毕业设计与课程设计完美答案之基于生成对抗网络的风格迁移系统设计与实现
大家好,这里是正在升级的在研小学生给大家带来的毕业设计与课程设计完美答案,基于生成对抗网络的风格迁移系统设计与实现(AI率与查重率均低于8%),希望能给因为一些任务焦虑的朋友们提供帮助~
首先,随着科学技术的不断进步和计算机计算能力的提高,大量深度学习模型的问世不仅提高了图像识别的准确度,同时也减少了人工提取特征所需的时间成本。
考虑到目前动漫的制作主要依赖手工,而手工制作动漫是一项极其耗费精力的工作。对于动漫艺术家而言,要创作出高质量的动漫作品,需要花费大量时间处理线条、纹理、颜色和阴影等方面的细节。如果能使用算法和模型自动地将真实世界照片转换为特定动漫风格不仅能让艺术家们集中精力于创造性工作,也有助于普通人实现他们自己的动漫创作梦想。本文训练和改进了一种将真实场景的照片转化为动漫风格图像的方法,实现了基于AnimeGAN的将现实世界场景的照片转换为动漫风格图像的应用程序,同时在此基础上进行了实时风格迁移功能的拓展和尝试。
同时,本文将AnimeGAN模型分别与CartoonGAN和ComixGAN进行比较。结果显示,AnimeGAN模型对硬件的需求更小,生成效果也会更好。同时,本文将训练出的今敏风格模型在本次的风格迁移系统中进行应用,最终实现了完整的风格迁移系统。
生成对抗网络概述
生成式对抗网络(GAN, Generative Adversarial Networks )是一种深度学习模型,是近年来复杂分布上无监督学习最具前景的方法之一。如图可以直观看到GAN的最基本的网络结构,生成对抗网络实际上包含了两个网络,一个是生成网络(Generator)用于生成假样本,另一个是鉴别网络(Discriminator)用于判别样本真假,并且引入对抗损失,通过对抗训练的方式让生成器生成高质量的样本。
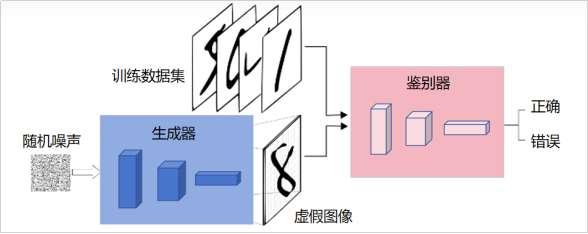
生成对抗网络的核心思想源自于博弈论的纳什均衡理论。GAN设定了两个角色:生成器和判别器。生成器的目标是学习尽可能接近真实数据分布,而判别器的目标是尽可能正确地区分真实数据和生成器生成的数据。为了达到最终的平衡,生成器和鉴别器需要持续优化,不断提高自身的生成和判别能力,这个学习过程就是寻找纳什均衡点。这一过程需要不断地迭代直到一个满足要求的结果出现。
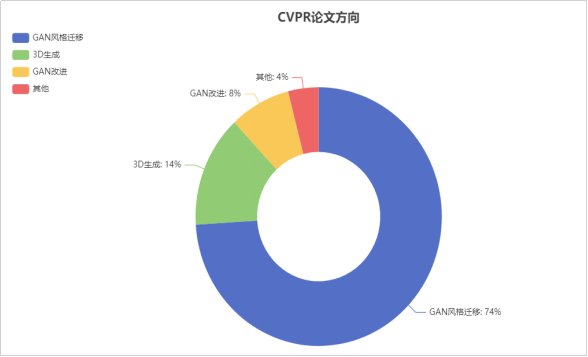
在计算机视觉领域顶级会议CVPR2023中,涌现出了大量AIGC的论文,广泛应用于各类视觉任务,通过网络统计、 scopu文献检索软件分析截取了2022年 CVPR关于GAN在视觉领域中的论文和2023年1月CVPR的AIGC论文共180篇。其中与风格迁移有关的有150篇,通过对论文方向进行进一步细分,通过图可以发现GAN在图像风格迁移领域仍是主流。
相关技术与算法
VGG19
VGG19,全称为Visual Geometry Group(视觉几何组)的19层网络结构,是由牛津大学的一组研究者提出的深度卷积神经网络(CNN)模型。这一命名源自其灵感来源:一方面是网络结构自身的层次化特性,另一方面则是为了纪念牛津大学的Visual Geometry Group研究团队。
VGG19以其深度和精细的特征提取能力在计算机视觉领域独树一帜。每一层都可以看作是一个独立的特征提取器,专注于从输入数据中提取局部特征。这种设计使得VGG19在处理图像分类、目标检测等任务时具有出色的性能。
VGG16是VGG网络的最基本版本,它包含了16个卷积层和3个全连接层。如图所示:

VGG19的每一层都包含着多个小型卷积核,这些卷积核对输入图像进行局部区域的处理,以提取出各种不同的特征。这些特征再经过一系列的非线性变换和组合,最终形成完整的图像表示。这种分层特征提取的结构使得VGG19能够从底层到高层逐步抽象出更高级别的视觉信息。
VGG19还采用了多个连续的小型卷积核来替代单一的大型卷积核。这种做法有两个主要优点:一是增加了网络对不同尺度特征的捕捉能力;二是提高了模型的泛化性能。因为使用多个小型卷积核可以在不同的尺度上捕捉到更多的信息,使模型对输入图像的大小变化、旋转等更具鲁棒性。
为了进一步提高网络的性能,VGG团队在VGG16的基础上又增加了3个卷积层和1个全连接层,于是得到了VGG19模型。同时通过表2-1直观展示VGG16和VGG19模型的卷积层和全连接层每层结构和卷积核个数。
|
VGG16 |
VGG19 |
|||
|
卷 积 层 |
3*3卷积核 |
最大池化层 |
3*3卷积核 |
最大池化层 |
|
128个 |
1个 |
128个 |
1个 |
|
|
256个 |
1个 |
256个 |
1个 |
|
|
256个 |
1个 |
1024个 |
1个 |
|
|
1024个 |
1个 |
2048个 |
1个 |
|
|
全 连 接 层 |
神经元 |
神经元 (输出层) |
神经元 |
神经元 (输出层) |
|
8192个 |
1000个 |
8192个 |
1000个 |
|
Canny边缘检测算法
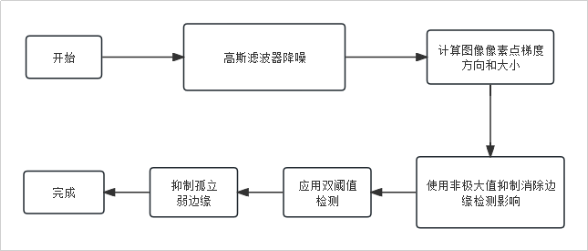
Canny边缘检测算法是一种在计算机视觉领域被广泛使用的边缘检测算法,由John Canny于1986年提出,被认为是一种边缘检测效果较好的算法之一。本文使用了该算法来对图像进行噪声抑制,具体的Canny边缘检测算法的步骤如下:
(1)高斯滤波:为了减少噪声对边缘检测的影响,首先对输入图像进行高斯滤波,以平滑图像。
(2)计算梯度:使用Sobel算子检测图像中的水平和垂直方向上的梯度。梯度的大小和方向可以帮助确定边缘的位置和方向。
(3)非极大值抑制:沿着梯度的方向对图像进行扫描,删除非边缘的像素,只保留局部最大值像素。
(4)双阈值检测:设置两个阈值,一个为高阈值,另一个为低阈值,然后根据像素的梯度值将其划分为强边缘、弱边缘和非边缘点。
(5)边缘连接:对强边缘像素与其周围的弱边缘像素进行连接,形成完整的边缘。
Tensorflow
TensorFlow这个词由Tensor和Flow两个词组成,是TensorFlow最基础的组成要素。Tensor代表张量(即数据),它以多维数组形式存在;而Flow表示流动,代表着计算与映射,用于定义操作中的数据流。
TensorFlow是由Google团队开发的深度学习框架之一,完全基于Python语言设计的开源软件。旨在以最简单的方式实现机器学习和深度学习概念,结合了计算代数的优化技术,并且能够计算多种数学表达式。同时TensorFlow可用于训练和运行深度神经网络,在诸如图像识别、手写数字分类、递归神经网络、单词嵌入、自然语言处理、视频检测等多种场景下应用广泛。作为训练模型的平台还拥有以下优点:
(1)灵活性:TensorFlow提供了丰富的工具和库,支持多种机器学习任务和模型类型,包括神经网络、深度学习、强化学习等。
(2)跨平台性:TensorFlow可以在各种不同的平台上运行,包括桌面、服务器、移动设备等,而且支持多种编程语言接口,如Python、C++、Java等。
(3)可扩展性:TensorFlow提供了灵活的架构,支持构建自定义的机器学习模型和算法,并且可以轻松地集成到现有的系统中。
(4)性能优化:TensorFlow在性能上进行了优化,可以高效地利用硬件资源,包括CPU、GPU和TPU等,并且支持分布式计算,可以加速训练过程。
(5)强大的社区支持:TensorFlow有着庞大的开发者社区,提供了丰富的文档、教程和示例代码,可帮助开发者快速入门并解决问题。
(6)持续更新和改进:TensorFlow的开发团队不断推出新的版本和更新,修复bug、改进性能,并且引入新的功能和技术,保持了框架的活力和竞争力。
同时TensorFlow官网(https://tensorflow.google.cn/)也提供了TensorFlow的官方学习文档以及最新版本的下载方式。
Flask框架
Flask是一个轻量级的Python web框架,适用于构建Web应用程序。有简单易用、灵活可扩展等优点,很适合用于小型和中型Web应用程序的开发。在Flask框架中,可以使用模板引擎(如Jinja2)来渲染HTML页面,并通过Flask提供的路由功能来控制URL的访问。简而言之,Flask框架具有以下特点:
(1)简单易用:Flask框架提供了简洁的API和清晰的文档,使开发者能够快速上手并构建Web应用程序。
(2)灵活可扩展:具有高度的灵活性和可扩展性,可以根据需要添加第三方扩展、中间件和插件,以满足不同的开发需求。
(3)轻量级高效:不依赖于其他外部库或工具,具有较小的内存占用和快速的响应速度。
(4)高度定制化:允许开发者自定义路由、异常处理、模板引擎、数据存储等方面的实现方式,以满足不同的开发需求。
(5)微内核设计:将核心功能和第三方扩展分离,允许开发者根据需要选择所需的功能和扩展。
(6)跨平台支持:可以在不同的操作系统和Web服务器上运行,包括Windows、Linux、macOS等操作系统,以及Apache、Nginx、Gunicorn等Web服务器。
(7)社区支持:拥有庞大的开源社区,提供了大量的第三方扩展、中间件和插件,为开发者提供了丰富的开发资源和技术支持。
(8)使用CSS控制样式:可以在HTML中嵌入或通过<link>标签引入CSS代码,实现Web应用程序的样式控制。
通过结合Flask框架和HTML、CSS技术,开发出具有动态数据和样式的Web应用程序有很大的作用。需要注意的是,在使用HTML和CSS时,务必遵循Web开发的最佳实践,以确保应用程序的易用性、可访问性和可维护性。
AnimeGAN概述
AnimeGAN是由武汉大学和湖北工业大学组成的研究团队开发的一种轻量级GAN,旨在将实景图像快速转换为动漫图像。
该技术结合了神经风格迁移(Neural Style Transfer)和生成对抗网络(GAN)的优势,采用Tensorflow,对线条、纹理、颜色、阴影等细节进行精准处理,实现照片到动漫风格的快速迁移。AnimeGAN的核心在于其独特的设计理念和损失函数,损失函数主要采用了以下三种:
(1)灰度样式丢失:让生成图像拥有动漫风格的纹理和线条;
(2)颜色重建损失:让生成图像维持原图的颜色内容;
(3)灰度对抗性损失:让生成图像有更鲜明的色彩。
这些损失函数的结合,使得生成的动漫图像既保留了原图的色彩和内容,又具有了鲜明的动漫风格。
AnimeGAN作为图像风格动漫化模型的改进,相对于之前的将实景图片转变为动漫图像的模型有了以下一些优点,
(1)轻量级设计:相较于传统的GAN模型,AnimeGAN采用了深度可分离卷积(DSConv)和倒置残差(inverted residual)设计,有效减少了生成器的参数数量,使得模型更加轻量级。这种设计不仅提高了模型的运算速度,还降低了对硬件资源的需求,使得更多的用户能够享受到这项技术带来的便利。
(2)高效转换:通过结合神经风格转换和GAN技术,AnimeGAN能够在短时间内实现实景图像到动漫风格的快速转换。这种高效的转换过程不仅为用户节省了大量时间,还使得生成的动漫图像更加真实、生动。
(3)保留原图信息:AnimeGAN在生成动漫图像的过程中,充分考虑了原图的颜色和内容,通过灰度样式丢失(grayscale style loss)和颜色重建损失(color reconstruction loss)的设计,使得生成的图像既具有动漫风格,又保留了原图的信息。这种特性使得用户能够在欣赏动漫风格的同时,仍然能够辨识出原图的内容。
AnimeGAN可以很轻松地进行端到端的训练,通过使用未配对的数据生成高质量的动漫风格的图像。本文以真实世界的照片作为内容图像,以动漫图像作为风格图像作为训练数据,测试数据中只包括了真实世界的照片。同时将所有训练图像的分辨率都设置为256*256。而对于内容图像,使用了6636张真实世界如图1的照片进行训练,对于具有特定风格的图像,由于不同的动漫艺术家都有自己独特的动漫风格,为了获得一个具有特定风格的系列图像,对于具有相同风格的动画图像,本文使用的关键帧动漫电影由同一艺术家绘制。在本文中,1792张动画图像从电影“起风了”中截取如图2,用于训练宫崎骏风格模型,1650张动画图像从电影“你的名字”中截取如图3,用于训练新海诚风格模型以及1553张动画图像从电影“红辣椒”中截取如图4,用于训练今敏风格模型。




数据集处理
使用高斯模糊滤波器,对输入的图像进行处理,并将处理结果保存在指定的目录中,操作的具体步骤如下:
(1)通过参数解析,获取数据集名称和图像大小等参数。
(2)创建保存平滑图像的目录,并获取待处理的彩色图像文件列表。
(3)遍历每个彩色图像文件:
(ⅰ)读取彩色图像和灰度图像。
(ⅱ)调整图像大小,并在图像周围填充边缘以解决边缘处理的边界问题。
(ⅲ)创建一个高斯模糊图像副本,并对边缘像素进行高斯加权平均处理,生成平滑的彩色图像。
(ⅳ)将处理后的平滑图像保存到指定的目录中。最后通过命令行参数解析执行主函数。
详细的数据处理与高斯函数的应用可以参考我的上一篇博客~传送门
AnimeGAN架构
AnimeGAN由两个卷积神经网络组成:一个是生成器(Generator),用于将现实世界的照片场景转换为动漫图像;另一个是鉴别器(Discriminator),用于区分图像是来自现实目标域还是由生成器产生的输出。AnimeGAN的网络结构如图3-6所示。
AnimeGAN的生成器可以看作是一个对称的编码器-解码器网络,如图3-7,主要由标准卷积块、深度卷积块、反向残差块(inverted residual blocks)、上采样和下采样模块组成。为了有效减少生成器的参数数量,AnimeGAN的网络中使用了8个连续且相同的反向残差块(IRBs)。在生成器中,最后一个卷积层没有使用归一化层,跟随其后的是tanh非线性激活函数。
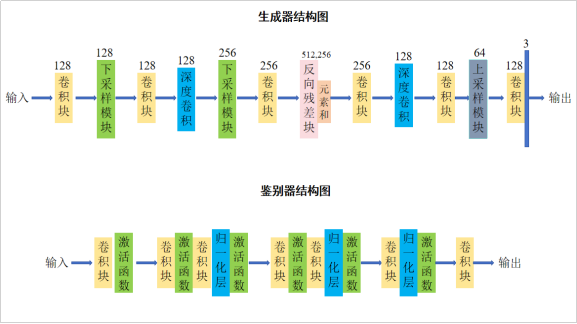
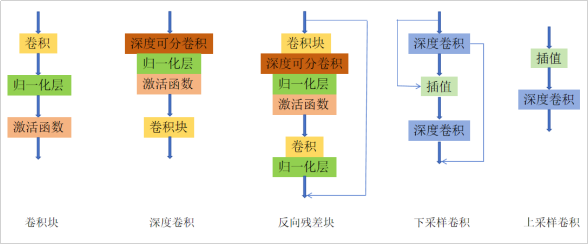
Conv-Block(卷积块)由3*3卷积核的标准卷积、实例归一化层(提高了模型的鲁棒性和泛化能力,同时稳定了训练过程)和LRelu激活函数(防止梯度消失,更好地传递梯度和优化模型)组成。DSConv(深度卷积)是由深度卷积块组成的,可以大大减少模型中的参数数量,因为其在每个输入通道上分别执行卷积操作,而不是在整个输入特征图上。
反向残差块可以显著减少网络的参数数量,降低计算工作量,生成器中使用的反向残差块由512个核的逐点卷积(组合和调整通道的特征表示)、512个核的深度卷积(每个输入通道上分别执行卷积运算,在保持较高性能的同时减少模型的大小和计算量)和256个核的逐点卷积组成。而为了避免最大池化导致的特征信息丢失,提出了下采样卷积,以降低特征图的分辨率。
在下采样卷积中,调整特征映射的大小为输入特征映射大小的一半。下采样卷积模块的输出是第2步的深度卷积模块和第1步的深度卷积模块的输出的和。
采用所提出的上采样卷积,用于提高特征图的分辨率。上采样卷积的架构也如图所示。在上采样卷积中,特征映射的大小被调整为输入特征映射的2倍。
在鉴别器结构中,所有卷积层都采用的是标准的卷积层。而对于每个卷积层的权值,使用了谱归一化(改善模型泛化能力,有助于避免过拟合),通过对卷积核的权重进行归一化,确保了每个卷积核的最大奇异值(最大特征值)都小于等于一个给定的阈值,使网络训练更加稳定。
各个模块中使用的激活函数都是LRelU。
CartoonGAN、ComixGAN和AnimeGAN都是基于生成对抗网络(GAN)的图像生成模型,它们分别针对卡通风格、漫画风格和动漫风格的图像生成。这些模型在图像生成领域引起了广泛关注,并在各自领域内取得了一定的成就。首先CartoonGAN专注于卡通风格的图像生成。通过对抗训练的方式,训练了一个生成器网络和一个判别器网络,使得生成器可以生成逼真的卡通风格图像。CartoonGAN的优点在于生成的图像具有鲜明的卡通特征,色彩丰富、线条清晰,能够有效地将真实世界的照片转换为卡通风格的图像。然而,CartoonGAN也存在一些局限性,例如在处理复杂场景或细节丰富的图像时可能表现不佳,生成的图像可能缺乏一些细节或真实感。
ComixGAN是专门设计用于生成漫画风格图像的模型。在生成器和判别器的结构上进行了优化,以适应漫画风格的特点。ComixGAN在保留原始图像内容的同时,赋予了图像漫画般的线条和色彩效果,使得生成的图像更加具有艺术感和视觉冲击力。然而,与CartoonGAN类似,ComixGAN在处理复杂场景或细节丰富的图像时也可能存在一定的挑战,需要进一步改进。
AnimeGAN是专门针对动漫风格的图像生成模型。在生成器和判别器的设计上考虑了动漫风格的独特特征,通过对抗训练来生成逼真的动漫风格图像。AnimeGAN的优点在于能够有效地捕捉到动漫风格的特征,生成的图像具有清晰的线条和鲜艳的色彩,非常符合动漫风格的审美要求。三种模型的功能较为相似,因此在本文中进行了模型效果的对比。
首先将AnimeGAN与两种先进的动画风格的转移方法进行比较,即CartoonGAN和 ComixGAN。CartoonGAN和ComixGAN具有相同的网络结构,并且损失函数的设计也相同,模型之间的不同在于:ComixGAN使用的训练策略不同,并将动漫风格的转换视频中进行了应用。与此同时,AnimeGAN与CartoonGAN使用的鉴别器的结构相同。
AnimeGAN所使用的鉴别器是一种轻量级的卷积神经网络,模型大小为4.20M。对于不同的生成器,每个输入照片的大小为256*256,其在模型大小、参数数量、计算量和推理时间方面的比较如表3-1所示:
表3-1 Cartoon与AnimeGAN生成器对比
|
模型 |
参数量 |
模型大小 |
计算量 |
推理时间 |
|
CartoonGAN |
12253186 |
45.47M |
109.97B |
52ms/图 |
|
AnimeGAN |
3956069 |
16.10M |
38.67B |
40ms/图 |
从表中可以看出,与CartoonGAN相比,AnimeGAN显著减少了参数的数量和计算成本,并且具有更快的推理速度。
CartoonGAN、ComixGAN和AnimeGAN的定性结果如图3-8所示。可以很明显地发现,这三种方法可以有效地捕捉动画风格。但是CartoonGAN生成的图像在局部区域产生了显著的彩色伪影,并因此失去了原始图像的色彩。由ComixGAN生成的图像很容易在本地区域中进行泛化,这将导致生成的图像丢失原始照片的内容。由AnimeGAN生成的图像可以在最大程度上保存照片的内容和照片中相应区域的颜色。与CartoonGAN和ComixGAN相比,AnimeGAN能够产生更高质量的动画视觉效果。

模型训练主要配置见表3-2。
表3-2 模型训练配置
|
名称 |
版本 |
|
Python |
3.6~3.7(推荐3.7) |
|
Tensorflow-gpu |
小于等于1.8(推荐1.14) |
|
GPU |
4080 |
|
Opencv-python |
4.3.0.38 |
|
Numpy |
1.19.5 |
|
CUDA |
10.0.130 |
|
CUDNN |
7.4.0 |
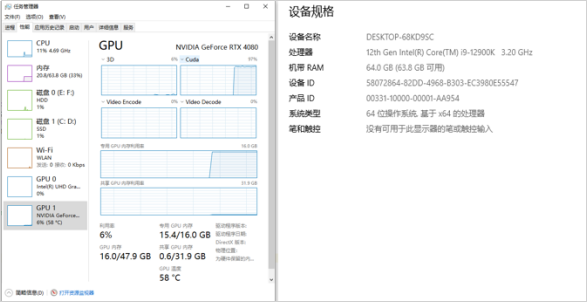
设备规格和训练过程截图如图3-9、图3-10:
(1)模型推理,采用宫崎骏的数据集实现今敏风格模型。
1.python test.py --checkpoint_dir checkpoint/generator_Paprika_weight --test dataset/test/real --style_name P
(2)训练前下载vgg19和预训练模型。
(3)下载数据集。
(4)图片边缘处理。
1.python edge_smooth.py --dataset Paprika --img_size 256
(5)训练。
1.python train.py --dataset Paprika --epoch 150 --init_epoch 50
(6)提取生成器权重。
1.python get_generator_ckpt.py --checkpoint_dir ../checkpoint/AnimeGAN_Paprika_lsgan_300_300_1_1_10 --style_name Paprika
系统主要配置见表4-1:
表4-1 系统环境配置
|
名称 |
版本 |
|
Python |
3.6~3.7(推荐3.6.8) |
|
Tensorflow-gpu |
小于等于1.8(推荐1.15) |
|
Opencv-python |
4.3.0.38 |
|
Numpy |
1.19.5 |
|
CUDA |
10.0.130及以上 |
Python版本保持在3.7以下否则会与Opencv-python库、Tensorflow版本产生冲突,Tensorflow-1.15.0与本系统代码兼容,小于等于1.8也支持,但本系统并没有做额外尝试。
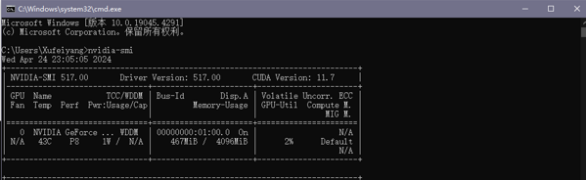
使用命令行查看本机显卡支持的最高CUDA的版本如图4-1,在官网下载对应的CUDA安装包如图4-2,查看对应CUDA对应的VS(Visual Studio)版本,以便下载并安装对应的VS版本。
系统架构设计
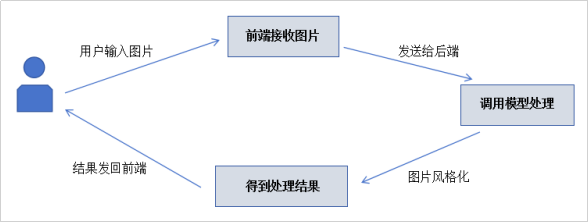
本系统风格迁移系统是一个能够将普通图片转换为动漫风格的应用程序,使用深度学习技术中的生成对抗网络来实现这一功能。
本系统设计采用的模型使用今敏的动漫电影红辣椒(Paprika)的帧截图作为训练数据集,最终将训练得到的今敏风格AnimeGAN模型,然后将模型在本系统中进行应用,最终实现了能够将图片转变为今敏风格的动漫图片系统,本系统的工作流程大致如图
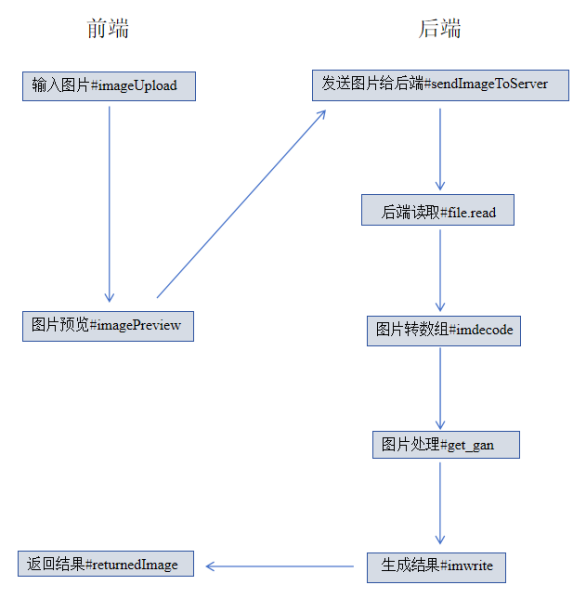
前后端处理流程图如图
功能展示
分别使用人像图片和风景图片进行测试,测试图片原图如图

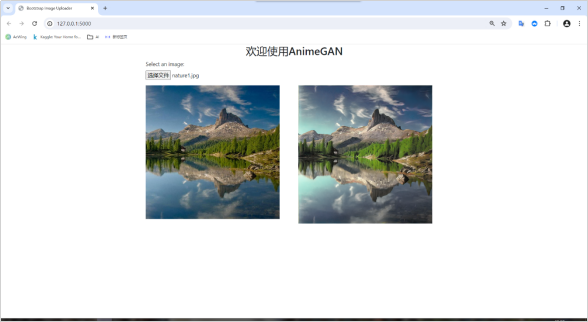
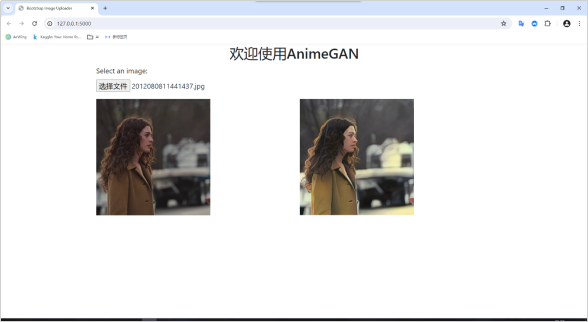
本文选取了今敏和宫崎骏作为目标生成模型并进行生成结果的对比,其中今敏的漫画有以下几点突出的个人风格,
(1)锐利而犀利的线条:今敏的线条通常更加锐利和犀利,他的作品中常常可以看到一些突出的边缘和角度,这种线条给人一种冷峻和深沉的感觉。
(2)大胆的笔触:今敏的笔锋常常显得更加大胆和有力。他擅长运用深浅不一的笔触来表现不同的情感和氛围,使得画面更加丰富多彩。
(3)超现实主义的线条处理:在表现超现实主义元素和梦境场景时,今敏常常采用大胆而前卫的线条处理方式。他的作品中常常可以看到一些抽象而富有想象力的线条构图,给人以深刻的印象和感受。
另一方面,宫崎骏的漫画个人风格也十分明显,
(1)流畅而柔和的线条:宫崎骏的线条通常呈现出流畅而柔和的特点。他的作品中很少有生硬的线条,而是更多地采用流畅的曲线,这种线条给人一种温暖和柔美的感觉。
(2)细腻的表现力:宫崎骏的笔锋非常细腻,他擅长通过微妙的线条变化来表现人物的情感和内心世界。这种细腻的表现力使得他的角色更加立体和生动。
(3)富有想象力的线条运用:在表现奇幻世界和幻想元素时,宫崎骏常常运用富有想象力的线条。他的作品中充满了各种奇妙的生物和场景,而这些都是通过他独特的线条运用来实现的。
宫崎骏和今敏在画漫画的线条和笔锋方面展现出了各自独特的风格和特点。宫崎骏的线条更加流畅和柔和,而今敏的线条则更锐利和大胆。这些不同的线条和笔锋的运用方式也为他们的作品赋予了不同的气质和魅力。
本系统中使用今敏数据集生成了对应的模型,并将模型应用在系统中,最终实现了能够将用户输入的图片转变为具有今敏动漫风格的图片。在漫画作家的作品中景物、人物和动物都是作品中故事和情节的重要参与,并给观众带来了舒适的视觉体验和真实的共情感受。因此在生成效果中分别采用景物、人物和动物三组图片将原图、今敏风格和宫崎骏风格图片进行对比。
from AnimeGAN import AnimeGAN
import argparse
from utils import *
import os
from flask import Flask, request, jsonify, send_file, render_template
import cv2
import numpy as np
import tensorflow as tf
from realtime import get_gan
from utils import *
from net import generator
import io
import base64
app = Flask(__name__)
globeSess = ""
@app.route('/')
def index():
return render_template('index.html')
@app.route('/index2')
def index2():
return render_template('index2.html')
def use_image_as_test(image, size):
img = image.astype(np.float32)
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
img = preprocessing(img, size)
img = np.expand_dims(img, axis=0)
return np.asarray(img)
def gan(style_name, sample, img_size=[256, 256]):
test_data = use_image_as_test(sample, img_size)
fake_img = globeSess.run(test_generated, feed_dict={test_real: test_data})
return fake_img
def get_gan(frame, size, style="S"):
frame = cv2.resize(frame, size, interpolation=cv2.INTER_NEAREST)
images = gan(style, frame, size)
res = inverse_transform(images.squeeze())
os.system("cls")
res_bgr = cv2.cvtColor(res, cv2.COLOR_RGB2BGR)
return res_bgr
@app.route('/')
def hello_world():
return 'Hello, World!'
@app.route('/upload', methods=['POST'])
def upload_file():
print(request)
if 'file' not in request.files:
return jsonify({'error': 'No file part'})
file = request.files['file']
width = int(request.form['width'])
height = int(request.form['height'])
print(width, height)
if file.filename == '':
return jsonify({'error': 'No selected file'})
# 读取上传的图像文件
file_stream = file.read()
# 将图像数据转换为 numpy 数组
nparr = np.frombuffer(file_stream, np.uint8)
frame = cv2.imdecode(nparr, cv2.IMREAD_COLOR)
# 将数据进行处理,返回值为一个np数组
data = get_gan(frame, size=(height, width), style="H")
# 将处理后的图像转换为 JPEG 格式
_, img_encoded = cv2.imencode('.png', data)
cv2.imwrite("1.png", data)
# 将处理后的图像数据返回给前端
# 直接发送处理后的图像数据给前端
return base64.b64encode(img_encoded.tobytes()).decode('utf-8')
# return send_file(
# io.BytesIO(img_encoded.tobytes()),
# mimetype='image/png'
# )
if __name__ == '__main__':
os.system("cls")
test_real = tf.placeholder(tf.float32, [1, None, None, 3], name='test')
with tf.variable_scope("generator", reuse=tf.AUTO_REUSE):
test_generated = generator.G_net(test_real).fake
saver = tf.train.Saver()
gpu_options = tf.GPUOptions(allow_growth=True)
globeSess = tf.Session(config=tf.ConfigProto(allow_soft_placement=True, gpu_options=gpu_options))
ckpt = tf.train.get_checkpoint_state('checkpoint/')
if ckpt and ckpt.model_checkpoint_path:
ckpt_name = os.path.basename(ckpt.model_checkpoint_path) # first line..
saver.restore(globeSess, os.path.join('checkpoint/', ckpt_name))
print(" [*] Success to read {}".format(ckpt_name))
else:
print(" [*] Failed to find a checkpoint")
exit(-1)
app.run(debug=True)
# if __name__ == '__main__':
# os.system("cls") # 清除控制台输出
# test_real = tf.placeholder(tf.float32, [1, None, None, 3], name='test') # 创建占位符
# with tf.variable_scope("generator", reuse=tf.AUTO_REUSE):
# test_generated = generator.G_net(test_real).fake # 构建生成器网络模型的输出节点
# saver = tf.train.Saver() # 创建模型保存器
# gpu_options = tf.GPUOptions(allow_growth=True) # 设置 GPU 使用选项,允许 GPU 内存自动增长
#
# globeSess = tf.Session(config=tf.ConfigProto(allow_soft_placement=True, gpu_options=gpu_options)) # 创建会话对象
# ckpt = tf.train.get_checkpoint_state('checkpoint/') # 获取模型检查点路径
# if ckpt and ckpt.model_checkpoint_path:
# ckpt_name = os.path.basename(ckpt.model_checkpoint_path) # 提取模型名称
# saver.restore(globeSess, os.path.join('checkpoint/', ckpt_name)) # 恢复模型参数
# print(" [*] Success to read {}".format(ckpt_name))
# else:
# print(" [*] Failed to find a checkpoint")
# exit(-1)
# app.run(debug=True) # 运行 Flask 应用(Web 服务器)

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 16
16 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)