GPU服务器租用:灵活算力如何选?
随着生成式 ΑΙ 场景的普及,随着大模型训练场景的普及,随着实时渲染等场景的普及,企业对 GPU 算力的需求呈指数级增长,开发者对 GPU 算力的需求呈指数级增长。然而,自建 GPU 服务器集群意味着有高昂的硬件采购成本,意味着有漫长的部署周期,意味着有持续的运维压力。因此,GPU 服务器租用模式正在成为越来越多团队的选择。本文将从成本维度,为您梳理 GPU 租用的核心要点与市场现状,本文将从弹性维度,为您梳理 GPU 租用的核心要点与市场现状,本文将从性能等维度,为您梳理 GPU 租用的核心要点与市场现状。
一、什么是GPU服务器租用?
一种按需付费的云计算服务是GPU服务器租用,用户不是自购硬件,而是借助互联网向服务商租借搭载GPU的服务器实例,像的RTX 4090、A100、H20等,租用模式通常涵盖三种形式。
有一种 GPU 容器实例,它具备开箱就能使用的特性,这种实例集成了大多主流的 AI 框架,并且它还支持通过一键操作就完成大模型的部署,其计费方式是依照使用的卡时来计算费用。
具有弹性特点的即时算力(),它能够在秒级的时间内实现自动伸缩,并且仅仅是在实际进行计算的那个时候才会去消耗资源,从而达成零闲置成本的情况。
面向裸金属租赁的情况,存在着这样的特性,物理机呈现出独占的状态,并且有着零虚拟化开销的特点,这种情况适合于高安全或者超低延迟的场景。
二、自建 vs. 租用:核心数据对比
将一台配备RTX 4090的GPU服务器作为例子,传统的自行搭建设置与租赁使用的关键衡量指标对比情况如下:
首先是初期投入方面,要是选择自建的话,那就需要去购买服务器硬件,这是以重资产的方式起步的,大概需要25万元,这里面包含了GPU、主板、电源等,而要是采用租用模式,也就是容器实例这种方式,每卡每小时仅仅需要从2.3元开始计费,并且是随时开启就能使用 的~
部署时间方面,对于自建而言,从进行采购开始,接着上架过程,再到环境配置,这一系列操作通常需要3个月时间;而租用服务的话,能够在5分钟之内实现开通并用于使用。
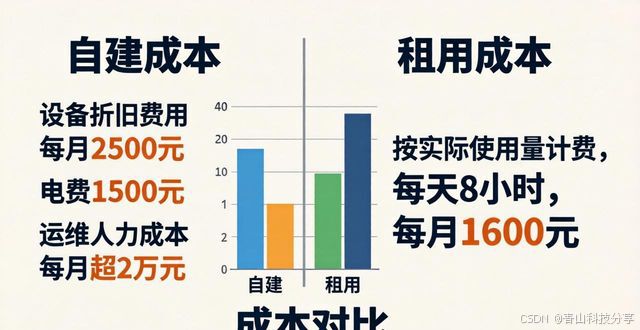
按月计算的成本方面,自己建设的话,其中涵盖设备折旧,每个月大概是2500元,还有电费,大约是1500元,以及运维人力,至少需要3人组成的团队,一年的成本100万起步,加起来每个月平均超过2万元。若选择租用的方式,则是依据实际使用量来计费,要是每天平均使用8小时,那么一个月的成本大概是1600元,这里面包含流量费用。
应对业务高峰时,弹性扩缩容方面,自建的情况会受限于硬件上限,要是手动进行扩容的话,所需时间会在4小时以上;而租用的方式呢,借助API调用或者自动策略,能够达成在秒级的伸缩切换,这样子便不会产生闲置浪费的状况(经过统计可知,在自建环境里,日均闲置率能够达到62%)。
网络时延方面,自建的情况是依赖单一个数据中心,在进行跨地域访问的时候,时延相对较高;而专业租用平台则借助全球节点调度,能够把端到端推理时延压缩到20毫秒以内。
三、选择GPU租用平台的关键指标
1. 算力规模与型号覆盖
具备千卡级以上资源池的可靠平台,应覆盖主流型号,这些型号从推理卡(像RTX 3090/4090)到训练卡(如H20、A100)。比如,当前市场里部分平台构建了2000P+异构算力资源池,同时配备2PB大容量存储以及Tbps级带宽,以此确保高并发场景下的稳定性。
2. 计费模式的灵活性
按卡时/按秒计费:适合实验、推理等间歇性任务。
包月租赁:适合长期训练或稳定生产环境。
有这样一种模式,它被称作混合模式,一些平台对其予以支持,其具备自动弹性扩缩容以及按量计费的特点,借助它这一模式能够把综合算力成本降低至超过总计成本百分之六十以上。
3. 节点分布与网络延迟
若业务是面向全球用户的情形,那就应当挑选边缘节点覆盖面广泛的服务商来合作。就拿白山智算来说,,它那边缘算力发放平台,把全球1000多个边缘节点给聚集起来了,范围涵盖东南亚、中东、美国以及欧洲等地,凭借智能路由优化以及就近推理这种方式,使得模型服务的端到端网络延迟下降了80%。对于实时渲染、金融风险预测这类对延迟敏感的用例来讲,节点选址可是特别重要的。
4. 技术服务与安全保障
专业的平台要提供7×24小时的AI工程师支撑,这支撑覆盖模型优化、容器部署、故障排查等整个流程。与此同时还得拥有网络安全防护能力,像是云WAF、抗DDoS攻击等。比如说,有些平台达成了智能监控告警,能把潜在风险的识别效率提高到90%,并且承诺99.99%的SLA(服务等级协议)。
四、典型应用场景的租用建议
大模型进行推理之际,运用GPU容器或者模式是较为推荐的做法。比如说在部署Llama 3或者Qwen模型之时,要去挑选那种已经预先设置好优化环境的平台,这样能够达成三分钟之内开通这一状况,并且依据现实的请求数量来计算费用。
对于模型微调或者训练,其需求具备连续性,而且资源消耗量大,既有裸金属租赁这种选择,又有包月容器实例可供挑选。就拿H20来说,每个月租金大约是44000元,它适合那种在3日内完成垂类大模型微调的自动驾驶仿真或者医疗影像AI应用场景。
视频进行渲染以及实时开展计算,要求具备超低的延迟以及突发的弹性,建议运用边缘节点在就近的地方进行处理,并且搭配自动扩缩容的方式,防止在峰值的时候出现排队的情况。
五、总结
通过资源池化、智能调度以及按需付费来租用GPU服务器,显著削减了企业获取高性能算力的门槛。不管是初创团队去验证AI原型,还是大中型企业来支撑商用级推理服务,租用模式都能够给出比自建更灵活、更有成本效益的解决方案。在挑选平台之际,要重点留意算力规模、计费粒度、节点覆盖以及技术支撑,并且借助像白山智算这类拥有全链路加速和多元异构池化能力的服务,能够更高效率地对业务创新予以支撑。就未来而言,随着边缘计算以及架构朝着进一步的成熟发展,GPU租用会变得更具实时性,更加经济实惠,而且更加易于使用。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 6
6 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)