Java开发者AI转型第十二课!吃透Embeddings向量化:让Java代码读懂文本语义
大家好,我是直奔標杆!专注Java开发者AI转型实战分享,和各位同行一起深耕Spring AI,从零基础到落地,每一步都干货拉满,拒绝纸上谈兵~ 今天带来《Spring AI 零基础到实战》系列的第12节,也是AI语义理解的核心一课——Embeddings(向量化),带你解锁文本背后的数学魔法!
回顾前面的课程,我们已经完成了ETL管道的“抽取(E)”和“切分(T)”两步,现在内存里已经积累了大量几百字的Document小文本块。接下来的关键,就是把这些文本存起来,供大模型后续高效搜索。但这里有个致命问题:传统数据库的搜索的是“字面匹配”,根本无法理解文本的“语义”。
举个很实在的例子:你的文档里写着“AI可以帮助人类提高效率”,但用户提问“AI会对生活产生影响吗?”,传统搜索会直接失效——字面重合度几乎为零!这也是很多Java开发者转型AI时,第一个卡住的难点:大模型到底凭什么能看懂两句话“意思相近”?
答案就是当代AI最核心的数学革命——Embedding(词嵌入/向量化)。今天这节课,咱们不玩虚的,先补好大模型底层的数学基础,再用纯Java代码手把手验证,一起搞懂AI“读懂语义”的底层逻辑,共同进步、一起上岸!
本节学习目标(共勉前行)
-
认知升级:搞懂数学层面的“向量(Vector)”和AI领域的“Embeddings”,打破认知壁垒;
-
吃透算法:深度拆解向量相似度的两大核心计算方法——欧式距离与余弦相似度,搞懂适用场景;
-
实战落地:结合Spring AI的EmbeddingModel和Apache Math库,用Java代码实现文本语义相似度计算,可直接复用!
核心突破:把自然语言“翻译”成高维数学空间
很多Java同行看到“高维向量”就头疼,其实不用怕,咱们用最通俗的话讲透,结合实战代码,保证人人能懂、个个会用。先看核心逻辑:Embedding的本质,就是把人类的自然语言,映射成高维数学空间里的一个“向量”——相当于给每段文本生成一张唯一的“语义基因图谱”。
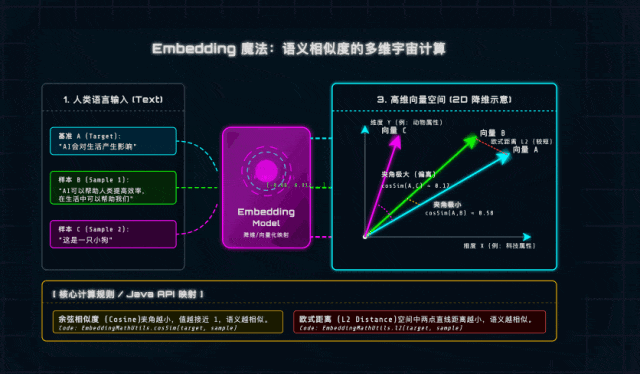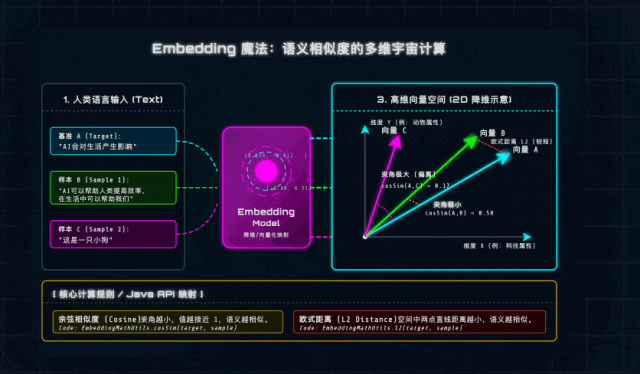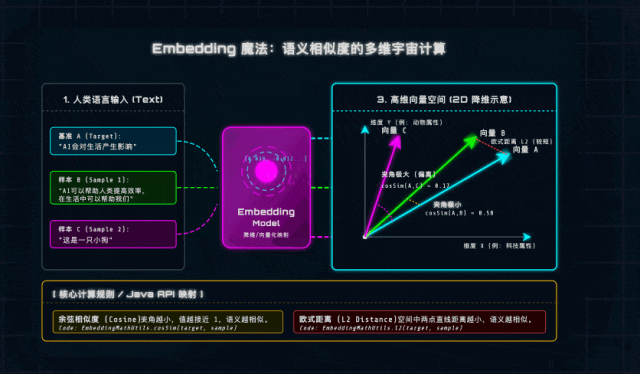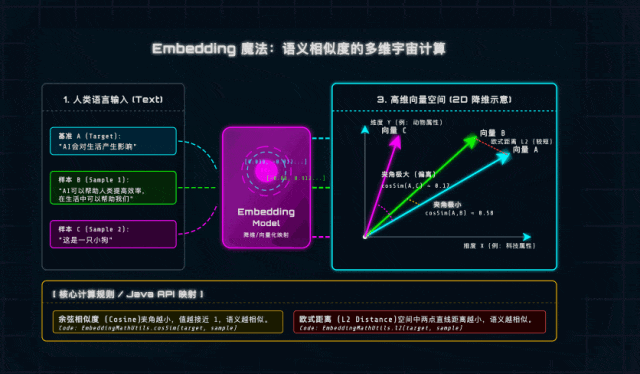
一、什么是向量(Vector)与Embeddings?(通俗解析)
从数学角度来说,向量就是“有大小、有方向的量”,形象点说就是带箭头的线段:箭头指向是方向,线段长度是大小,咱们不用深究复杂的数学推导,记住核心即可。
而在AI领域,Embedding(嵌入)就是大模型的“语言翻译器”——它能把我们说的每一句话、每一个词,翻译成一串浮点数(Float)数组,这串数组就是文本在高维空间中的“坐标”,每一个维度都对应一个潜在的语义特征(比如科技感、情感色彩、领域属性等)。
给大家举个实际例子,用常用的text-embedding-3-large模型(功能强、适配性高,适合复杂自然语言任务),输入一段文本后,它返回的向量大概是这样的(简化版):
[
0.03970907,
0.023125263,
0.01896734,
...
]这串看似杂乱的数字,就是大模型眼中的“语义”。再举个咱们Java开发者能秒懂的例子:“苹果手机”和“iPhone”,字面完全不重合,但Embedding模型(底层是训练好的神经网络)通过学习海量互联网知识,早就知道这两个词的“科技/数码属性”极强,“水果属性”极弱,所以它们的向量在高维空间中会靠得非常近——这就是AI理解语义的核心逻辑。
二、向量间的相似度计算:AI判断“语义相近”的数学依据
既然文本已经变成了高维空间中的“坐标点”,那判断两句话意思是否相近,就变成了一道纯粹的几何题:计算两个向量在空间中“靠得有多近”。这里重点讲两个Java实战中最常用的计算方法,建议大家记牢,后续项目一定会用到。
1. 欧式距离(Euclidean Distance)
核心逻辑:n维空间中两个点之间的“直线距离”,本质是基于勾股定理推导而来,相信大家上学时都接触过,不用死记公式,重点记适用场景和优缺点。
计算公式(通俗版):向量A减去向量B,得到的新向量的“长度”(即对应维度差值的平方和的平方根)。
判定标准:距离越小,两个向量(文本)越相似。
实战提醒(避坑重点):欧式距离对向量的“绝对大小”很敏感。比如两句话意思完全一样,但一句话长、一句话短,会导致向量模长不一样,计算出的距离变大,结果不够准确——所以文本语义对比场景,不优先用它。
2. 余弦相似度(Cosine Similarity)
核心逻辑:不关注向量的“长度”,只关注两个向量的“方向”——这刚好契合文本语义对比的需求:我们更关心两句话的“核心思想”是否一致,而不是字数多少。这也是Java AI项目中,语义匹配的首选方法。
计算公式(通俗版):向量A和向量B的点积,除以两个向量模长的乘积。
判定标准(必记):取值范围是[-1, 1],记住三个关键值:
-
1:方向完全一致,语义极度相似(比如一句话和它本身);
-
0:方向垂直,语义毫无关联(比如“AI”和“小狗”);
-
-1:方向完全相反,语义对立(比如“喜欢AI”和“厌恶AI”)。
小结:做文本语义匹配、关键词检索时,优先用余弦相似度;如果需要关注向量的实际距离(比如推荐系统中的用户偏好),再考虑欧式距离。
实战环节:用Java代码验证“语义相似度”(可直接复制复用)
理论讲再多,不如一行代码落地。咱们结合Spring AI和Apache Math库,手把手实现文本语义相似度计算,步骤清晰,新手也能跟着做,大家可以跟着敲一遍,加深理解,有问题欢迎在评论区交流~
步骤1:引入核心依赖(pom.xml)
需要两个核心依赖:Apache Math库(处理向量的点积、模长计算),以及Spring AI的OpenAI依赖(获取文本向量),版本已适配,直接复制即可:
<!-- 数学计算库:处理向量点积、模长等核心运算 -->
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-math3</artifactId>
<version>3.6.1</version>
</dependency>
<!-- Spring AI OpenAI依赖:用于调用API获取文本向量 -->
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-starter-model-openai</artifactId>
</dependency>步骤2:编写向量计算工具类(EmbeddingMathUtils)
把刚才讲的欧式距离和余弦相似度公式,封装成工具类,后续项目中可以直接复用,注释已经写得很详细,大家可以根据自己的需求调整:
/**
* 向量计算工具类(Java AI转型实战专用)
* 账号:直奔標杆 | 专注Java开发者AI转型,分享实战经验,共同进步
*
* 核心说明:
* - 余弦相似度:优先用于文本、关键词语义对比,关注方向,越大越相似
* - 欧式距离:适用于向量尺度一致的场景,越小越相似
*/
public class EmbeddingMathUtils {
/**
* 余弦相似度计算(文本语义对比首选)
*/
public static double cosSim(float[] embeddingA, float[] embeddingB) {
return cosSim(new ArrayRealVector(toDoubleArray(embeddingA)), new ArrayRealVector(toDoubleArray(embeddingB)));
}
public static double cosSim(RealVector a, RealVector b) {
// 公式实现:A·B / (|A| * |B|),点积除以模长乘积
return a.dotProduct(b) / (a.getNorm() * b.getNorm());
}
/**
* 欧式距离计算
*/
public static double l2(float[] embeddingA, float[] embeddingB) {
return l2(new ArrayRealVector(toDoubleArray(embeddingA)), new ArrayRealVector(toDoubleArray(embeddingB)));
}
public static double l2(RealVector a, RealVector b) {
// 公式实现:A-B的模长(直线距离)
return a.subtract(b).getNorm();
}
/**
* 工具方法:Spring AI返回float[],转为Apache Math需要的double[]
* 避坑点:处理null值,避免空指针异常
*/
public static double[] toDoubleArray(float[] floats) {
if (floats == null) {
return new double[0];
}
double[] doubles = new double[floats.length];
for (int i = 0; i < floats.length; i++) {
doubles[i] = floats[i];
}
return doubles;
}
}步骤3:Spring AI实战测试(TestEmbedding)
Spring AI已经帮我们封装好了EmbeddingModel,不用自己写HTTP请求调用OpenAI API,直接注入使用即可。咱们用三句话做测试,看看计算结果是否符合直觉,验证AI的语义理解能力:
// 直奔標杆 | Spring AI实战测试类
@SpringBootTest(classes = SpringAiDemo010Application.class)
public class TestEmbedding {
// 注入Spring AI封装好的EmbeddingModel,自动配置,无需手动初始化
@Autowired
private EmbeddingModel embeddingModel;
@Test
void testVectorMath() {
// 基准语句:我们要查询的核心文本
String targetText = "AI会对生活产生影响";
// 测试样本:语义相近、语义无关各一句,模拟实际搜索场景
List<String> textList = Arrays.asList(
"AI可以帮助人类提高效率,在生活中可以帮助我们", // 语义相近
"这是一只小狗" // 语义无关
);
// 1. 获取基准语句的高维向量
float[] targetVector = embeddingModel.embed(targetText);
// 2. 自身对比(验证计算准确性)
double selfCos = EmbeddingMathUtils.cosSim(targetVector, targetVector);
double selfL2 = EmbeddingMathUtils.l2(targetVector, targetVector);
System.out.println("【相同文本对比】: [" + targetText + "] vs [" + targetText + "]");
System.out.println("余弦相似度(越大越相似): " + selfCos + " ; 欧式距离(越小越相似): " + selfL2 + "\n");
// 3. 循环对比测试样本,模拟实际语义检索场景
for (String sample : textList) {
float[] sampleVector = embeddingModel.embed(sample);
double cosSim = EmbeddingMathUtils.cosSim(targetVector, sampleVector);
double l2Dist = EmbeddingMathUtils.l2(targetVector, sampleVector);
System.out.println("【样本比对】: [" + targetText + "] vs [" + sample + "]");
System.out.println("余弦相似度(越大越相似): " + cosSim + " ; 欧式距离(越小越相似): " + l2Dist + "\n");
}
}
}步骤4:测试结果分析(关键结论,必看)
运行测试用例后,会得到如下结果(数值可能有微小差异,属于正常现象),结合结果理解语义匹配的逻辑,大家可以对照自己的运行结果分析:
【相同文本对比】: [AI会对生活产生影响] vs [AI会对生活产生影响]
余弦相似度(越大越相似): 1.0000000000000002 ; 欧式距离(越小越相似): 0.0
【样本比对】: [AI会对生活产生影响] vs [AI可以帮助人类提高效率,在生活中可以帮助我们]
余弦相似度(越大越相似): 0.5806288901635841 ; 欧式距离(越小越相似): 0.915828694595532
【样本比对】: [AI会对生活产生影响] vs [这是一只小狗]
余弦相似度(越大越相似): 0.1795984715265334 ; 欧式距离(越小越相似): 1.2809383533767933核心结论(结合实战场景):
-
自身对比:余弦相似度接近1.0(理论最大值),欧式距离为0.0,说明计算逻辑正确,符合预期;
-
语义相近:虽然两句话字面差异大、字数不同,但余弦相似度达到0.58,说明模型能精准识别“AI与生活相关”的核心语义,这就是Embedding的魔力;
-
语义无关:余弦相似度跌至0.17,欧式距离增至1.28,说明模型能轻松区分无关文本,后续做检索时,可直接剔除这类低相似度结果。
企业级实战补充:本地Embedding模型混搭架构(避坑干货)
很多Java同行在做企业级RAG项目时,会踩一个大坑:把公司机密文档(比如核心源码、财务报表)通过公网发给OpenAI API做Embedding,这里有两个致命问题,一定要避开:
-
数据泄露风险:机密数据传给第三方接口,相当于把公司核心信息暴露在外,合规性不达标;
-
成本过高:海量文档(比如500页员工手册)加上Overlap重叠切分,Token数量惊人,频繁更新会产生高额费用。
破局方案(实战推荐):本地化+混搭架构!划重点:生成向量的Embedding模型,和最终聊天的Chat模型,完全可以分开选择,不用是同一个——这也是Spring AI的核心优势之一,接口高度抽象,解耦性极强,像搭乐高一样灵活组合。
具体做法:在企业内网部署一个开源免费的轻量级本地Embedding模型(比如bge-m3,亲测好用),专门处理海量文档生成向量,保证数据不出内网;最后需要生成回答时,再调用云端大模型(比如GPT-4o)——兼顾数据安全和回答质量,性价比拉满。
Spring AI配置示例(application.yml),直接复制修改即可使用:
spring:
ai:
# 聊天大模型:调用云端OpenAI GPT-4o
openai:
api-key: sk-xxxx... # 替换成自己的api-key
chat:
options:
model: gpt-4o
# 向量化模型:本地部署Ollama + bge-m3
ollama:
base-url: http://localhost:11434 # 本地Ollama服务地址
embedding:
model: bge-m3补充说明:Spring AI的ChatModel和EmbeddingModel是完全解耦的两个Bean,大家可以根据项目需求,灵活切换模型(比如Embedding用bge-m3,Chat用通义千问、智谱AI等),不用修改业务代码,这也是Spring AI的便捷之处。
本节总结(共勉)
今天这节课,咱们一起吃透了AI语义理解的核心——Embedding向量化技术,从数学原理(向量、相似度计算)到Java实战(工具类、Spring AI测试),再到企业级架构(本地模型混搭),每一步都贴合Java开发者的转型需求。
核心收获:我们学会了AI如何通过高维浮点数数组,将自然语言“量化”为可计算的语义,也掌握了余弦相似度这个实战中最常用的语义匹配方法,更避开了企业级项目中的数据安全和成本陷阱。
至此,ETL数据清洗管道的“抽取(E)、切分(T)、向量化(Embed)”三步已经全部完成!现在你的Spring容器里,已经有了成千上万个文本块和它们对应的向量,但这些数据还只存在于内存中——一旦断电,全部丢失!
下节预告(持续深耕)
既然向量和文本块不能一直放在内存里,那该如何永久、安全地存储?传统关系型数据库(MySQL、Oracle)根本无法高效存储和比对高维向量!
下一节(第十三课),咱们将解锁AI时代的专属新基建——向量数据库,一起学习《知识库的终极归宿!Vector Store (向量数据库) 架构演进与 redis-stack 实战》,利用Spring AI的统一VectorStore接口,将今天生成的向量全部存入数据库,彻底打通ETL管道的最后一关(L-加载)。
跟着直奔標杆,一步一个脚印,Java开发者AI转型不迷路!下节继续干货输出,咱们不见不散~
往期回顾(便于衔接学习)
-
Java开发者AI转型第九课!突破知识边界!企业级 RAG (检索增强生成) 核心架构与 ETL 管道初探
-
Java开发者AI转型第十课!化繁为简!Spring AI 全能文档解析器 (Document Readers) 与元数据提取实操
-
Java开发者AI转型第十一课!文本切分避坑指南:Spring AI 智能分块与Overlap语义防割裂实战
最后,欢迎各位Java同行在评论区留言交流,分享自己的实战心得、踩坑经验,咱们互相学习、共同进步,一起直奔AI转型的标杆!

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 11
11 0
0- 0



 已为社区贡献39条内容
已为社区贡献39条内容

所有评论(0)