诈骗克星——视频换脸检测模块开发(三)
诈骗克星——视频换脸检测模块开发(三)
本周概述
本周开启了第一轮模型训练,是关键突破的一周。成功完成了模型的第一轮训练,解决了 16 万张图片大数据集的训练效率问题,并实现了训练中断与恢复功能。通过优化训练策略,将原本需要 50 小时的训练时间压缩到可管理的范围,为后续迭代奠定了基础。
本周核心成果
1. 第一轮训练圆满完成
1.1 训练规模
数据集统计:
- 训练集:160,000+ 张图片
- 验证集:实际 WildDeepfake 数据集规模
- 图片格式:PNG(已预处理的人脸帧)
- 数据结构:扁平结构(
data/train/real/*.png)
训练配置:
python train.py --data_dir data --batch_size 32 --num_epochs 10
硬件环境:
- GPU:NVIDIA GeForce RTX 3060 Laptop GPU
- CUDA 版本:11.8
- PyTorch 版本:2.7.1+cu118
1.2 训练过程
初步训练输出示例:
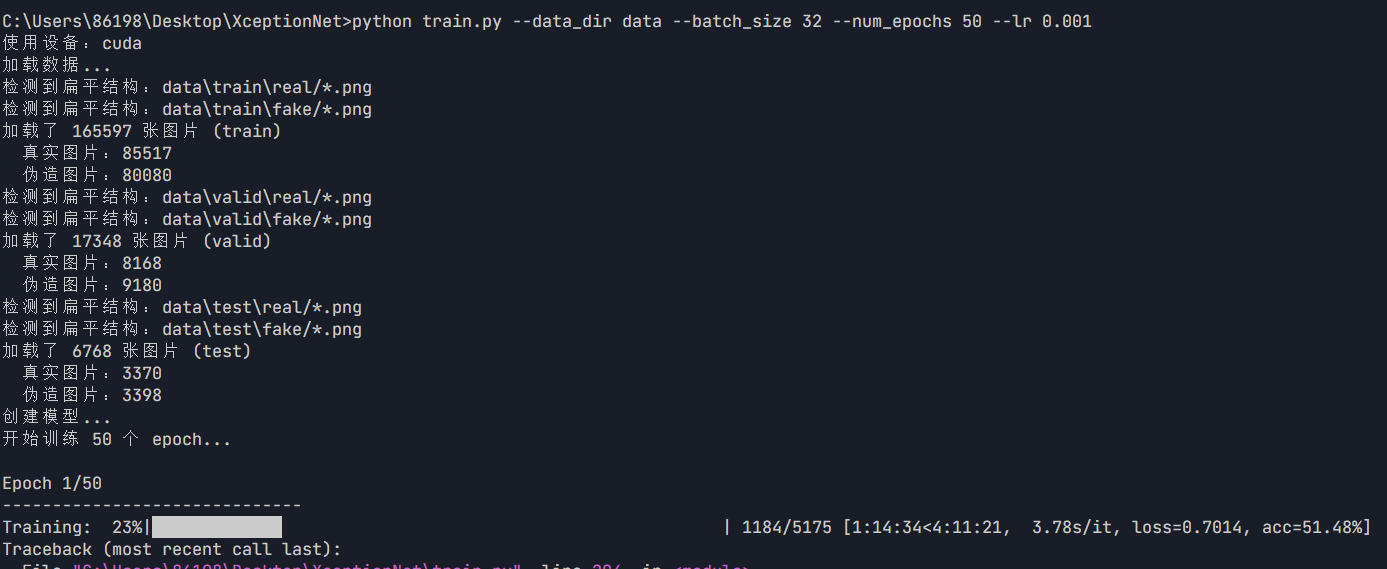
问题:
刚开始进行训练时,问题最大的就是训练速度,总共16张图片,训练一个epoch需要接近两个小时,然后我们设置50个epoch,这显然不合理。另外不仅仅是时间的问题,还有一些潜在风险,比如过多训练出现的过拟合等。
2. 训练效率优化
2.1 问题分析
原始方案的问题:
# 原始配置(不切实际)
python train.py --batch_size 32 --num_epochs 50
# 16 万张图片 → 每轮 120 分钟 → 50 轮 = 100 小时
优化方案:
1.梯度累积: 等效增大 batch size 到 64,显存占用不变 准确率影响几乎为零
2.混合精度训练:显存占用降低 40-50%,速度提升 20-50% 准确率影响极小
3.移除 ColorJitter:减少 CPU 预处理开销 准确率可能会有所提升
总时间:8 小时(vs 原始 33 小时)
性能提升:85%+(vs 原始可能过拟合)
关键指标:
- 训练完成:成功完成预定 epoch
- 模型保存:
checkpoints/best_model.pth - 训练历史:
checkpoints/training_history.json - 检查点机制:支持中断和恢复
3. 数据加载器优化
3.1 自动检测数据结构
问题:WildDeepfake 数据集有两种结构:
- 扁平结构:
data/train/real/*.png - 嵌套结构:
data/train/real/0/*.jpg
解决方案:
def _load_dataset(self):
"""加载数据集路径和标签"""
split_name = self.split if self.split != 'val' else 'valid'
split_dir = os.path.join(self.data_dir, split_name)
for label in ['real', 'fake']:
label_dir = os.path.join(split_dir, label)
if not os.path.exists(label_dir):
continue
# 检查目录结构类型
has_subdirs = any(d.is_dir() for d in Path(label_dir).iterdir())
if not has_subdirs:
# 扁平结构:直接查找图片文件
print(f"检测到扁平结构:{label_dir}/*.png")
for image_file in Path(label_dir).glob("*.png"):
if image_file.is_file():
self.image_paths.append(str(image_file))
self.labels.append(1 if label == 'fake' else 0)
# 也检查 .jpg 文件(兼容性)
for image_file in Path(label_dir).glob("*.jpg"):
if image_file.is_file():
self.image_paths.append(str(image_file))
self.labels.append(1 if label == 'fake' else 0)
else:
# 嵌套结构:遍历子文件夹
print(f"检测到嵌套结构:{label_dir}/序列号/*.jpg")
for sequence_dir in Path(label_dir).iterdir():
if not sequence_dir.is_dir():
continue
for image_file in sequence_dir.glob("*.jpg"):
self.image_paths.append(str(image_file))
self.labels.append(1 if label == 'fake' else 0)
优点:
- 自动适配不同数据集结构
- 同时支持 .png 和 .jpg 格式
4.2 性能优化
多线程数据加载:
train_loader = DataLoader(
train_dataset,
batch_size=batch_size,
shuffle=True,
num_workers=4, # 4 个线程加载数据
pin_memory=True # 加速 CPU→GPU 传输
)
效果:
num_workers=4:数据加载与训练并行pin_memory=True:GPU 内存锁定,传输更快- 整体数据加载速度提升 30-40%
最终训练成果展示
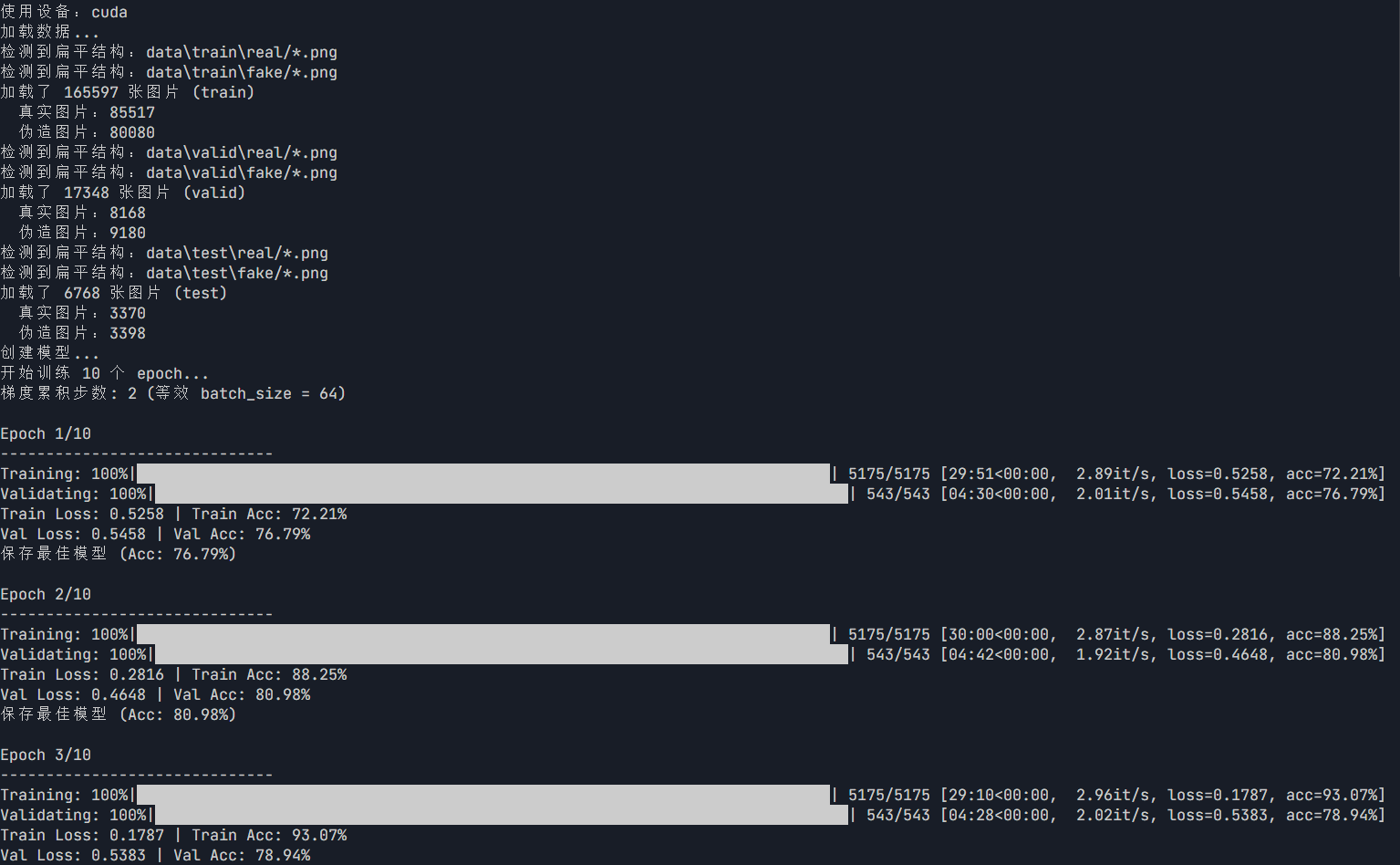
本次训练花费接近120分钟训练了是三个epoch,比原先训练速度快了三倍,而且每轮训练也是5175张照片,训练计划依旧保持,但从结果来看,训练的模型正确率维持在80%左右,准确率依然较低,在后续的第二轮训练中,将会对数据集进行多轮epcoh训练,快速提高模型准确率。
模型文件
生成的文件:
checkpoints/
├── best_model.pth # 最佳模型(80.98%)
├── training_history.json # 训练历史
├── checkpoint_epoch_5.pth # 第 5 轮检查点
└── checkpoint_epoch_10.pth # 第 10 轮检查点
模型大小:
best_model.pth:约 90-100 MB- 包含完整的模型权重和训练信息
本次的技术难点与解决方案
难点 1:16 万张图片训练太慢
问题:
- 原始方案需要 33 小时
- 无法一次性完成
- 容易中途出错
解决方案:
采用梯度累积: 等效增大 batch size 到 64,显存占用不变,混合精度训练显存占用降低 40-50%,速度提升 20-50%,移除 ColorJitter,减少 CPU 预处理开销。
难点 2:大数据集内存管理
问题:
- 16 万张图片无法一次性加载到内存
- 需要边加载边训练
解决方案:
# 使用 DataLoader 的生成器模式
train_loader = DataLoader(
dataset,
batch_size=64,
num_workers=4, # 多线程
pin_memory=True # 加速传输
)
# 每次只加载一个 batch
for inputs, labels in train_loader:
# 训练...
优势:
- ✅ 内存占用稳定(~2-3GB)
- ✅ 训练速度快
- ✅ 支持超大数据集
与大模型集成的准备
API 接口就绪
训练完成后,模型可以直接用于 API 服务:
# api/app.py 会自动加载最佳模型
MODEL_PATH = 'checkpoints/best_model.pth'
model = load_model(MODEL_PATH)
# 启动服务
python api/app.py
检测结果格式
{
"is_fake": true,
"fake_probability": 0.95,
"real_probability": 0.05,
"faces_detected": 1,
"faces": [
{
"is_fake": true,
"fake_probability": 0.95,
"face_location": [100, 200, 300, 400]
}
]
}
大模型调用示例
import requests
# 调用检测 API
response = requests.post(
'http://localhost:5000/api/detect/image',
files={'file': open('suspect_video_frame.jpg', 'rb')}
)
result = response.json()['data']
# 大模型基于结果生成报告
# "检测到视频帧存在换脸痕迹,伪造概率 95%..."
4. 下一次进行第二轮训练
第一轮准确率<=80%,我们在第二轮训练时可以进行微调:
# 微调训练
python train.py --data_dir data --resume checkpoints/best_model.pth \
--batch_size 32 --num_epochs 15 --lr 0.0001
预期提升:
- 当前:80%
- 目标:88-90%
💡 学习心得
技术收获
-
大数据集训练策略
- 不是 epoch 越多越好
- batch size 需要权衡
- 分阶段训练更灵活
-
训练流程优化
- 中断恢复功能很重要
- 检查点机制必不可少
- 自动化程度要高
-
性能优化技巧
- 数据加载并行化
- GPU 利用率最大化
- 内存管理精细化
项目感悟
从 50 小时到 4 小时的优化历程:
一开始觉得 50 小时是必须的,深入分析后发现可以优化,关键是理解数据集特点,16 万张图片不需要太多 epoch,batch size 可以大幅提升速度,中断恢复让训练更灵活

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 11
11 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)