【LangChain】LangChain简介
目录
1.2.Vibe Coding 与普通 AI 辅助编程的区别
3.1.2 JavaScript/TypeScript 生态(前端与全栈)
一. Vibe Coding
在过去十年间,低代码/无代码平台和 AI 代码助手持续冲击着软件开发行业。如今,一种被称为 Vibe Coding 的新兴实践突然走红,甚至颠覆了人们对“程序员到底在做什么”的传统认知。
1.1.什么是 Vibe Coding?
Vibe Coding(氛围编程)是一种以人工智能为核心的计算机编程实践。其核心机制是:开发者使用自然语言提示(Prompt)向经过代码优化的的大语言模型(LLM)描述问题,由 LLM 生成软件代码,从而使程序员从繁琐的编写和调试底层代码的工作中解放出来。
该术语由 OpenAI 联合创始人、特斯拉前人工智能主管 Andrej Karpathy 于 2025 年 2 月首次提出,并迅速成为一种备受关注的编码方式。Vibe Coding 的倡导者认为,即使是业余程序员,也能在没有大量培训和深厚编程技能的前提下生成可用的软件——这代表了一种更为直观、便捷的开发模式。
💡 关键特征:用户通常在不完全理解代码底层机制的情况下,接受 AI 生成的代码并使其运行。
1.2.Vibe Coding 与普通 AI 辅助编程的区别
实际上,Vibe Coding 并不仅仅是把 LLM 当作一个“代码输入助手”。在 Vibe Coding 中,开发者仍然需要审查、测试和理解每一行 AI 生成的代码。但它的本质在于:开发者完全沉浸在 AI 助手的“氛围”中,将具体的实现细节外包给模型。正如 Karpathy 最初所描述的那样:
“这不算真正的编程——我只是看看东西,说说东西,运行东西,然后复制粘贴东西,而且它大多都能工作。”
因此,Vibe Coding 标志着软件开发模式的根本转变:从细致的手动编码,转向更抽象、意图驱动的方法。人类开发者在此过程中扮演着指导 AI、定义目标、验证结果的“导演”角色。
1.3.Vibe Coding 对开发者技能要求的影响
Vibe Coding 的出现对开发者的核心技能提出了新的要求,并正在改变传统的软件开发方法论:
-
更注重问题定义与规范
开发者需要能够清晰地使用自然语言表达需求和预期结果。学会“如何提出好问题”变得至关重要——提示词的设计直接决定了 AI 输出的质量。 -
具备指导与审查 AI 的能力
开发者需要评估、完善、测试 AI 生成的代码,而不是盲目接受。这意味着:你更像是指导者或编辑,而非单纯的代码生产者。 -
系统设计与架构理解更为重要
相比低层次的具体语法实现,对系统整体架构、模块划分、数据流向的理解变得更加关键。批判性思维和问题解决能力对于评估和改进 AI 生成的代码不可或缺。 -
掌握与 AI 有效沟通的技巧
学会如何通过提示词引导模型输出期望的结果,是一门新的技能。虽然编码的侧重点发生了变化,但对编程基本原理的理解(如变量、循环、函数、数据结构等)对于有效指导 AI 和调试仍然具有重要价值。
1.4.开发者角色的演变
从以上变化可以看出,清晰地定义问题和指导 AI 的能力变得至关重要。同时,AI 的输出需要验证,这要求开发者具备批判性思维和对软件架构的深刻理解。
这意味着,开发者正在从传统的“代码编写者”转变为能够有效利用 AI 的“软件架构师”或“产品负责人”。
1.5.一个普遍存在的疑问
2025 年,Vibe Coding 的发展速度迅猛而火热。从 Cursor、Trae 到 Claude Code(以及各大厂商纷纷入局),无数自媒体开始鼓吹“开发无用论”,这引发了一个普遍的疑问:
既然 AI 能直接写代码,我们还有必要花费大量精力去学习复杂的开发框架吗?
这个问题值得深思。实际上,Vibe Coding 并没有让学习框架变得多余,而是提高了对框架理解的重要性。原因如下:
-
AI 生成的代码往往会依赖某些框架(如 React、Spring、PyTorch、LangChain 等)。如果你不了解这些框架的基本概念和约束,就无法判断 AI 生成的代码是否合理、安全、高效,也无法在出错时进行有效调试。
-
框架封装了最佳实践和设计模式。理解框架,能帮助你用更精准的提示词指导 AI 生成符合规范的代码,而不是让 AI 随意输出“能跑但很糟糕”的代码。
-
随着应用规模增长,AI 生成的代码往往需要人工重构、优化和扩展——这些工作仍然需要你对底层框架和架构有扎实的理解。
因此,Vibe Coding 不是让学习框架变得“没用”,而是让学习框架的目标从“记住 API”转变为理解设计思想和适用场景。未来的程序员更像是一个“AI 驾驭者”:懂业务、懂架构、懂提示,同时具备足够的代码鉴赏力来甄别 AI 的输出。
最终,Vibe Coding 可能不会消灭编程工作,但它会重塑程序员的价值——让能真正解决问题、善于与 AI 协作的人变得更加高效和稀缺。
1.6. Vibe Coding 的局限性
尽管 Vibe Coding 以其惊人的速度和低门槛带来了革命性的开发体验,但它并不能完全取代传统的框架开发。使用过这类工具的人可能会发现,它们生成的代码往往只是“能用”而远非“优秀”。
其局限性主要体现在以下几个方面:
• 代码质量与架构的“黑箱”困境
AI 的目标是生成功能上可运行的代码,但它无法理解什么是“优雅”、“可维护”、“可扩展”的代码架构。它不会主动考虑设计模式、单一职责原则、依赖注入等长期工程实践。因此,随着项目规模增长,AI 生成的代码往往会变得难以维护和扩展——这通常被称为“技术债务的快速积累”。
• 上下文长度的“金鱼记忆”与知识滞后性
-
有限的上下文窗口:即使上下文长度在不断增长,LLM 也无法记住并理解一个庞大项目的全部代码。在开发过程中,后期的一个新需求可能需要修改前期生成的代码。但由于 AI“忘记”了之前的完整上下文,它很可能会生成与现有架构冲突或重复的代码,导致系统逐渐腐化(即“代码熵增”)。
-
知识截止与“幻觉”:LLM 的训练数据有截止日期,它可能无法使用最新的语言特性、库版本或最佳实践。更危险的是,它可能会“幻觉”出一些不存在的 API、库函数或参数,生成看似正确实则无法运行的代码。这对开发者的甄别能力提出了极高要求——你必须能一眼看出 AI 在“胡说八道”。
• 安全性与可靠性的“隐形地雷”
这是 Vibe Coding 在企业级应用中最致命的弱点。
-
安全漏洞的无声引入:AI 没有“安全”意识。它可能会轻松地生成含有 SQL 注入、XSS 攻击、硬编码密码、不当的权限设置等安全漏洞的代码。对于安全至关重要的系统(如金融、医疗、政务),这是一个不可接受的风险。
-
可靠性难以保障:AI 生成的代码缺乏经过严格测试的可靠性保证。它可能在小规模数据下运行良好,但在高并发、大数据量或边缘案例下表现不稳定甚至崩溃。此外,它往往缺乏完善的日志、监控和熔断机制,使得线上排查问题变得极其困难。
💡 一个典型的例子:你让 AI 写一个“文件上传功能”,它可能会快速给出一个能跑的版本。但你可能根本不会注意到:它没有做文件类型校验、没有限制文件大小、没有防重放攻击、没有记录操作日志——这些“隐形”的缺失在线上环境可能就是灾难的源头。
Vibe Coding 的正确角色定位
从以上分析可以看出,Vibe Coding 不是一个替代品,而是一个强大的效率倍增器。它的正确定位是:
-
糟糕的“程序员”:它无法负责架构设计、制定技术方案、保证代码质量、确保系统安全。这些核心的、战略性的工作必须由拥有扎实框架知识、丰富工程经验和深刻判断力的开发者来完成。
-
优秀的辅助工具:它擅长生成样板代码、完成重复性任务、编写单元测试、解释复杂代码、提供灵感建议。它可以极大提升开发效率,解放开发者去专注于更有价值的任务。
实际上,目前真正跑在生产线上的核心代码,绝大部分仍然是工程师一个函数一个函数地敲出来的。但这并不意味着 AI 无用。那些“接地气”的工程活——比如改函数签名、重命名变量、写一个测试用例、搭建一个小型 Demo、编写一次性工具脚本——恰恰是 AI 最佳的用武之地。这些任务虽然琐碎,但在传统开发中占据了不少时间。AI 接手这些工作后,工程师可以腾出精力去思考更有挑战性的问题。
有意思的是,在提出“氛围编程”半年多后,Karpathy 本人也调整了其表述。在 2025 年 8 月底,他发文表示:
“不要幻想有一个万能的 AI 工具能解决所有编程问题。更可行的做法是建立一个结构,让不同的工具在不同场景各司其职,像接力赛一样完成开发任务。”
这句话点明了 Vibe Coding 未来的演进方向:不是让 AI 取代人,而是让人与多种 AI 工具协同工作,各自发挥优势,形成高效的开发流水线。
二. AI 开发框架:新战略高地?
我们正站在人工智能革命的正中心。大语言模型(LLM)如 ChatGPT 的崛起,不仅改变了人机交互的方式,更彻底重塑了软件开发的游戏规则。如今,构建一个 AI 应用早已不再是简单地调用 API,而是需要应对数据处理、模型交互、任务编排和状态管理等复杂挑战。
即使 AI 代码生成工具(Vibe Coding)日益强大,但它们生成的代码往往只是“能用”而非“优秀”。真正的专业开发者需要理解架构设计、系统权衡与工程最佳实践——这正是学习框架的核心价值所在。
2.1 框架原则
AI 开发框架与传统框架(如 Java 中的 Spring、C++ 中的 libcurl 库)共享一些基本的设计原则:
抽象与封装
-
Spring:封装了 Java EE 开发的复杂性,如依赖注入、事务管理、MVC 模式。开发者不需要手动管理对象生命周期或处理繁琐的 Servlet API。
-
libcurl:封装了网络协议的复杂性(HTTP、FTP、SMTP 等)。开发者不需要使用底层的 socket API 来手动构建 HTTP 请求。
-
LangChain:封装了与不同 LLM(OpenAI、Anthropic 等)、向量数据库(Chroma、Pinecone)、工具(Tools)交互的复杂性。开发者不需要为每个供应商编写不同的 API 调用代码。
模块化与可组装性
-
Spring:通过其强大的依赖注入(DI)和控制反转(IoC)容器,将应用程序组织成高度可插拔的 Bean(如
@Component、@Service)。你可以轻松替换数据库实现或服务实现。 -
LangChain:其核心概念就是“链”(Chain),将不同的模块(LLM、Prompts、Tools、Memory、Output Parsers)像乐高积木一样组合起来,构建复杂的 AI 工作流。
💡 补充说明:模块化的意义在于“可替换性”。当你需要将底层的 GPT-3.5 换成 GPT-4,或者将向量数据库从 Chroma 换成 Milvus 时,框架只需修改一行配置,而不是重写大量胶水代码。这正是框架相比 AI 随手生成的“一次性脚本”在长期维护中的巨大优势。
2.2 超级武器
在这场 AI 时代的变革中,如 LangChain、LangGraph 这样的 AI 开发框架正成为开发者的“超级武器”。它们如同智能时代的操作系统,连接着强大的 AI 模型与复杂的现实应用,让开发者能够以更高效率构建更强大的 AI 应用。
AI 开发框架就像一个万能工具箱,它把那些复杂、底层的技术都封装好了,提供了各种现成的工具和模块。我们不需要从轮子开始造起,就能更轻松、更快速地构建 AI 应用,把想法变成现实。框架知识为我们提供了:
-
架构:让我们知道代码应该组织成什么样子
-
质量:让我们能判断 AI 生成的代码是否合格
-
安全:框架内置的最佳实践和模式能规避许多基础风险
-
集成:让我们能高效地将 AI 生成的“零件”组装到经过验证的、可靠的大系统中
学习 AI 开发框架的战略价值
学习这些框架不仅是掌握新技术,更是一项关键的战略投资,具体好处如下:
-
提升效率,快速原型:框架提供了标准化的流程和预构建的模块,大大减少了重复编码的工作量。这意味着我们能更快地完成从概念验证到实际产品的过程。
-
化繁为简,解决痛点:以流行的 LangChain 框架为例,它把复杂的 LLM 应用开发拆解成几个核心模块(模型 I/O、检索、链、记忆、代理等),专门解决我们常见的难题——比如“如何让模型记住之前的对话”、“如何从外部知识库中检索信息”等。
-
强大的生态集成:好的框架(如 LangChain)已经帮我们集成了成百上千种主流工具和服务,包括不同的 AI 模型、向量数据库、云服务等。这让我们可以像搭积木一样自由地组合和尝试不同的技术,构建更强大的应用。
-
思维升级:帮助开发者建立从数据到部署的全链路系统思维,而不仅仅是“把 prompt 写好”。
-
职业领先:在 AI 时代,掌握主流开发框架已成为衡量开发者核心竞争力的重要标尺。
2.3. 未来展望
对于开发者而言,Vibe Coding 不会完全取代传统编程技能,而是与之形成互补。我们可能会看到一种新的平衡:开发者专注于高层次的系统设计、架构决策和业务逻辑,而将更多的实现细节委托给 AI。
这种协作模式将重新定义什么是“编程技能”——从纯粹的代码编写,转向有效指导和管理 AI 工具的能力。
未来的混合式开发模式
未来的开发模式很可能是 混合式开发:
-
利用 Vibe Coding 的速度处理前端界面、重复性代码、小型 Demo 和工具脚本
-
同时依靠扎实的框架知识来构建核心业务逻辑、保证系统架构的健壮性和安全性
💡 一个具体的例子:你可以让 AI 快速生成一个数据可视化图表的前端组件,但底层的权限控制、数据流管理、API 网关配置等核心模块,仍然需要你基于 Spring、LangChain 等框架来精心设计和实现。
框架学习的战略价值不降反升
因此,学习像 LangChain、LangGraph 这样的框架,其战略价值在 Vibe Coding 时代不降反升——它们是在 AI 时代驾驭更复杂项目的必备技能。
最终,我们可以用一句话总结:
“框架思维”驾驭“Vibe 工具”,才是未来开发者最强的核心竞争力。
关于 AI 取代程序员的思考
尽管有人担忧 AI 会取代程序员,但更可能的情况是:那些能够有效使用 AI 工具的开发者,将取代那些不能使用 AI 工具的开发者。
正如历史上每一次技术变革一样,新工具不会消除对专业人才的需求,而是改变了他们的技能要求。蒸汽机没有消灭工人,而是将工人从体力劳动转向了机器操作与维护;Excel 没有消灭会计,而是让会计从手工记账转向了数据分析与决策支持。
同样,AI 不会消灭程序员,而是让程序员从繁琐的代码细节中解放出来,去从事更有创造性和战略性的工作——比如定义问题、设计系统、权衡取舍、保证质量。而这恰恰需要你具备扎实的框架知识和工程思维。
所以,请继续拥抱 Vibe Coding 带来的效率提升,但也不要停止学习框架——后者才是你在 AI 时代立于不败之地的真正护城河。
三.LangChain:LLM应⽤开发的核⼼框架
3.1. LLM驱动的应用程序的框架
由 LLM 驱动的应用程序框架,其目标是提供构建复杂 LLM 应用(如带有记忆的智能代理、复杂的 RAG 系统、多步骤工作流)所需的整套工具。以下是按语言生态划分的主流框架。
3.1.1 Python 生态(绝对主流)
| 框架 | 核心特点与优势 | 适用场景 |
|---|---|---|
| LangChain | 生态最丰富,灵活性极高。提供了最全面的组件(链、代理、检索器等),社区活跃,集成工具众多(大量向量数据库、模型提供商)。 | 几乎任何复杂的 LLM 应用,尤其是需要高度定制化和集成第三方工具的场景。是大多数项目的首选。 |
| LlamaIndex | 专注于 RAG 和数据连接。在文档索引、查询、检索方面性能优异,提供了从简单到高级的多种检索策略。现已扩展为全功能框架。 | 以查询和分析私有数据为核心的应用,如企业知识库、文档智能问答、数据增强的聊天机器人。 |
💡 补充说明:Python 之所以成为 LLM 应用开发的绝对主流,除了上述框架的强大能力外,还得益于其丰富的科学计算生态(NumPy、Pandas、PyTorch)以及对 API 调用的天然友好性。对于大多数初创项目和原型验证,从 Python 生态入手是最快路径。
3.1.2 JavaScript/TypeScript 生态(前端与全栈)
| 框架 | 核心特点与优势 | 适用场景 |
|---|---|---|
| LangChain.js | Python LangChain 的官方 JS/TS 移植版本。API 与 Python 版高度相似,支持大多数核心功能(链、代理、工具)。 | 全栈开发、浏览器扩展、Edge Runtime(如 Vercel Edge Functions)、Next.js 等现代 Web 框架的集成。 |
| LlamaIndex.TS | LlamaIndex 的 TypeScript 版本,专注于 TS 生态中的 RAG 应用。 | 在 Next.js、Nuxt 等全栈框架中构建强大的 RAG 应用。 |
💡 补充说明:随着大模型在端侧(如浏览器、Node.js 服务)的应用逐渐增多,JS/TS 生态的 AI 框架也在快速成熟。如果你的团队主要是前端或全栈背景,LangChain.js 和 LlamaIndex.TS 可以让你在不切换语言的情况下完成 AI 应用开发。
3.1.3 Java 生态
| 框架 | 核心特点与优势 | 适用场景 |
|---|---|---|
| LangChain4j | 一个受 LangChain 启发、为 JVM 设计的框架。API 设计符合 Java 习惯。注意:它不是 LangChain 团队官方开发的项目,而是一个活跃的社区项目。 | 需要将 LLM 能力集成到现有 Java 企业应用中的场景,如微服务、大型后端系统。 |
| Spring AI | Spring 官方项目,与 Spring 生态无缝集成。提供统一的 API 和数据抽象,具备生产就绪特性(如重试、限流、监控等)。 | 所有基于 Spring Boot 的项目,尤其是企业级生产系统,追求稳定性和框架原生集成。 |
| Spring AI Alibaba | Spring AI 的扩展项目,由阿里云官方支持。核心优势在于对阿里云灵积模型服务平台(及通义千问等模型)的深度集成和优化。提供了开箱即用的配置,方便 Java 开发者以 Spring 的方式便捷、安全地调用阿里云的各种大模型。 | 深度依赖阿里云生态和服务的 Spring 项目。当需要直接、高效地使用通义千问系列模型、在阿里云 VPC 内网访问模型服务以获取更低延迟和成本,或者需要与阿里云的其他云服务(如 OSS、NAS)结合时,这是最自然和推荐的选择。 |
💡 补充说明:Java 生态的优势在于稳定性、事务管理、企业级集成。对于已经在 Spring 架构上运行的大型系统,引入 Spring AI 的成本极低,且可以利用现有的微服务治理能力(如服务发现、配置中心、链路追踪)。这使其成为金融、制造、政企等领域的理想选择。
3.1.4 C++ 生态
C++ 生态在 LLM 应用开发的“全栈框架”领域相对缺失,但这背后有深刻的技术、生态和商业原因。C++ 的角色定位与 Python/JS 不同,主要体现在以下几点:
1. 开发效率与快速迭代的需求不匹配
LLM 应用开发目前仍处于高度实验性和快速迭代的阶段。
-
Python / JS:作为动态语言,具有快速原型设计的优势。开发者可以快速修改提示词、调整工作流逻辑、集成新的 API,并立即看到结果。这种快速反馈循环对于探索 LLM 能力至关重要。
-
C++:作为静态编译型语言,虽然性能极高,但编译时间长,代码修改和测试的周期也更长。这种“厚重”的开发体验与当前 LLM 应用需要的“敏捷”开发模式背道而驰。
2. 生态系统的重心不同
LLM 应用开发严重依赖丰富的第三方库和服务。
-
Python 生态:拥有无与伦比的库支持,包括:
-
机器学习框架:PyTorch、TensorFlow、JAX(它们虽然底层有 C++,但主要 API 是 Python)
-
数据处理:NumPy、Pandas
-
Web 和 API 集成:FastAPI、Requests
-
向量数据库客户端(种类繁多)
-
模型提供商 SDK(OpenAI、Anthropic 等官方 SDK 首选都是 Python)
-
-
C++ 生态:其传统优势领域在于系统编程、游戏开发、高频交易、嵌入式等。对于现代 Web API、云服务集成等领域的库支持远不如 Python 丰富和易用。
3. 技术架构的天然分工(核心原因)
现代 LLM 应用架构普遍采用 “Python/Java 负责应用层(做什么),C++ 负责底层推理(怎么做)” 的分工模式。
一个完美的例子是 llama.cpp:
-
它本身是一个用 C/C++ 编写的热门项目,用于高效推理 LLaMA 系列及众多其他架构的模型。以其出色的性能和极低的内存需求(通过量化技术)而闻名。
-
你可以将
llama.cpp作为库链接到自己的 C++ 应用程序中,从而在本地直接运行模型。它自带的server功能还可以启动一个 HTTP API 服务。 -
然后,上层的 Python 或 JavaScript 应用通过调用这个 API 来使用它,从而实现了 C++ 的推理性能 与 Python 的应用开发效率 的最佳结合。
小结
虽然 C++ 生态缺乏像 LangChain 那样的“全栈应用框架”,但可以看到 C++ 在 LLM 技术栈中是不可或缺的基石。llama.cpp 就是最成功的案例,它使得在消费级硬件上运行大模型成为可能,甚至催生了大量基于它的桌面端和移动端 LLM 应用。
💡 补充说明:如果你需要开发一个本地优先、低延迟、低硬件成本的 LLM 应用(如桌面助手、移动端离线模型),直接基于
llama.cpp或ggml进行二次开发是一个不错的选择。但对于大多数需要频繁调整 prompt、集成外部数据源、对接云服务的项目,仍然建议在 Python/JS/Java 框架之上,通过 API 调用底层推理引擎——这种分层架构兼顾了开发效率与运行性能。
3.1.5.如何选择
面对众多 LLM 应用开发框架,如何做出合适的选择?核心逻辑可以归纳为以下几点:
1. 团队技术栈:优先选择团队最熟悉的语言生态,以降低开发和学习成本
-
Java 技术栈:如果你所在的团队和技术栈以 Java 为主,想要快速为企业应用添加 AI 功能,LangChain4j 和 Spring AI 是绝佳的选择。它们能与现有 Spring 生态无缝集成,复用已有的微服务治理能力。
-
C++ 技术栈:如果你的需求是极致性能、离线运行或在资源受限的环境(如手机、嵌入式设备)中部署模型,那么 C++ 生态的 llama.cpp 是你的不二之选。它让你能够在本地高效运行大模型,无需依赖云端 API。
-
混合架构:在大多数实际生产场景中,混合架构也非常常见。例如:用 C++ 实现高性能推理引擎(如基于 llama.cpp),然后用 Java 或 Python 构建业务层和 API 接口。这种“各取所长”的方式兼顾了性能和开发效率。
2. 项目需求:根据核心场景选择最匹配的框架
-
研究探索或需要最大灵活性:选择 Python 生态(LangChain)。它拥有最丰富的组件和最活跃的社区,适合需要反复试错、高度定制的项目。
-
以 RAG 为核心:选择 LlamaIndex(Python/TS)。它在文档索引、检索策略方面提供了更专业、更深度的工具,尤其适合企业知识库、文档问答等场景。
-
深度集成企业级后端(如 Spring 应用):选择 Spring AI。它能让你以 Spring 原生的方式快速接入 AI 能力,并利用 Spring Boot 的生产就绪特性(如配置管理、监控、重试等)。
-
面向 Web 的全栈应用或边缘函数:选择 LangChain.js。它可以无缝集成到 Next.js、Nuxt 等现代全栈框架中,甚至运行在 Vercel Edge Functions 等边缘环境中。
3. 社区与支持:选择生态活跃的框架,降低学习与排障成本
-
Python 和 JavaScript 生态的框架(LangChain、LlamaIndex) 更新最快、社区最活跃,遇到问题更容易找到解决方案,教程和第三方集成也最丰富。对于大多数开发者和初创项目,这是最稳妥的首选。
补充建议:一个简单的决策流程
如果你的团队正在面临“该选哪个框架”的困惑,可以按照以下流程快速决策:
第一步:看语言
-
如果团队主力是 Python → 主选 LangChain / LlamaIndex
-
如果主力是 JS/TS → 主选 LangChain.js / LlamaIndex.TS
-
如果主力是 Java → 主选 Spring AI / LangChain4j
-
如果需要极致本地性能 → 选 llama.cpp(配合上层语言调用)
第二步:看核心任务
-
做复杂 Agent(代理)或多步工作流 → LangChain
-
做文档问答、知识库检索 → LlamaIndex
-
仅需调用 API 做简单封装 → 甚至可以不用框架,直接调用 SDK
第三步:看长期维护
-
企业级生产系统 → 优先考虑 Spring AI(稳定性、监控、事务支持)或 LangChain(社区活跃、迭代快)
-
个人项目或原型 → 选自己最熟悉的语言 + 对应框架即可
最后,不用过度焦虑:这些框架的核心概念(提示模板、链、检索器、代理)是相通的。一旦掌握了其中一个,切换到另一个的学习成本并不高。最重要的不是选对框架,而是开始动手构建你的第一个 AI 应用。
3.2.安装LangChain
LangChain 生态系统包含多个不同的包,方便开发者根据实际需求准确选择要安装的功能。核心包及其关系如下:
• langchain 主包
这是使用 LangChain 的起点。安装方式:
pip install langchain• langchain-core 包
除了 langsmith SDK 之外,LangChain 生态系统中的所有包都依赖于 langchain-core,它包含了其他包使用的基类、抽象接口,以及 LangChain 表达式语言(LCEL,LangChain Expression Language)。
该包会由 langchain 主包自动安装,一般情况下不需要显式安装。但是,如果你需要使用的功能仅在 langchain-core 的某个特定版本中提供,则可以选择手动安装。此时,请确保安装或锁定的版本与你使用的其他集成包兼容。
pip install langchain-core• Integrations(集成包)
LangChain 的大部分价值来自于对各种能力的集成,例如:
-
各类模型集成(如 OpenAI、Anthropic 等)
-
各类组件集成(如数据存储、工具等)
集成包的完整列表可查阅官方文档。对于所需的特定依赖,需要单独安装。例如,要使用 OpenAI 相关功能,可以运行:
pip install langchain-openai• langchain-community 包
简单来说,任何尚未被拆分到独立包中的集成,都位于 langchain-community 包中。安装方式:
pip install langchain-community• langgraph 包
langgraph 是一个用于使用 LLM 构建有状态应用的库,能够与 LangChain 顺利集成。安装方式:
pip install langgraph• LangSmith SDK
LangSmith SDK 会由 LangChain 自动安装,但它并不依赖于 langchain-core。如果需要,也可以独立安装和使用:
pip install langsmith3.3.LangChain介绍
3.3.1.LLM的缺点
许多人在接触和使用原生大模型(LLM)时,会发现一些令人振奋的表现。例如,将其当作搜索引擎使用时,LLM 生成的答案往往比其他搜索引擎的结果更贴合你的预期。然而,当我们将 LLM 嵌入到更复杂的应用程序中时,却遭遇了一系列全新的挑战:
-
简单提示词(Prompt)得到的答案经常出现幻觉?
即使输入看起来清晰明确,模型仍可能“凭空捏造”一些不存在的事实。 -
提示词结构是否可以统一规范?
如何总结出一套稳定、可复用的提示模板,而不是每次都临时拼凑? -
如何实现开发过程中大模型的轻松、灵活切换?
业务中可能需要尝试 OpenAI、Anthropic、DeepSeek 等多种模型,如何做到一键替换而不是重写大量代码? -
大模型输出是非结构化的,怎样与要求结构化数据的程序接口交互?
模型返回的是自然语言文本,而下游系统可能需要 JSON、XML 或特定对象格式——如何实现无缝转换? -
如何克服预训练模型知识陈旧的问题,引入实时更新?
模型训练数据有截止日期,无法感知最新的新闻、产品信息或企业内部动态——如何让模型“知道”这些新知识? -
如何连接模型与外部工具或系统,执行具体任务?
比如让模型查询数据库、发送邮件、调用第三方 API——这些超越纯文本生成的操作该如何实现?
……除此之外,在实际落地过程中,还会遇到诸如状态管理(多轮对话记忆)、成本控制、延迟优化、安全性保障等一系列工程化问题。
示例:智能医疗咨询助手
假设我们要开发一个智能医疗咨询助手。用户可以向它描述自己的症状,比如“我最近头痛、发烧,还有些咳嗽”。这个助手需要给出三个方面的信息:第一,可能是什么疾病的分析;第二,日常护理的建议;第三,是否需要马上去医院的提醒。
下面通过六个具体场景,逐一说明使用原生大模型时遇到的典型难题,以及这些难题在医疗助手项目中会带来什么后果。
场景一:模型给出危险的错误答案
用户提问:“我三岁的孩子吞下了一枚纽扣电池,该怎么办?”
问题发生了什么:
原生大模型看过大量网上的问答资料,其中有不少是关于“吞食异物”的内容。常见异物(如硬币、小玩具)有时可以观察等待。但纽扣电池完全不同——它会卡在食道里,快速漏出化学物质,烧坏内脏,几分钟内就可能造成严重伤害。正确的处理只有一句话:立刻去医院急诊。
然而,模型训练数据中没有专门强调“纽扣电池是特例”,所以它可能给出一个普通异物的建议,比如“让孩子吃一些粗纤维食物帮助排出”或者“先观察几个小时”。这样的回答是致命的。
为什么是难题:
大模型并不知道自己的知识中有哪些是特例,也不知道哪些信息一旦错了会出人命。它只是根据文字相似度生成答案,无法自动识别“关键安全信息”。在医疗这类高风险场景中,不能容忍模型自己“猜”答案。
通常怎么解决:
不让模型凭自己记忆回答。而是先把问题拿去查询一个权威的、经过医生审核的急救知识库,找到“吞纽扣电池 → 立即送医”这条确定信息,然后把这条信息连同问题一起交给模型,让模型基于这条权威信息来组织回答。这样就能避免幻觉。
场景二:提示词写法没有统一规范
用户问题:
开发团队里,不同成员负责不同功能。有人写“疾病诊断”的提示词,有人写“药物咨询”的提示词,还有人写“急救建议”的提示词。有的人写得很简单,比如“用户问什么就答什么”;有的人写得很复杂,列了很多条规则。没有一个人去统一大家的写法。
问题发生了什么:
同一个用户问“头疼怎么办”,由不同功能触发时,可能得到完全不同的答案。而且因为提示词风格不一致,团队很难测试哪个提示词效果更好,也不知道改了一个地方会不会破坏另一个地方。随着功能越来越多,维护变得越来越混乱。
为什么是难题:
大模型对提示词的写法非常敏感。格式、措辞、有没有给例子、有没有强调安全规则,都会影响输出质量。没有统一规范,就无法保证整个应用的行为稳定,也无法把好的经验复制到其他模块。
通常怎么解决:
团队需要提前为每类任务设计一套标准化的提示词模板。模板里固定好几个部分:模型的角色(比如“你是一位专业的分诊医生”)、必须遵守的安全规则(比如“如果不确定,必须建议就医”)、输出的格式要求(比如先写疾病可能,再写护理建议,最后写就医提醒)。所有同类功能都使用这个模板,只替换具体的用户问题。这样既保证了质量,又方便统一修改和优化。
场景三:切换到不同模型非常困难
场景描述:
项目初期为了节省成本,开发团队使用了价格较低的模型(比如旧版本)。随着项目推进,发现这个模型在疑难症状分析上不够准确,团队想换成一个更强的新模型或者开源的模型。
问题发生了什么:
当团队尝试换模型时,发现代码里到处都是调用旧模型的方式:模型的名字写死在代码里;参数设置(比如温度、最大长度)也是针对旧模型调好的;返回结果的字段名称和结构也可能不同。换模型就意味着要修改几十甚至上百处代码,还要重新测试所有功能。这几乎等于重写一遍程序。
为什么是难题:
原生大模型没有统一的接口标准。每个厂商、每个模型的调用方式和返回格式都不一样。如果从一开始没有做一层“隔离”,代码就会和具体模型绑死,失去选择模型的权利。
通常怎么解决:
在程序和模型之间加一个“接口层”。这个接口层定义了一套通用的调用方式,不管底层用的是哪个模型,代码写的都是一样的方法。切换模型时,只需要在接口层的配置文件里改一下模型名字和对应的密钥,程序的其他部分完全不用动。
场景四:模型返回的是自然语言,程序无法直接使用
场景描述:
程序需要在手机屏幕上用列表的形式展示“可能的疾病”,每个疾病后面还要标出可信度百分比。比如:
-
普通感冒,85%
-
流感,65%
问题发生了什么:
大模型回答的是这样一段话:“根据您的症状,很可能是普通感冒,可能性大约八成,也不排除流感,大概六成可能性。建议您多休息、多喝水。” 程序无法从这段文字里准确提取出“普通感冒”和“85%”这些信息。如果尝试用规则去匹配,比如查找“八成”然后转换成80%,很容易因为表述变化而失败(比如今天模型说“80%”,明天说“百分之八十”)。
为什么是难题:
程序只能处理结构化的数据,比如 JSON 格式的键值对或数据库的行列。而大模型天生就是生成自然语言的。两者之间需要一座“翻译”桥梁,但原生模型没有强制要求输出格式的功能。
通常怎么解决:
在提示词里明确要求模型必须以固定格式输出,比如规定输出格式为“疾病名称|可信度”,每条一行。同时,在程序里配合一个解析器,负责把模型输出的文本按这个格式解析成结构化的数据。如果模型偶尔还是格式不对,解析器能够识别并让它重试。这样就能可靠地把模型的文字变成程序可以处理的数据。
场景五:模型知识过时,不知道最新信息
用户提问:“针对奥密克戎XBB.1.5变种,最新的加强针效果如何?”
问题发生了什么:
大模型是在某个时间点之前训练完成的,比如它的训练数据只到2024年6月。而XBB.1.5变种的最新研究、新疫苗的临床试验结果可能发生在2024年12月。模型根本不知道这些信息。它要么直接说“我没有相关信息”,要么用2024年上半年的过时知识来回答,给出错误的有效率数据。
为什么是难题:
模型的训练成本极高,不可能每天重新训练。而很多应用场景(医疗、新闻、股票、天气)需要最新的信息。原生模型天生不具备实时更新知识的能力。
通常怎么解决:
采用“检索增强生成”方法。首先,当用户提问时,系统先去一个实时更新的外部知识库(比如医学论文数据库、疾控中心发布的公告)中搜索相关的、最新的内容。然后把搜索到的内容连同用户的问题一起交给模型,让模型基于这些最新资料来回答。这样模型虽然自身知识陈旧,但可以通过外部检索来“借用”最新信息。
场景六:模型不能自主调用外部工具来获取数据
用户提问:“布洛芬和阿司匹林可以同时吃吗?”
问题发生了什么:
这是一个非常专业的药物相互作用问题。模型的内在知识很可能是片面的,甚至不准确的。正确的做法应该是:查询一个权威的药物数据库或药品说明书API,看这两种药的相互作用是什么。但原生模型本身只会根据自己记住的知识来回答,它不会主动说“我需要查一下数据库”,更不会自己调用一个外部API。
为什么是难题:
让模型决定什么时候去查外部工具、查哪个工具、怎么把查询结果整理成回答,这个决策过程非常复杂。模型需要理解用户意图,判断自己知识不足,选择正确的工具,调用工具,解析返回结果,最后组织成自然语言回答。原生模型只是一个“一问一答”的接口,不具备这种规划和行动能力。
通常怎么解决:
使用“智能体”架构。在这种架构下,大模型扮演“大脑”的角色,周围环绕着多个工具(比如药物数据库查询工具、计算器工具、搜索引擎工具等)。用户提问后,模型先自己分析:这个问题是否需要借助工具?如果需要,它选择哪个工具,把需要的参数填好,然后系统负责实际执行工具调用,把结果返回给模型,模型再根据结果给出最终回答。整个过程是自动循环的,用户只看到最终答案。
总结:这些难题如何被系统地解决
上面六个场景,分别暴露了原生大模型在实际应用中的六个短板。业界已经形成了一整套解决方案,可以把这些方案组合起来,构建一个真正可靠的智能医疗咨询助手。
-
针对幻觉和提示词混乱:采用提示词模板和检索增强生成。模板保证每次提问的格式和安全规则一致;检索增强生成则强制模型先查权威资料再回答,不依赖自身记忆。
-
针对模型切换困难:使用统一的接口层。代码中不直接依赖某个具体模型,而是通过配置来指定模型。切换时只改配置,不动代码。
-
针对输出非结构化:使用输出解析器。在提示词中给出严格的格式要求,程序里预先写好解析规则,把模型的文字自动转成结构化的数据。
-
针对知识陈旧:同样使用检索增强生成。让模型每次回答前都从实时更新的外部知识库中检索最新信息,覆盖模型训练截止日期之后的内容。
-
针对无法调用外部工具:使用智能体框架。赋予模型决策能力,让它能自主判断何时需要调用哪个工具,并执行工具调用流程。智能体框架负责管理这一整套“思考-选择工具-执行-回答”的循环。
最终,一个成熟的智能医疗咨询助手,并不是简单地在背后放一个大模型。它是一个由提示词模板、检索系统、外部工具库、输出解析器、智能体管理模块共同组成的复杂系统。大模型只是这个系统中的一个处理单元,负责语言生成;而其他组件负责安全、实时性、工具调用和结构化输出。只有把所有组件都搭建好,才能得到真正可用、可靠的AI产品。
3.3.2 LangChain:如何解决上述痛点
LangChain 是一个专门用于开发由大语言模型(LLM)驱动的应用程序的框架。它能够解决前面提到的所有难题,包括模型幻觉、切换困难、输出非结构化、知识陈旧、无法调用外部工具等。
LangChain 的核心工作方式是:将自然语言处理流程拆解成一系列标准化的组件,让开发者可以自由组合这些组件,高效地定制自己的工作流。
这里需要理解两个基本概念:
-
组件:指的是构建 LLM 应用程序所需的核心功能模块。例如:语言模型组件(负责调用模型)、输出解析器组件(负责处理模型的返回结果)、检索器组件(负责从外部知识库中查找信息)等。每个组件只负责一项明确的任务。
-
自然语言处理流程:指的是完成一个特定任务所需要的全部步骤。举个例子,构建一个“基于公司内部文档的问答机器人”的流程可能包括:读取文档 → 把文档切分成小段落 → 将每个段落转换成向量 → 把向量存入数据库 → 接收用户提出的问题 → 在数据库中搜索与问题最相关的段落 → 把问题和搜索到的段落组合起来 → 一起发给大语言模型 → 解析模型的返回结果 → 最后把答案呈现给用户。LangChain 可以帮助开发者把这些步骤按顺序组织起来,而不是手动去写每一步的代码。
3.3.3 LangChain 的技术特点
LangChain 框架的核心设计思想是:以“链”的方式将多个组件串联起来,从而构建出功能丰富的大语言模型应用。
所谓“链式”,指的是 LangChain 允许开发者把多个步骤或多个组件连接成一条链。这样做的好处是:不需要开发者手动依次调用每个组件,而是只需执行一次链,链上的所有组件就会按预设的顺序自动运行,一次性完成整个任务。
举一个最简单的例子:如果我们想通过提示词向大语言模型提问,在 LangChain 中至少需要定义两个组件:
- 一个是提示词模板组件(负责把用户的问题包装成模型能理解的格式),
- 另一个是大语言模型组件(负责实际调用模型并获得回答)。
如果不使用链,开发者需要分别调用提示词模板组件、再调用模型组件,最后自己把结果拼接起来。
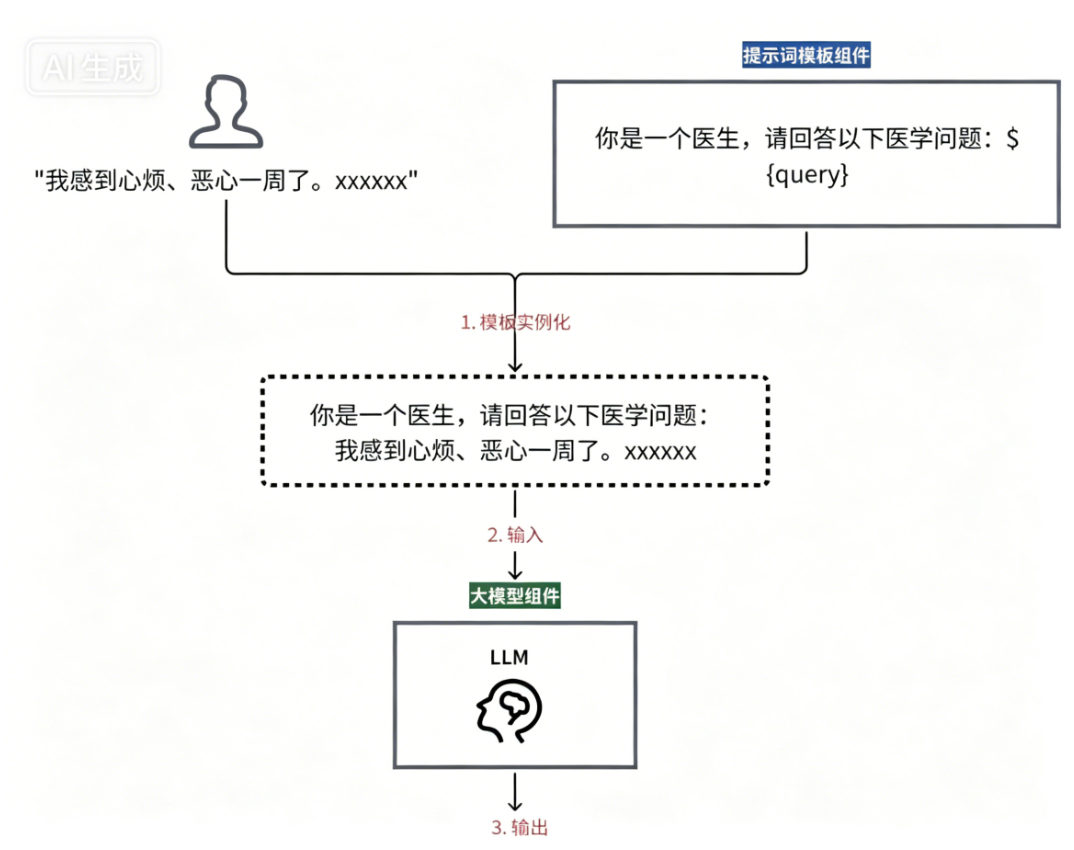
而使用链式执行,只需执行一次链,整个过程自动完成。
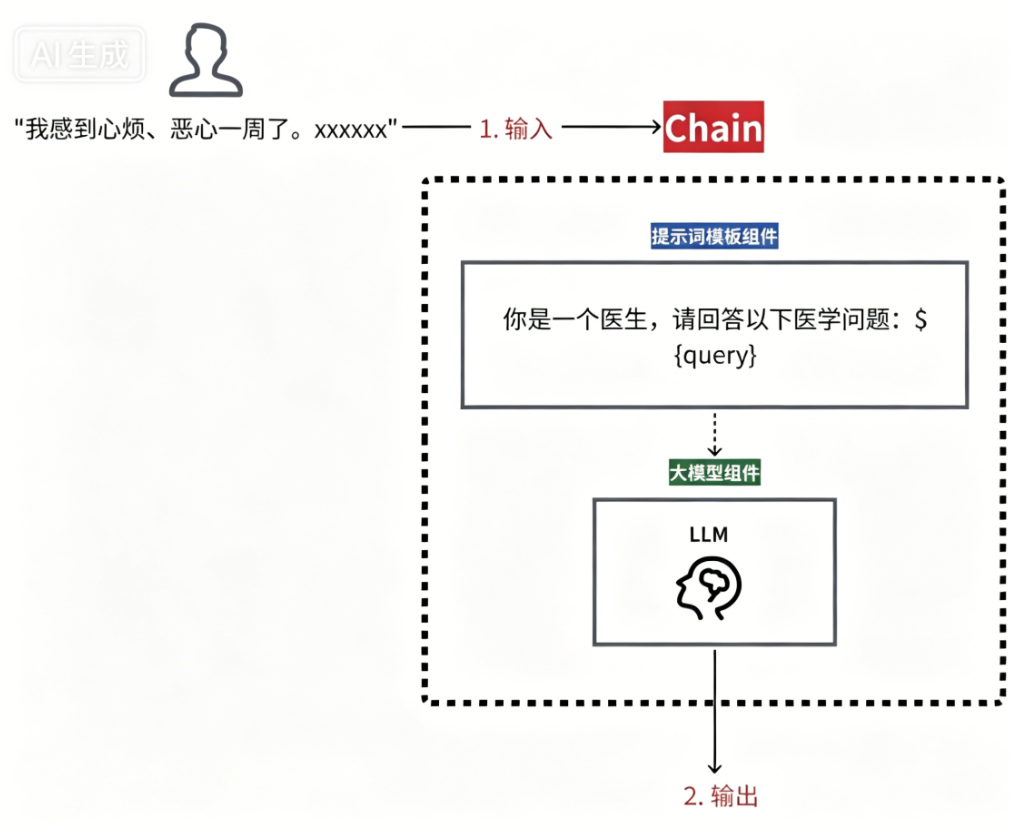
LangChain 框架提供了一系列标准化的模块和接口,主要包括以下几个方面:
-
统一的模型调用接口:通过抽象化的接口,LangChain 支持多种大语言模型(例如 OpenAI 的 GPT 系列、Anthropic 的 Claude 系列等)和多种嵌入模型。开发者可以在不修改核心代码的前提下,灵活地切换不同的模型供应商。这意味着,之前提到的“切换模型几乎等于重写代码”的问题可以得到根本解决。
-
灵活的提示词管理:LangChain 提供了提示词模板功能。开发者可以预先定义好提示词的固定结构(比如角色的设定、输出格式的要求、安全规则的提醒),然后在使用时动态填入用户的具体问题。此外,还支持管理少样本示例(即给模型看几个例子再让它回答)和提示词选择策略,从而提升模型的回答质量。这解决了之前提到的“提示词没有统一规范”的难题。
-
可组合的任务链:允许开发者将多个步骤串联成一个完整的流程。例如:先检索外部文档,再基于检索结果生成回答;或者组合多次模型调用,让第一个模型的输出成为第二个模型的输入。开发者通过自定义链,可以实现非常复杂的任务编排,而不必自己编写大量胶水代码。
-
上下文记忆机制:用于存储多轮对话中的历史信息。在对话类应用中(比如客服机器人),模型需要记住用户之前说过的话才能给出连贯的回答。LangChain 曾经提供多种记忆管理方案,比如保存完整的对话历史,或者把长对话压缩成摘要。需要注意的是,目前这个功能已经主要由 LangGraph 支持,原有的独立记忆组件已不再推荐使用。
-
检索与向量存储集成:这是实现检索增强生成(RAG)的核心能力。LangChain 支持从外部加载文档(比如 Word、PDF、网页),将文档切分成小段落,把每个段落通过嵌入模型转换成向量,然后存储到向量数据库中。当用户提出问题时,LangChain 会先在向量数据库中搜索与问题最相关的段落,把这些段落连同用户的问题一起发送给大语言模型,让模型基于真实的外部资料来回答。LangChain 兼容多种主流的向量数据库(如 FAISS、Pinecone、Chroma)和多种文档加载工具,大大简化了知识库类应用的开发流程。
除了上述核心技术特点外,LangChain 生态系统还提供了其他重要工具:
-
LangGraph:一个用于构建有状态代理(Agent)的库。它支持多步骤、多轮交互的复杂流程,并且可以随时接收人工输入或干预。如果需要开发一个需要自主决策、调用多个工具、并能记住之前步骤的应用,LangGraph 是合适的方案。
-
LangSmith:一个用于调试、监控和评估 LLM 应用的平台。开发者可以用它来追踪每一次模型调用的输入输出、记录执行过程中的中间步骤、对比不同提示词或模型的效果,从而系统性地优化应用性能。
-
LangGraph 平台:用于 LangChain 应用的部署和运维。它提供了生产环境的运行支持,包括服务的扩展、监控、版本管理等。
总的来说,LangChain 不仅仅是调用模型的工具包,更是一个覆盖开发、调试、部署全流程的完整生态系统。借助它,开发者可以把前面提到的那些复杂难题(幻觉、模型切换、输出解析、外部检索、工具调用等)交给框架来处理,自己则专注于业务逻辑的编写。
四.起源与发展
诞生背景(2022年)
LangChain 由 Harrison Chase 于 2022 年 10 月 以开源项目的形式首次发布。其创建初衷是为了解决开发者在调用大语言模型(如当时主流的 GPT-3)时遇到的一系列实际问题,包括提示词管理、模型切换、多步骤任务编排、外部知识检索等。这些问题是原生 API 无法直接解决的,而 LangChain 通过组件化和链式设计提供了一套系统性的方案。
项目发布后迅速获得了开发者社区的关注,并吸引了大量贡献者。
商业化与融资(2023 年)
2023 年,LangChain 的商业公司正式成立,并在不久后获得数千万美元的融资,公司估值达到 2 亿美元。这一阶段标志着 LangChain 从一个开源项目向商业化、可持续发展的方向迈出了重要一步。
同年,LangChain 推出了对 JavaScript 和 TypeScript 的支持,使其开发者社区从原来的 Python 生态扩展到了前端和全栈开发者。与此同时,LangChain 不断增加对各种 LLM 模型的支持:从最初仅适配 OpenAI API,逐步扩展到 Anthropic、Hugging Face 等模型提供商,以及支持本地部署的开源模型(如 LLaMA 系列),并提供了统一的调用接口。这意味着开发者可以在同一个框架下使用不同来源的模型,而无需为每个模型单独编写接入代码。
重大架构调整与稳定版本(2024 年初)
2024 年 1 月,LangChain 发布了 0.1.0 版本——这是官方认定的第一个稳定版本。本次发布伴随着一次重大的架构调整:将核心代码与第三方集成进行解耦。
具体来说,新引入了 langchain-core 库,其中包含了稳定的抽象接口和核心功能;而所有第三方集成(如各类模型、向量数据库、工具包的具体实现)则被移到了 langchain-community 或独立的伙伴包中。这一拆分带来了两个明显的好处:一是框架的模块化程度大大提高,开发者可以根据实际需求只安装必要的部分;二是依赖管理更加清晰,避免了之前一个大包引入过多不需要的依赖。
此外,0.1.0 版本还带来了 LangChain 表达式语言(LCEL),这是一套用于定义和组合链的声明式语法,支持用户高度定制链的执行流程(包括并行处理、异步调用、中间结果捕获等),使得复杂任务编排变得更加简洁和强大。
持续迭代(2024 年中至年底)
2024 年 5 月,LangChain 发布了 0.2.0 版本,引入了一系列新特性和改进,同时也包含部分 API 的调整(部分旧接口被标记为弃用)。该版本进一步增强了以下能力:
-
异步调用:支持非阻塞方式与模型交互,提升高并发场景下的性能。
-
流式输出:允许模型逐步生成内容并实时返回给用户,改善交互体验。
-
检索系统的集成优化:让 RAG 类应用的构建更加顺畅。
2024 年下半年,LangChain 发布了 0.3.x 版本,主要工作是持续改进性能,并不断增加新的集成支持,如更多的向量存储后端(例如 Milvus、Weaviate)和工具插件(如搜索引擎、计算器、数据库查询器等)。
面向未来的 1.0 版本(2025 年)
2025 年 9 月,LangChain 发布了 1.x Alpha 内测版,这标志着框架即将进入一个更加成熟和稳定的阶段。该版本在多个方面进行了重要改进:
-
统一现代 LLM 功能:在各模型提供商之间统一了对推理、引用、服务器端工具调用等现代大模型特性的支持。这意味着开发者可以用一致的代码写法,使用不同厂商提供的类似能力。
-
新增预构建的 LangGraph 链和代理:针对常见应用场景(如多轮问答、代码生成、数据分析等),直接提供了开箱即用的链和代理模板,降低了上手门槛。
-
包范围缩小:主
langchain包的职责被重新聚焦,只保留最流行和最重要的抽象概念。为了保持向后兼容性,原有的旧代码被移入langchain-legacy包,这样老项目在升级时不会立刻中断。
版本发布信息
完整的版本发布历史可以通过 LangChain 的 GitHub 仓库查看:
https://github.com/langchain-ai/langchain/releases
五.LangGraph
5.1 LangChain 的局限性
LangGraph 是 LangChain 生态系统中较晚出现的一个框架,其诞生背景与大语言模型应用日益增长的复杂性密切相关。随着开发者尝试构建更高级的 AI 代理和多轮对话系统,传统链式结构(即 LangChain 最初的核心模式)的局限性逐渐显现出来。
传统 LangChain 中的“链”是一种线性的、预先定义好的步骤序列。例如:先做 A,然后做 B,然后做 C,最后输出结果。这种模式在处理简单的、固定流程的任务时非常有效。但在实际复杂场景中,往往会遇到以下几个突出问题:
-
线性流程难以处理循环和分支:在真实应用中,经常需要根据中间结果返回上一步重新执行,或者根据条件选择不同的后续路径。线性链无法自然地实现“如果信息不完整,就重复询问直到完整”这样的循环逻辑,也无法实现“如果是投诉,走投诉处理流程;如果是咨询,走咨询流程”这样的动态分支。
-
缺乏对长期运行任务的状态维护能力:链每次调用通常是无状态的,即每次执行完就结束了,不保留任何中间信息。但在多轮对话、长时间运行的任务(如客服工单可能持续数小时甚至数天)中,系统需要记住之前说过什么、已经收集了哪些信息、当前进行到哪一步。如果完全依赖开发者自己管理这些状态(比如写入数据库、再从数据库读取),代码会变得非常臃肿且容易出错。
-
难以融入人工介入:在很多实际系统中,AI 并非全自动,有时需要将某些任务转交给人类处理(例如当用户情绪激动、或者遇到系统无法判断的复杂情况)。在线性链中,一旦需要人工介入,链就会中断。后续人工处理完成后,如何让原来的链继续执行剩余步骤?传统的链式结构没有提供现成的机制,开发者需要自己构建额外的系统来通知、等待、重新触发,导致整个工作流被割裂成互不相连的两段。
-
流程僵化,难以根据条件动态跳转:一个真实的客服系统需要根据用户的不同意图走不同的子流程。例如,识别出用户要“退货”,就走退货流程;识别出是“产品咨询”,就走咨询流程。在线性链中,实现这种分支通常需要写一个巨大的“主链”,内部通过大量的条件判断语句来调用不同的子链。这导致工作流的逻辑被隐藏在代码中,而不是以清晰、可见的结构呈现出来,使得设计、调试和后续维护都变得困难。
一个具体的例子:自动处理客服工单
假设我们要构建一个 AI 代理,用来自动处理用户提交的客服工单,包括退货请求、产品咨询、投诉等。一个理想的流程可能包含以下阶段:
-
信息收集:确认用户身份、订单号、问题类型等基本信息。
-
意图识别:判断用户是退货、咨询还是投诉。
-
路由到对应处理流程:根据意图进入不同的子流程(例如退货需要校验商品状态,咨询需要查找产品资料,投诉需要安抚并升级)。
-
执行具体操作:比如生成退货单、给出产品解答、记录投诉工单等。
-
结果确认与反馈:告知用户处理结果,询问是否满意。
如果用传统的链式结构(Chain A → Chain B → Chain C)来构建这个系统,会遇到以下具体问题:
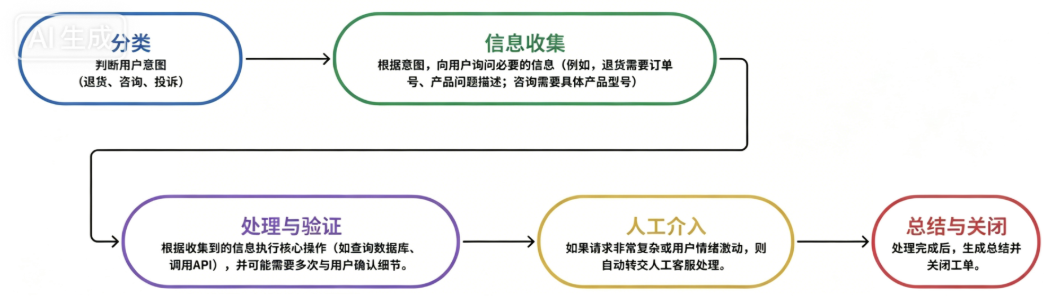
问题1:难以处理循环和分支 —— 无法动态路由和多次询问
在“信息收集”阶段,用户可能第一次提供了一个不完整的订单号(例如少了一位数字)。链式流程是单向的,一旦执行到下一步,就无法自动“跳回”上一步再次要求用户补充信息。结果只能是整个链失败退出,或者生成一个僵硬的错误消息(如“订单号无效,请重新提交工单”),用户体验非常差。无法实现“只要信息不完整,就持续询问直到完整”这样的常见逻辑。
问题2:状态维护困难 —— 无法长时间运行和记忆上下文
客服对话通常是多轮的,可能持续几分钟、几小时甚至几天(例如用户下班后回来继续咨询)。传统的链在每次调用时都是“无状态”的——它不记得上次用户说了什么,也不记得当前处理到哪一步。因此,状态管理的负担完全落在了开发者身上:必须依赖外部数据库或缓存来手动存储和读取每次对话的中间状态。随着业务逻辑复杂化,这部分代码会变得非常臃肿和脆弱,也容易引入状态不一致的 bug。
问题3:难以融入人工介入 —— 无法做到人机协同
当 AI 无法处理某些情况(例如用户情绪非常激动、涉及敏感隐私、或者系统规则未覆盖的特殊请求)时,需要将工单无缝地转交给人工客服。在链式流程中,一旦需要人工介入,链的执行就到此中断。之后人工客服处理完毕,系统如何继续执行后续的自动化步骤(比如向用户发送结案通知、记录满意度调查)?链式结构没有提供现成的机制。结果,整个流程被硬生生分割成两半:AI 自动部分和人工部分。开发者需要额外构建一套系统来通知人工客服、接收人工处理的结果,然后重新触发后续的链。这严重破坏了工作流的完整性和可管理性。
问题4:僵化的流程 —— 无法根据条件动态跳转
不同的用户意图需要完全不同的子流程。例如,如果用户意图是“投诉”,系统可能需要先触发安抚话术、再记录投诉详情、最后升级给主管;如果用户意图是“产品咨询”,系统可能需要先查询知识库、再生成产品介绍、最后推荐相关商品。在线性链中,实现这种条件分支非常笨拙:通常需要编写一个巨大的“主链”,内部通过大量的 if-else 语句来调用不同的小链。这导致工作流的逻辑变成了代码中的控制流语句,而不是以清晰可见的图形化结构呈现。开发和调试时很难一眼看清整个流程,后期修改一个分支也可能不小心影响其他分支。
总结:从链到图
正是由于以上这些局限性,LangChain 生态在后来引入了 LangGraph。LangGraph 不是用“链”来描述流程,而是用“图”。在图结构中,可以定义多个节点(每个节点代表一个处理步骤)和节点之间的边(代表执行顺序或条件跳转)。图支持循环、分支、状态持久化、人工介入等复杂场景,同时还能将整个工作流以可视化的方式展示出来。简单来说:链适合简单的、固定的流程;而图(LangGraph)适合复杂的、动态的、需要状态管理的任务。
在后续章节中,我们将进一步介绍 LangGraph 的具体能力,以及如何用它来构建更强大的 AI 代理和多智能体系统。
5.2 LangGraph:如何解决上述痛点
为了解决传统链式结构中存在的线性、无状态、难以分支和循环等局限性,LangChain 团队于 2024 年 推出了 LangGraph 框架。LangGraph 的核心思想是采用图结构和状态化的方式来构建复杂的 AI 代理应用,而不是沿用原来的线性链。
LangGraph 的官方定位是“低层次的编排框架”,主要用于构建可控、可靠的 AI 代理工作流。它并非一个实验性的项目,而是已经在一些生产环境中得到了实际应用。据报道,包括 LinkedIn、Uber、GitLab 在内的多家公司都在使用 LangGraph 来构建复杂的生成式 AI 代理系统。
用图结构重新设计客服工单代理
我们仍然使用之前“自动处理客服工单”的例子,来说明 LangGraph 如何解决问题。在 LangGraph 中,整个流程被建模为一个图。图中有多个节点(每个节点代表一个处理步骤,比如“信息收集”、“意图识别”、“退货处理”等),节点之间通过边连接,表示执行顺序或跳转逻辑。
与链式结构最大的不同在于,LangGraph 为整个流程维护了一个共享的状态对象。这个状态对象像一个公共的记事本,里面记录了所有在流程中产生的临时数据和决策结果。在图执行的过程中,任何一个节点都可以读取这个记事本,也可以往里面写入新的信息。后面的节点可以基于记事本中的内容决定下一步做什么。
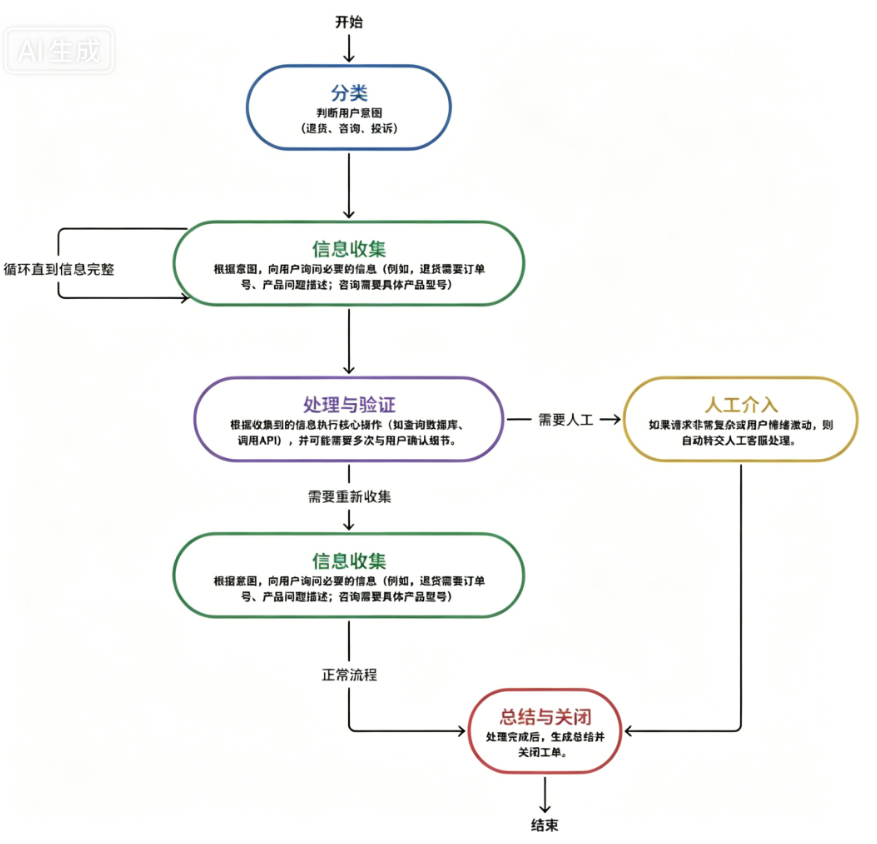
例如,我们可以定义图的状态包含以下字段:
-
intent:记录用户意图,比如“退货”、“咨询”或“投诉”。
-
collected_info:用一个字典(键值对)来存储已经收集到的信息,例如订单号、问题描述、用户联系方式等。
-
needs_human:用“是”或“否”来标记当前工单是否需要转给人工处理,默认值为“否”。
-
is_verified:标记已经收集的信息是否通过验证(例如订单号格式是否正确),默认值为“否”。
-
is_complete:标记整个流程是否已经完成,默认值为“否”。
-
message_history:用一个列表来保存整个对话的历史记录,用于多轮交互时的上下文记忆。
有了这样的状态对象,之前链式结构中的四个问题就可以得到有效解决:
-
循环和分支:当“信息收集”节点发现
is_verified为“否”时,可以通过一条边让流程跳回到该节点本身,再次要求用户补充信息,直到验证通过。这实现了循环逻辑。 -
状态维护:所有中间信息都自动保存在共享状态对象中,不需要开发者额外维护数据库或缓存。即使整个任务运行几天,状态也不会丢失。
-
人工介入:如果某个节点判定
needs_human设置为“是”,流程可以进入一个“等待人工处理”的节点,并在此处暂停。人工处理完成后,可以继续执行后续节点,无需打断整个工作流。 -
动态分支:在“意图识别”节点之后,可以根据
intent的值,通过条件边自动将流程路由到“退货处理”、“咨询处理”或“投诉处理”等不同的子图中,每个子图有自己的节点和逻辑。
LangGraph 与 LangChain 的关系
LangGraph 并不是要取代 LangChain,而是对 LangChain 的扩展和补充。LangGraph 的底层大量复用了 LangChain 的现有组件,包括模型调用接口、工具定义、记忆管理等。开发者可以在 LangGraph 的节点中直接使用 LangChain 的链或代理作为子流程。因此,两者是互补关系:
-
简单的线性任务:使用 LangChain 的链式结构已经足够高效,代码也更简洁。
-
复杂的控制流、长期状态、多智能体协作:使用 LangGraph 的图结构可以获得更强大的支持。
5.3 LangGraph 的技术特点
LangGraph 将应用程序的逻辑建模为图结构。图由两部分组成:
-
节点:每个节点代表一个操作或一个状态处理步骤。例如:接收用户输入、调用大模型、查询数据库、发送邮件等。
-
边:边定义了节点之间的转移顺序和数据流向。边可以是固定的(A 执行完后一定去 B),也可以是带条件的(根据当前状态决定去 C 还是去 D)。
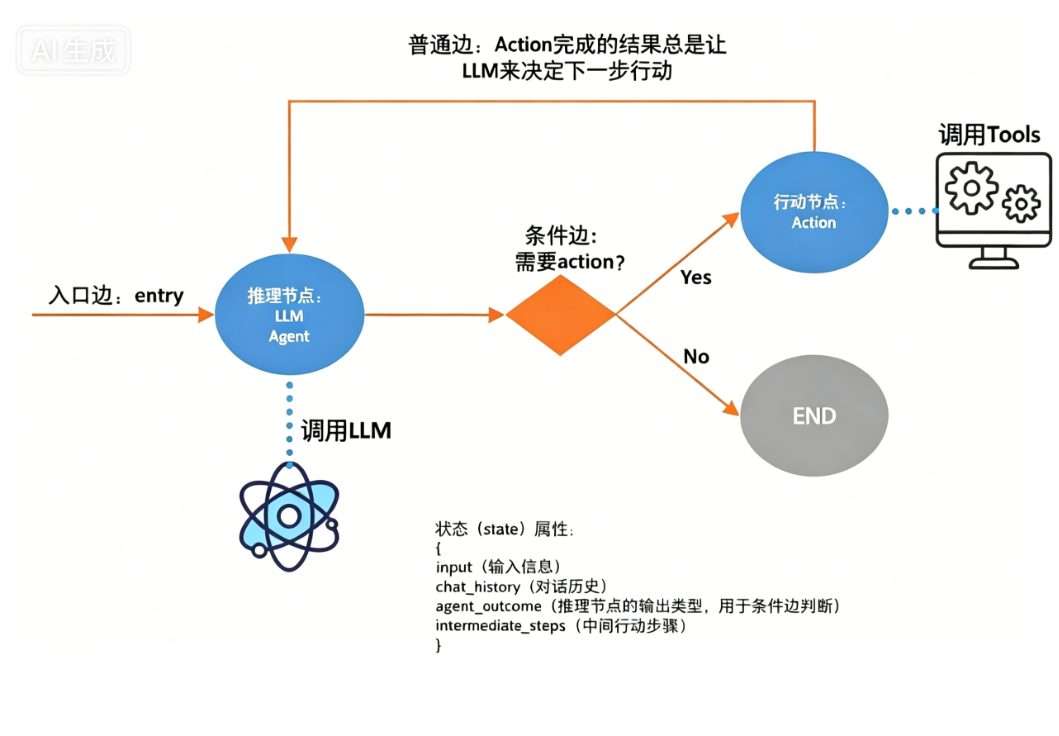
相比于 LangChain 的线性链式结构,LangGraph 的图式架构具有以下明显优势:
-
支持循环与分支:图中的节点可以指向其他任何节点,包括指向自己。因此,可以轻松实现“信息不完整时重复询问”这样的循环,也可以根据条件选择不同的后续路径。
-
动态路由:通过条件边,系统可以在运行时根据当前状态的值,动态决定下一个要执行的节点。例如,在“分类”节点之后,可以根据用户意图的识别结果,自动路由到“退货处理”、“咨询处理”或“投诉处理”等完全不同的子图中去。
-
自动状态维护:LangGraph 有一个核心的状态对象,在整个图的执行过程中自动保存和传递。所有节点都可以读取和修改这个状态。这意味着用户的对话历史、已经收集的信息、当前处理阶段等数据都会自动保留,不需要开发者手动管理。这对于长时间运行的任务尤其重要。
-
持久化执行:LangGraph 支持将状态持久化到外部存储(如数据库)。因此,即使系统因故障重启,也能从上次中断的地方自动恢复,继续执行未完成的任务。这对于需要数小时甚至数天才能完成的复杂代理来说非常关键。
-
人工协作能力:LangGraph 允许在执行的任何时候检查和修改代理的状态。这意味着可以在流程中无缝加入人工监督:例如当一个节点需要人工审批时,流程可以暂停,等待人工输入或修改状态,然后再继续。整个工作流保持完整,不会被分裂成多个独立的部分。
-
全面的记忆机制:LangGraph 可以为代理提供多种记忆能力。短期工作记忆用于在当前对话或任务中持续推理;长期持久记忆则可以跨越多个会话,例如记住用户长期的偏好或历史行为。
-
借助 LangSmith 进行调试:LangGraph 与 LangSmith(LangChain 生态的调试和监控平台)深度集成。开发者可以通过可视化工具查看整个图的执行路径、捕获每次状态转换、获得详细的运行时指标。这使得调试复杂的图结构变得非常直观,避免了在“面条式代码”中苦苦寻找问题。
-
生产级部署:LangGraph 提供了专门的基础设施来部署有状态的、长时间运行的工作流。它解决了传统无状态服务难以处理的持久化、恢复、扩展等问题,让开发者可以自信地将复杂的代理系统部署到生产环境中。
5.4.LangGraph 的发展历程
诞生背景与早期阶段(2024年初)
LangGraph 由 LangChain 团队于 2024 年 正式推出,旨在提供一种基于图结构和状态化管理的方式来构建复杂的 AI 代理应用。它的出现标志着 LangChain 从最初的“线性链式架构”向更灵活的“图式架构”进行了重要扩展。
在 2024 年初,LangGraph 首先作为 LangChain 0.1.0 版本中的一个实验性功能发布。当时它主要面向那些对复杂工作流编排有更高需求的早期开发者,允许他们尝试用图结构来定义循环、分支和状态管理。
独立演进与关键机制引入(2024年中)
从 2024 年中开始,LangGraph 逐步脱离 LangChain 主框架的束缚,开始独立演进。LangChain 团队为 LangGraph 建立了专门的代码仓库和独立文档,并将其打造为一套独立于 LangChain 主框架的工具集。
在这个阶段,LangGraph 引入了一个非常重要的机制——检查点。检查点允许系统在执行过程中定期保存整个图的运行状态。这一机制带来了两个直接好处:第一,当系统发生故障时,可以从最近一个检查点恢复,而不必从头开始执行;第二,所有执行状态都可以被记录和回放,便于后续的调试和审计。
功能完善与稳定化(2024年下半年)
进入 2024 年下半年,LangGraph 进入了密集的迭代周期,先后发布了 0.2.x 和 0.3.x 等多个版本。这些版本的主要工作是持续改进核心功能、提升系统稳定性、修复已知问题。
到 2024 年底,LangGraph 进一步增强了对异步执行和并发处理的支持。这意味着它可以更高效地同时处理多个任务,而不会互相阻塞。同时,该版本还提供了更完善的类型定义(方便开发者在编码时发现错误)和更友好的错误处理机制(当某个节点执行失败时,系统能够更清晰地报告问题所在)。
生态扩展与平台化(2025年)
2025 年,LangGraph 继续保持快速迭代,发布了 0.4.x 和 0.5.x 等版本。在此期间,LangGraph 发展出了完善的 Python 和 JavaScript 两种语言实现,覆盖了后端开发者和前端/全栈开发者的使用需求。
更重要的是,LangChain 团队在 2025 年推出了 LangGraph Platform 这一配套产品。LangGraph Platform 是一套用于简化复杂代理应用部署和管理的平台级工具,它解决了开发者在使用 LangGraph 时遇到的运维难题,例如如何将有状态、长时间运行的工作流部署到生产环境、如何进行版本管理、如何监控运行状态等。
迈向 1.0 正式版(2025年中)
2025 年 6 月,LangGraph 发布了 0.6 版本,并正式启动了 v1.0 路线图计划。团队开始广泛收集社区反馈,以确定正式版应该包含哪些核心功能、如何保持向后兼容、以及如何平滑升级。这标志着 LangGraph 已经从一个相对年轻的项目,逐步走向成熟和稳定。
后续发展(2025年下半年至2026年)
根据官方发布记录,LangGraph 在 2025 年下半年至 2026 年期间持续演进,主要工作集中在以下几个方面:
-
版本快速迭代:发布了 1.1.x 系列多个版本(如 1.1.6、1.1.7、1.1.8、1.1.9 等),每个版本都包含问题修复和小的功能改进。
-
预构建组件增强:
langgraph-prebuilt包持续更新,为开发者提供了更多开箱即用的节点和工具,例如增强的 ToolNode(工具节点),使其能够返回更丰富的结果类型。 -
命令行工具完善:
langgraph-cli工具不断优化,简化了图结构的本地开发和云端部署流程。 -
检查点机制升级:
langgraph-checkpoint包发布了多个版本(如 4.0.x 系列),提升了状态保存的安全性和灵活性,并支持更严格的序列化控制。 -
与 LangSmith 深度集成:增强了对执行路径的追踪能力、状态转换的捕获能力,以及详细的运行时指标输出。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 10
10 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)