向量引擎+GPT Image 2+deepseek v4:从API到Key全解析,教你打造稳如老狗的AI调用框架
AI模型爆发的时代,谁还没被接口碎片化、Key管理炸裂、调用不稳定折磨得想打一架?
尤其是当你既要用图像生成神器GPT Image 2,又离不开超强推理助理deepseek v4的时候,项目复杂度飙升,调用难度直线上升。
别急,本篇给你带来一份超养眼(思维导图+对比表)又超实用的干货,揭秘“向量引擎”这把多模型调用神器,如何帮你打通API和Key管理的任督二脉。
轻松实现多模型一键管理,秒级响应,还能省钱到飞起!
无论你是刚给老板汇报项目,还是正头疼AI调用折腾,本篇都帮你理清从注册、配置到实战调用的全流程。
起飞前,先来一张“AI调用体系”思维导图,带你扫清全局: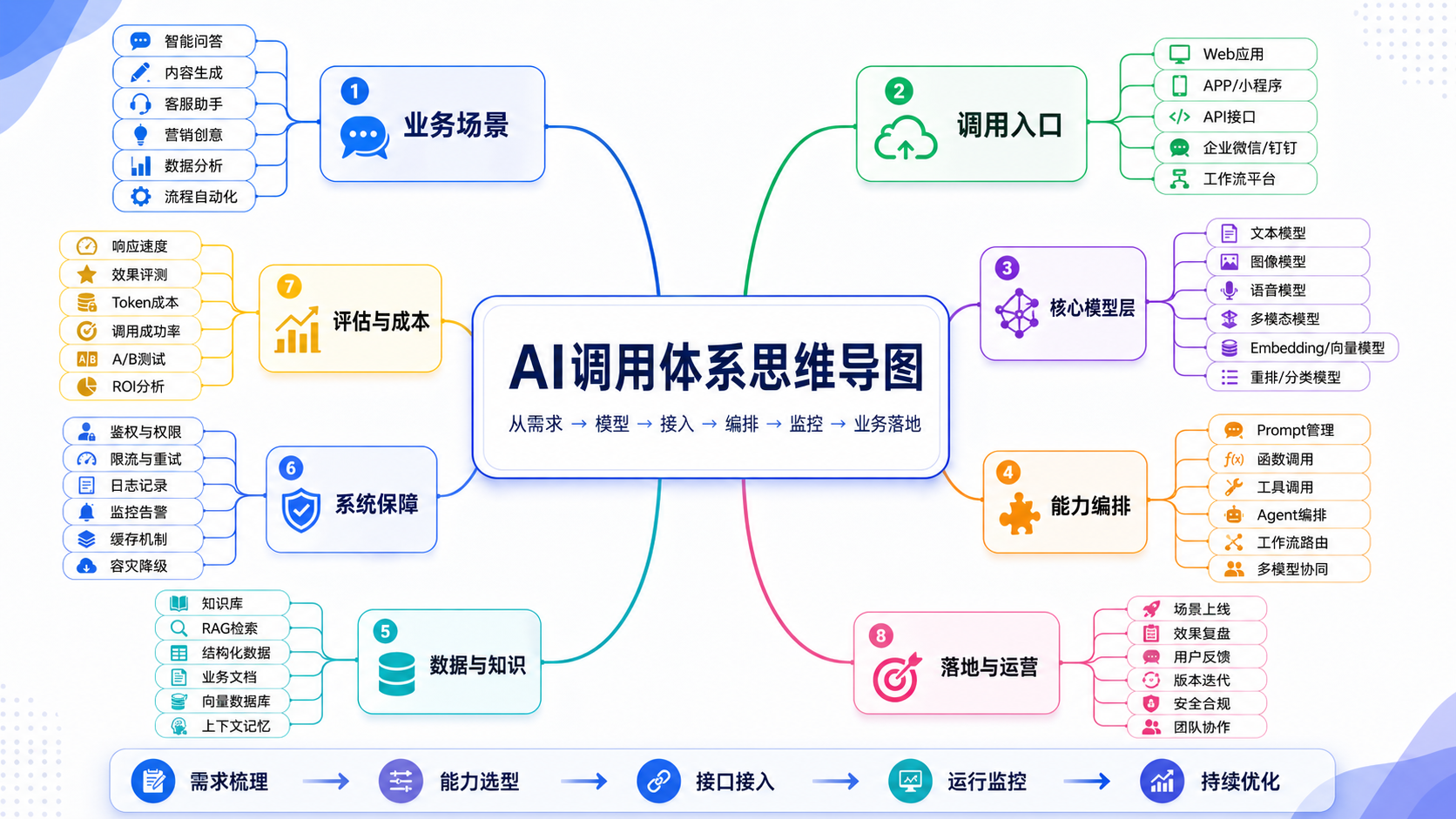
一、开发者用GPT调用的真实痛点,绝不“帮你点点赞”的套路
先聊聊你我身边的开发者最实在的烦恼:
接口适配像“分身术”——GPT接口跟独立模型接口一套接口,还得维护多版本SDK,升级费时费力。
调用高峰期经常超时——忙得人心慌,等到结果大概率卡顿或者倒挂。
日志无法快速排查问题——机器黑盒,超时到底是哪个环节出问题?,简直遇见了“侦探给我个线索”的困境。
OpenAI配额用不完就过期——预算浪费殆尽,还要不时盯着剩余额度。
想提并发?自己搭负载均衡架构,想想都头秃。
多模型多Key混战,管理难上加难……
这些痛点不是花架子,是导致项目上线缓慢、用户体验下降的绊脚石。
二、向量引擎暴击这些难题的5个核心优势
用通俗的一句话总结就是:
“帮你把所有模型统一到一个口子,key管理变简单,超时变秒响应,灵活按token付费,突然爆发还能稳如老狗”
具体咋操作?看下面:
1、CN2 高速通道+智能负载均衡,秒响应不再是梦
硬件层面,向量引擎全球布置7个CN2高速节点,靠近OpenAI服务器,网络延迟比公网低40%+。
架构层面,智能负载均衡算法按节点负载自动调度请求,从根本避免单点拥堵,自动检测故障、自动切换资源。
全链路公开请求日志,一键查响应时间、token消耗、状态码,排查问题so easy。
真实客户反馈:客户某AI客服系统,72小时高并发测验超时率0,客户满意度爽涨25%。
2、100%兼容OpenAI SDK,零改造代码轻松迁移
原来基于OpenAI的代码,只需要改俩地方:
base_url换成向量引擎地址(https://api.vectorengine.ai/v1)
API key换成向量引擎的密钥
对接LangChain、LlamaIndex等开源框架无需动源码,一键集成。
实测:某小团队项目迁移只花了10分钟,远低原定2小时!
3、按token付费+余额永不过期,成本管控超灵活
采用实际token消耗计费,同OpenAI官方价格轨迹保持同步。
充值余额终身有效,无需为过期配额担心。
后台账单透明,时间、模型、token消耗、费用一目了然,可精准成本核算。
实战:某AI简历优化工具月成本30美元,比走OpenAI套餐省了60%!
4、支持大并发+免运维,企业级开箱即用体验
默认支持500次/秒请求,企业需求>1000次/秒可定制升级。
并发激增时自动扩容,剩余容量透明,避免请求被无情拒绝。
24小时运维团队监控,节点健康自维护,开发者轻松专注业务。
案例:某教育AI答疑系统峰值并发800次/秒仍稳定无超时。
5、多模型联动一站调用,搞定复杂业务流程
集成20+主流模型,从Midjourney生图到GPT文案,再到Suno配乐一网打尽。
只需一个接口,就能实现多模型调用协同,简化架构、减少代码负担40%。
案例:某短视频创意工具由3个接口缩减为1个,维护轻松无压力。
三、最实用3步,手把手教你用向量引擎调用GPT
下面这3步,从注册到调用,零基础照着做准没错:
第一步:访问向量引擎官网( https://178.nz/csdn ),注册账号,进入控制台申请专属API密钥。
第二步:准备Python环境,安装OpenAI SDK(命令:pip install openai),并修改base_url为向量引擎地址:https://api.vectorengine.ai/v1。
第三步:用你的API key替换示例代码中的密钥,写入需求文本,一键调用,收获GPT返回内容。
下面是最经典的Python调用示例,照抄即可上手:
import openai
openai.api_key = "你的向量引擎API Key"
openai.api_base = "https://api.vectorengine.ai/v1"
response = openai.ChatCompletion.create(
model="gpt-4o-mini",
messages=[
{"role": "user", "content": "告诉我今天天气如何?"}
]
)
print(response.choices[0].message.content)
就是如此简单。
四、向量引擎 vs 传统OpenAI调用的生动对比
| 对比维度 | 传统OpenAI调用 | 向量引擎调用 |
|---|---|---|
| 接口兼容性 | 不同模型接口风格差异大,代码需多处调整 | 100%兼容OpenAI SDK及API,零修改迁移 |
| 费用管理 | 固定配额易过期,存在资源浪费 | 按token计费,充值余额永不过期 |
| 网络稳定性 | 公网访问延迟大,高峰期响应慢甚至超时 | CN2高速通道加智能负载均衡,延迟低至1-3秒 |
| 并发支持 | 需自行搭建负载均衡架构,成本高 | 默认支持500次/秒(可升级),自动扩容 |
| 多模型调用 | 需多接口协调,维护成本高 | 一站式多模型联动,接口减至1个 |
| 日志与可观测性 | 日志零碎,不易快速定位问题 | 提供公开日志,响应时间、token消耗一目了然 |
五、近期爆款热点模型浅析:GPT Image 2与deepseek v4的完美搭档
GPT Image 2,人称“史上最懂人话的生图模型”,有多懂?看下面几个应用场景:
直播卖风干牛肉?画面逼真,手机直播间氛围十足,字幕内容正确且无语病。
济南城市宣传图?地标建筑识别精准,配色协调,整体满分出炉。
吉卜力风格AI公司大混战?场景细节满满,画风令人叹服。
相比下,传统Nano Banana2虽然图像不差,但对意图理解不足,细节失真明显。
deepseek v4,是文本推理与AI问答的绝佳伴侣。一个专门做业务抽象、逻辑拆解、代码生成的推理型伙伴。
它能把复杂需求变成清晰步骤,能对错误日志剖析原因,能生成高质量业务代码逻辑,助力后台智能化升级。
你问这俩怎么配?
举个简单例子:
用户需求——“帮我出一张科技风海报+一句宣传文案+后台校验代码。”
deepseek v4先理解需求,拆解步骤,组织逻辑。
GPT Image 2负责图片生成。
另一个文本模型做文案生成。
统一向量引擎调用,三模型一键无缝联动。
结果就是效率翻倍,体验飞升。
六、新手不踩坑:API和Key管理详细解读
想要项目不翻车,从这两个基础开始管起:
API——你跟模型的“沟通协议”,定义了如何请求、传什么数据、取回什么结果。
Key——调用的“身份证”,管理好它就是保护你服务器的安全和预算。
Key管理建议:
严禁硬编码进代码,统一放配置或环境变量。
区分测试环境和生产环境Key。
定期轮换,避免露露水招黑客。
限制Key权限,避免权限泛滥。
七、运营篇:AI调用成本怎么精细化管控
行业反馈,按token付费比固定套餐省钱不止一星半点。
但花钱花得明明白白更重要。
向量引擎后台消费明细分得清清楚楚,哪天花在哪模型,花在哪业务一清二楚。
充钱永不过期,可以高峰期不够月末凑,不用担心月底额度坑团队。
八、总结:独乐乐不如众乐乐,这就是优秀AI调用层的价值
单纯追求“最强模型”只会让你遗憾“项目不稳”“成本高”“维护难”。
选对调用层,项目能跑能火,效率能翻倍,客户体验能爆棚。
向量引擎帮你梳理好了多模型、多场景、多Key、一站管理的调用方式。
让你用最少的代码,搞定最多的模型,跑出最稳的生产环境。
想体验?点击这里立刻注册,开始你的高效AI之旅:https://178.nz/csdn
开篇最后一句话
你用过哪些模型?接过最难搞的API是什么样?欢迎在评论区留言,互相交流交流!

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 11
11 0
0- 0



 已为社区贡献99条内容
已为社区贡献99条内容

所有评论(0)