彻底理解Java NIO(一)C语言实现 单进程+多进程+多线程 阻塞式I/O 服务器详解
文章目录
前言
有时候排查一些问题,避免不了要看一些Java框架的源码,和外部有网络交互功能的框架,现在基本上都使用了reactor模式。虽然看过很多文章讲解reactor模式及其相关知识,时间一长总是忘,面对源码时,还是一头雾水。所以还是彻底理解它比较好,通过自己实现一个极简socket服务器来理解。一开始用C来实现,到最后用Java实现以从底层彻底理解I/O多路复用、select、epoll、reactor等这些技术的使用过程
最简单的socket服务器
服务器整体流程
要想让服务器服务外部,基本是以下几个步骤
- 创建socket
- 给socket绑定一个地址和端口
- 允许服务器接受连接
- 等待并接受新连接
- 接收新连接后读写数据
- 关闭新连接
- 重复步骤4-6
服务器C代码实现
-
创建socket本质上是打开一个文件,返回其文件描述符
int make_socket() { int sockfd; sockfd = socket(AF_INET, SOCK_STREAM, 0); if (sockfd < 0) { perror("socket"); exit(EXIT_FAILURE); } int flags = fcntl(sockfd, F_GETFL, 0); if (flags < 0) { perror("fcntl"); exit(EXIT_FAILURE); } if (!(flags & O_NONBLOCK)) { printf("socket is blocking I/O\n"); } return sockfd; }
关于文件
打开文件时,可以指定文件访问模式,例如:O_RDWR代表以读写方式开文件和操作标志,例如:O_NONBLOCK代表以非阻塞方式打开
read,write等系统调用是否为阻塞还是非阻塞,取决于底层文件的操作标志,如果没有O_NONBLOCK标志则为阻塞式读/写
socket默认以阻塞式方式打开
关于文件描述符
内核对于文件和文件描述符,维护了3张表
-
进程级别的文件描述符表,又叫descriptor table/open file descriptor。每个进程都有它自己的文件描述符表,这个表中有1列是系统级打开文件表的引用,这个引用指向第2张表-系统级打开文件表。这里使用引用而不是指针,是因为代码使用C实现,用指针容易混淆,不理解的同学,暂且可以把它理解为ID,例如第二张表的数据的ID
-
系统级别的打开文件表,又叫open file table。所有进程表的文件引用都可以在这个表中找到。
-
不同进程表的文件引用很可能会指向这张表的同一项,例如:fork()系统调用,创建子进程时,子进程会获得父进程所有文件描述符的副本,这意味着父、子进程中对应的引用指向相同的open file table的一项。所以这个表中还有一个最重要的列叫引用计数, reference count,如果这行数据又被另外一个进程引用,那么引用计数+1;
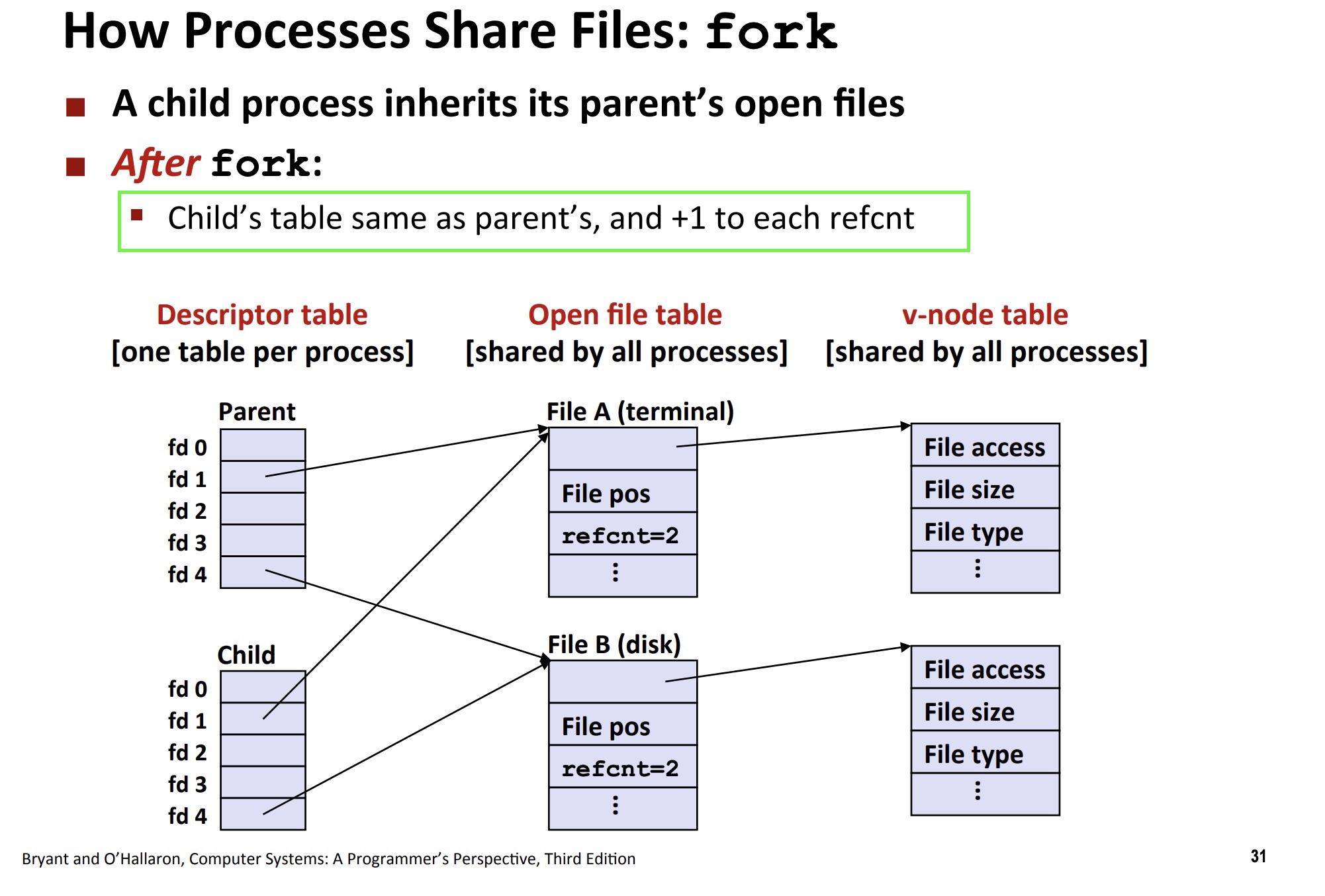
截图来自于CSAPP 深入理解计算机系统教学课件
如果进程关闭资源,例如close()系统调用,则引用计数-1。重要的是:只有当引用计数变为0后,内核才会真正去释放底层资源,例如:TCP 4次挥手真正开始,发送第1个FIN包(如果是主动关闭的话),或者发送第二个FIN包(如果是被动关闭的话)
-
每个进程可持有的文件描述符数量是有限制的,同时系统也限制了所有进程能够打开的文件数量
-
同样,这个表中也有1列是真正的文件的i-node的引用,这个引用指向第3张表-文件系统的i-node表
-
-
文件系统的i-node表。可以简单理解为:文件系统会把所有的文件都登记在这张表中,每1行数据1个文件
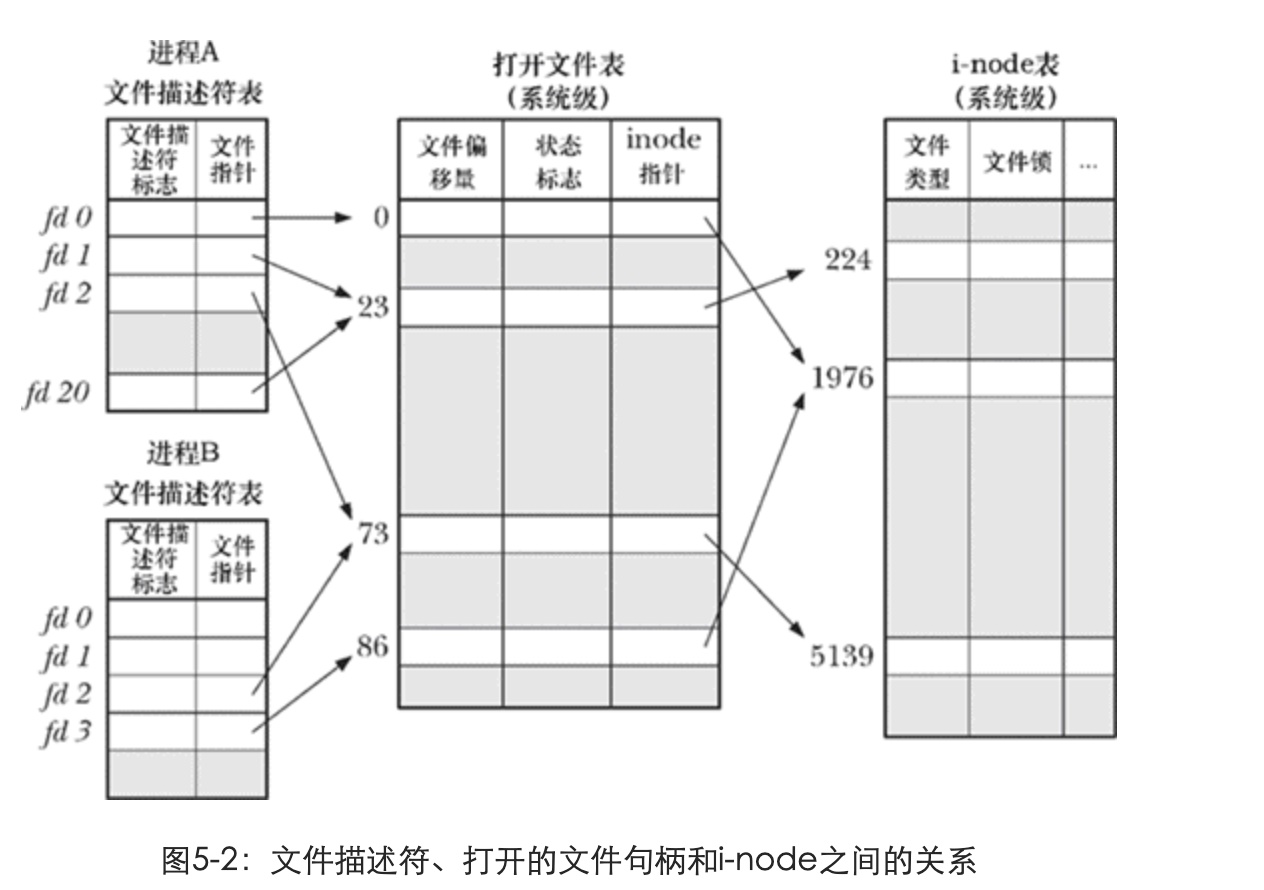
-
给socket绑定一个地址和端口并通过listen来允许服务器接受连接
#define SERVER_PORT 18080 int bind_server_socket_to_port_and_listen() { int sockfd = make_socket(); struct sockaddr_in server_addr_info; server_addr_info.sin_family = AF_INET; server_addr_info.sin_port = htons(SERVER_PORT); server_addr_info.sin_addr.s_addr = INADDR_ANY; if (bind(sockfd, (struct sockaddr *)&server_addr_info, sizeof(server_addr_info)) < 0) { perror("bind"); close(sockfd); exit(EXIT_FAILURE); } if (listen(sockfd, SOMAXCONN) < 0) { perror("listen"); close(sockfd); exit(EXIT_FAILURE); } return sockfd; }
网络字节序
关于htons函数的说明:htons 全称 host to network short, 将一个16位整数从主机字节序转换为网络字节序。IP地址和端口号是整数值。在将这些值在网络中传递时碰到的一个问题是不同类型的计算机的硬件结构会以不同的顺序来存储一个多字节整数的字节,即大端存储和小端存储。为了统一,网络协议规定了一个标准的字节顺序,称为网络字节序,使用大端存储。使用一些特定的函数可以将一个整数转为标准的网络字节序,然后把转换后的整数写入套接字地址结构中传递出去,这样无论发送方和接收方的计算机使用什么样的字节顺序,网络协议都能正确地解释这些整数值
backlog 参数
backlog参数是指在TCP3次握手完成之后,如果此时服务器线程还没有使用accept来接收连接,那么新到的连接就会排队。这个排队的长度就是backlog。
如果已经完成了TCP3次握手时最后一次服务端ACK时,发现连接队列满了,那么内核可能会丢掉最后一次的ACK包,然后重发SYN+ACK,如果重发多次,accept queue一直是满的,那么最终服务端可能会放弃该半连接。反应在客户端的现象就是:TCP握手成功了,但是发送数据超时了
Client Kernel (Server) App
| | |
|──── SYN ────────→| |
| | 放入 SYN 队列 |
|←── SYN-ACK ──────| |
| | |
|──── ACK ────────→| |
| | Accept 队列满了? |
| | ├── 否 → 放入 Accept 队列 → 等待 accept()
| | └── 是 → 丢弃 ACK (或发 RST)
| | |
| (客户端以为连接建立了!) |
| (但服务端 accept 队列没有它) |
一般使用SOMAXCONN这个macro,如果想测试我说的这种情况,可以将上述代码中的listen的第二个参数改为1,然后在服务器端处理请求时休眠几秒,同时发起多个请求看看,即可验证
-
处理请求并关闭连接
#define BUFFER_SIZE 512 #define MESSAGE "I have received your message" int read_from_client(int client_socket) { char buffer[BUFFER_SIZE]; int bytes_read = read(client_socket, buffer, BUFFER_SIZE); if (bytes_read < 0) { perror("read"); exit(EXIT_FAILURE); } else if (bytes_read == 0) { return -1; } fprintf(stdout, "got message: '%s'\n", buffer); return 0; } void handle_request(int client_socket) { while (1) { if (read_from_client(client_socket) <= 0) { write(client_socket, MESSAGE, strlen(MESSAGE) + 1); close(client_socket); printf("close client socket\n"); break; } } }
单进程服务器
单进程服务器也叫迭代型服务器,服务器只有1个主进程。接受连接,处理请求,返回;然后再重复该步骤
int server_that_can_only_process_requests_iteratively()
{
int server_socket = bind_server_socket_to_port_and_listen();
while (1)
{
struct sockaddr_in client_socket;
socklen_t addr_len = sizeof(client_socket);
printf("server is ready for accept connection......\n");
int new_client_socket = accept(server_socket, (struct sockaddr *)&client_socket, &addr_len);
if (new_client_socket < 0)
{
perror("accept");
exit(EXIT_FAILURE);
}
fprintf(stdout,
"Server: connect from host %s, port %hd.\n",
inet_ntoa(client_socket.sin_addr),
ntohs(client_socket.sin_port));
handle_request(new_client_socket);
}
}
这种服务器每次只处理一个客户端,只有当完全处理完一个客户端的请求后才去处理下一个客户端。没有任何并发能力
多进程服务器
具有并发能力的服务器叫并发型服务器,并发型服务器可以有多种实现,例如:多进程,多线程
int server_that_can_process_requests_concurrently_using_child_process()
{
int server_socket = bind_server_socket_to_port_and_listen();
while (1)
{
/*
如果不关心客户端的连接信息,则后面2个参数可以传NULL
*/
int new_client_socket = accept(server_socket, NULL, NULL);
if (new_client_socket < 0)
{
perror("accept");
exit(EXIT_FAILURE);
}
printf("Server: new client connected.");
switch (fork())
{
case -1:
close(new_client_socket);
break;
case 0:
close(server_socket);
handle_request(new_client_socket);
_exit(0);
default:
close(new_client_socket);
break;
}
}
}
fork()系统调用后,会存在2个进程,然后这2个进程都会从fork()的返回处继续执行代码。根据前面有关文件描述符的知识,就可以知道
-
为什么对于子进程要去关闭用于监听的文件描述符?
因为子进程需要处理实际的客户端的连接,不需要处理接收连接这个事,这是父进程要干的事。所以要把server_socket关闭以使得server_socket文件描述符的引用计数-1
-
为什么对于父进程要去关闭用于处理请求的文件描述符?
因为父进程不关心连接后的事情,它只负责监听连接,所以要把new_client_socket关闭以使得new_client_socket文件描述符的引用计数-1。即使子进程在请求处理完了会关闭连接,如果父进程不关闭new_client_socket文件描述符,那么内核不会真正发起关闭TCP连接动作,因为引用计数不为0,反映在TCP 4次挥手层面就是,服务器端不会主动发起关闭连接;或即使客户端主动发起关闭连接,但服务器存在大量CLOSE-WAIT的连接。同时如果它不关闭这个文件描述符,那么它持有的文件描述符数量会一直增加,从而导致父进程持有文件描述符的数量达到系统限制
进程的缺点就是太重了,fork系统调用代价比较高
多线程服务器
void *handle_request_for_threads(void *client_socket)
{
int client_fd = *(int *)client_socket;
free(client_socket);
printf("thread is %lu\n", (unsigned long)pthread_self());
handle_request(client_fd);
return NULL;
}
int server_that_can_process_requests_concurrently_using_thread()
{
int server_socket = bind_server_socket_to_port_and_listen();
while (1)
{
int new_client_socket = accept(server_socket, NULL, NULL);
if (new_client_socket < 0)
{
perror("accept");
exit(EXIT_FAILURE);
}
pthread_t client_thread;
int *pclient = malloc(sizeof(int));
if (pclient == NULL)
{
perror("malloc");
exit(EXIT_FAILURE);
}
*pclient = new_client_socket;
int create_result = pthread_create(&client_thread, NULL, handle_request_for_threads, pclient);
if (create_result != 0)
{
perror("pthread_create");
exit(EXIT_FAILURE);
}
pthread_detach(client_thread);
}
}
由于pthread_create函数最后1个参数是指针类型,所以要在该方法调用前声明1个指针并为其分配内存,并把接受到的新连接的值赋给这个指针,为什么这样做?
如果直接传&new_client_socket,假设此时子线程创建完还没拿到CPU的执行权,此时主线程又accept了另外一个客户端,此时子线程再拿这个new_client_socket对应的内存地址数据,拿的可能是第2个客户端的socket
还有另外一种不用单独声明指针的写法
void *handle_request_for_threads(void *client_socket)
{
int client_fd = (int)(intptr_t)arg;
...
}
int server_that_can_process_requests_concurrently_using_thread(){
...
int create_result = pthread_create(&client_thread, NULL, handle_request_for_threads,(void *)(intptr_t)new_client_socket)
...
}
不过我习惯第1种写法
pthread_detach的作用是在线程终止后自动清理并移除
尽管线程已经比进程轻很多了,但上面代码的并发能力还是不够。因为创建线程和进程一样也需要开销,例如:时间、 内存等。假设创建1个线程是1s, 那么同时来1000个连接,由于主进程需要accept之后还要创建完线程算循环一次完毕,那么1000个连接要等待999秒才能真正被处理
使用池化技术高效利用进程/线程
可以使用池化技术来管理进程/线程,来解决上面主进程创建进程/线程的开销
- 服务器程序在启动阶段(即在任何客户端请求到来之前)就应该立刻预先创建好一定数量的子进程(或线程),而不是针对每个客户端来创建一个新的子进程(或线程)。 这就解决了accept+创建线程耦合的问题
- 服务池中的每个子进程一次只处理一个客户端。在处理完客户端请求后,子进程并不会终止,而是获取下一个待处理的客户端继续处理,如此类推
- 使用进程池或线程池时。池子应该足够大,以确保能充分响应客户端的请求。这意味着服务器父进程必须对未占用的子进程加以监视,并且在服务器处于负载高峰期时增加服务池的大小,这样就总会有足够多的子进程存在,从而可以立刻服务于新的客户端请求。如果负载下降了,那么应该相应地降低服务池的大小,因为过多的空余进程会降低系统的整体性能。即资源调度
线程池示例
线程池其实就是:工作线程数组+任务队列数组。
Q: 为什么线程池中要有队列的概念?
A: 是因为如果提交任务速度超过处理任务的速度,那么线程就会阻塞,从而导致服务器无法处理新的客户端请求。 所以得有一个缓冲的区域,这个缓冲区就是队列。同时如果没有缓冲区,线程处理完任务后,它该如何去哪找新的任务?所以池化技术中的队列,本质上一个 生产者-消费者 模型. 消费者处理完1个任务就去缓冲区中去【抢】新任务,如果没有新任务则阻塞。直到【被通知】有任务加入到缓冲区
#define MAX_QUEUE_SIZE 4
#define WORKERS 4
static int task_queue_size = 0;
static pthread_mutex_t mutex = PTHREAD_MUTEX_INITIALIZER;
static pthread_cond_t cond = PTHREAD_COND_INITIALIZER;
struct client_info
{
int client_socket;
int using_non_blocking_io;
};
// 这里放指针而不是值,企业级应用中项目中大多数使用指针而不是值
struct client_info *task_queue[MAX_QUEUE_SIZE];
void *thread_workers_handle_request(void *arg)
{
while (1)
{
struct client_info *client;
int s = pthread_mutex_lock(&mutex);
if (s != 0)
{
perror("pthread_mutex_lock");
exit(EXIT_FAILURE);
}
while (task_queue_size == 0)
{
print_time();
pthread_cond_wait(&cond, &mutex);
print_time();
}
// 先把队列任务数量减1,然后取数组下标。 也可以直接写task_queue[--task_queue_size]
task_queue_size--;
client = task_queue[task_queue_size];
s = pthread_mutex_unlock(&mutex);
if (s != 0)
{
perror("pthread_mutex_unlock");
exit(EXIT_FAILURE);
}
// 真正的业务逻辑不要在锁内执行,拿到对象后直接释放锁,避免长时间占用锁
int client_socket = client->client_socket;
free(client);
printf("thread %ld is handling request from client %d\n", (unsigned long)pthread_self(), client_socket);
close(client_socket);
}
}
int using_thread_pool()
{
int server_socket = bind_server_socket_to_port_and_listen();
for (size_t i = 0; i < WORKERS; i++)
{
pthread_t tid;
pthread_create(&tid, NULL, thread_workers_handle_request, NULL);
}
while (1)
{
int client_socket = accept(server_socket, NULL, NULL);
if (client_socket < 0)
{
perror("accept");
exit(EXIT_FAILURE);
}
struct client_info *client = malloc(sizeof(struct client_info));
client->client_socket = client_socket;
client->using_non_blocking_io = 0;
pthread_mutex_lock(&mutex);
task_queue[task_queue_size++] = client;
pthread_cond_signal(&cond);
pthread_mutex_unlock(&mutex);
}
}
- 主进程启动时,先创建4个worker线程用于后续处理请求
- worker线程并发同时抢占任务队列数组里的任务,为了保证多线程并发安全,使用pthread_mutex_t
- 如果任务队列数组没有任务,则pthread_cond_wait 释放锁并休眠。该方法有2个作用:
- 如果共享变量未处于预期状态,线程应在等待条件变量并进入休眠前解锁互斥量(以便其他线程能访问该共享变量)
- 当线程因为条件变量的通知而被再度唤醒时,必须对互斥量再次加锁,因为在典型情况下,线程会立即访问共享变量
- 函数pthread_cond_wait()会自动执行最后两步中对互斥量的解锁和加锁动作
- 主进程中有任务后,提交到任务队列数组,并使用pthread_cond_signal唤醒1个工作线程
- 在多线程抢占锁之后,在取完业务逻辑用的数据之后,应迅速释放锁,而不是把业务逻辑放在锁中执行。防止该线程长时间占用锁
待解决的问题
截止到现在为止,代码中的读写都是阻塞式I/O,例如:服务器等着客户端发消息,客户端等着服务器数据。如果有大量的连接,没有什么数据要收发时,持有该连接的进程/线程会一直阻塞在那里,什么也不干。这对系统来说,是一种资源的浪费。
因为如果没什么数据接发,终止这些进程/线程以释放资源,因为每个进程/线程都是要消耗内存的
下一篇博文将讨论如何用非阻塞式I/O来解决这个问题,以及I/O多路复用的实现
备注
本章有关TCP的更多知识可以在这篇博文中找到

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 9
9 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)