《从零构建大模型》阅读总结
引言
现在能和ChatGPT交流,让它写代码、改文章,背后的核心其实是一套反复在做的“猜词游戏”。本文基于《从零构建大模型》[作者:[美]塞巴斯蒂安·拉施卡] 的逻辑主线,进行理解,整理和补充。从数据处理、模型结构,到预训练、微调,阐述大模型成型的完整链条。
大模型
大语言模型最核心的能力其实就一句话:处理和生成看似符合语境的文本。它属于自然语言处理(NLP)模型,底层大多基于Transformer——一种能并行处理序列的深层神经网络架构。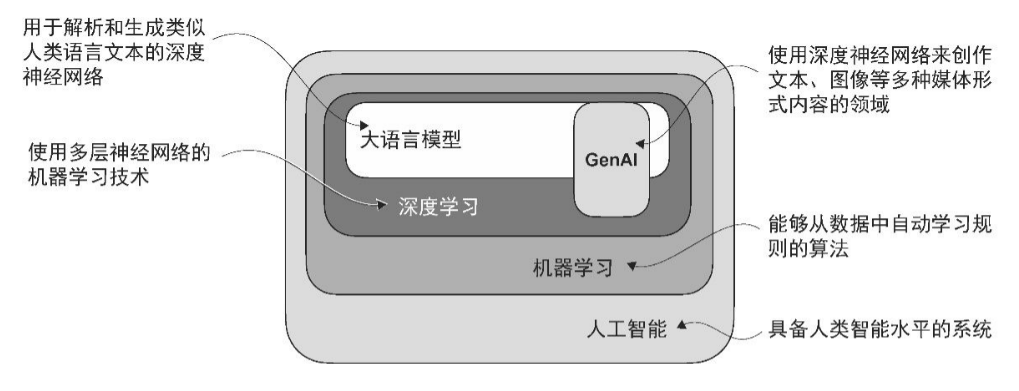
大模型的成型通常分两大阶段:
- 预训练:用互联网上的海量无标注文本(书籍、网页等),让模型学习语言的统计规律,得到一个基础模型。
- 微调:再用少量高质量标注数据,把基础模型调整到更适应具体任务,常见的有指令微调(让它听懂指令)和任务分类微调(如情感分类)。
现在大多数LLM都源于Transformer架构,但是其使用方式有所不同。经典的Transformer由编码器(Encoder)和解码器(Decoder)组成。流程是:自然文本 → 编码器 → 语义向量 → 解码器 → 自然文本。这其中诞生了两个流派:
- BERT:只用了编码器,擅长“读懂”文本(填空、分类)。
- GPT:只用了解码器,擅长“续写”文本(预测下一个词)。
其中ChatGPT、GPT-4,都属于GPT这条解码器路线,一个终极的“文本生成器”。
分词与嵌入
计算机只懂数字,所以处理文本的第一步就是把它切碎并向量化,这整个流程称为嵌入。
1. 分词(Tokenization)
文本先被切成一个个词元(Token),甚至是子词级别的。高级方案如BPE(字节对编码),能把“playing”切成“play”和“ing”,这样即使遇到生僻词也不怕,大大减少未知词<|unk|>的出现。
实际操作只需要几行代码(使用OpenAI的tiktoken库):
import tiktoken
tokenizer = tiktoken.get_encoding("gpt2")
tokens = tokenizer.encode("大模型很有趣。")
print(tokens) # 输出一串词元ID
print(tokenizer.decode(tokens)) # 还原文本
2. 从ID到向量
每个词元会根据词表得到一个唯一整数ID,然后通过嵌入层映射为高维词元嵌入向量。但光知道“词”还不够,模型还需要知道位置,因此会把位置嵌入加到词元嵌入上,最终形成大模型的输入。
训练阶段:文本分词 ——> 词元(token)——词汇表——> 词元ID ——> 滑动窗口(输入-目标对)——数据加载器——>输入-目标Pytorch张量 ——>嵌入向量 ——>批量送入模型 ——>计算损失 ——>更新参数。
推理阶段:接收原始文本
用户输入,比如:“请用一句话介绍北京”
——>分词
用同一个分词器(如tiktoken)把文本切成词元序列,再映射为词元ID。
结果变成一个ID列表,如:[1212, 318, 257, 1999, 820, 198]
——>转换为嵌入向量
查嵌入表得到每个词的词元嵌入,再叠加位置嵌入,形成最终输入张量:
[t1+pos1, t2+pos2, …, tn+posn],形状为 (1, seq_len, embed_dim)
——>一次前向传播,得到所有位置的预测
把整个序列一次性送入GPT模型(多层掩码注意力块),输出张量形状同样是 (1, seq_len, vocab_size)。
我们只关心里面最后一个位置的输出向量,因为它代表模型基于“请用一句话介绍北京”这个上文,预测出的“下一个词”的概率分布。
——>选出下一个词元
对最后一个位置的预测分数做softmax得到概率,然后用贪心采样(选最高概率)或温度采样等方法,挑出一个词元ID,比如 13809(可能是“北”字的子词)。
——>拼接到输入序列末尾
现在输入变成 [1212, 318, …, 198, 13809],长度+1。
——>循环生成直到结束
把新的序列再次喂给模型,取最后一个位置的输出,得到下一个词元ID……如此反复,直到模型生成了一个特殊的“结束符”(如 <|endoftext|>)或达到最大长度限制。
——>解码回文本
把生成过程中收集到的所有词元ID(不含原始输入部分,或包含由你决定)用分词器的 decode 还原为人类可读的文本。
最终输出:“北京是中国的首都,拥有悠久的历史和丰富的文化。”
滑动窗口(输入-目标对)纯粹是为高效训练而设计的数据结构,存在训练阶段,在推理阶段没有。
由词元变为词元ID 称为encode, 反之为decode
位置嵌入被添加到词元嵌入向量中,从而生成大语言模型的输入嵌入
3. 准备训练数据
预训练要用“滑动窗口”生成输入-目标对。例如文本“热爱可抵岁月漫长”,如果用窗口大小为4,可能构造出:
- 输入:[热,爱,可,抵] → 目标:[爱,可,抵,岁]
这就构成了预测下一词元的监督信号。经过数据加载器,这些输入-目标对被批量打包成PyTorch张量,送入模型。
自注意力机制
Transformer的强大来自自注意力机制:处理一个词时,模型会同时观察序列中所有其他词,并给每个词一个“注意力权重”,表示彼此有多相关。例如在“把桌上的苹果吃了,因为它很甜”中,“它”会高度关注“苹果”,而忽略“桌子”。这种权重通过点积计算得出,并为每个词生成融合了上下文信息的上下文向量。
为了防止在预测时“偷看”未来词汇,GPT引入了因果注意力机制(也叫掩码多头注意力)。解码时,系统用一个三角矩阵把未来的词强行遮蔽(权重为负无穷),让每个位置只能看到它自身及之前的内容。这就是语言模型自回归生成的关键:逐词预测,不偷窥未来。
对掩码多头注意力机制的通俗理解:用一个比喻来总结一下这两个阶段:
- 训练阶段:就像给你一张已经拍完的考卷照片,上半部分是题目,下半部分是答案,让你根据照片的上半部分来猜下半部分的内容。如果有掩码,是把照片下半部分挡住了让你猜;如果没有掩码,就是直接让你看着答案来回答,完全失去了考试的意义。
- 推理阶段:就像给你半张空白的画布,让你接着画下去。掩码机制就是确保你画画时,是基于已经画好的部分进行构思,而不是分心去盯着那些还没画的空白区域。
所以,大模型在训练时,是绝对不能“看见未来”的,那叫信息泄露,会彻底破坏学习;而在推理时,本就没有“未来”可以被它看见,掩码机制是为了让它专注于已有的“过去”,从而正确地创造未来。
GPT模型生成长文本
GPT的大模型架构清晰而优雅,按数据流顺序主要包括:
- 嵌入层:将词元转换为带位置信息的嵌入向量。
- Transformer块:核心计算单元,每一块内部含有掩码多头注意力和前馈网络,会堆叠很多层。
- 输出层:一个线性投影层,将每个位置的向量映射为词表大小的概率分布,得到“下一个词”的预测。
文本生成过程本质就是重复做这件事:把已有文本送入模型,取输出的最后一个位置的预测词,拼接到末尾,再重新送入,直到生成结束。所以GPT写作看起来就像一步一步的“词元涂鸦”,依靠全量上下文不断猜出下一个合理的词。
预训练
预训练是完全自监督的:不需要人工标注,直接从原始文本中构造任务。根据前面的词预测下一个词(下一词元预测)。经过预训练的大模式是基础模型,它已经内化了语法、事实、推理雏形,但不太会遵循人的指令,经常东拉西扯。这个阶段的模型就像一个博览群书但不懂沟通的孩子,需要后续的微调来“通人情”。
分类微调
如果想让大模型做特定任务,比如判断一段影评是好评还是差评,就可以用分类微调。
做法很简单:拿掉原模型的输出层,换成一个分类头(把向量映射为类别数),然后用少量带标签的数据训练。通常只更新分类头或少量参数(冻结主干),就能快速将通用的语言知识迁移到分类任务上。例如通过几千条标注影评,就可以得到一个高准确率的电影评价分类器,而无需从零训练。
指令微调
基础模型虽然会说,但经常“你说前门楼子,它扯胯骨轴子”。指令微调(Instruction Tuning)的目的,就是让模型学会理解并遵循人类的指令。
方法是用覆盖各类任务的“指令-回答”对继续训练模型。数据格式如:
指令:将以下英文翻译成中文。
输入:Hello, world.
输出:你好,世界。
通过大量这类高质量示例,模型学会了归纳指令意图,哪怕遇到没见过的任务格式,也能按照要求输出。配合人类反馈强化学习(RLHF)等对齐技术,模型变得更有用、更诚实且无害。今天智能对话体验,正是指令微调这一关键阶段赋予的。
结语
从把文字切成词元、嵌入成向量,到关注上下文的自注意力,再到千亿参数的预训练和精巧的微调,大语言模型铺就了一条从“高级填词机”到“通才助手”的演进之路。理解这些基本组件,就像获得了阅读AI时代的常识底色,在面对每次技术刷屏时,不仅能知其然,还能知其所以然。大模型的训练,微调,量化等工具有LLaMa-Factory。另外AI模型服务平台或推理中心有Xinference。
愿你我都能在各自的领域里不断成长,勇敢追求梦想,同时也保持对世界的好奇与善意!

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 8
8 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)