大模型工具调用能力揭秘:SFT、RLHF与蒸馏如何让AI“学会”调用工具?
文章深入探讨了大型语言模型如何获得工具调用能力。首先指出预训练模型由于仅限于文本预测而无工具调用能力。随后详细解析了三个核心训练阶段:SFT(监督微调)通过示范教会模型输出JSON格式的工具调用请求;RLHF(基于人类反馈的强化学习)则教会模型判断何时调用工具;蒸馏技术则将大模型的能力迁移至小模型。文章还介绍了LoRA作为SFT的高效实现手段,以及运行时模型决策与执行的解耦机制,并总结了三者组合的最佳实践。
大模型工具调用能力是怎么来的
它怎么就"学会"了看到工具描述之后输出一段 JSON?
本文从预训练的局限出发,逐层拆解 SFT(教动作)、RLHF(教克制)和蒸馏(教迁移)如何赋予大模型工具调用能力,并延伸到 LoRA 高效微调的原理。
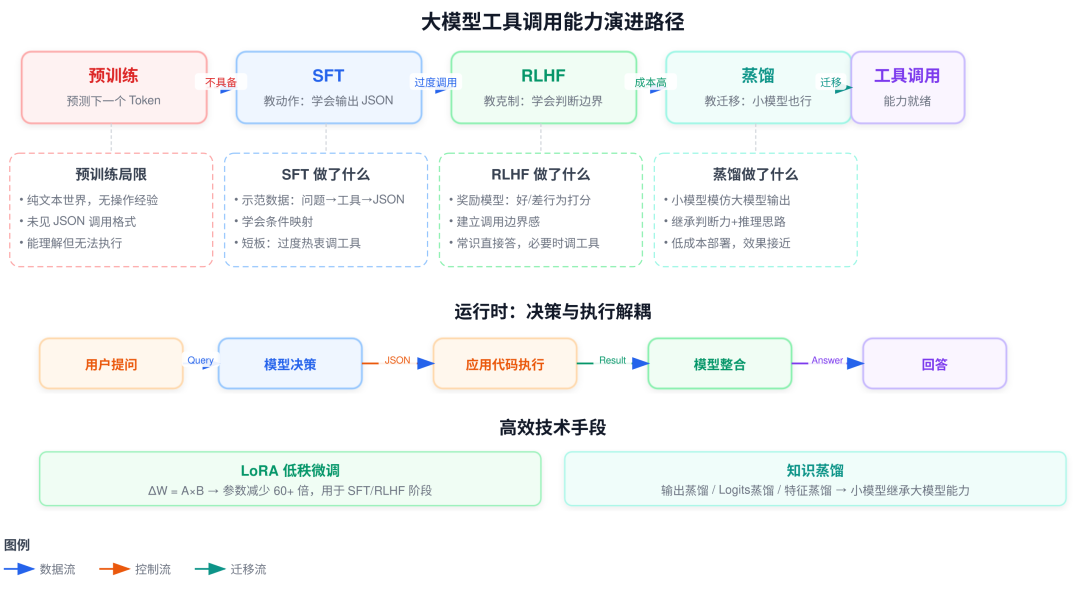
一、问题起源:原始大模型为什么不会调工具
这个问题是理解后面所有内容的前提。
大模型在预训练阶段做的事情本质上只有一件:给一段文本,预测下一个 token。它在互联网上几乎所有的公开文本上训练过——百科、新闻、论文、代码、论坛帖子……但整个训练过程都发生在纯文本的世界里。模型从来没有"操作过"任何外部系统,也从来没有见过"输出一段 JSON 触发一次 API 调用"这种行为模式。
类比:只读书不动手的人
一个人从小到大只读书、不动手。他读过无数本关于烹饪的书,知道"热锅凉油"四个字怎么写,但从来没有摸过锅铲。你突然把他扔进厨房,递给他一把铲子说"炒个菜",他是没法直接上手的——他对"炒菜"的认知还停留在文字描述层面,没有变成可以执行的动作模式。
原始大模型面对工具调用的处境一样。你在 System Prompt 里告诉它"你有一个查库存的工具",它能理解这句话的意思,甚至可能回复"好的,我来帮你查一下库存"——但它不会输出一段结构化的 JSON 调用请求,因为训练数据里从来没有这种格式的输出。
**结论:工具调用能力必须靠后天专门的训练来注入。 *
二、核心原理:三阶段训练的分工逻辑
| 阶段 | 核心比喻 | 学习方式 | 解决的问题 |
|---|---|---|---|
| SFT | 师傅带徒弟 | 看标准示范,依葫芦画瓢 | 学会技能(如输出 JSON 格式) |
| RLHF | 教练看比赛 | 尝试多种方案,根据反馈优化 | 学会判断(如该不该用工具) |
| 蒸馏 | 名师出高徒 | 模仿大模型输出,小模型继承能力 | 学会迁移(小模型也能调工具) |
2.1 SFT 阶段:从"文本预测"到"逻辑填空"
在预训练阶段,模型只知道"天气"后面可能接"很好"。但在 SFT 之后,它学到了一个新的隐性模式匹配:
- 输入: System(Tools: [A, B]) + User(Query)
- 输出概率分布: 指向 {“tool_calls”: …} 的概率被大幅拉高
关键点: 此时模型学会的是**“条件映射”**。它把 System Prompt 里的 JSON Schema 当成了"填空题的模版",把用户问题当成了"题干"。
SFT 的一个关键短板
SFT 教会了模型"怎么调工具",但有一个明显的盲区:模型不太会判断"该不该调"。
训练数据绝大多数都是"需要调工具"的正样本——毕竟你要教模型学会调用,当然得给它看调用的示范。但副作用是:模型训练之后会变得过度热衷调工具。
你问"3×7 等于多少",它不去直接说 21,反而去调一个计算器。你问"太阳从哪边升起",它可能去调搜索引擎。这些问题它本来就知道答案,但因为训练数据里"调工具"这个动作得到了太多正向强化,模型形成了"有工具就调"的惯性。
这个问题,SFT 自己解决不了,需要第二阶段的 RLHF 来矫正。
2.2 RLHF 阶段:建立"调用成本"意识
SFT 容易让模型变"傻"。RLHF 的本质是给模型注入一套价值函数:
| 场景 | 模型行为 | 奖励得分 | 原因 |
|---|---|---|---|
| 问"1+1",模型调计算器 | 过度调用 | -5 | 浪费 Token,响应慢 |
| 问"1+1",直接回"2" | 简洁高效 | +5 | 正确且高效 |
| 问"深圳明天穿什么",模型查天气再回答 | 必要调用 | +10 | 必要且准确 |
三、详细解析:训练流程拆解
3.1 SFT:教模型"看示范、学动作"
SFT 全称 Supervised Fine-Tuning(监督微调)。类比到职场,就像新员工入职培训的第一周:师傅领着你,手把手演示流程——“遇到这种情况该填这个表,走这个审批”,看十遍二十遍,自然就学会了。
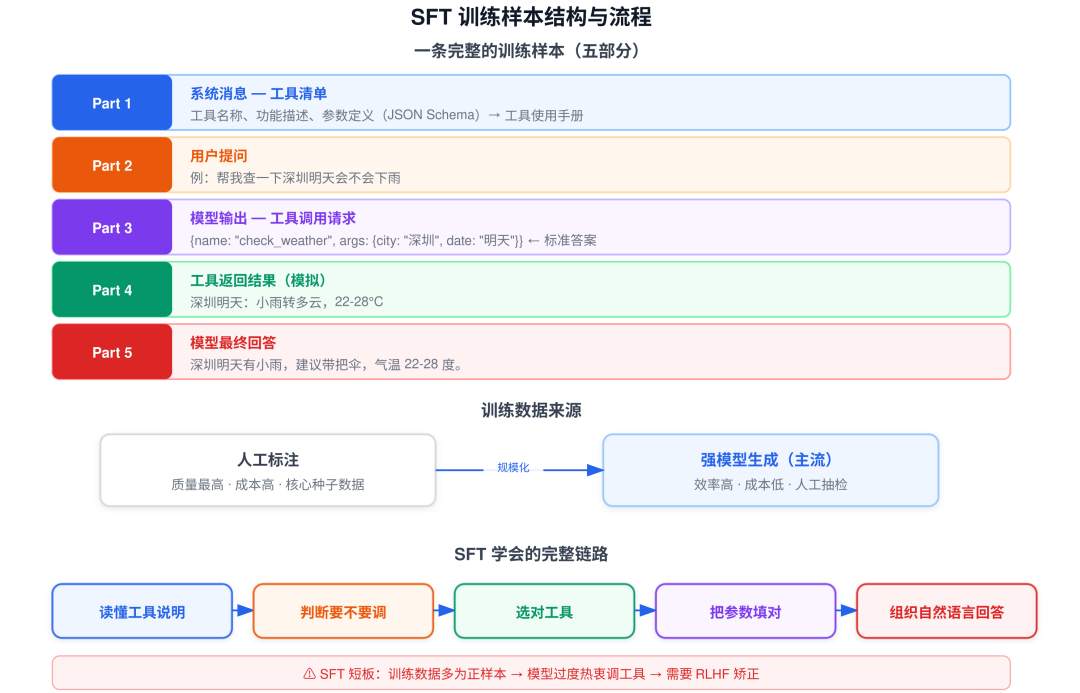
训练样本的五部分结构
每条训练样本是一个完整的多轮对话,至少包含五个部分:
┌──────────────────────────────────────────────────────────┐
│ Part 1: 系统消息 — 工具清单 │
│ 列出每个工具的名称、功能描述、参数定义(JSON Schema) │
│ → 相当于给模型发了一份"工具使用手册" │
├──────────────────────────────────────────────────────────┤
│ Part 2: 用户提问 │
│ 例:"帮我查一下深圳明天会不会下雨" │
├──────────────────────────────────────────────────────────┤
│ Part 3: 模型应输出的工具调用请求(JSON 格式) │
│ {"tool_calls": [{"name": "check_weather", │
│ "arguments": {"city": "深圳", "date": "明天"}}]} │
│ → 这就是模型需要学会输出的"标准答案" │
├──────────────────────────────────────────────────────────┤
│ Part 4: 工具执行后的返回结果(训练时模拟) │
│ → "深圳明天:小雨转多云,22-28°C" │
├──────────────────────────────────────────────────────────┤
│ Part 5: 模型拿到结果后的最终自然语言回答 │
│ → "深圳明天有小雨,建议带把伞,气温 22-28 度。" │
└──────────────────────────────────────────────────────────┘
模型在几十万甚至上百万条这样的样本上训练,就能学会整套链路:
读懂工具说明 → 判断要不要调 → 选对工具 → 把参数填对 → 拿到结果后组织自然语言回答
训练数据从哪来?
| 渠道 | 方法 | 优势 | 劣势 |
|---|---|---|---|
| 人工标注 | 工程师构造问题+标准答案 | 质量最高 | 成本高,通常用于核心种子数据 |
| 强模型生成 | 用 GPT-4 等批量生成,人工抽检 | 效率高、成本低、可规模化 | 需要抽检把控质量 |
目前业界主流做法是强模型批量生成 + 人工抽检。
3.2 RLHF:教模型"什么时候该克制"
RLHF 全称 Reinforcement Learning from Human Feedback(基于人类反馈的强化学习)。如果 SFT 是新员工的入职培训,RLHF 就是他工作几个月后,主管根据实际表现给的持续反馈:这件事处理得好,加分;那件事过度操作了,减分。时间一长,他就知道了什么场景下该积极行动、什么场景下该保持克制。
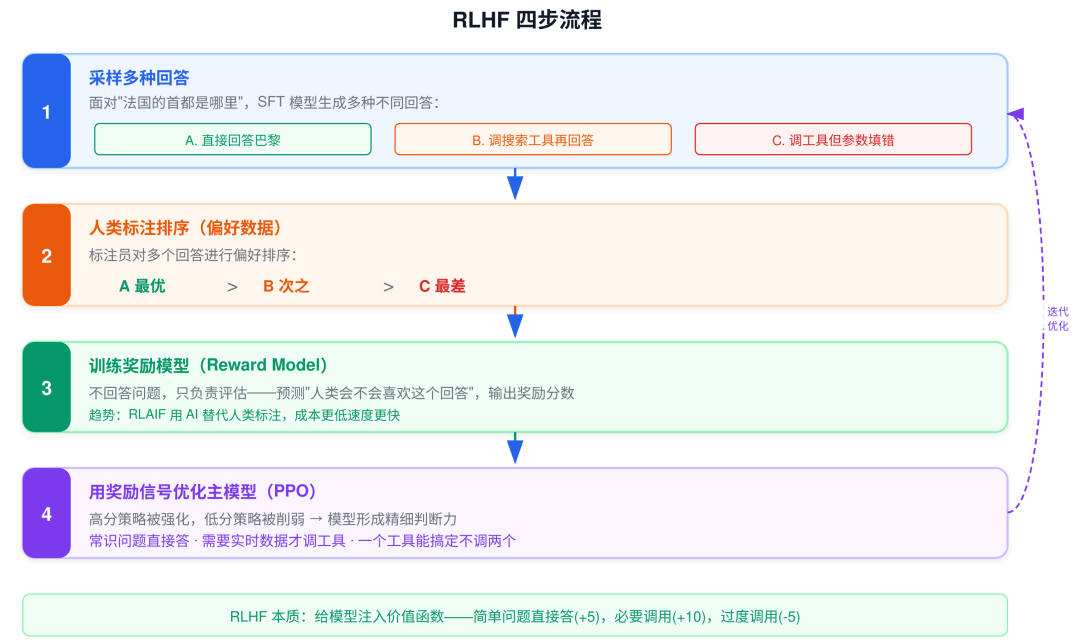
RLHF 的四步流程
Step 1: 采样多种回答
面对"法国的首都是哪里",模型生成三种回答:
A. 直接回答"巴黎"
B. 调搜索工具查一下再回答
C. 调了工具但参数填错了
Step 2: 人类标注排序
A > B > C(直接回答最好,过度调用次之,调用出错最差)
Step 3: 训练奖励模型(Reward Model)
不回答问题,只负责评估——预测"人类会不会喜欢这个回答"
Step 4: 用奖励信号优化主模型
高分策略被强化,低分策略被削弱
→ 模型形成精细判断力:常识直接答,需要实时数据才调工具
趋势: 业界也在用 RLAIF(AI Feedback) 替代人类标注——用另一个大模型充当"标注员"做偏好判断,成本更低、速度更快,效果与人工标注的差距越来越小。
四、运行时机制:决策与执行解耦
理解了训练过程,再看运行时的调用流程就清晰了。
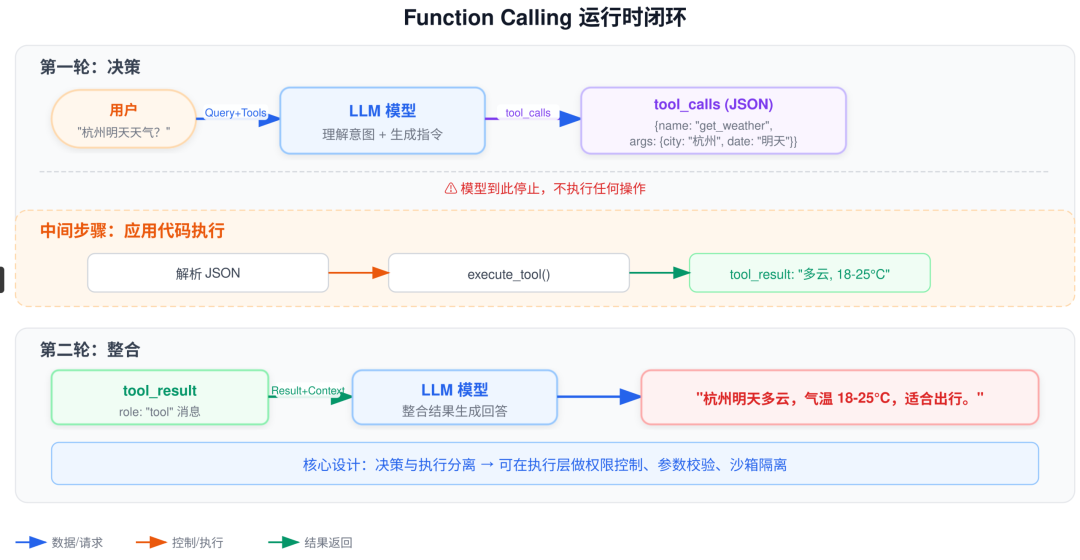
4.1 运行时闭环流程
| 步骤 | 主体 | 动作 | 产物 |
|---|---|---|---|
| 1. 决策 | 模型 | 理解意图,生成指令 | tool_calls (JSON) |
| 2. 执行 | 应用代码 | 解析 JSON,发起网络请求 | tool_result (Raw Data) |
| 3. 整合 | 模型 | 结合原始问题 + 执行结果 | 自然语言答案 |
4.2 代码层面的直观感受
# 伪代码:Function Calling 的运行时闭环
import json
# 第一轮:把工具定义和用户问题一起传给模型
response = llm.chat(
messages=[{"role": "user", "content": "帮我查一下杭州明天的天气"}],
tools=weather_tool_schema # 工具说明书
)
# 模型判断需要调工具,返回 tool_calls
if response.finish_reason == "tool_calls":
call = response.tool_calls[0]
func_name = call.name # "get_weather"
func_args = json.loads(call.arguments) # {"city": "杭州", "date": "明天"}
# 你的代码去真正执行
result = execute_tool(func_name, func_args)
# 第二轮:把执行结果喂回模型
messages.append(response.message)
messages.append({"role": "tool", "tool_call_id": call.id, "content": result})
final = llm.chat(messages=messages, tools=weather_tool_schema)
print(final.content) # "杭州明天多云,气温 18-25°C,适合出行。"
核心要点: 模型全程只做决策,不做执行。它只是输出一段 JSON 说"我要调 get_weather,参数是杭州和明天"。既没有访问网络,也没有调用任何 API。真正干活的是你写的
execute_tool函数。
4.3 "决策与执行分离"的设计意义
这个架构设计非常重要——它意味着你可以在执行层做权限控制、参数校验、沙箱隔离,而不用担心模型直接操作系统资源带来的安全风险。
五、延伸:LoRA —— SFT 的高效实现手段
LoRA 属于 SFT 阶段的一种高效实现手段,不属于 RLHF,也不属于预训练。
5.1 本质理解
LoRA 全称 Low-Rank Adaptation(低秩自适应)。
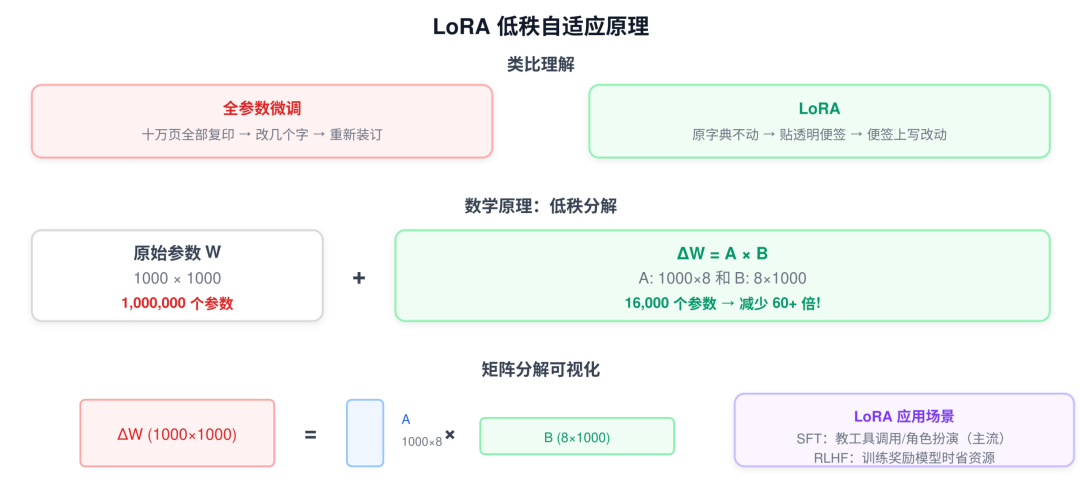
把大模型比作一本十万页的字典(原始参数 WW),微调的过程就是要在字典上改动一些内容:
| 方法 | 类比 | 特点 |
|---|---|---|
| 全参数微调 | 把十万页全部复印一遍,在上面改几个字,再装订成一本新字典 | 费钱、费显存 |
| LoRA | 不改原字典,拿一张透明便签纸贴在相关页码上,只在便签上写改动内容,查字典时把原书内容和便签内容加在一起看 | 极其高效 |
5.2 数学直觉:为什么叫"低秩"?
大模型参数矩阵通常是极其巨大的(高维度),但研究发现,让模型学会某个特定任务,其实不需要改动所有参数——参数的变化落在一个很小的维度空间里。
LoRA 将巨大的参数增量矩阵 ΔW 分解为两个极小的矩阵相乘:
ΔW=A×B
原始矩阵:1000 × 1000 → 1,000,000 个参数
LoRA 分解:1000 × 8 和 8 × 1000 → 16,000 个参数
→ 参数量减少了 60+ 倍!
→ 这就是为什么你在笔记本显卡上就能微调大模型的原因。
5.3 LoRA 与 SFT/RLHF 的关系
虽然 LoRA 最常用于 SFT 阶段,但它其实是一个通用的"减负工具":
- 在 SFT 中: 用 LoRA 来教模型学会"工具调用"、“角色扮演"或"特定领域知识”。这是目前最主流的用法。
- 在 RLHF 中: RLHF 过程也需要训练模型(训练奖励模型或优化策略模型),为了省资源,同样可以使用 LoRA 来完成这些环节中的微调。
六、延伸:知识蒸馏——让小模型也能调工具
SFT 和 RLHF 把大模型训练好了,但大模型太贵太慢。能不能让小模型也拥有工具调用能力?这就是蒸馏要解决的问题。
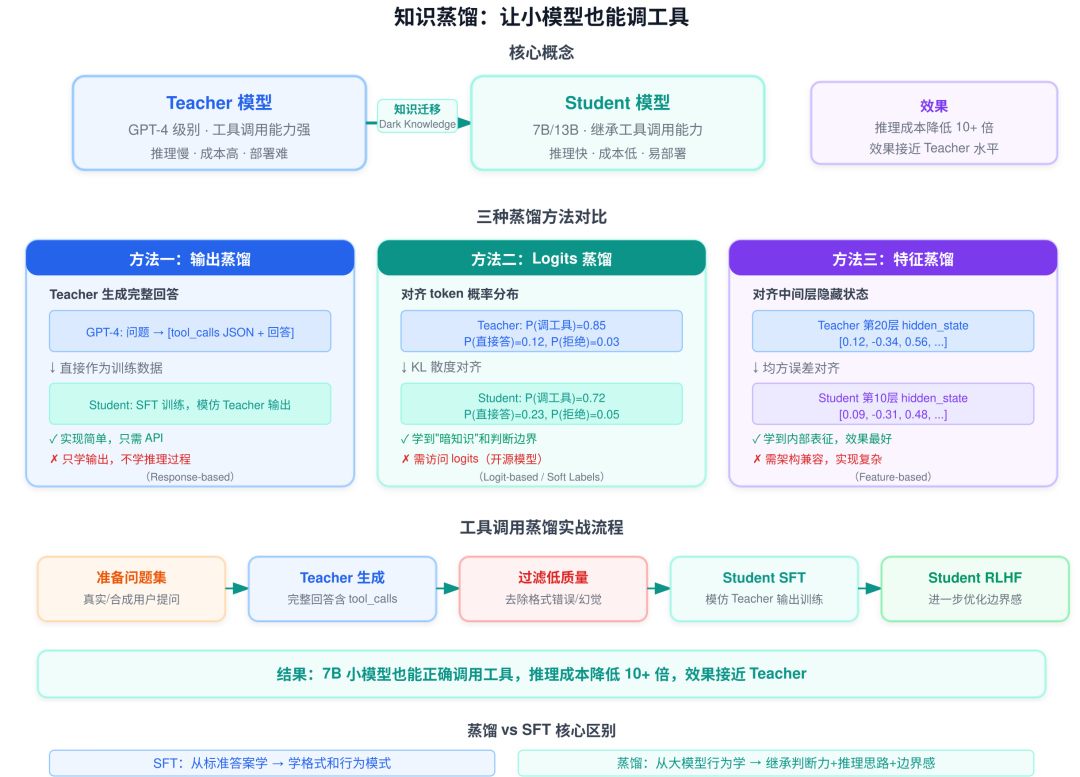
6.1 为什么需要蒸馏
GPT-4 级别的大模型虽然工具调用能力出色,但部署成本极高——推理慢、显存大、API 贵。而实际业务中,大量场景可以用 7B、13B 的小模型来服务,只要它们也能"看懂工具描述、输出正确 JSON、判断该不该调"。
蒸馏的核心目标:把大模型的能力迁移到小模型上,用极低的成本获得接近大模型的效果。
6.2 蒸馏的本质:从"学知识"到"学行为"
普通 SFT 教小模型用的是"标准答案"——一条条人工构造的 问题→JSON调用→回答。但蒸馏不同,它让小模型直接模仿大模型的行为输出。
类比到职场:
| 方式 | 类比 | 学到的东西 |
|---|---|---|
| SFT | 读教科书学标准答案 | 知道"该怎么做",但不够灵活 |
| 蒸馏 | 跟着资深员工看他怎么处理各种情况 | 学到"怎么灵活应对",包括大模型的推理思路 |
6.3 蒸馏的三种主要方法
方法一:输出蒸馏(Response-based)
最简单直接的方式。拿一大批问题,先让大模型(Teacher)生成完整回答(包括工具调用的 JSON),再用这些 <问题, 大模型回答> 对作为训练数据来教小模型(Student)。
Teacher (GPT-4): 问题 → [完整回答,含 tool_calls JSON]
↓
Student (7B): 同一问题 → 学习模仿 Teacher 的输出
优点: 实现简单,只需调用大模型 API 生成数据 缺点: 只能学到最终输出,学不到大模型的中间推理过程
方法二:Logits 蒸馏(Logit-based)
比输出蒸馏更精细。不仅让小模型学大模型的最终答案,还要学大模型对每个 token 的概率分布(即 logits 或 soft labels)。
Teacher: "深圳明天天气" → P(调工具)=0.85, P(直接答)=0.12, ...
↓ KL 散度对齐
Student: "深圳明天天气" → P(调工具)=0.72, P(直接答)=0.23, ...
小模型的训练目标是同时优化:
- 硬标签损失: 和标准答案的交叉熵
- 软标签损失: 和大模型 logits 的 KL 散度
关键洞察: 大模型的概率分布包含丰富的"暗知识"(Dark Knowledge)——比如它认为"调工具"概率 0.85、"直接回答"0.12,这个分布本身就包含了判断边界的精细信息,而不仅仅是"该调"或"不该调"的二选一。
优点: 能学到更细粒度的判断能力,小模型效果更接近大模型 缺点: 需要访问大模型的 logits 输出(开源模型才行,API 通常不提供)
方法三:特征蒸馏(Feature-based)
最深层的方式。不仅对齐输出,还对齐大模型中间层的隐藏状态(hidden states)和注意力模式。
Teacher 第20层: [hidden_state = [0.12, -0.34, 0.56, ...]]
↓ 均方误差对齐
Student 第10层: [hidden_state = [0.09, -0.31, 0.48, ...]]
优点: 小模型能学到与大模型相似的内部表征,效果最好 缺点: 需要大模型和小模型的架构兼容,实现复杂度高
6.4 蒸馏在工具调用中的实战策略
业界做工具调用蒸馏的典型流程:
Step 1: 准备大量真实/合成的用户提问
↓
Step 2: 用 Teacher 模型(如 GPT-4)生成完整回答
- 包含判断:该不该调工具
- 包含调用:tool_calls JSON
- 包含整合:基于工具结果的自然语言回答
↓
Step 3: 过滤低质量样本(格式错误、幻觉回答等)
↓
Step 4: 用这批数据对 Student 模型做 SFT
↓
Step 5: (可选)再对 Student 做 RLHF 微调,进一步优化
↓
结果:7B 小模型也能正确调用工具,推理成本降低 10+ 倍
6.5 蒸馏 vs SFT 的关键区别
| 维度 | SFT(从零教) | 蒸馏(从大模型学) |
|---|---|---|
| 训练数据来源 | 人工标注 / 规则生成 | 大模型生成 |
| 数据质量 | 依赖标注质量 | 继承大模型的判断力 |
| 学到的内容 | 标准行为模式 | 大模型的推理+判断+边界感 |
| 成本 | 标注成本高 | API 调用成本(但可批量) |
| 效果上限 | 受限于标注数据的多样性 | 接近 Teacher 模型的水平 |
| 典型场景 | 训练初始能力 | 将能力迁移到小模型 |
实际组合: 业界最佳实践是 SFT(建立基础能力)→ RLHF(建立边界感)→ 蒸馏(迁移到小模型) 三步组合。先用 SFT+RLHF 把大模型训练好,再通过蒸馏把能力迁移到部署友好的小模型上。
七、总结:完整的认知链条
会用 Function Calling 的人很多,但大多数人的认知链条是:
定义 tools → 调 API → 解析 tool_calls → 执行 → 返回结果
这条链条是运行时的操作流程,不涉及任何原理。面试官一追问"这个能力怎么来的",链条就断了。
真正理解原理的人,脑子里的链条更深一层:
预训练阶段模型不具备工具调用能力 → SFT 阶段通过示范数据教会模型输出结构化调用请求 → RLHF 阶段通过偏好反馈教会模型判断什么时候该调、什么时候不该调 → 蒸馏阶段将大模型的能力迁移到小模型 → 运行时模型只做决策,宿主代码做执行
三个常见翻车点
| # | 翻车点 | 正确理解 |
|---|---|---|
| 1 | 混淆 SFT 和 RLHF 的分工 | SFT 教的是"工具调用的完整行为模式"(识别描述→判断调用→生成 JSON→整合结果);RLHF 教的是"在什么场景下应该/不应该调用"——即调用的边界感 |
| 2 | 以为 Function Calling 是模型"自己去执行" | 模型不执行任何东西,它只输出一段 JSON 指令。真正发起 HTTP 请求、访问数据库、执行代码的,始终是应用程序 |
| 3 | 说不清训练数据怎么来的 | 核心种子数据靠人工标注保证质量,大规模数据靠更强的模型批量生成再人工抽检 |
| 4 | 混淆蒸馏和 SFT | SFT 是"从标准答案学",蒸馏是"从大模型的行为学";蒸馏能继承大模型的判断边界和推理思路,而不只是格式 |
加分项: 如果你在面试里能加上实战经验——“我在项目里遇到过模型过度调工具的问题,后来在 Prompt 里加了明确的指导规则,让模型只在确实需要外部数据时才触发调用,误调率降了不少”——这种补充会让面试官觉得你不是在背概念。
假如你从2026年开始学大模型,按这个步骤走准能稳步进阶。
接下来告诉你一条最快的邪修路线,
3个月即可成为模型大师,薪资直接起飞。
阶段1:大模型基础

阶段2:RAG应用开发工程

阶段3:大模型Agent应用架构

阶段4:大模型微调与私有化部署

配套文档资源+全套AI 大模型 学习资料,朋友们如果需要可以微信扫描下方二维码免费领取【保证100%免费】👇👇





配套文档资源+全套AI 大模型 学习资料,朋友们如果需要可以微信扫描下方二维码免费领取【保证100%免费】👇👇


AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 11
11 0
0- 0



 已为社区贡献164条内容
已为社区贡献164条内容

所有评论(0)