Java开发者AI转型第十一课!文本切分避坑指南:Spring AI 智能分块与Overlap语义防割裂实战
大家好,我是直奔標杆!专注Java开发者AI转型干货分享,和各位同行一起从零基础吃透Spring AI,抱团成长、共同进阶~
欢迎来到《Spring AI 零基础到实战》系列的第十一课!上一节课我们刚搞定了RAG数据管道ETL的“E(抽取)”环节——用DocumentReader把PDF文件提取成带页码元数据的Document对象,相信很多小伙伴已经动手实操过,也感受到了Spring AI文档解析的便捷。
但实操中大家大概率会遇到一个问题:从PDF里提取的纯文本Document,动辄上万甚至几十万字,要是直接丢给后续的向量化模型(Embedding)处理,简直是“自找坑”!
大模型都有严格的Token窗口上限,超长文本不仅会直接导致API报错,就算勉强塞进去,用户搜索某个小知识点时,系统也没法精准定位到对应段落,检索效率和准确率直接拉胯。这也是很多小伙伴做RAG项目时,前期踩的最常见的坑之一,今天我们就一起解决它!
其实解决方案很简单:完成ETL的“T(转换)”环节——像切蛋糕一样,把长文档切分成大模型“好消化”的小文本块(Chunks)。这节课,我们就手把手拆解文本切分的核心技巧,避开语义割裂的坑,吃透Spring AI的Text Splitters!
本节学习目标(共勉共进)
-
避坑优先:搞懂“粗暴切分”的危害,再也不踩语义割裂的雷;
-
吃透核心:掌握文本切分的两个关键参数——Chunk Size(块大小)与Overlap(重叠度);
-
架构认知:了解Spring AI最新ETL规范下,DocumentTransformer家族的核心成员;
-
实战落地:用TokenTextSplitter优雅切分文本,实操SummaryMetadataEnricher与KeywordMetadataEnricher,让AI自动给文档打标签(附完整测试代码)。
避坑重点:为什么不能“粗暴切分”?语义割裂有多坑?
很多小伙伴刚开始做文本切分,都会想当然:每500个字切一刀不就完了?真的不行!这种“无情快刀”式的硬切,会导致极其致命的“语义割裂”,直接影响后续RAG检索的准确性。
给大家举个最直观的例子(相信大家一看就懂):
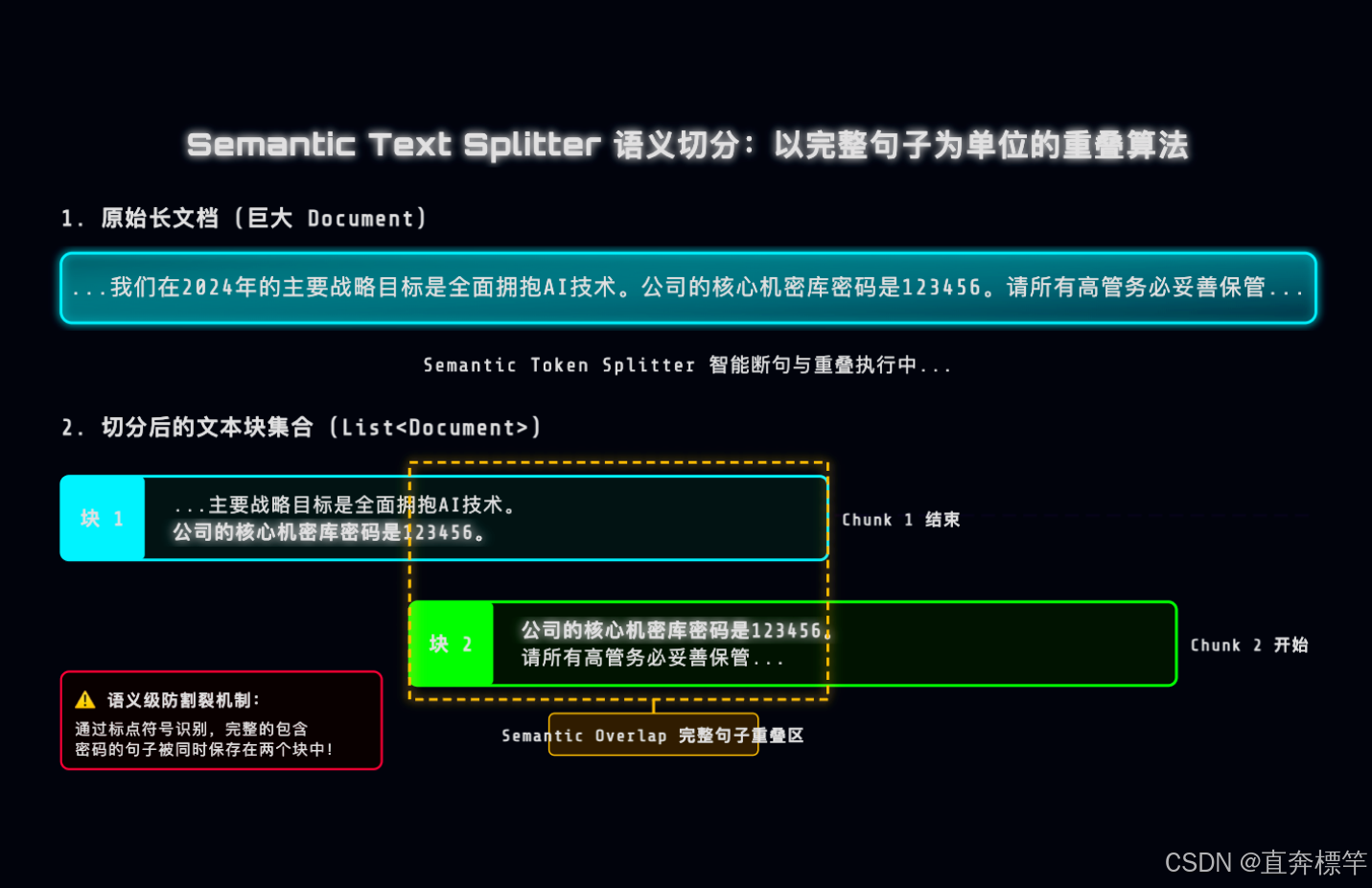
原文:“公司的核心机密库密码是123456,请妥善保管。”
如果硬切在中间,会变成这样:
块1:“公司的核心机密库密码是”
块2:“123456,请妥善保管。”
当用户提问“机密库密码是多少”时,检索到块1,没有密码;检索到块2,不知道123456是什么——相当于白切了,还踩了大坑!这就是语义割裂的危害,也是我们做文本切分必须避开的核心痛点。
核心解法:Overlap滑动重叠区,彻底解决语义割裂
想要避免语义割裂,关键就是引入“Overlap(滑动重叠区)”,结合Chunk Size一起设置,形成“黄金搭配”。先给大家用通俗的语言拆解这两个参数(配合图解理解更直观,大家可以自行对照实操场景脑补):
这两个参数直接决定了RAG检索的质量,建议大家记好实操范围:
-
Chunk Size(块大小):每个文本块的最大Token数,不是字符数!通常设置在500~1000之间——太长容易超出大模型处理上限,太短会丢失上下文,800左右是比较稳妥的中间值。
-
Overlap(重叠度):下一个文本块的开头,包含上一个文本块结尾的Token数。通常设置为Chunk Size的10%~20%(比如块大小800,重叠度100),这样就能完美衔接上下文,避免一刀切断语义。
关键疑问:为什么必须按Token切分?字符切分不行吗?
很多Java同行会问:我用Java原生的String.substring(),按字符长度(比如每500个char)切分,不也能实现效果吗?其实这里藏着一个容易踩的坑——大模型和Embedding模型,不按“字符(Character)”限制,只按“Token(词元)”限制!
给大家科普一个关键知识点(记牢能避坑):Token是模型底层的最小语义单元,不同语言的Token换算规则不一样,比如OpenAI的规则:
-
1个英文单词,大约对应0.75个Token;
-
1个生僻汉字,可能占用2~3个Token!
举个例子:如果盲目按1000个中文字符切分,经过模型Tokenizer(分词器)处理后,Token数可能膨胀到2500个,直接超出很多Embedding模型(512 Token或1024 Token)的上限,导致API报错。
这里给大家一个实操建议:Spring AI自带的TokenTextSplitter,对中文断句和重叠的支持不够完美,我自定义了一个SemanticTokenTextSplitter(源码可自取),能实现“物理大小限制+标点完整断句+句子级连贯重叠”的三重安全切分,避免踩坑。
进阶认知:DocumentTransformer家族,不只是切分那么简单
很多小伙伴以为文本切分就是“切完就完了”,其实不然。在Spring AI的ETL规范中,所有对Document进行加工的类,都实现了DocumentTransformer接口(对应ETL的T环节),这个家族非常强大,除了切分,还有两个高频实用的成员,建议大家重点掌握:
-
TokenTextSplitter:核心功能,负责将长文本物理切分成符合要求的Chunk;
-
KeywordMetadataEnricher:调用大模型,自动读取每个文本块,提取核心关键字(比如“Java, 并发, 锁”),并存入文档的Metadata中;
-
SummaryMetadataEnricher:调用大模型,自动为每个文本块生成一句话摘要,同样存入Metadata中。
可能有小伙伴会问:为什么要把关键字和摘要存入Metadata?这里给大家透露一个高阶技巧:在高级RAG检索(比如Self-Querying)中,我们可以先通过类似SQL的语法过滤Metadata(比如SELECT * WHERE keywords IN ('并发')),再进行向量相似度比对,能大幅提升检索精准度!这也是企业级RAG项目的常用优化手段。
实战环节:完整文本切分+LLM元数据增强流水线(附测试代码)
理论讲再多,不如动手实操一次。下面给大家分享一套完整的Transform流水线代码,包含PDF读取、文本切分、元数据增强,大家可以直接复制到项目中测试(记得替换自己的PDF路径),一起动手练起来!
准备工作:提前准备一份纯文本PDF(比如src/main/resources/docs/alibaba-java-guide.pdf),确保Spring AI相关依赖已导入。
@Test
void processEtlPipeline() {
System.out.println("--- 1. 执行 ETL-E (Extract) 读取 PDF ---");
PagePdfDocumentReader reader = new PagePdfDocumentReader(pdfResource);
List<Document> rawDocuments = reader.get();
System.out.println("读取到长文档总页数: " + rawDocuments.size());
System.out.println("\n--- 2. 执行 ETL-T (Transform): Token切块 ---");
// 初始化语义切分器:默认 每块最多 800 Token,重叠区 100 Token(可根据需求调整)
SemanticTokenTextSplitter splitter = SemanticTokenTextSplitter.builder().build();
List<Document> chunkedDocs = splitter.apply(rawDocuments);
System.out.println("成功切分为小文本块(Chunks)数量: " + chunkedDocs.size());
System.out.println("\n--- 3. 执行 ETL-T (Transform): 高阶 AI 元数据增强 ---");
// 3.1 关键字提取器 (告诉大模型:帮我给每个块提取最多 5 个核心关键字)
KeywordMetadataEnricher keywordEnricher = new KeywordMetadataEnricher(chatModel, 5);
// 3.2 摘要提取器 (告诉大模型:帮我总结这个块的核心思想,中文输出)
SummaryMetadataEnricher summaryEnricher = new SummaryMetadataEnricher(chatModel,
List.of(SummaryMetadataEnricher.SummaryType.CURRENT),
"""
这是该章节的内容:
{context_str}
请总结该章节的关键主题和实体,并使用中文回答。
总结:
"""
, MetadataMode.ALL); // CURRENT 仅总结当前块内容,避免上下文干扰
// 执行加工流水线:给被切碎的文档块,打上高价值的 AI 标签!
System.out.println("正在使用大模型阅读文本块并提取特征...");
List<Document> enrichedDocs = keywordEnricher.apply(chunkedDocs);
enrichedDocs = summaryEnricher.apply(enrichedDocs);
// 4. 查看加工结果,验证效果
System.out.println("\n========== 加工完成 ==========");
// 只打印前2个块,避免输出过多
for (int i = 0; i < Math.min(2, enrichedDocs.size()); i++) {
Document chunk = enrichedDocs.get(i);
System.out.println("\n【文本块 " + (i+1) + " ID】: " + chunk.getId());
System.out.println("【截取内容】: " + chunk.getText().replace("\n", "").substring(0, Math.min(60, chunk.getText().length())) + "...");
// 重点看这里:Metadata中新增了关键字和摘要
System.out.println("【提取的关键字 (Keywords)】: " + chunk.getMetadata().get("excerpt_keywords"));
System.out.println("【提取的摘要 (Summary)】: " + chunk.getMetadata().get("section_summary"));
System.out.println("【溯源页码】: " + chunk.getMetadata().get("page_number"));
}
}运行结果预览(直观感受效果)
--- 1. 执行 ETL-E (Extract) 读取 PDF ---
读取到长文档总页数: 3
--- 2. 执行 ETL-T (Transform): Token切块 ---
成功切分为小文本块(Chunks)数量: 6
--- 3. 执行 ETL-T (Transform): 高阶 AI 元数据增强 ---
正在使用大模型阅读文本块并提取特征...
========== 加工完成 ==========
【文本块 2 ID】: 6423e592-8a0e-438c-b385-e54f3a2c108f
【截取内容】: 是尽可能少踩坑,杜绝踩重复的坑,切实提升质量意识。 ...
【提取的关键字 (Keywords)】: Keywords: Java开发规约, 阿里巴巴, 代码质量, 云栖大会, 码出高效
【提取的摘要 (Summary)】: 该章节的关键主题和实体如下:
**关键主题**:
1. **Java开发规范**:强调通过《阿里巴巴Java开发手册》减少代码缺陷,提升开发质量。
**核心实体**:
- **《阿里巴巴Java开发手册》**:核心文档,规范开发实践。
【溯源页码】: 1大家可以看到,我们不仅把长文本切成了适合大模型处理的小文本块,还通过两个Enricher让AI自动提取了关键字和摘要,贴在了Metadata上。而且最关键的是,原有的溯源信息(比如page_number页码)完全保留,后续排查问题、追溯来源非常方便!
本节总结(一起复盘,巩固知识点)
到这一节,我们已经顺利完成了RAG架构ETL数据管道的前两个核心环节,复盘一下,帮助大家加深记忆:
-
E(Extract 抽取):用DocumentReader将不可读的物理文件(如PDF),提取为带元数据的纯文本Document集合;
-
T(Transform 转换):用SemanticTokenTextSplitter配合Chunk Size和Overlap黄金参数,安全切割长文本;再用KeywordMetadataEnricher和SummaryMetadataEnricher,让AI给每个文本块打上关键字、摘要标签,提升后续检索精准度。
现在,我们手里已经有了一堆贴满“标签”的小文本块,下一步就是解决RAG检索的核心问题:如何让机器理解语义?
举个例子:文本里写的是“机密”,用户搜的是“保密”;文本里是“苹果手机”,用户搜的是“Apple iPhone”,传统的SQL模糊查询(LIKE "%关键字%")根本无法匹配,但语义上它们是同一个意思。这就是我们下一节课要解决的核心问题!
下节预告(精彩继续,不见不散)
如何让冷冰冰的机器,真正理解语义的一致性?答案就是Embedding(向量化)!
下一节课(第十二课):《AI时代的数学魔法:Embedding (向量化) 模型与语义相似度降维打击》,我们将一起揭开大模型底层的数学奥秘——调用Embedding API,把这些纯文本小段落,转换成几千维的浮点数数组(向量),这也是RAG检索高精度运行的核心!
期待和各位同行继续一起深耕Spring AI,从零基础到实战,逐步实现Java开发者的AI转型,直奔標杆!
往期干货(错过的小伙伴可以补卡)
-
Java开发者AI转型第八课!避开Token陷阱!Spring AI记忆裁剪源码解析与Token级防溢出核心技巧
-
Java开发者AI转型第九课!突破知识边界!企业级 RAG (检索增强生成) 核心架构与 ETL 管道初探
-
Java开发者AI转型第十课!化繁为简!Spring AI 全能文档解析器 (Document Readers) 与元数据提取实操
最后,欢迎各位同行在评论区留言交流实操心得,遇到的问题也可以提出来,我们一起探讨解决,共同进步!觉得有用的话,记得点赞收藏,关注直奔標杆,后续持续更新Spring AI干货~

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 15
15 0
0- 0



 已为社区贡献39条内容
已为社区贡献39条内容

所有评论(0)