即插即用系列 | arxiv 2025 CPDATrack:Transformer 跟踪新突破!上下文感知剪枝 + 判别式注意力,提速 37% 且精度超越 OSTrack
论文标题:Context-Aware Token Pruning and Discriminative Selective Attention for Transformer Tracking
论文原文 (Paper):https://arxiv.org//pdf/2511.19928
代码 (code):https://github.com/JananiKugaa/CPDATrack
哔哩哔哩视频讲解:https://space.bilibili.com/57394501?spm_id_from=333.337.0.0
本论文的完整复现代码(即插即用版)已更新至专栏
即插即用系列(代码实践) | arxiv 2025 CPDATrack:Transformer 跟踪新突破!上下文感知剪枝 + 判别式注意力,提速 37% 且精度超越 OSTrack
目录
1. 核心思想
本文提出了一种名为 CPDATrack 的新型视觉跟踪框架,旨在解决现有单流(One-stream)Transformer 跟踪器计算冗余大且易受干扰物影响的问题。其核心思想包含两点:
- 做减法(提速):设计了一个 上下文感知 Token 剪枝 (CTP) 模块,它不仅移除背景 Token,还特意通过“形态学膨胀”的思想保留了目标周围的上下文 Token,防止过度剪枝导致的语义丢失。
- 做加法(提精):引入了 判别式选择性注意力 (DSA) 机制,强行抑制搜索区域中背景和相似干扰物(Distractor)对模板的注意力贡献,让模型“只看该看的地方”。
2. 背景与动机
2.1 文本背景总结
目前的 SOTA 跟踪器(如 OSTrack, SimTrack)大多采用单流 Transformer 结构,将模板(Template)和搜索区域(Search Region)的 Token 拼接后输入 ViT。
虽然效果好,但存在两个严重问题:
- 计算浪费:搜索区域中大部分是背景(树木、街道等),这些 Token 参与了昂贵的自注意力计算,却对定位目标贡献极小。
- 判别力不足:现有的 Token 剪枝方法(如 PPT 等)通常只保留高响应的 Token。然而,目标跟踪需要上下文信息(例如,要跟踪“人”,知道旁边的“车”有助于确定边界),过度剪枝会导致模型在目标发生形变或模糊时跟丢。此外,相似的干扰物容易混淆模型。
2.2 动机图解分析

看图说话与痛点分析:
- 左图(Baseline):我们可以看到,在标准的单流跟踪器中,注意力图非常稠密。大量的背景 Token(比如草地、天空)都与模板产生了交互。这不仅计算量大(FLOPs 高),而且引入了噪声。
- 中图(Existing Pruning):这是现有的剪枝策略(如基于阈值的保留)。可以看到,虽然背景被去除了,但目标(比如图中的运动员)变得支离破碎,很多边缘信息和辅助判断的背景(上下文)丢失了。这就是“语义鸿沟”——为了效率牺牲了完整性。
- 右图(Ours - CPDATrack):这是本文的结果。注意看,保留下来的 Token 不仅覆盖了目标主体,还智能地保留了一圈轮廓和周围环境。这种“藕断丝连”的保留策略,既减少了计算量,又确保了模型能理解目标所处的环境,完美解决了效率与精度的平衡。
3. 主要创新点
- 上下文感知 Token 剪枝 (CTP):提出了一种基于预测得分并结合“邻域膨胀”策略的剪枝模块,在去除冗余背景的同时,显式地保留了目标周围的关键上下文信息。
- 判别式选择性注意力 (DSA):设计了一种新的注意力掩码机制,根据 Token 的类别(前景/背景)动态调整注意力权重,有效抑制了搜索区域中的干扰物(Distractor)。
- 高效与高性能的平衡:在 LaSOT、TNL2K 等主流数据集上,CPDATrack 在减少了约 37% 的 FLOPs 的同时,性能依然超越了 OSTrack 等基线模型。
4. 方法细节
4.1 整体网络架构
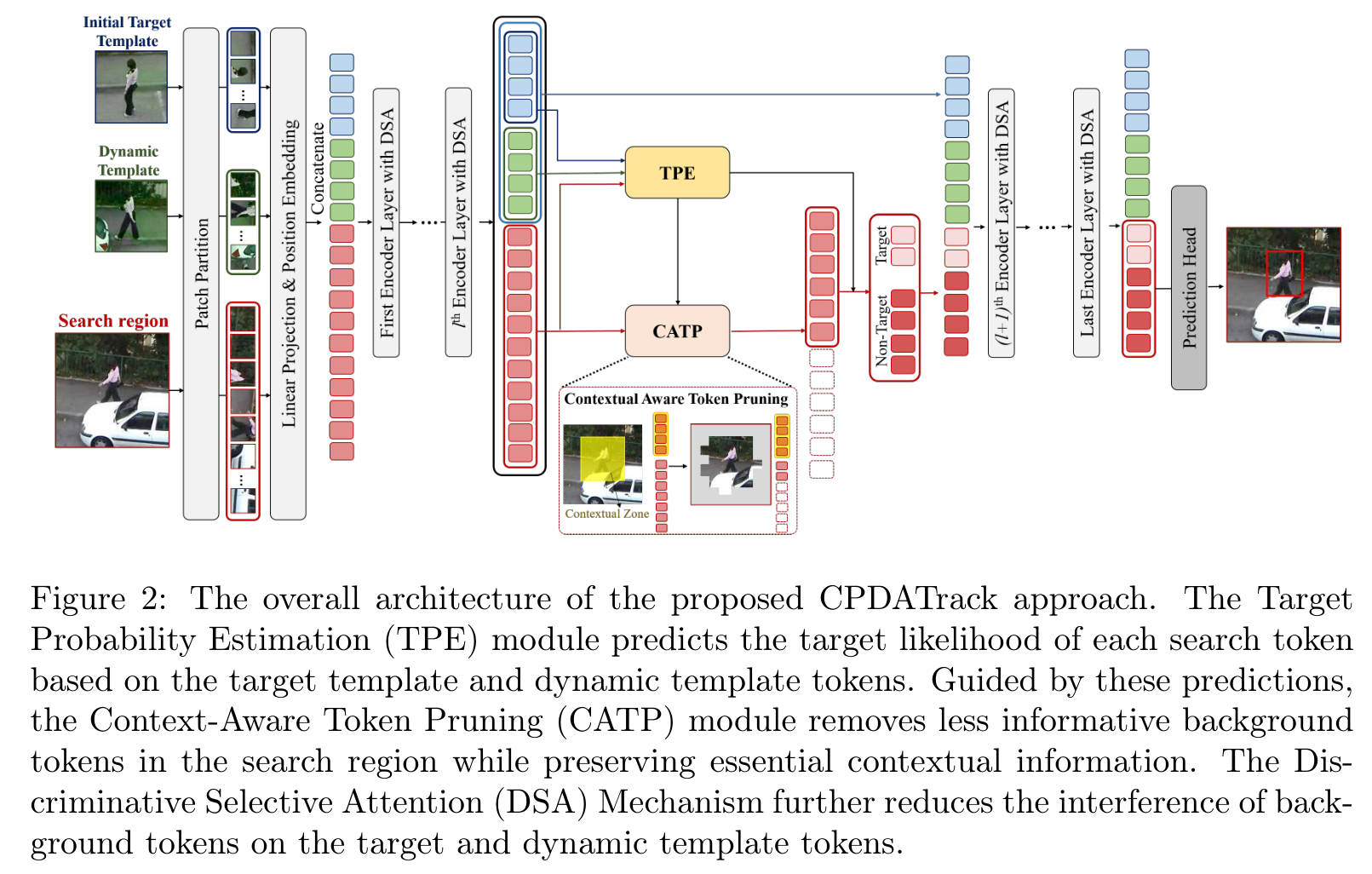
数据流详解:
CPDATrack 基于标准的 ViT 架构(如 MAE 预训练的 ViT-B)。
- 输入 (Input):接收两个输入——模板图像 Z Z Z 和搜索区域图像 X X X。
- Patch Embedding:将图像切块并映射为 Token 序列。
- 第一阶段编码 (Pre-Pruning Encoder):前 K K K 层 Transformer Block 处理完整的 Token 序列( Z Z Z 和 X X X 拼接),提取初步特征。
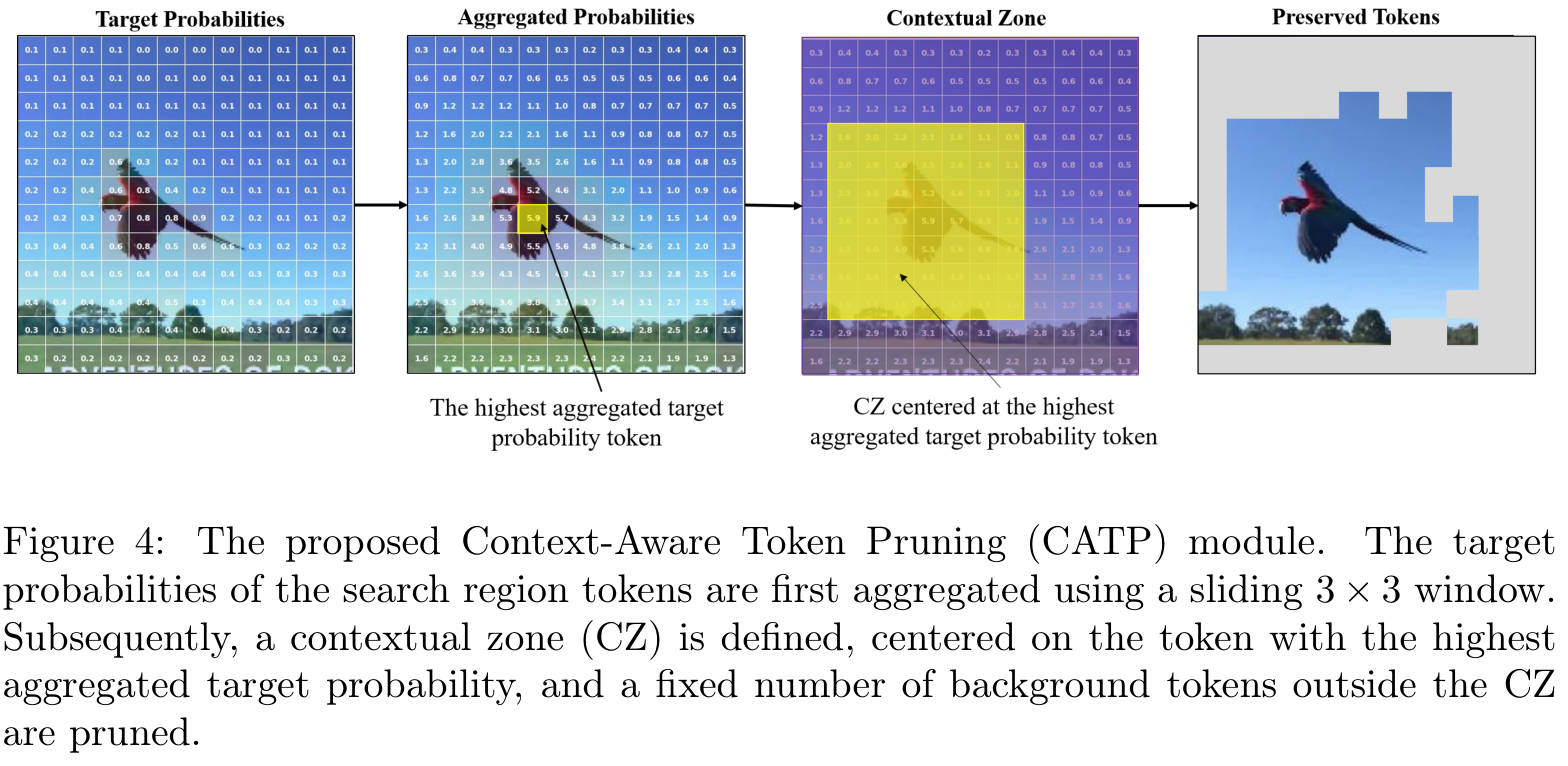
- 关键动作:CTP 模块:在第 K K K 层之后,插入 CTP 模块。这里会根据预测的分数,丢弃搜索区域中大部分无关的背景 Token。
- 第二阶段编码 (Post-Pruning Encoder):剩余的 Token(数量大大减少)进入后续的 L − K L-K L−K 层 Transformer Block。
- 注意:在这些深层网络中,应用了 DSA(判别式选择性注意力) 机制,进一步提升特征的纯净度。
- 输出 (Output):最后剩下的搜索区域 Token 被还原(Unshuffle/Reshape),送入预测头(Head)输出目标框坐标。
4.2 核心创新模块详解
模块 A:上下文感知 Token 剪枝 (CTP Module)
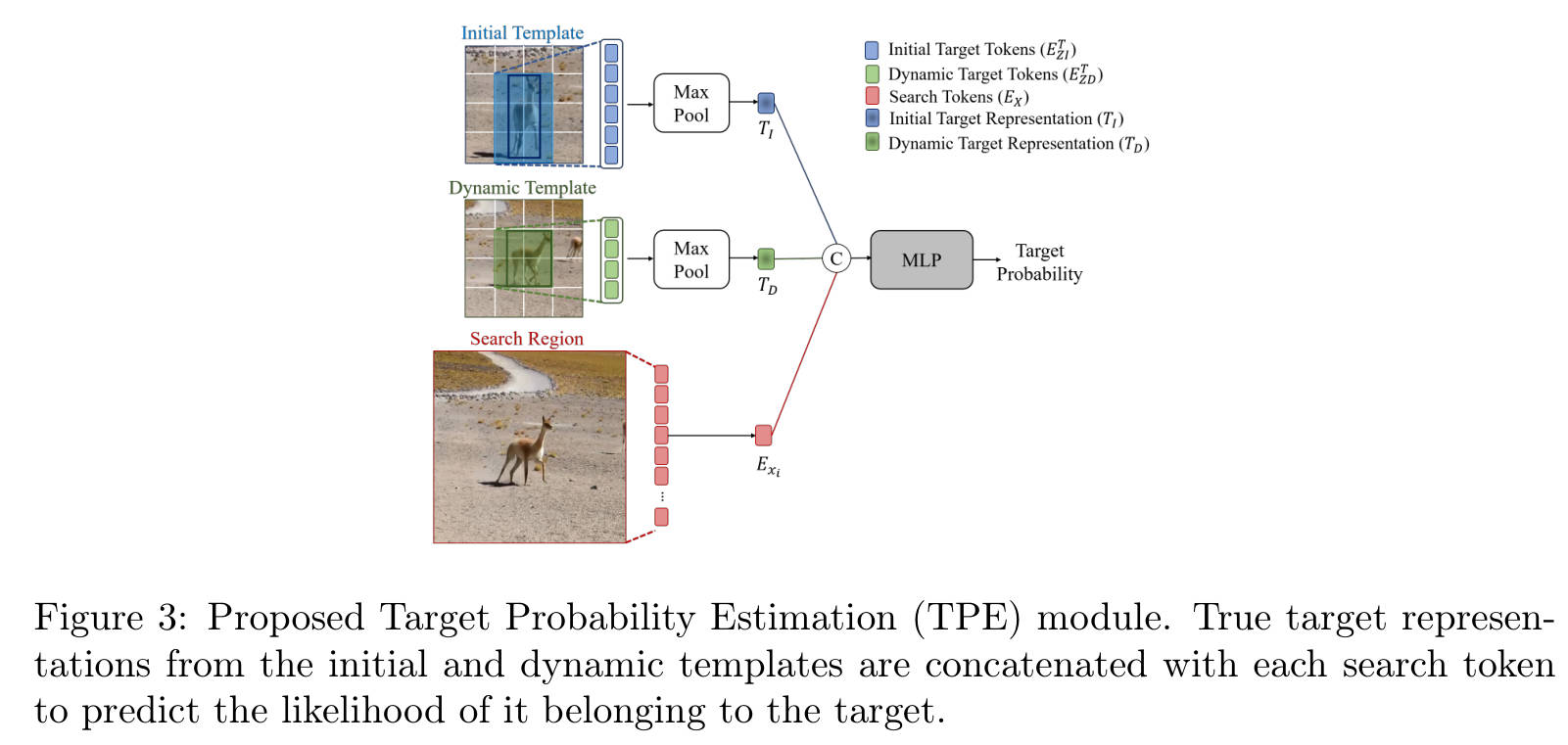
这个模块是本文“提速”的核心,内部流动如下:
- 重要性评估:输入搜索区域的 Token T s T_s Ts。通过一个轻量级的 MLP 预测每个 Token 属于“目标”的概率得分。
- Top-K 选择:根据得分,选取前 k k k 个最重要的 Token(通常是目标主体)。
- 上下文补全(Context Dilation):这是最精彩的一步。
- 作者没有止步于 Top-K,而是计算了这 k k k 个 Token 在原始 2D 空间中的邻域(例如 3 × 3 3 \times 3 3×3 范围)。
- 如果一个背景 Token 位于目标 Token 的邻域内,它会被强制召回(Recall)。
- 设计目的:类似于图像处理中的“形态学膨胀”。它确保了目标不是孤立的像素点,而是包含边缘和局部环境的整体,解决了之前剪枝方法导致的“信息破碎”问题。
模块 B:判别式选择性注意力 (DSA)
这个模块是为了解决“干扰物”问题,设计理念如下:
- 问题:在常规 Self-Attention 中,模板 Token 可能会错误地关注到搜索区域中长得像目标的“干扰物”。
- 分组:根据 CTP 模块预测的得分,将搜索区域 Token 显式地分为“前景集”和“背景集”。
- 掩码重加权(Masking & Reweighting):
- 修改 Attention 的计算公式: A t t e n t i o n ( Q , K , V ) = S o f t m a x ( Q K T d + M ) V Attention(Q, K, V) = Softmax(\frac{QK^T}{\sqrt{d}} + M)V Attention(Q,K,V)=Softmax(dQKT+M)V。
- 矩阵 M M M (Mask):被设计用来阻断特定的交互。例如,限制模板 Token 过度关注搜索区域的背景 Token,或者限制搜索区域的背景 Token 来“污染”模板的特征更新。
- 工作机制:通过这种强制的“注意力路由”,模型被迫专注于目标本身及其上下文,大大降低了漂移(Drift)到干扰物上的风险。
4.3 理念与机制总结
CPDATrack 的成功在于其**“先保全,再聚焦”**的理念:
- CTP (Context-Aware Token Pruning):负责保全。它承认“背景也有价值”,通过保留目标周边的上下文,保证了特征的完整性。
- DSA (Discriminative Selective Attention):负责聚焦。在保留下来的 Token 中,通过注意力机制进一步区分“谁是真正的目标”,剔除难样本(Hard Negative)的干扰。
4.4 图解总结
回到动机图解(图1),CPDATrack 之所以能画出右图那样干净且完整的注意力图,正是因为:
- CTP 先把无关的草地、天空等背景物理剔除了(减少了计算量)。
- CTP 的“膨胀”操作把运动员身体边缘的像素留住了(保留了形状)。
- DSA 确保了剩下的 Token 中,注意力不会跑偏到旁边穿着相似衣服的人身上(抗干扰)。
5. 即插即用模块的作用
本文提出的 CTP 和 DSA 模块具有很好的通用性:
-
CTP 模块的应用场景:
- 视频目标分割 (VOS):视频中相邻帧变化不大,背景冗余极高,使用 CTP 可以显著加速 Video Transformer。
- 动态场景的检测:在计算资源受限的端侧设备上,可以用 CTP 替换标准的 Patch Embedding 或早期层,实现“动态推理”。
-
DSA 模块的应用场景:
- ReID (行人重识别):DSA 天然适合解决 ReID 中的背景干扰问题,强迫模型只关注人体区域。
- Few-shot Learning:在样本很少的情况下,DSA 可以帮助模型更集中地提取关键特征,避免过拟合背景。
6. 实验部分简单分析
论文在 LaSOT, TNL2K, TrackingNet 等权威数据集上进行了验证。
-
精度 vs. 速度:
- 在 LaSOT 上,CPDATrack 取得了 70.5% 的 SUC (Success Score),这一成绩优于基线 OSTrack (69.1%)。
- 更重要的是,FLOPs 降低了 37.6%(从 21.6G 降至 13.5G),FPS 显著提升。这说明剪枝策略不仅没有掉点,反而因为去除了噪声而涨点了。
-
抗干扰能力:
- 在包含大量干扰物(Distractors)的属性子集测试中,CPDATrack 的表现明显优于对比方法,验证了 DSA 模块在抑制假阳性方面的有效性。
-
可视化效果:
- 论文展示的定性结果图中,在目标被部分遮挡或背景杂乱时,CPDATrack 依然能紧紧咬住目标,而没有漂移到相似背景上。
总结:这是一篇非常扎实的“做减法”的论文。它告诉我们,在 Transformer 时代,不仅要卷更大的模型,更要卷更聪明的计算方式。保留上下文的剪枝策略(Context-Aware)是未来轻量化模型设计的一个重要方向。
到此,所有的内容就基本讲完了。如果觉得这篇文章对你有用,记得点赞、收藏并分享给你的小伙伴们哦😄。
7. 获取即插即用代码关注 【AI即插即用】

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 7
7 0
0- 0



 已为社区贡献13条内容
已为社区贡献13条内容

所有评论(0)