SlurmInsight:让 Slurm 集群管理告别终端!
还在用
scontrol和sinfo手动查集群状态?SlurmInsight 是一款专为 Slurm 调度系统打造的 Web 可视化监控平台。从仪表盘到节点热图,从作业队列到历史趋势,让 HPC 集群管理像看仪表盘一样简单。即将开源,敬请关注!
一、HPC 运维的「黑屏困境」
在高校超算中心、科研院所和企业研发部门的日常工作中,Slurm 作业调度系统是高性能计算(HPC)集群的标配。当你管理着一个拥有 233 个计算节点、近 17000 个 CPU 核心、253 张 GPU 卡的大型集群时,你是不是也经常这样:
- 在黑屏终端里反复敲
sinfo、squeue、scontrol,一眼看不到全局资源使用率 - 用户的作业 pending 了,却不知道是因为资源不足、优先级不够还是队列配置问题
- 某个节点挂了,要从几百行
sinfo -R输出里翻找异常原因 - 想分析集群的历史负载趋势,发现没有任何可视化工具可用
今天,给大家介绍一款我近期开发的开源 Slurm 集群监控平台 —— SlurmInsight。它基于现代 Web 技术构建,旨在将复杂的 Slurm 集群管理,变成一目了然的可视化体验。
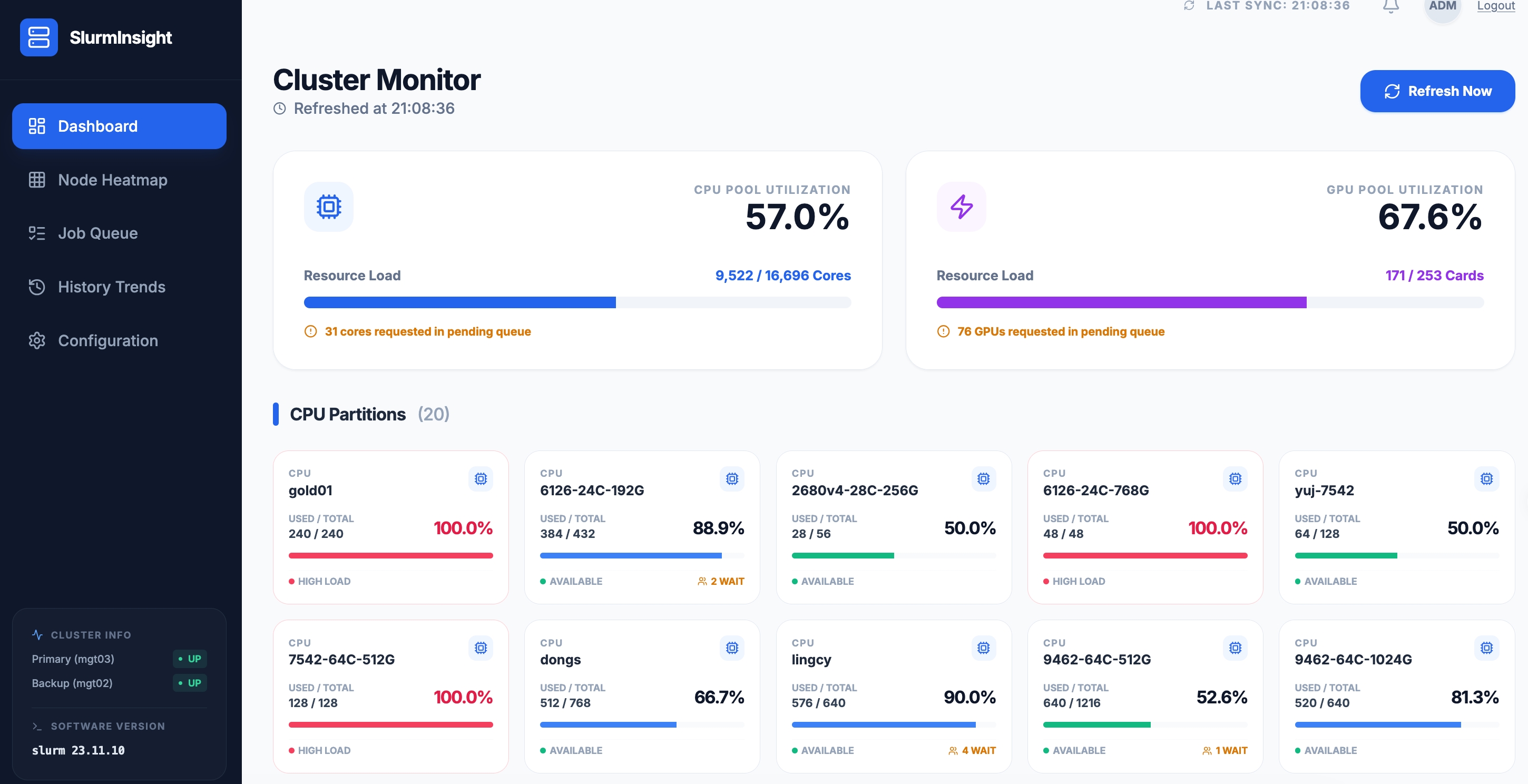
二、集群仪表盘:资源全貌尽收眼底
打开 SlurmInsight 的第一眼,就是集群仪表盘。这里用卡片式布局展示了最核心的资源指标:
| 指标 | 数值 | 说明 |
|---|---|---|
| CPU Pool Utilization | 57.0% | 9522 / 16696 核心 |
| GPU Pool Utilization | 67.6% | 171 / 253 显卡 |
| Pending CPU Cores | 31 | 队列中等待的 CPU 核心申请 |
| Pending GPUs | 76 | 队列中等待的 GPU 卡申请 |
仪表盘下方是 20 个 CPU 分区的实时负载柱状图。每个分区卡片清晰展示了 used/total 核心数、使用率百分比,以及状态标识(AVAILABLE / HIGH LOAD / WAIT)。一眼就能看出哪些分区已满负荷、哪些还有余量。
对于管理员来说,这意味着不再需要写脚本解析 sinfo 输出,打开浏览器就能看到全局资源水位。
三、节点热图:233 个节点的「健康地图」
如果说仪表盘看的是全局,那节点热图看的就是个体。
3.1 状态视图 —— 一眼发现异常节点
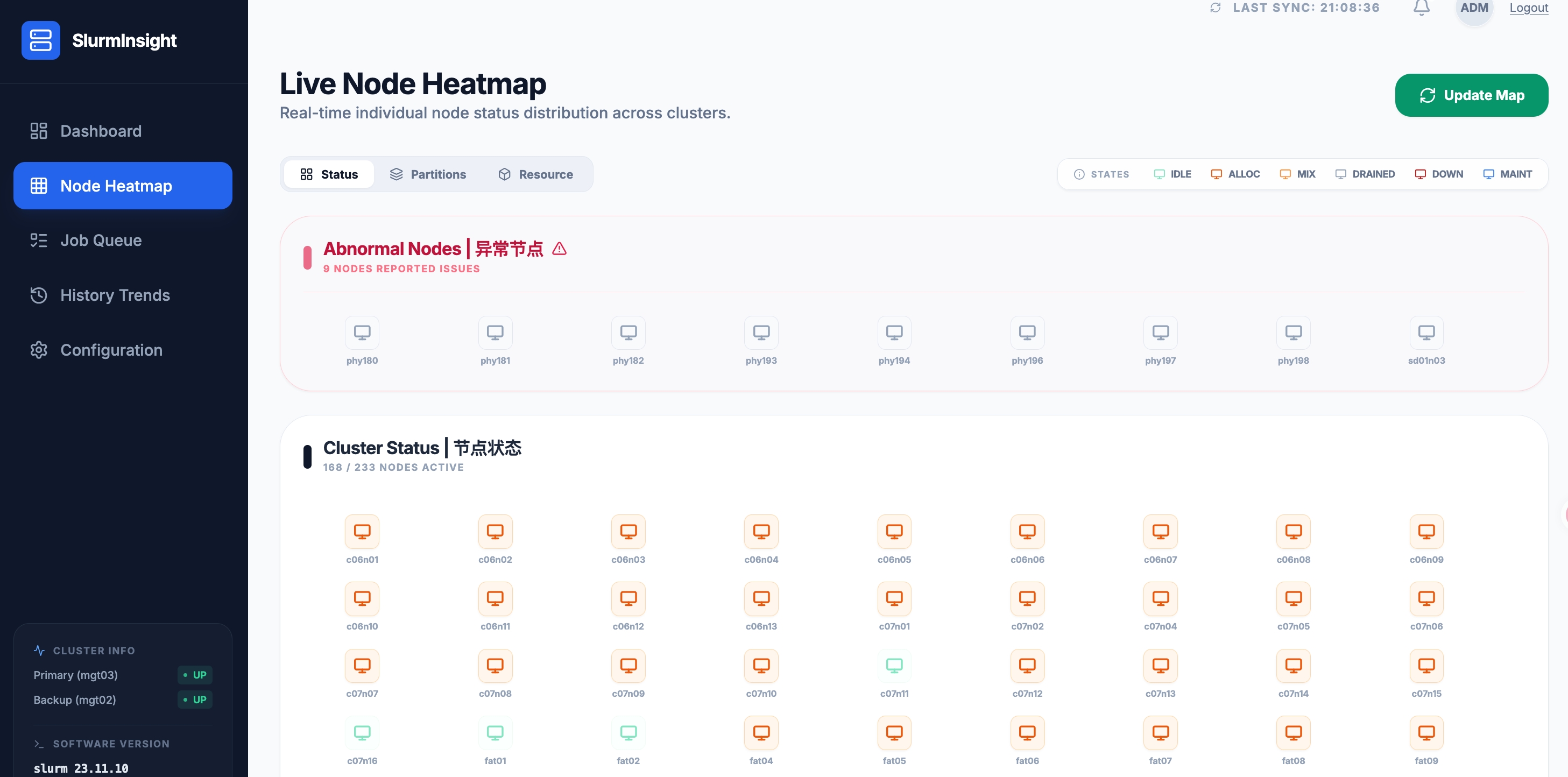
节点热图的 Status 标签页将所有节点以网格形式铺开展示:
- IDLE — 空闲可用
- ALLOC — 全部分配
- MIX — 部分使用
- DOWN — 故障离线
- DRAINED — 已排空
- MAINT — 维护模式
顶部特别标注了 Abnormal Nodes | 异常节点 区域,9 个报告问题的节点(phy180 ~ phy198, sd10n03)直接高亮呈现。不用翻日志,异常节点无所遁形。
3.2 分区视图 —— 按队列组织节点
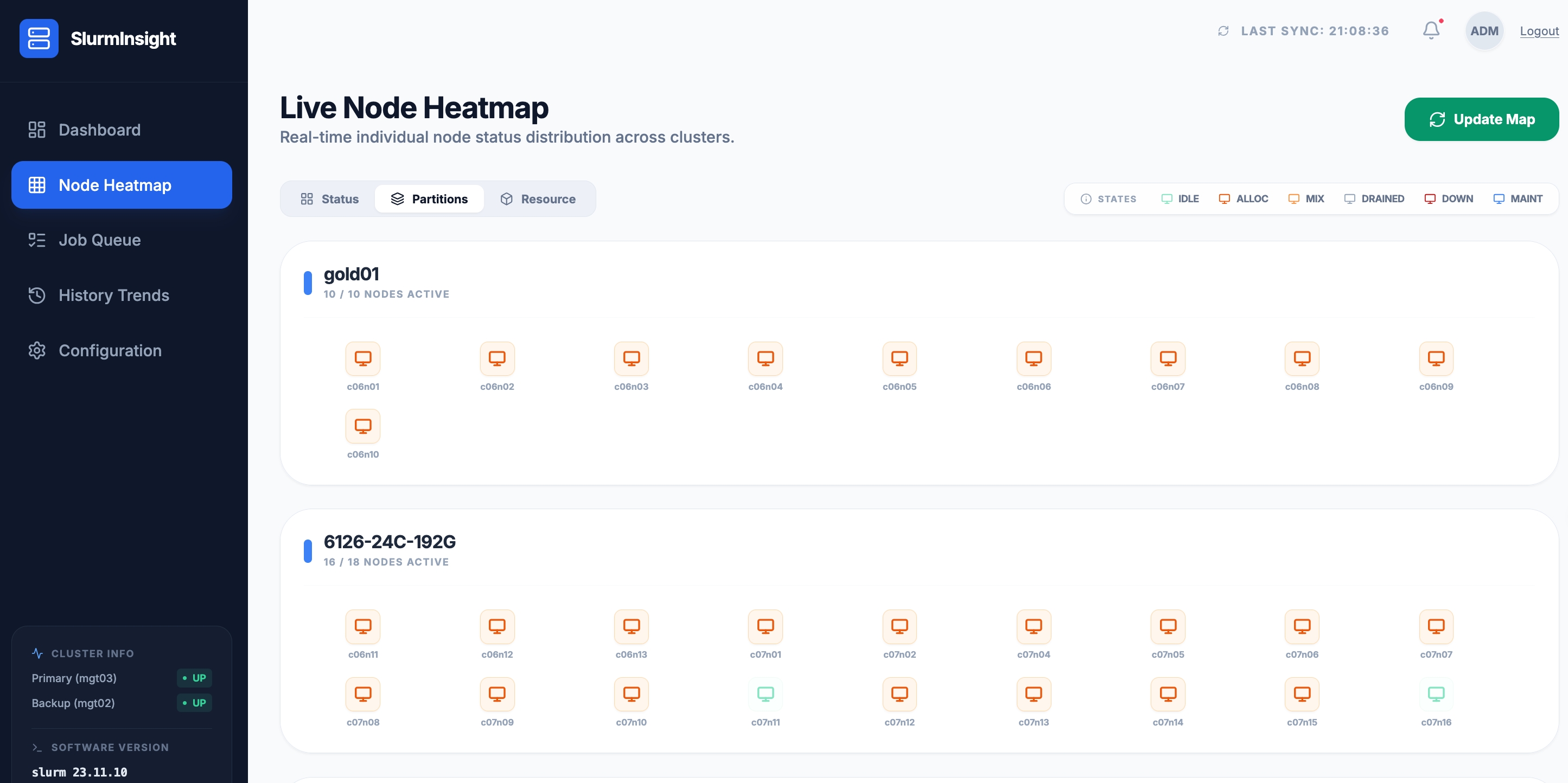
Partitions 标签页将节点按 Slurm 分区(Partition)分组展示。比如 gold01 分区 10 个节点全部在线,6126-24C-192G 分区 16/18 个节点活跃。这种视图特别适合按硬件配置批次管理节点。
3.3 资源视图 —— CPU / GPU 分组一目了然
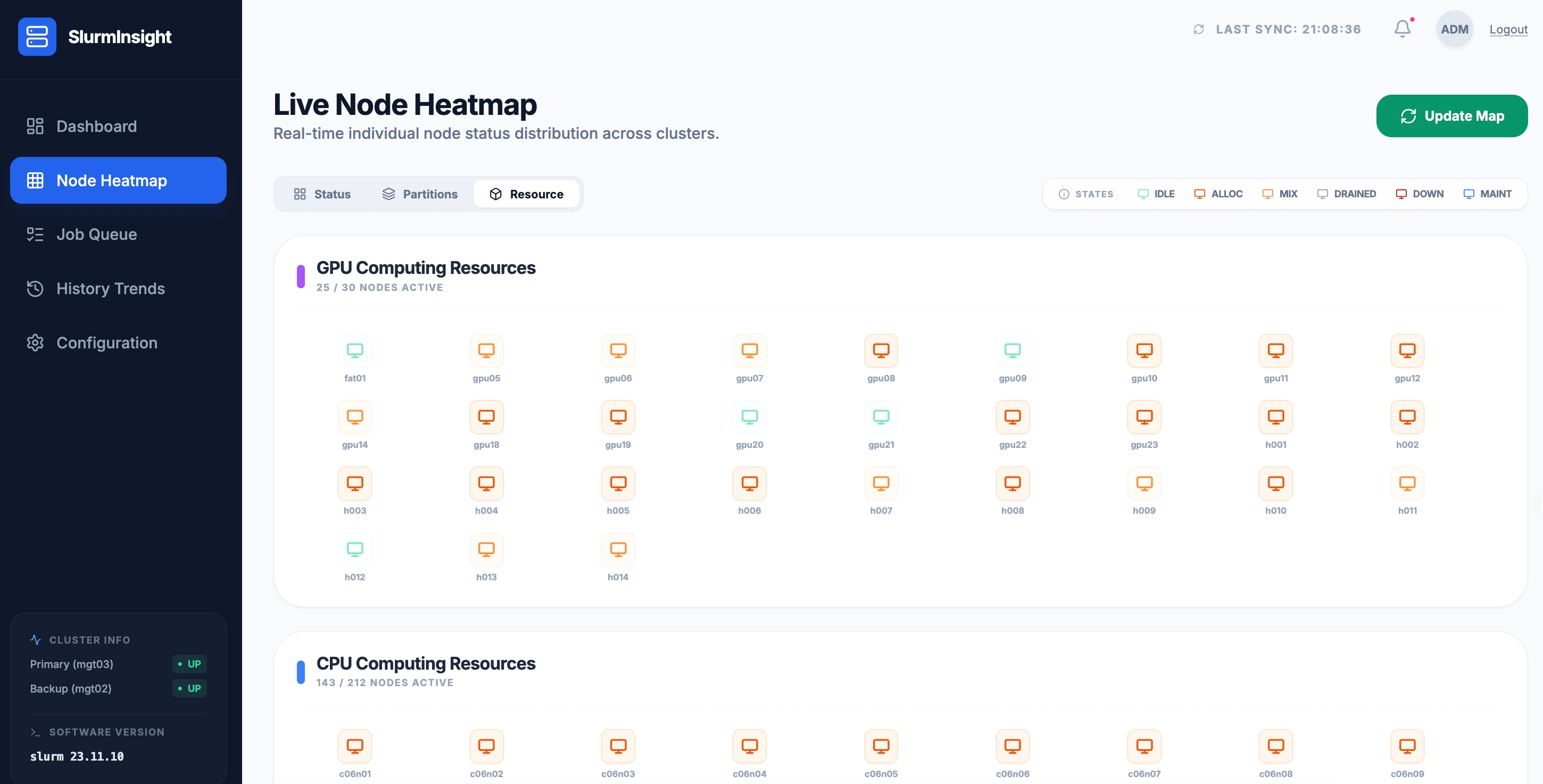
Resource 标签页则将节点按计算资源类型分为 GPU Computing 和 CPU Computing 两大类。GPU 节点(gpu05-gpu14、h001-h014 等)和 CPU 节点(c06n01-c06n09 等)分别展示,异构集群的管理也变得清晰有序。
四、作业队列:每一条作业的来龙去脉
4.1 全局队列 —— 427 条作业实时追踪
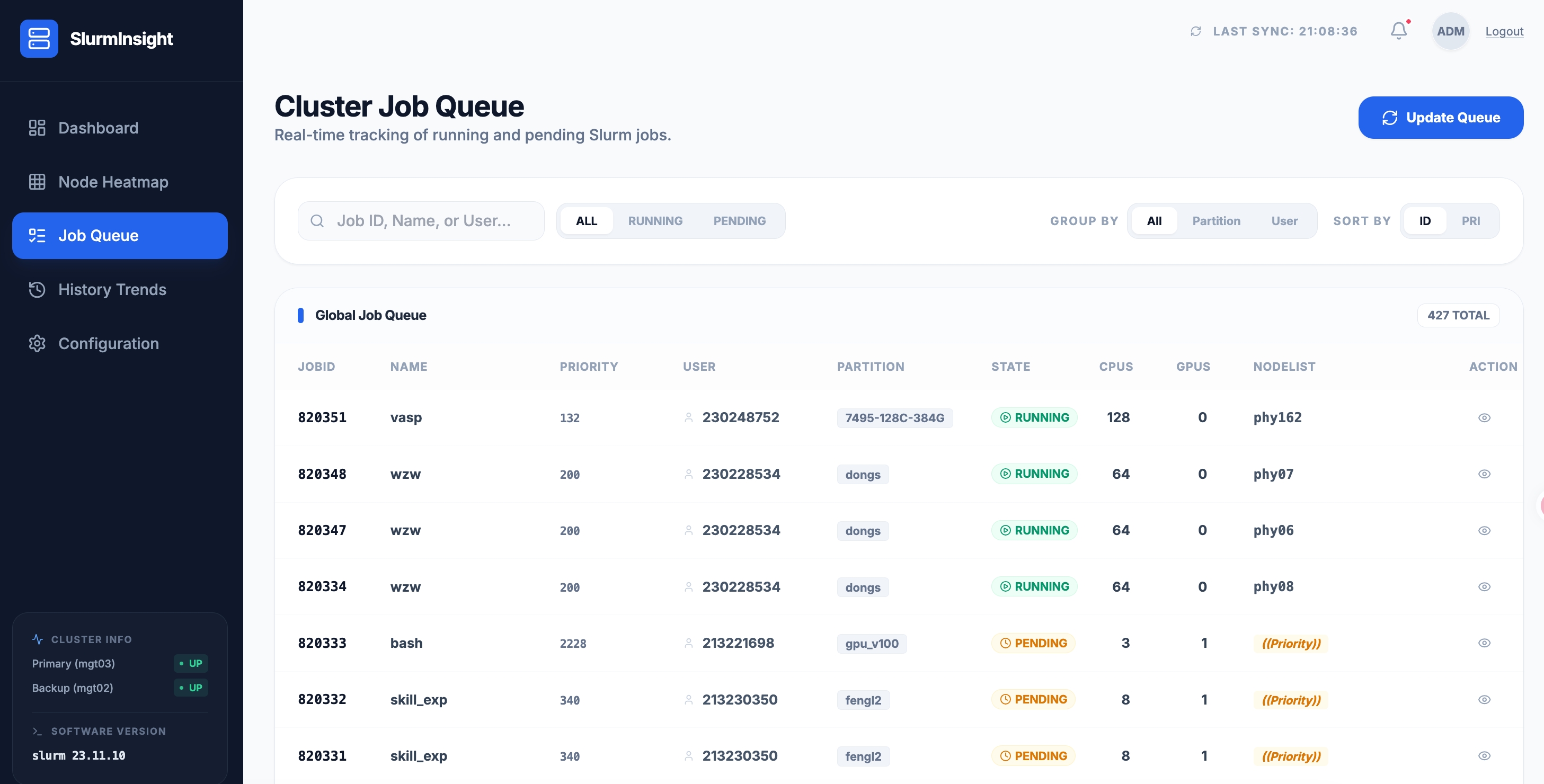
Job Queue 模块实时追踪集群中的所有作业。当前集群共有 427 条作业,列表中清晰展示每条作业的:
- JOBID / NAME — 作业标识与名称(如 vasp、wzw、bash、skill_exp)
- PRIORITY — 调度优先级(132 ~ 2228 不等)
- USER — 提交用户
- PARTITION — 运行分区(如 dongs、gpu_v100、fengli2)
- STATE — 状态(RUNNING / PENDING)
- CPUS / GPUS — 申请的 CPU/GPU 资源数
- NODELIST — 分配的节点(如 phy162、phy87)
支持 搜索(Job ID、Name、User)、状态筛选(ALL / RUNNING / PENDING)、分组(By Partition / User)、排序(By ID / PRI),管理员可以快速定位任何一条作业。
4.2 作业详情 —— 点击即见的深度信息
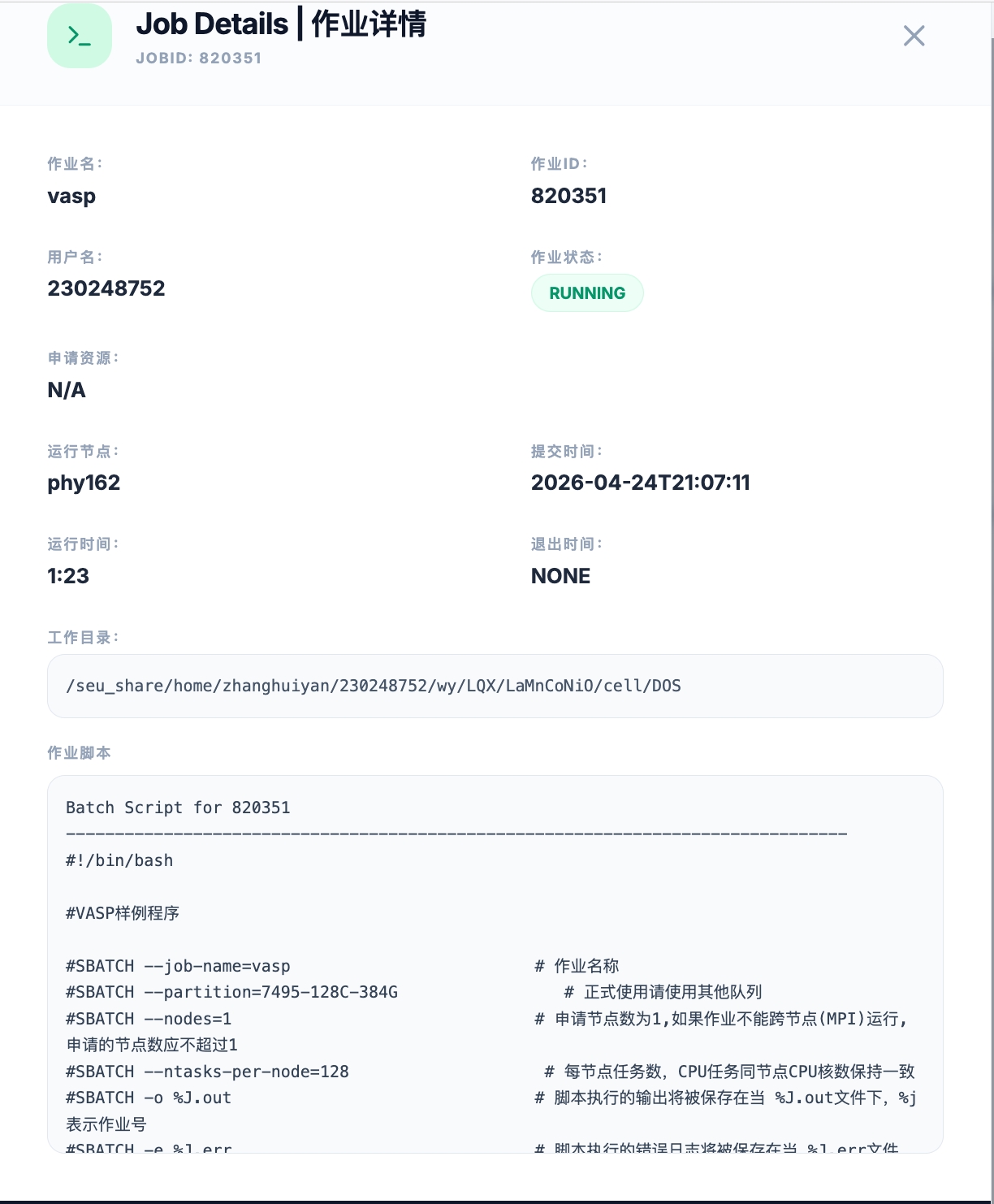
点击任意一条作业,弹出 作业详情 面板:
| 字段 | 内容 |
|---|---|
| 作业名 | vasp |
| 作业 ID | 820351 |
| 用户名 | 230248752 |
| 作业状态 | RUNNING |
| 申请资源 | N/A(自动分配) |
| 运行节点 | phy162 |
| 提交时间 | 2026-04-24T21:07:11 |
| 运行时间 | 1:23 |
| 工作目录 | /seu_share/home/... |
| 作业脚本 | 完整的 #SBATCH 批处理脚本 |
用户再也不用反复执行 scontrol show job=xxx 了,点击一下,这条作业的所有信息尽收眼底。甚至连原始的 SBATCH 提交脚本 都完整展示,方便管理员排查配置问题。
4.3 PENDING 视图 —— 排队原因一目了然
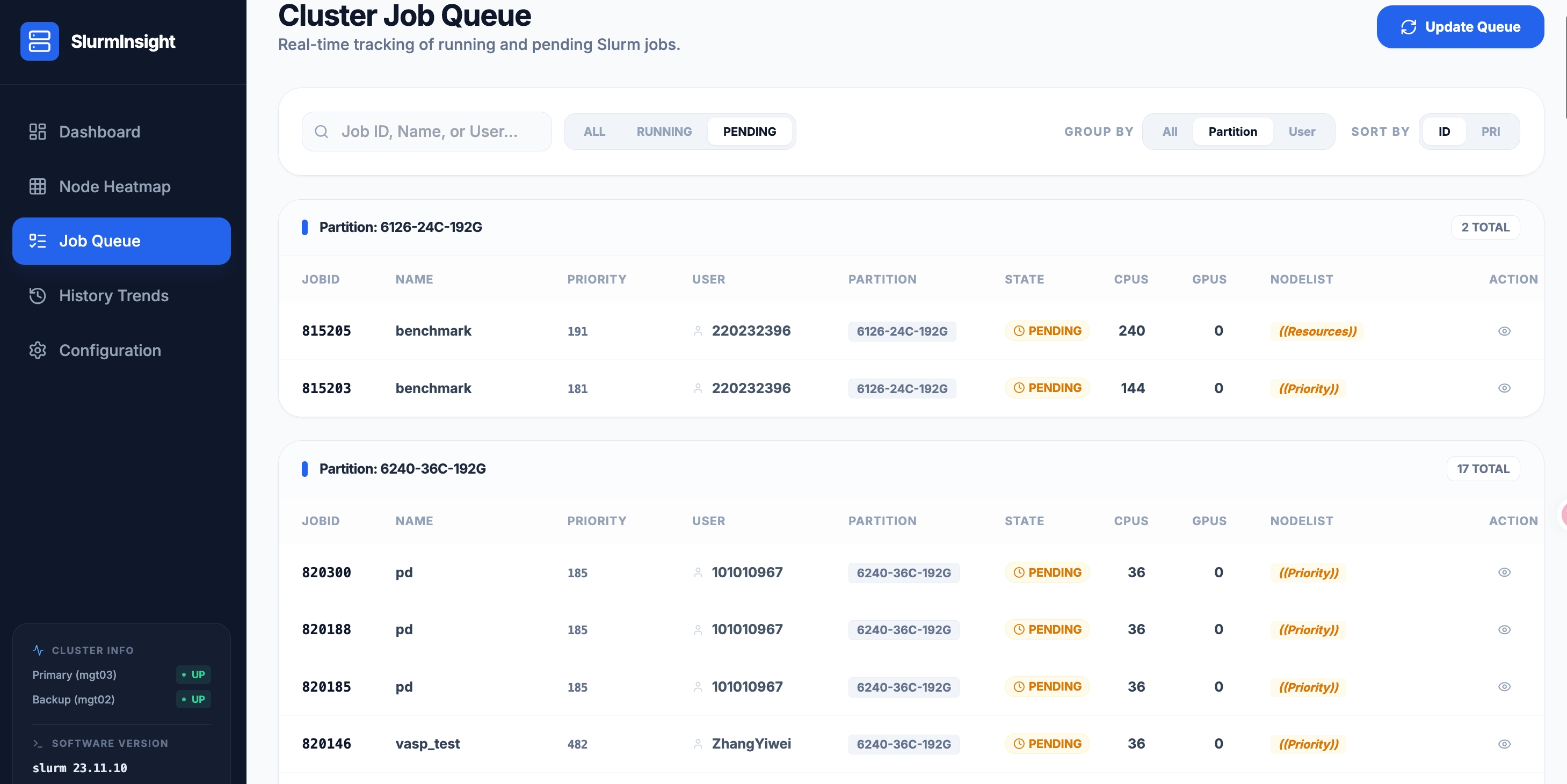
切换到 PENDING 筛选,作业还会按分区自动分组。每条 pending 作业后面标注了等待原因:
- ((Resources)) — 资源不足,等待空闲节点
- ((Priority)) — 优先级不够,等待调度
用户焦急地问"为什么我作业还没跑",管理员可以秒答:"你的作业在 6240-36C-192G 分区排队,前面还有 17 个,等优先级或者资源释放出来。"
五、历史趋势:让数据说话
5.1 概览视图 —— 多分区 24 小时资源走势
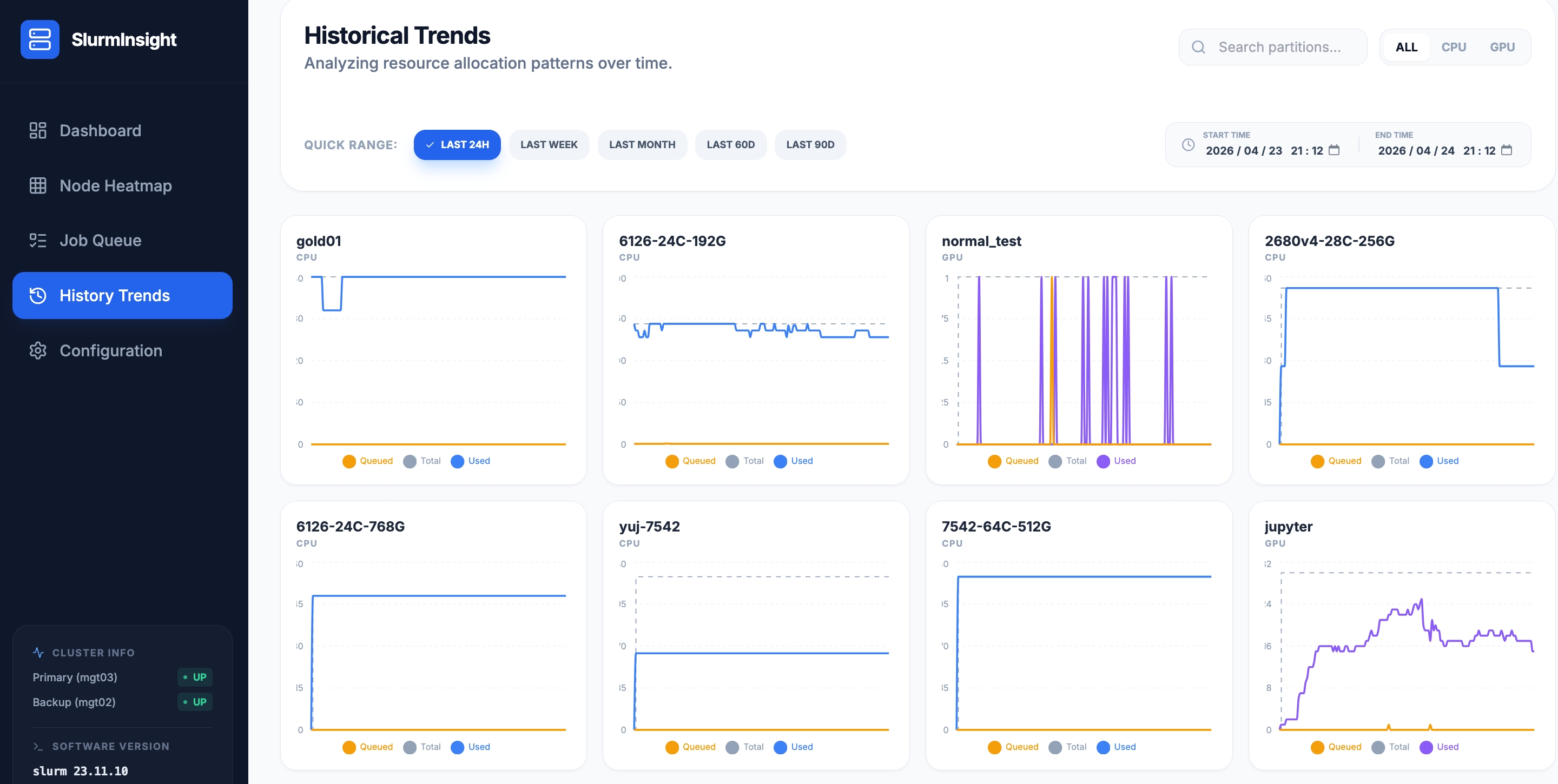
History Trends 模块提供了集群资源使用的时间维度分析。默认展示 LAST 24H 的各分区资源走势,每条曲线包含:
- Queued — 排队资源量
- Total — 分区总资源量
- Used — 实际使用量
还支持 LAST WEEK / LAST MONTH / LAST 60D / LAST 90D 多个时间维度切换,自定义起止时间范围搜索。
5.2 CPU 分区趋势 —— 精准到每个队列
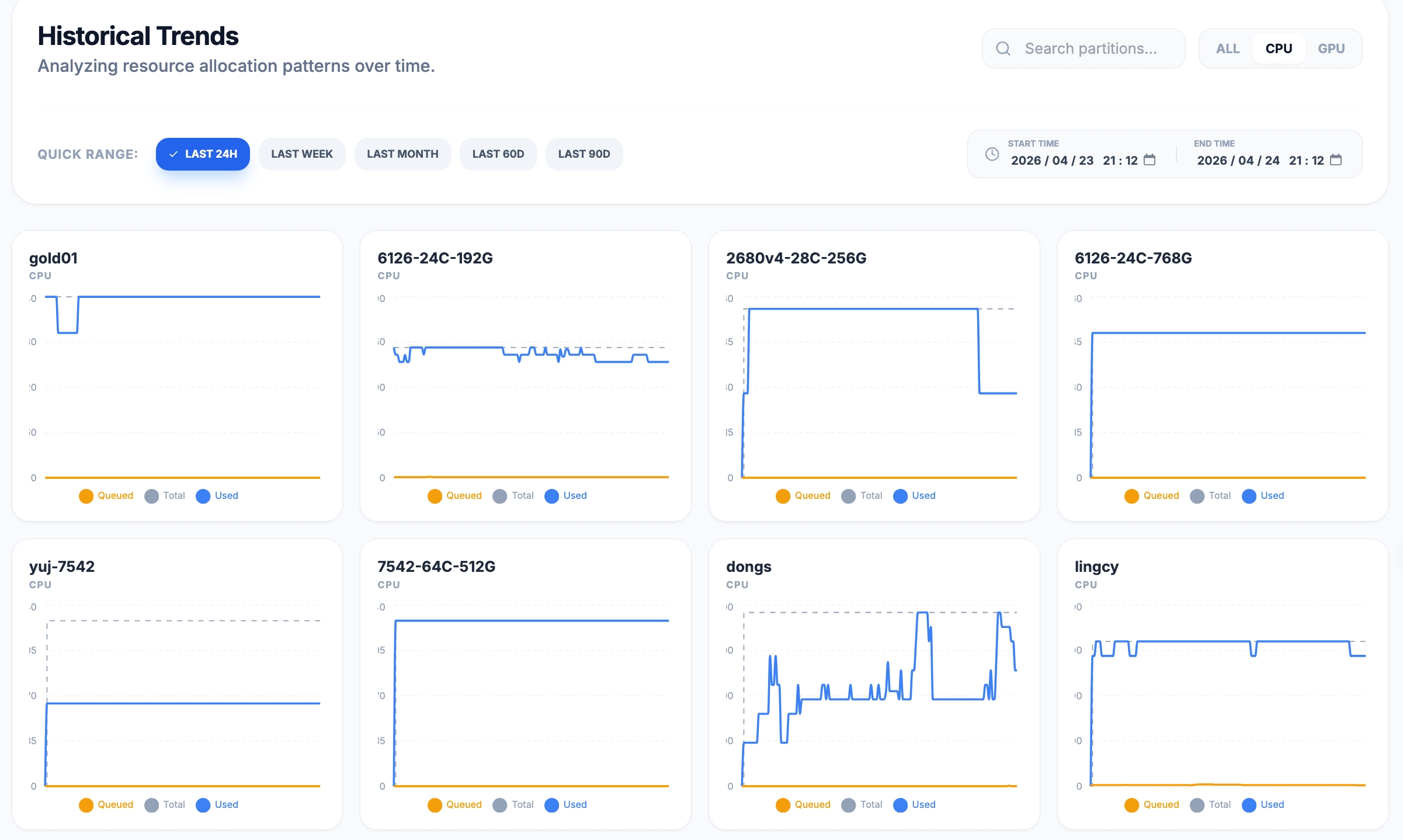
切换到 CPU 筛选,可以看到各个 CPU 分区的独立趋势图。哪些分区在白天跑满、哪些在夜间空闲,用来做容量规划和调度策略优化再合适不过。
5.3 GPU 分区趋势 —— AI 训练负载一目了然
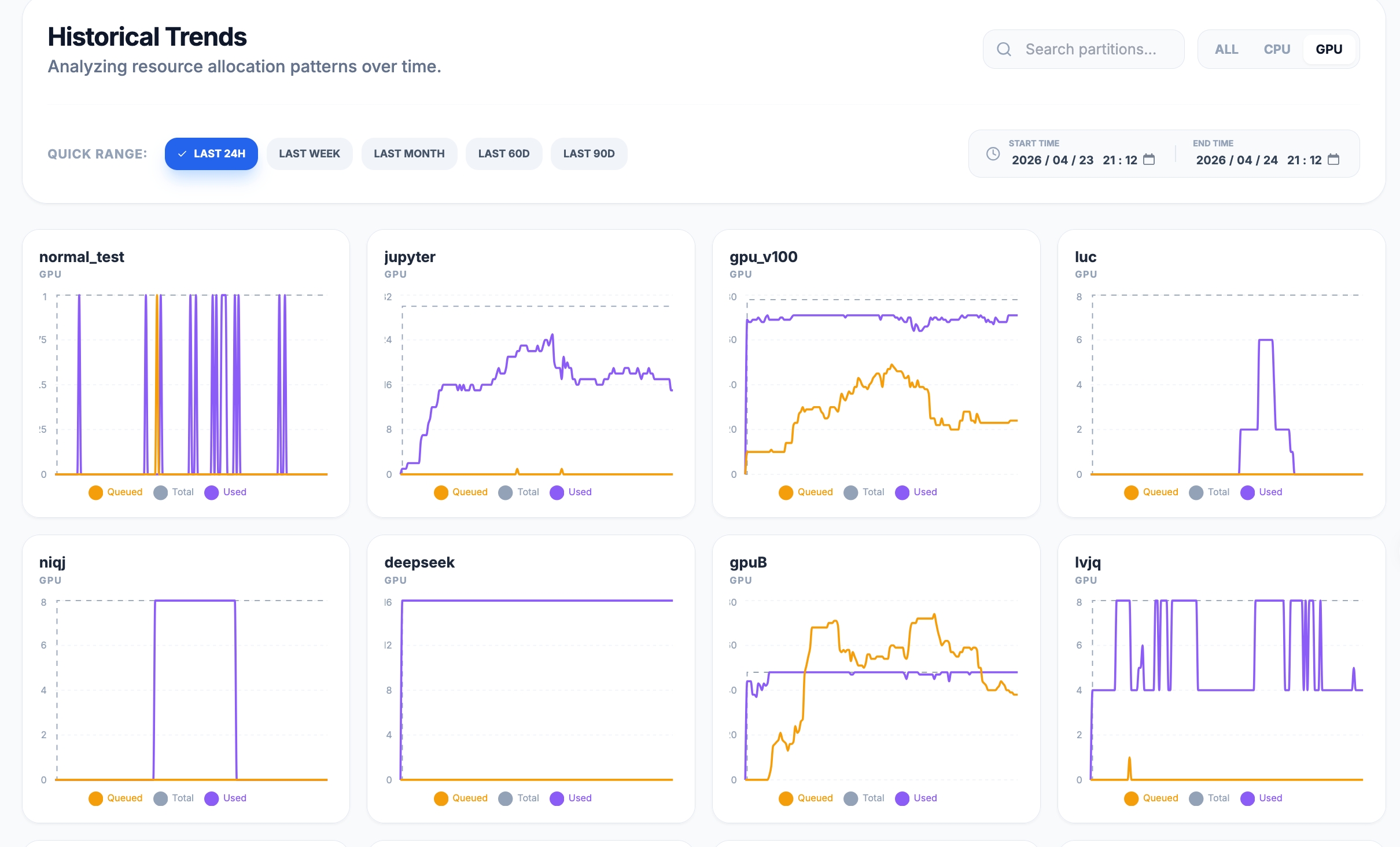
切换到 GPU 筛选,AI 训练作业的资源波动清晰可见:
- jupyter 分区:白天持续爬升到峰值,典型的交互式开发负载
- deepseek 分区:几乎满载运行,大模型训练占满 GPU
- niqi / gpuB / lvjq:间歇性峰值,推测是周期性提交的训练任务
这些数据对集群管理员来说价值满满:可以据此调整分区资源配置、引导用户错峰提交、甚至预判扩容需求。
六、不止于此:SlurmInsight 的技术亮点
| 亮点 | 说明 |
|---|---|
| 实时同步 | Last Sync 显示精确到秒的数据同步时间,资源状态实时更新 |
| 高可用架构 | Controller HA 双机热备(Primary mgt03 / Backup mgt02 均 UP) |
| 多维筛选 | 作业队列支持 ID / Name / User 搜索 + 状态 / 分区 / 用户分组 |
| 可视化分析 | 历史趋势支持 24H / Week / Month / 60D / 90D 多时间维度 |
| 现代界面 | 深色侧边栏 + 明亮主内容区,专业且易读 |
| 中英双语 | Job Details 等弹窗同时展示英文与中文标签 |
SlurmInsight 的诞生,源于我作为 HPC 集群管理员的真实日常。每天面对数百个节点的状态、几百条作业的排队、用户不停的"我作业怎么还没运行"的询问,我深切感受到:命令行工具虽然强大,但可视化才是效率的倍增器。
这个工具目前已经在生产环境中稳定运行,管理着一个 233 节点、16696 CPU 核心、253 GPU 卡的 Slurm 集群。从以前需要同时开 5 个终端窗口查状态,到现在的浏览器一站式监控,管理效率提升了不止一个数量级。
重要预告:SlurmInsight 即将在 GitHub 上开源!
如果你也在管理 Slurm 集群,或者在高校/企业/研究所做 HPC 相关工作,欢迎关注。代码开源后,期待收到大家的 Issue、PR 和功能建议,一起把它做得更完善。
GitHub 仓库地址:即将发布,敬请期待!
有任何问题或想法?欢迎在评论区留言交流!你的每一条反馈都是这个项目前进的动力。
© 2026 SlurmInsight Project | HPC · 集群监控 · 开源共享

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 24
24 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)