | AdaptMLP, AdapterFusion | ~0.5%~5% | 在 Transformer 层间插入小型 MLP 模块 |
| LoRA 及其变体 | LoRA, AdaLoRA, QLoRA | ~0.1%~1% | 低秩矩阵近似更新权重 ΔW |
| Prefix / Prompt Tuning | Prefix Tuning, P-Tuning v2 | ~0.01%~0.5% | 在输入端添加可学习的虚拟 token |
| (IA)³ | (Infused Adapter by Inhibiting and Amplifying Inner Activations) | 极轻 (< 0.01%) | 学习向量 rescale 激活值 |
广义上,LoRA 也被视为一种“适配器模式”,虽然不叫 adapter,但思维一致。
四、核心技术原理(以 LoRA 为例)
对于预训练权重矩阵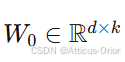
LoRA 不直接全量更新 ![]() ,而是:
,而是:
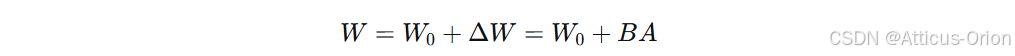
其中:
-
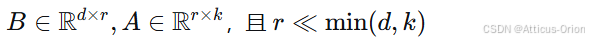
-
训练时只更新 A,B,冻结
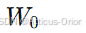
为什么轻量:
-
如果 d=k=4096,r=8,原矩阵参数量 = 16M,LoRA 参数量 = 4096×8+8×4096=65,536
仅原来的 0.4%
五、典型使用流程
-
加载预训练主干模型并冻结
-
在所有(或部分)注意力层 / FFN 层插入适配器模块
-
只训练适配器参数
-
推理时:主干 + 选定任务的适配器
-
切换任务:卸载当前适配器,加载另一个(无需重新加载主干)
六、优缺点总结
✅ 优点:
-
极大节省显存和存储
-
支持快速任务切换
-
缓解灾难性遗忘
-
易于分布式 / 端侧部署
⚠️ 局限:
-
效果可能略低于全量微调(但差距常在 1~2% 内)
-
超低参数量(如 r=1~4)在复杂任务上可能不足
-
推理时需额外计算适配器路径(但对现代硬件影响很小)
七、Mermaid 总结框图
八、一句话总结
超轻量适配器是一种让大模型“学会多种技能”却几乎不增加存储与计算负担的微调范式,是现代大模型应用落地的重要工程思想。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 3
3 0
0- 0



 已为社区贡献73条内容
已为社区贡献73条内容

所有评论(0)