【人工智能】从零搭建AI问答助手项目(四):API调用实战
引言
在前面三篇中,我们依次梳理了项目整体架构、完成了云模型与本地模型的选型,也确定了后续要使用的CLI 交互形式。理论和选型部分已经铺垫完成,从这一篇开始,我们正式进入代码实战环节。
无论使用哪种模型,AI 问答助手的核心第一步都是实现可靠的模型调用。只有先把 API 调通,确保能够正常获取模型返回结果,后续的 RAG 检索、对话逻辑、交互界面才有基础。
本篇我们就以实现云模型 API 的调用为例,并封装成统一接口,为后续接入知识库做好准备。
版本目标
跑通流程,调通大模型,并只使用本地知识库作为回答问题的资料。
实现步骤
第一步,新建python项目
根据下面的项目结构创建一个新的python项目。
my_ai_qa_assistant/
│
├── core/
│ ├── rag.py # RAG主流程
│ ├── llm.py # 模型抽象层(关键)
│ ├── vector_db.py # 向量检索(先做简化版)
│
├── cli/
│ └── main.py # CLI入口
│
├── data/
│ └── knowledge.txt # 知识库
│
├── config.py # 配置(切模型用)
│
└── requirements.txt
项目结构实际效果图如下: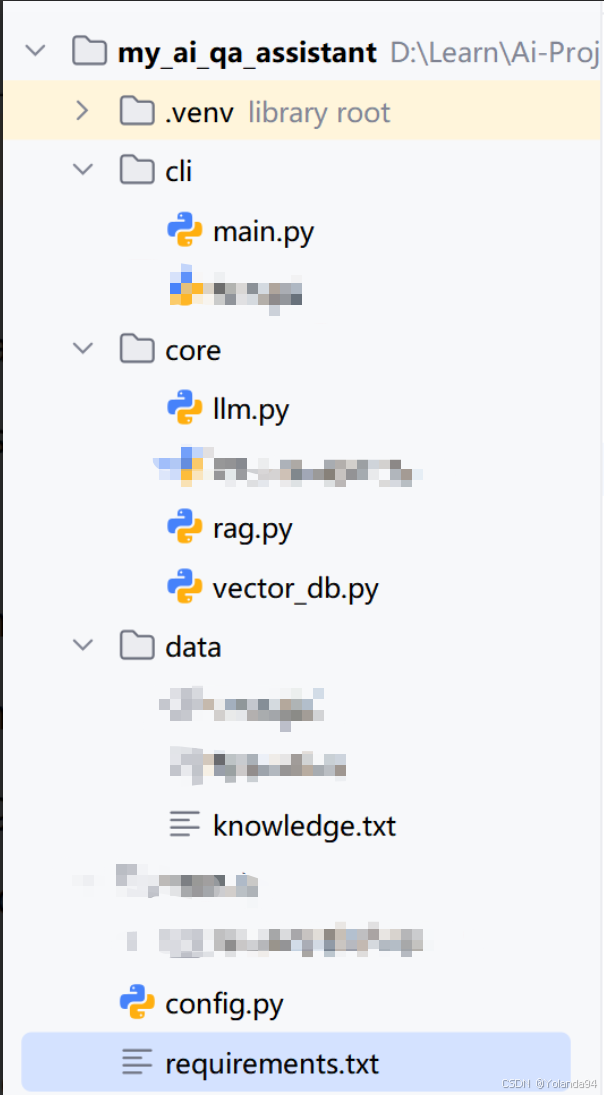
第二步,准备环境——依赖安装
python安装相关依赖,在PyCharm的命令行工具中输入以下命令,这是将openai和requests两个依赖安装到我们新建的python项目中。
pip install openai requests

第三步,配置文件(支持切换模型,config.py)
配置文件的作用是用来存储各个模型的API key信息,至于各个模型的API key则需要大家自行注册OpenAI账号和Deepseek开放平台账号,并获取相应的API key。
ps:为了后续调试能跑通,建议同时再注册通义千问的账号并获取相应的API key。
代码示例:
# 配置(切换模型用)
# MODEL_TYPE = "deepseek"
# MODEL_TYPE = "qwen"
MODEL_PRIORITY = ["openai", "deepseek", "qwen"]
OPENAI_API_KEY = "sk-*****************************************************************************"
DEEPSEEK_API_KEY = "sk-****************************"
QWEN_API_KEY = "sk-*******************************"
以下为各个模型的官网地址及查看API key的地址:
OpenAI官网
OpenAI官网查看API key
Deepseek开放平台
Deepseek开放平台查看API key
第四步,LLM抽象层(core/llm.py)
LLM抽象层的代码主要内容是对接各个模型,对接详情见各个模型的官方对接文档:
OpenAI对接文档
通义千问对接文档
以下为OpenAI、Deepseek、Qwen三个大模型的对接代码示例:
代码示例
# 模型抽象层(关键)
import dashscope
import requests
from config import MODEL_TYPE, OPENAI_API_KEY, DEEPSEEK_API_KEY, QWEN_API_KEY
class LLM:
def generate(self, prompt: str) -> str:
raise NotImplementedError
# OPENAI
class OpenAIModel(LLM):
def generate(self, prompt: str) -> str:
from openai import OpenAI
client = OpenAI(api_key=OPENAI_API_KEY)
resp = client.chat.completions.create(
model="gpt-4o-mini",
messages=[{"role": "user", "content": prompt}],
)
print("resp:", resp)
return resp.choices[0].message.content
# DEEPSEEK
class DeepSeekModel(LLM):
def generate(self, prompt: str) -> str:
try:
url = "https://api.deepseek.com/v1/chat/completions"
headers = {
"Authorization": f"Bearer {DEEPSEEK_API_KEY}",
"Content-Type": "application/json"
}
data = {
"model": "deepseek-chat",
"messages": [{"role": "user", "content": prompt}],
}
resp = requests.post(url, headers=headers, json=data)
print("resp:", resp)
if resp.status_code == 200:
raise resp.json()["choices"][0]["message"]["content"]
elif resp.status_code == 400:
raise Exception("[错误] 请求体格式错误,请根据错误信息提示修改请求体")
elif resp.status_code == 401:
raise Exception("[错误] 密钥错误,请检查您的 API key 是否正确")
elif resp.status_code == 402:
raise Exception("[错误] 账号余额不足,请确认账户余额,并前往 充值 页面进行充值")
elif resp.status_code == 422:
raise Exception("[错误] 请求体参数错误,请根据错误信息提示修改相关参数")
elif resp.status_code == 429:
raise Exception("[错误] 请求速率达到上限,请合理规划您的请求速率")
elif resp.status_code == 500:
raise Exception("[错误] 服务器故障,请稍后再试")
elif resp.status_code == 503:
raise Exception("[错误] 服务器故障,请稍后再试")
else:
raise Exception("[错误] 未知错误,请稍后再试")
except requests.exceptions.Timeout:
raise Exception("[错误] 请求超时,请稍后再试")
except requests.exceptions.ConnectionError:
raise Exception("[错误] 网络连接失败")
except Exception as e:
raise Exception (f"[未知错误] {str(e)}")
# QIANWEN
class Qwenmodel(LLM):
def generate(self, prompt: str) -> str:
try:
dashscope.api_key = QWEN_API_KEY
messages = [
{'role': 'system', 'content': 'You are a helpful assistant.'},
{"role": "user", "content": prompt}
]
resp = dashscope.Generation.call(
model="qwen-turbo",
messages=messages,
result_format="message"
)
print("resp:", resp.output)
return resp.output.choices[0].message.content
except Exception as e:
print(f"[错误] {str(e)}")
# 工厂函数(模型选择)
def get_llm_by_name(name: str):
if name == "openai":
return OpenAIModel()
elif name == "deepseek":
return DeepSeekModel()
elif name == "qwen":
return Qwenmodel()
else:
raise ValueError(f"不支持的模型类型: {MODEL_TYPE}")
def get_llm():
if MODEL_TYPE == "openai":
return OpenAIModel()
elif MODEL_TYPE == "deepseek":
return DeepSeekModel()
elif MODEL_TYPE == "qwen":
return Qwenmodel()
else:
raise ValueError(f"不支持的模型类型: {MODEL_TYPE}")
第五步,简化版“向量检索”(先用关键词代替,core/vector_db.py)
简化版“向量检索”的实现方案是将本地知识库的文本内容通过换行符"\n"进行切分为关键词,在搜索时选取前三条内容作为返回给用户的内容。
使用简化版的目的是为了快速跑通流程,暂且不必纠结这个设计是否合理。
代码示例:
# 向量检索(先做简化版)
from pathlib import Path
def load_knowledge():
BASE_DIR = Path(__file__).resolve().parent.parent
file_path = BASE_DIR / 'data' / 'knowledge.txt'
with open(file_path, 'r', encoding='utf-8') as f:
return f.read().split("\n")
def search(question, docs):
# 简单关键词匹配(后面会升级为向量检索)
results = []
for doc in docs:
if any(word in doc for word in question):
results.append(doc)
return results[:3] # 返回前3条结果
第六步,RAG主流程(“伪RAG”,core/rag.py)
RAG流程:用户在控制台输入问题,用问题的文本在本地知识库切分后的文本里检索答案,检索到答案后与默认的prompt提示词拼装成最终访问大模型的prompt,去调用相应的大模型生成回答。
代码示例:
#RAG主流程
from core.vector_db import load_knowledge,search
from core.llm_manager import LLMManager
docs = load_knowledge()
# llm = get_llm()
llm_manager = LLMManager()
def ask(question:str)->str:
related_docs = search(question,docs)
context ="\n".join(related_docs)
prompt=f"""
请基于以下知识回答问题,如果无法从中找到答案,请说“我不知道”。
知识:
{context}
问题:
{question}
"""
return llm_manager.generate(prompt)
第七步,CLI入口(cli/main.py)
CLI入口即用户交互入口,也就是用户输入问题的地方。本地测试时,在PyCharm控制台处进行交互。
代码示例:
#CLI入口
from core.rag import ask
def main():
print("AI问答助手(输入exit退出)")
while True:
q=input("\n请输入问题:")
if q.lower()=='exit':
break
answer = ask(q)
print("\n回答",answer)
if __name__ == '__main__':
main()
第八步,准备知识库
随便准备一段测试文本,用于后续提问测试。注意在后续版本优化中尽量保持本地知识库不变。
本地知识库示例:
Java是一种面向对象的编程语言。
Python是一种解释型语言,适合快速开发。
人工智能是研究如何让机器模拟人类智能的学科。
RAG是检索增强生成技术。
踩过的坑
读取文件的代码路径写的不适配
Chatgpt给的初始版本代码路径写的不适配,导致本地运行报FileNotFoundError: [Errno 2] No such file or directory: ‘data/knowledge.txt’,即Python 在当前运行路径下,找不到 data/knowledge.txt 这个文件。
问题主要出在这行代码上,这是一个相对路径,但它不是相对于文件,而是相对于执行Python命令时所在的目录。
with open("data/knowledge.txt", "r", encoding="utf-8") as f:
解决方案
其实有三种:
方案1(最快):用正确路径运行
回到项目根目录再运行:
cd ai_qa_assistant
python cli/main.py
方案2:改成绝对路径(工程常用)
修改 vector_db.py:
import os
BASE_DIR = os.path.dirname(os.path.dirname(os.path.abspath(__file__)))
file_path = os.path.join(BASE_DIR, "data", "knowledge.txt")
with open(file_path, "r", encoding="utf-8") as f:
return f.read().split("\n")
方案3:用pathlib依赖来获取文件路径。
from pathlib import Path
BASE_DIR = Path(__file__).resolve().parent.parent
file_path = BASE_DIR / "data" / "knowledge.txt"
with open(file_path, "r", encoding="utf-8") as f:
return f.read().split("\n")
但最终我决定采用方案3,因为:
方案1:仅为临时解决方案,且需要修改运行目录,如果做新的项目,这个代码复用过去依然可能还报这个错。
方案2:不够灵活,一旦代码迁移到服务器或者其他人的电脑,那么这个绝对路径可能就是失效了。
方案3:既灵活又可复用,不是绝对路径,不会换个电脑就失效,不用更改运行目录,复用到新项目依然可用。
大模型调用出错情况的处理
Chatgpt给的初始代码未对模型调用失败做异常处理导致调用Deepseek时返回402- 余额不足,但这个错误信息在运行时完全不抛出,也不打印在控制台上。从运行结果完全看不出是大模型调用的问题,断点调试才发现是这里有问题。
ps:余额这个问题,老实说,得感谢阿里家大业大,个人账户注册之后有免费额度(个人验证时是这样,不担保后续哈)。OpenAI和Deepseek都很高贵冷艳,不充值没额度。
为什么要处理大模型调用出错情况?
因为AI系统 = 不稳定外部依赖系统,所以必须做到可失败、可恢复、可降级。
可能出现的错误类型:
1、API Key / Token问题:
key无效、余额不足、token耗尽,报错:401 / 403
2、网络问题:
超时、DNS失败、连接断开,报错:Timeout / ConnectionError
3、接口限流(很常见):
QPS限制、并发限制,报错:429
4、服务端错误:
模型挂了、内部错误,报错:500
5、返回格式异常:
JSON结构变化、字段缺失
解决方案
针对模型调用不通的问题,因为OpenAI访问需要科学上网,Deepseek则是没有测试的额度,必须先充值,为了快速跑通流程,于是又找了国内的几个大模型是试了试,发现通义千问有免费额度,可以调通,遂优先使用通义千问。当然如果读者们有其他更好的方案也欢迎在评论区一起讨论~
至于异常处理机制,则主要增加了对Deepseek的异常码(参考Deepseek官网)的针对性处理:
if resp.status_code == 200:
raise resp.json()["choices"][0]["message"]["content"]
elif resp.status_code == 400:
raise Exception("[错误] 请求体格式错误,请根据错误信息提示修改请求体")
elif resp.status_code == 401:
raise Exception("[错误] 密钥错误,请检查您的 API key 是否正确")
elif resp.status_code == 402:
raise Exception("[错误] 账号余额不足,请确认账户余额,并前往 充值 页面进行充值")
elif resp.status_code == 422:
raise Exception("[错误] 请求体参数错误,请根据错误信息提示修改相关参数")
elif resp.status_code == 429:
raise Exception("[错误] 请求速率达到上限,请合理规划您的请求速率")
elif resp.status_code == 500:
raise Exception("[错误] 服务器故障,请稍后再试")
elif resp.status_code == 503:
raise Exception("[错误] 服务器故障,请稍后再试")
else:
raise Exception("[错误] 未知错误,请稍后再试")
except requests.exceptions.Timeout:
raise Exception("[错误] 请求超时,请稍后再试")
except requests.exceptions.ConnectionError:
raise Exception("[错误] 网络连接失败")
except Exception as e:
raise Exception (f"[未知错误] {str(e)}")
当然针对这种情况,其实最佳解决方案应该是采取降级策略,建立容灾机制:即OpenAI访问不通则调用Deepseek,Deepseek调用不同再调用其他大模型,比如通义千问。
代码示例
首先在core/llm.py(新增)
新增通义千问模型
# QIANWEN
class Qwenmodel(LLM):
def generate(self, prompt: str) -> str:
try:
dashscope.api_key = QWEN_API_KEY
messages = [
{'role': 'system', 'content': 'You are a helpful assistant.'},
{"role": "user", "content": prompt}
]
resp = dashscope.Generation.call(
model="qwen-turbo",
messages=messages,
result_format="message"
)
print("resp:", resp.output)
return resp.output.choices[0].message.content
except Exception as e:
print(f"[错误] {str(e)}")
新增新的模型选择方法:
# 工厂函数(模型选择)
def get_llm_by_name(name: str):
if name == "openai":
return OpenAIModel()
elif name == "deepseek":
return DeepSeekModel()
elif name == "qwen":
return Qwenmodel()
else:
raise ValueError(f"不支持的模型类型: {MODEL_TYPE}")
新增“模型调度器”:
# 模型调度器
from config import MODEL_PRIORITY
from core.llm import get_llm_by_name
class LLMManager:
def __init__(self):
self.models = [get_llm_by_name(name) for name in MODEL_PRIORITY]
def generate(self, prompt: str) -> str:
last_error = None
for i, model in enumerate(self.models):
try:
print(f"[尝试模型] {MODEL_PRIORITY[i]}")
result = model.generate(prompt)
print(f"[成功] 使用模型: {MODEL_PRIORITY[i]}")
return result
except Exception as e:
print(f"[失败]{MODEL_PRIORITY[i]}: {str(e)}")
last_error = e
return f'[系统错误]所有模型均失败{str(last_error)}'
将模型选择接入RAG:
from core.vector_db import load_knowledge, search
from core.llm_manager import LLMManager
docs = load_knowledge()
llm_manager = LLMManager()
def ask(question: str) -> str:
related_docs = search(question, docs)
context = "\n".join(related_docs)
prompt = f"""
请基于以下知识回答问题,如果无法从中找到答案,请说“我不知道”。
知识:
{context}
问题:
{question}
"""
return llm_manager.generate(prompt)
模型幻觉(Hallucination)
首先,明确一下定义:模型生成了看似合理但未被提供数据支持的内容。
一开始就简单地测试了“java”、“python”、“RAG”这种单个词,根本没有发现答案有超出我本地知识库的内容,以为整个流程已经完全跑通,达到本次版本的目标。结果突发奇想测了一个“Java有哪些优点”,发现大模型不仅没有回答“我不知道”,还给出了我本地知识库没有的答案,感觉不太合理,断点调试后发现了它最后使用了大模型自己的知识库得到了问题的答案。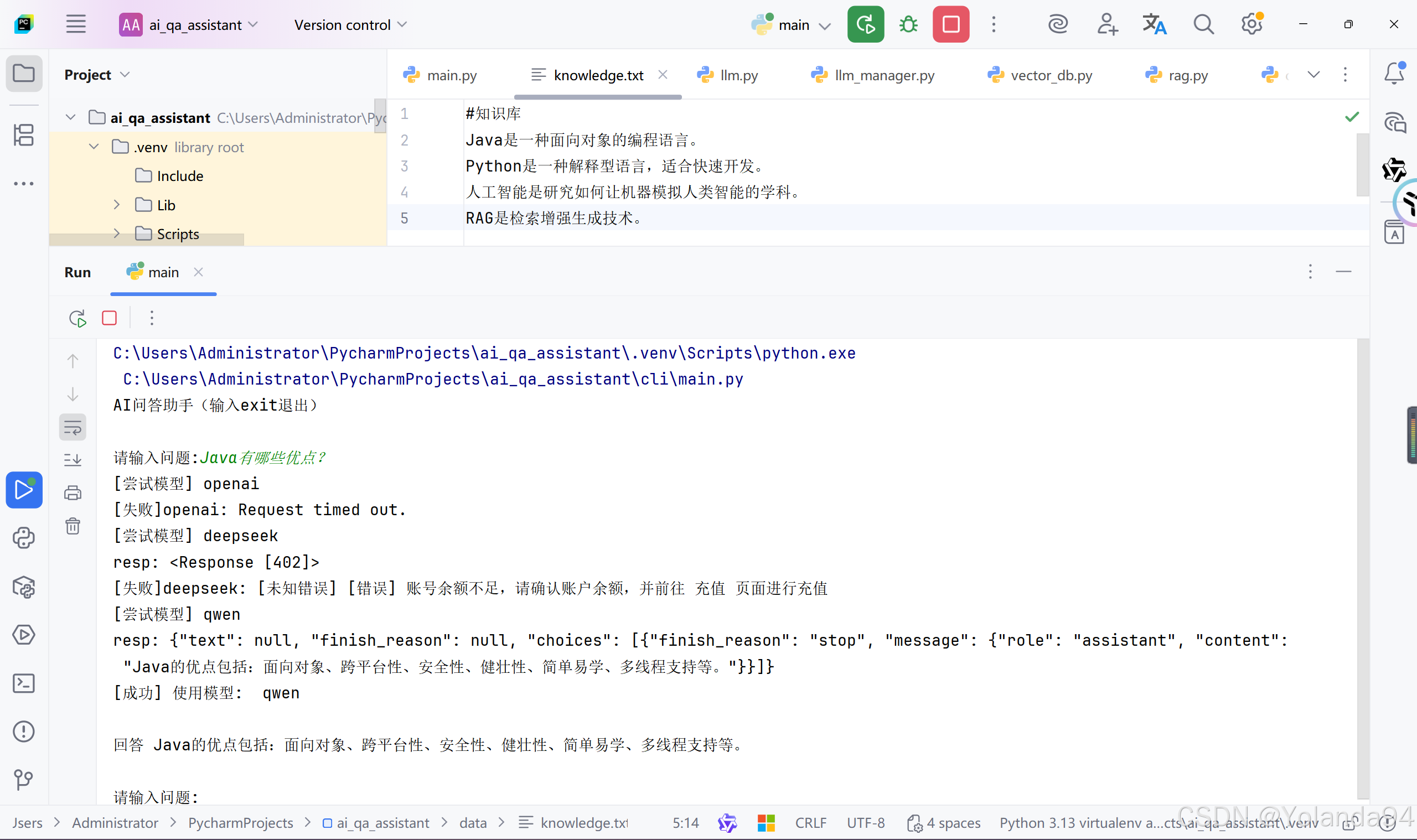
解决方案
强化 Prompt(最简单有效)
改为更强的约束,简而言之,严格要求大模型只能使用本地知识库,不允许使用大模型自己的知识库。
以下为Prompt示例:
你是一个严格的问答助手。
【规则】:
1. 只能根据“提供的知识”回答问题
2. 如果知识中没有相关内容,必须回答:“我不知道”
3. 不允许使用你自己的知识
4. 不允许进行推测或补充
【知识】:
{context}
【问题】:
{question}
加“空context判断”
def ask(question: str) -> str:
related_docs = vector_db.search(question)
# ❗关键判断
if not related_docs:
return "我不知道(知识库中未找到相关内容)"
context = "\n".join(related_docs)
prompt = f"""
你是一个严格的问答助手...
知识:
{context}
问题:
{question}
"""
return llm_manager.generate(prompt)
解决后的效果
规则:非本地知识库内容的问题回答“我不知道”。
使用了强约束后,同一个问题“Java有哪些优点”的答案,在本地知识库中没有检索到,所以按照Prompt的要求返回了“我不知道”。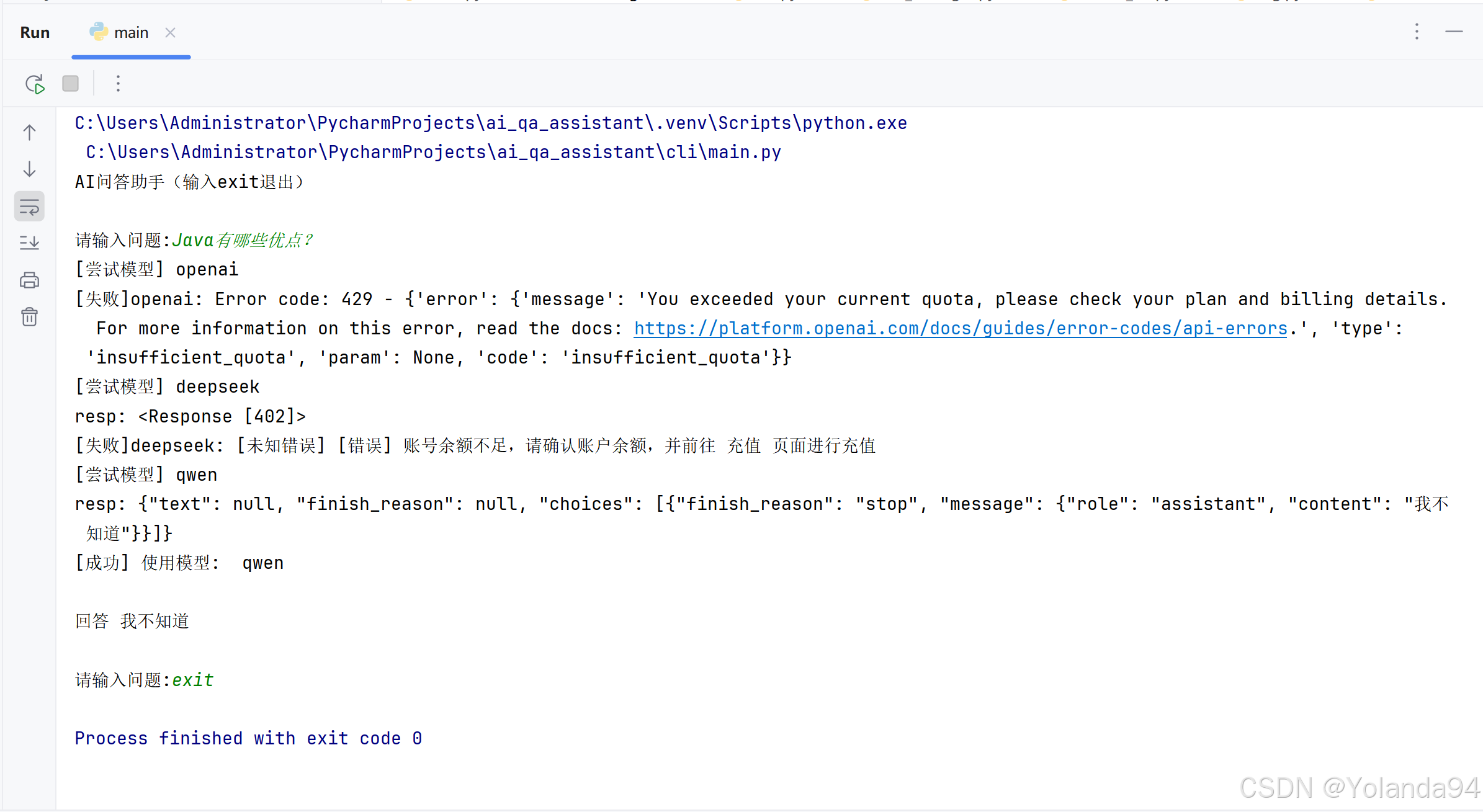
下一步

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 7
7 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)