BIT-TPS:关于实验 8:线程池与工程收尾——ThreadPool 接入 TaskGraph的简单解释
本实验不属于考试内容,在此简单略过,只作了解
主线项目:MiniEngine — 子系统 B 收尾 + 全工程 demo

看到这里我真的有点懵,所以为了节约时间咱们尽快做完
Task 1:导入骨架,确认工程前置条件

新增文件:
include/ThreadPool.h ← 骨架(填写 TODO)
include/Scheduler.h ← 骨架(填写 TODO)
apps/week08/thread_pool_lab.cpp ← 练习(填写 TODO)
apps/week08/main.cpp ← 只读(端到端 demo)
tests/ThreadPoolTest.cpp ← 已有测试 + 末尾 TODO 追加区
tests/SchedulerTest.cpp ← 已有测试 + 末尾 TODO 追加区
完成之后先尝试能不能构建成功
cmake -S . -B build -G "MinGW Makefiles"
cmake --build build --target week08_thread_pool_lab
能够构建(即使 TODO 未填写),说明工程配置正确,可以继续完成热身练习。
git checkout main
git checkout -b lab/week08-threadpool
git add .
git commit -m "init: 导入 MiniEngine 第8周骨架"
注意。这里是不需要push的
Task 2:线程池热身练习
1 要求

2 代码
#include <chrono>
#include <condition_variable>
#include <exception>
#include <functional>
#include <future>
#include <iostream>
#include <mutex>
#include <queue>
#include <stdexcept>
#include <string>
#include <thread>
#include <vector>
// ─────────────────────────────────────────────────────────────────────────────
// 第 8 周线程池热身练习
//
// 运行方式:
// cmake --build build --target week08_thread_pool_lab
// ./build/apps/week08_thread_pool_lab
//
// 四道练习逐步引导:
// 1. 条件变量 + 谓词 wait
// 2. 生产者-消费者最小模型
// 3. packaged_task + future 取值
// 4. 异常通过 future 传播
// 5. 迷你池(桥接到 Task 3):把 1-4 组装为"1 个 worker 的最小池"
// ─────────────────────────────────────────────────────────────────────────────
// ── Exercise 1:cv.wait 的谓词写法 ────────────────────────────────────────────
//
// 要求:
// 1. 主线程创建 worker 线程,worker 通过 cv.wait(lock, pred) 等待 ready == true
// 2. 主线程休眠 100ms 后加锁设置 ready=true、value=42,然后 cv.notify_one()
// 3. worker 收到通知后打印 "worker awakened, value = 42"
//
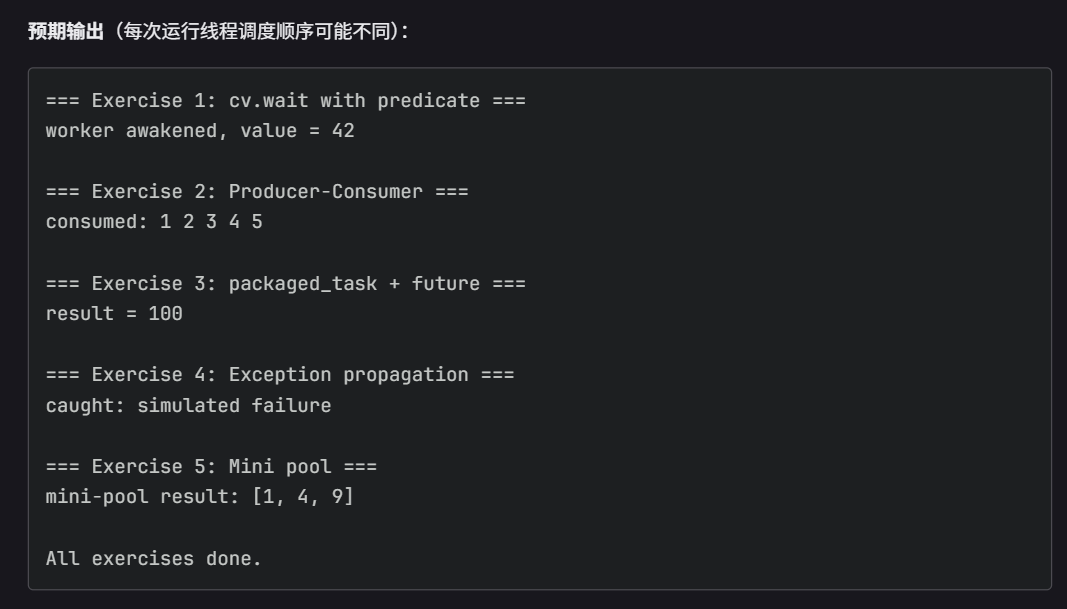
// 预期输出:
// === Exercise 1: cv.wait with predicate ===
// worker awakened, value = 42
void Exercise1() {
std::cout << "\n=== Exercise 1: cv.wait with predicate ===\n";
std::mutex mtx;
std::condition_variable cv;
bool ready = false;
int value = 0;
std::thread worker([&]{
std::unique_lock<std::mutex> lock(mtx);
// TODO: 使用带谓词的 cv.wait,等待 ready 变为 true
// cv.wait(lock, [&]{ return ready; });
// 然后打印 "worker awakened, value = " << value
cv.wait(lock, [&]{ return ready; });
std::cout << "worker awakened, value = " << value << "\n";
});
std::this_thread::sleep_for(std::chrono::milliseconds(100));
// TODO: 加锁 → 设置 ready=true, value=42 → 解锁 → cv.notify_one()
{
std::lock_guard<std::mutex> lock(mtx);
ready = true;
value = 42;
} // 先解锁再 notify,避免 worker 被唤醒后立刻重新阻塞在锁上
cv.notify_one();
worker.join();
}
// ── Exercise 2:生产者-消费者最小模型 ──────────────────────────────────────────
//
// 要求:
// 1. 一个生产者线程依次将 1..5 推入队列(每次 push 后 notify_one)
// 2. 一个消费者线程等待队列非空,出队并打印
// 3. 生产者生产完后,用一个 done 标志通知消费者退出
//
// 预期输出:
// === Exercise 2: Producer-Consumer ===
// consumed: 1 2 3 4 5
void Exercise2() {
std::cout << "\n=== Exercise 2: Producer-Consumer ===\n";
std::mutex mtx;
std::condition_variable cv;
std::queue<int> q;
bool done = false;
std::thread producer([&]{
for (int i = 1; i <= 5; ++i) {
// TODO: 加锁 → q.push(i) → 解锁 → cv.notify_one()
{
std::lock_guard<std::mutex> lock(mtx);
q.push(i);
}
cv.notify_one();
}
// TODO: 加锁 → done=true → 解锁 → cv.notify_all()
{
std::lock_guard<std::mutex> lock(mtx);
done = true;
}
cv.notify_all();// 告知消费者"不再有新数据"
});
std::thread consumer([&]{
std::cout << "consumed:";
while (true) {
std::unique_lock<std::mutex> lock(mtx);
// TODO: cv.wait(lock, [&]{ return !q.empty() || done; });
// TODO: 如果 q 空且 done 为 true,break
// TODO: 取出队头元素 v 并 pop,解锁后打印 " " << v
cv.wait(lock, [&]{ return !q.empty() || done; });
if (q.empty() && done)
break;// 队列空且生产结束,退出循环
int v = q.front();
q.pop();
lock.unlock();
std::cout << " " << v; // I/O 前先解锁,不占用锁做输出
// 占位 break,避免死循环;填好 TODO 后会被上面的逻辑覆盖
break;
}
std::cout << "\n";
});
producer.join();
consumer.join();
}
// ── Exercise 3:packaged_task + future 基础 ──────────────────────────────────
//
// 要求:
// 1. 用 std::packaged_task<int()> 包装一个返回 100 的 lambda
// 2. 从 task 取出 future
// 3. 在独立线程中执行 task
// 4. 主线程 fut.get() 并打印 "result = 100"
//
// 预期输出:
// === Exercise 3: packaged_task + future ===
// result = 100
void Exercise3() {
std::cout << "\n=== Exercise 3: packaged_task + future ===\n";
// TODO: std::packaged_task<int()> task([]{ return 100; });
// TODO: auto fut = task.get_future();
// TODO: std::thread t(std::move(task));
// t.join();
// TODO: std::cout << "result = " << fut.get() << "\n";
std::packaged_task<int()> task([]{ return 100; });
auto fut = task.get_future();
std::thread t(std::move(task));
t.join();
std::cout << "result = " << fut.get() << "\n";
}
// ── Exercise 4:异常通过 future 传播 ──────────────────────────────────────────
//
// 要求:
// 1. 用 std::async(std::launch::async, ...) 启动一个抛 std::runtime_error("simulated failure") 的任务
// 2. 主线程用 try/catch 包裹 fut.get(),捕获后打印 "caught: simulated failure"
//
// 预期输出:
// === Exercise 4: Exception propagation ===
// caught: simulated failure
void Exercise4() {
std::cout << "\n=== Exercise 4: Exception propagation ===\n";
// TODO: auto fut = std::async(std::launch::async, []() -> int {
// throw std::runtime_error("simulated failure");
// });
auto fut = std::async(std::launch::async, []() -> int {
throw std::runtime_error("simulated failure");
return 0;
});
// TODO: try { fut.get(); } catch (const std::exception& e) {
// std::cout << "caught: " << e.what() << "\n";
// }
try {
fut.get();
} catch (const std::exception& e) {
std::cout << "caught: " << e.what() << "\n";
}
}
// ── Exercise 5:迷你池(桥接到 Task 3 的 ThreadPool)──────────────────────────
//
// 目标:把前 4 题的元素组装为**只有 1 个 worker 的最小池**,它长什么样?
// - 一个队列:存 std::function<void()>
// - 一个 worker 线程:谓词 wait + 出队执行 + 关停时退出
// - 一个 Submit:用 packaged_task 包装 + 取 future + 入队 + notify_one
//
// 完成后你会意识到:Task 3 的 ThreadPool 无非是把"1 个 worker → N 个 worker"。
//
// 要求:
// 1. 提交 3 个计算任务:平方(1)、平方(2)、平方(3)
// 2. 依次 get() 结果,按 "mini-pool result: [1, 4, 9]" 格式输出
// 3. main 返回前 worker 正确停机(join 前记得 notify_all)
//
// 预期输出:
// === Exercise 5: Mini pool ===
// mini-pool result: [1, 4, 9]
void Exercise5() {
std::cout << "\n=== Exercise 5: Mini pool ===\n";
std::mutex mtx;
std::condition_variable cv;
std::queue<std::function<void()>> tasks;
bool stop = false;
// TODO 1: 启动一个 worker 线程,行为与 Task 3 的 WorkerLoop 一致(但只有 1 个)
// std::thread worker([&]{
// while (true) {
// std::function<void()> job;
// {
// std::unique_lock<std::mutex> lk(mtx);
// cv.wait(lk, [&]{ return stop || !tasks.empty(); });
// if (stop && tasks.empty()) return;
// job = std::move(tasks.front());
// tasks.pop();
// }
// job();
// }
// });
std::thread worker([&]{
while (true) {
std::function<void()> job;
{
std::unique_lock<std::mutex> lk(mtx);
cv.wait(lk, [&]{ return stop || !tasks.empty(); });
if (stop && tasks.empty()) return; // 停机且无剩余任务
job = std::move(tasks.front());
tasks.pop();
}
job(); // 锁外执行,不阻塞提交者
}
});
// TODO 2: 写一个本地 lambda submit(fn) -> future<int>,内部:
// - 用 shared_ptr<packaged_task<int()>> 包装 fn
// - 取出 future
// - 加锁入队 lambda [task]{ (*task)(); }
// - notify_one()
// - 返回 future
auto submit = [&](std::function<int()> fn) -> std::future<int> {
std::shared_ptr<std::packaged_task<int()>> task = std::make_shared<std::packaged_task<int()>>(fn);
std::future<int> fut = task->get_future();
{
std::lock_guard<std::mutex> lk(mtx);
tasks.push([task]{ (*task)(); }); // 入队一个无参 void 包装
}
cv.notify_one();
return fut;
};
// TODO 3: 提交三个任务:平方(1)、平方(2)、平方(3)
// 收集 future 到 vector,依次 get() 并打印:
// std::cout << "mini-pool result: [" << a << ", " << b << ", " << c << "]\n";
auto fut1 = submit([]() { return 1 * 1; });
auto fut2 = submit([]() { return 2 * 2; });
auto fut3 = submit([]() { return 3 * 3; });
std::cout << "mini-pool result: [" << fut1.get() << ", " << fut2.get() << ", " << fut3.get() << "]\n";
// TODO 4: 停机:加锁置 stop=true → notify_all → worker.join()
{
std::lock_guard<std::mutex> lk(mtx);
stop = true;
}
cv.notify_all();
worker.join();
}
int main() {
Exercise1();
Exercise2();
Exercise3();
Exercise4();
Exercise5();
std::cout << "\nAll exercises done.\n";
return 0;
}
3 解释
4 输出
cmake --build build --target week08_thread_pool_lab
./build/apps/week08_thread_pool_lab
输出没问题就提交一下
git add apps/week08/thread_pool_lab.cpp
git commit -m "feat: 完成线程池热身练习(含 Exercise 5 迷你池桥接)"
Task 3:实现 ThreadPool
1 要求
2 代码
#pragma once
#include <condition_variable>
#include <functional>
#include <future>
#include <memory>
#include <mutex>
#include <queue>
#include <stdexcept>
#include <thread>
#include <type_traits>
#include <utility>
#include <vector>
// ─────────────────────────────────────────────────────────────────────────────
// ThreadPool — 最小正确线程池
//
// 四件套:
// 1. 工作线程集合 workers_:固定数量,提前创建
// 2. 任务队列 tasks_:std::queue<std::function<void()>>
// 3. 同步原语 mtx_ + cv_:保护队列,唤醒 worker
// 4. 生命周期信号 stop_:配合析构函数实现优雅停机
//
// 骨架说明:
// - 数据成员与公开方法签名已固定,禁止修改
// - 在下方"实现区"的 TODO 中填写方法体
//
// 铁律:
// - 锁只保护队列操作,禁止持锁执行任务
// - 析构三部曲:置位 → notify_all → join,禁止持锁 join
// ─────────────────────────────────────────────────────────────────────────────
class ThreadPool {
public:
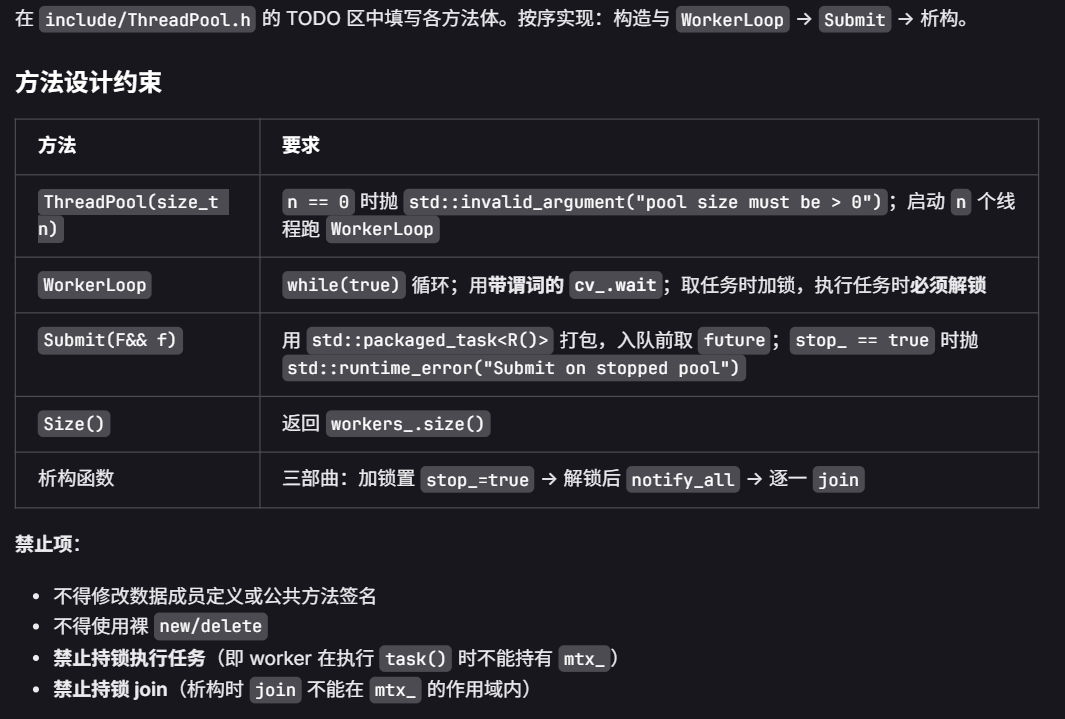
// 构造 n 个工作线程;n == 0 时抛 std::invalid_argument("pool size must be > 0")
explicit ThreadPool(std::size_t n);
// 析构:优雅停机(置位 + notify_all + join)
~ThreadPool();
// 禁止拷贝与移动(线程池管理独占的系统资源)
ThreadPool(const ThreadPool&) = delete;
ThreadPool& operator=(const ThreadPool&) = delete;
ThreadPool(ThreadPool&&) = delete;
ThreadPool& operator=(ThreadPool&&) = delete;
// 提交可调用对象 f,返回 future<R>(R = invoke_result_t<F>)
// 若线程池已停止,抛 std::runtime_error("Submit on stopped pool")
// 任务抛出的异常通过 future.get() 处重抛
template <class F>
auto Submit(F&& f) -> std::future<std::invoke_result_t<F>>;
// 返回线程池中工作线程的数量
std::size_t Size() const noexcept { return workers_.size(); }
private:
// 工作线程主循环
void WorkerLoop();
std::vector<std::thread> workers_;
std::queue<std::function<void()>> tasks_;
mutable std::mutex mtx_;
std::condition_variable cv_;
bool stop_ = false;
};
// ─────────────────────────────────────────────────────────────────────────────
// 实现区 — 在每个 TODO 中填入方法体,不得修改方法签名
// ─────────────────────────────────────────────────────────────────────────────
inline ThreadPool::ThreadPool(std::size_t n) {
// TODO:
// 1. 若 n == 0,抛 std::invalid_argument("pool size must be > 0")
// 2. 用 workers_.reserve(n) 预分配
// 3. 循环 n 次,用 workers_.emplace_back([this]{ WorkerLoop(); }) 启动线程
if (n == 0) {
throw std::invalid_argument("pool size must be > 0");
}
workers_.reserve(n);
for (std::size_t i = 0; i < n; ++i) {
workers_.emplace_back([this]{ WorkerLoop(); });
}
}
inline ThreadPool::~ThreadPool() {
// TODO(析构三部曲):
// 1. 加锁并置 stop_ = true(用 lock_guard 限定作用域,离开作用域自动解锁)
// 2. 解锁后调用 cv_.notify_all() 唤醒所有 worker
// 3. 遍历 workers_,对 joinable() 的线程逐一 join
//
// 注意:join 必须在 mutex 解锁之后!
// 错误示范:lock_guard g(mtx_); for (auto& t : workers_) t.join();
// → 死锁,worker 拿不到 mtx_ 退出不了
{
std::lock_guard<std::mutex> g(mtx_);
stop_ = true;
}
cv_.notify_all();
for (auto& t : workers_) {
if (t.joinable()) {
t.join();
}
}
}
inline void ThreadPool::WorkerLoop() {
// TODO(worker 主循环):
// while (true) {
// std::function<void()> task;
// {
// std::unique_lock<std::mutex> lock(mtx_);
// cv_.wait(lock, [&]{ return stop_ || !tasks_.empty(); });
// if (stop_ && tasks_.empty()) return;
// task = std::move(tasks_.front());
// tasks_.pop();
// } // 离开作用域时解锁
// task(); // !执行任务时不持有锁
// }
while (true) {
std::function<void()> task;
{
std::unique_lock<std::mutex> lock(mtx_);
cv_.wait(lock, [&]{ return stop_ || !tasks_.empty(); });
if (stop_ && tasks_.empty()) return; // 停机且无剩余任务,退出线程
task = std::move(tasks_.front());
tasks_.pop();
} // 离开作用域时解锁
task(); // !执行任务时不持有锁
}
}
template <class F>
auto ThreadPool::Submit(F&& f) -> std::future<std::invoke_result_t<F>> {
using R = std::invoke_result_t<F>;
// TODO:
// 1. 用 auto task = std::make_shared<std::packaged_task<R()>>(std::forward<F>(f));
// 包装任务——packaged_task 会自动把异常记录到关联的 future
// 2. 用 std::future<R> fut = task->get_future(); 取出 future
// 3. 加锁检查 stop_,若 true 则抛 std::runtime_error("Submit on stopped pool")
// 4. 将 [task]{ (*task)(); } 入队(注意:std::function 要求可拷贝,
// 而 packaged_task 不可拷贝,所以用 shared_ptr 包装)
// 5. 解锁后 cv_.notify_one() 唤醒一个 worker
// 6. 返回 fut
//
// 提示:这是本周最核心的一段代码,务必对照 PPT 的"任务提交"一页反复阅读
auto task = std::make_shared<std::packaged_task<R()>>(std::forward<F>(f));
std::future<R> fut = task->get_future();
{
std::lock_guard<std::mutex> lock(mtx_);
if (stop_) {
throw std::runtime_error("Submit on stopped pool");
}
tasks_.emplace([task]{ (*task)(); });
}
cv_.notify_one();
return fut; // TODO: 返回真正的 future
}
3 解释
4 输出
cmake --build build --target ThreadPoolTest
./build/tests/ThreadPoolTest

所有已有测试(建议 ≥ 10 个)须通过后,进入 Task 4。
git add include/ThreadPool.h
git commit -m "feat(threadpool): 实现ThreadPool"
MR1
git push -u origin lab/week08-threadpool
[Week08] 实现 ThreadPool + 热身练习
Task 4:TaskGraph::ExecuteOnPool
1 要求
2 代码
// ─────────────────────────────────────────────────────────────────────────────
// 【本周 TODO】ExecuteOnPool — 把任务提交到线程池
// ─────────────────────────────────────────────────────────────────────────────
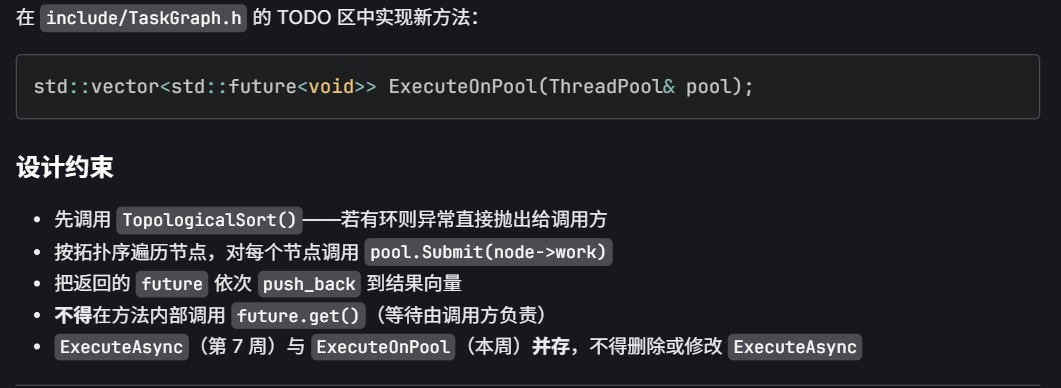
inline std::vector<std::future<void>> TaskGraph::ExecuteOnPool(ThreadPool& pool) {
// TODO:
// 1. 调用 TopologicalSort() 获得执行序 order(若有环会抛 runtime_error,直接上抛给调用方)
// 2. 对每个 id,调用 pool.Submit(nodes_.at(id)->work),把返回的 future 存入结果 vector
// 3. 注意:不要在方法内部调用 future.get(),由调用方负责等待
//
// 提示:pool.Submit(...) 返回 std::future<void>,可以直接 push_back
auto order = TopologicalSort();
std::vector<std::future<void>> futures;
futures.reserve(order.size());
for (int id : order) {
futures.push_back(pool.Submit(nodes_.at(id)->work));
}
return futures; // TODO: 返回真正的 futures
}
3 解释
4 输出
git checkout main
git checkout -b lab/week08-integration
git add include/TaskGraph.h
git commit -m "feat(taskgraph):实现 TaskGraph的ExecuteOnPool新方法 "
Task 5:调度策略(策略模式 × std::function)
1 要求

2 代码
#pragma once
#include <algorithm>
#include <functional>
#include <stdexcept>
#include <unordered_map>
#include <vector>
// ─────────────────────────────────────────────────────────────────────────────
// Scheduler — 任务调度策略(策略模式现代 C++ 写法)
//
// 核心思路:
// 用 std::function 替代继承体系持有"选哪个节点"的策略。
// 策略签名:int(const std::vector<int>&) ——
// 接受当前就绪节点 ID 列表,返回本轮应派发的节点 ID。
//
// 骨架说明:
// - PickFn 类型别名已固定,禁止修改
// - Scheduler 的数据成员已固定,禁止修改
// - 在下方每个 TODO 中填写方法体
//
// 铁律:
// - SetPolicy / Pick / MakeFIFO / MakePriority 共四处 TODO,逐一完成
// - 不得修改 PickFn 定义与 Scheduler 的 public 方法签名
// ─────────────────────────────────────────────────────────────────────────────
// 调度策略类型:接受就绪节点 ID 列表,返回选中的节点 ID
using PickFn = std::function<int(const std::vector<int>&)>;
class Scheduler {
public:
// 注入调度策略;若传入空 PickFn,Pick() 将回退到默认 FIFO 行为
void SetPolicy(PickFn f) {
// TODO: pick_ = std::move(f);
pick_ = std::move(f);
}
// 从就绪节点列表中按当前策略选出一个节点 ID
// - ready 为空时抛 std::runtime_error("no ready nodes")
// - 未调用 SetPolicy 或策略为空时,默认返回 ready.front()(FIFO)
// - 已设置策略时,调用 pick_(ready) 并返回其结果
int Pick(const std::vector<int>& ready) const {
// TODO
if (ready.empty()) {
throw std::runtime_error("no ready nodes");
}
if (!pick_)
return ready.front();
return pick_(ready);
}
// ── 内置策略工厂 ──────────────────────────────────────────────────────────
// MakeFIFO:始终取就绪列表的第一个(先入先出,与 Kahn 算法默认顺序一致)
static PickFn MakeFIFO() {
// TODO: 返回 [](const std::vector<int>& r){ return r.front(); }
return [](const std::vector<int>& r){
return r.front();
};
}
// MakePriority:按优先级表选取优先级最高(值最大)的节点 ID
// priority_map: 节点 ID → 优先级整数(未出现的 ID 优先级视为 0)
//
// 实现提示:
// return [pm = std::move(priority_map)](const std::vector<int>& r) {
// return *std::max_element(r.begin(), r.end(),
// [&](int a, int b) {
// auto get = [&](int id) {
// auto it = pm.find(id);
// return it != pm.end() ? it->second : 0;
// };
// return get(a) < get(b);
// });
// };
static PickFn MakePriority(std::unordered_map<int, int> priority_map) {
return [pm = std::move(priority_map)](const std::vector<int>& r) {
// max_element 以"优先级值"为比较键
return *std::max_element(r.begin(), r.end(),
[&](int a, int b) {
auto get = [&](int id) {
auto it = pm.find(id);
return it != pm.end() ? it->second : 0;
};
return get(a) < get(b); // a < b → a 优先级更低
});
};
}
private:
PickFn pick_;
};
3 解释
4 输出
验证
cmake --build build --target SchedulerTest
./build/tests/SchedulerTest
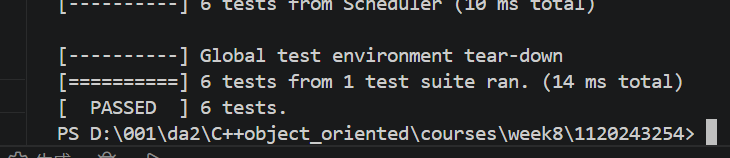
6 个基础测试全部通过后,继续完成 Task 6。
提交
git add include/Scheduler.h tests/SchedulerTest.cpp
git commit -m "feat: 实现 Scheduler 调度策略(FIFO + Priority)"
Task 6:端到端 demo + 测试通过
Step A:补充学生测试
代码
ThreadPoolTest.cpp
/ TODO: 在此追加至少 3 个学生测试
TEST(ThreadPool, StudentTest_ThousandIncrements) {
constexpr int kTasks = 1000;
ThreadPool pool(8);
std::atomic<int> counter{0};
std::vector<std::future<void>> futs;
for (int i = 0; i < kTasks; ++i) {
futs.push_back(pool.Submit([&]{
counter.fetch_add(1);
}));
}
for (auto& f : futs) f.get();
EXPECT_EQ(counter.load(), kTasks);
}
TEST(ThreadPool, StudentTest_MixedReturnTypes) {
ThreadPool pool(4);
auto f1 = pool.Submit([]{ return 10; });
auto f2 = pool.Submit([]{ return std::string("hello"); });
auto f3 = pool.Submit([]{});
EXPECT_EQ(f1.get(), 10);
EXPECT_EQ(f2.get(), "hello");
f3.get(); // void task
}
TEST(ThreadPool, StudentTest_HighThroughputManyShortTasks) {
constexpr int kTasks = 5000; // 压力更大一点
ThreadPool pool(8);
std::atomic<int> counter{0};
std::vector<std::future<void>> futs;
futs.reserve(kTasks);
for (int i = 0; i < kTasks; ++i) {
futs.emplace_back(pool.Submit([&]{
// 极短任务(几乎无计算)
counter.fetch_add(1, std::memory_order_relaxed);
}));
}
for (auto& f : futs) {
f.get();
}
EXPECT_EQ(counter.load(), kTasks);
}
SchedulerTest.cpp
// TODO: 在此追加至少 2 个学生测试
TEST(Scheduler, StudentTest_FIFOSingleElement) {
Scheduler sched;
sched.SetPolicy(Scheduler::MakeFIFO());
std::vector<int> ready = {42};
EXPECT_EQ(sched.Pick(ready), 42);
}
TEST(Scheduler, StudentTest_PickNoSideEffect) {
Scheduler sched;
sched.SetPolicy(Scheduler::MakeFIFO());
std::vector<int> r1 = {1, 2, 3};
std::vector<int> r2 = {4, 5};
EXPECT_EQ(sched.Pick(r1), 1);
EXPECT_EQ(sched.Pick(r2), 4); // 不应受上次调用影响
}
TaskGraphTest.cpp
// TODO: 追加学生测试
TEST(TaskGraph, StudentTest_ExecuteAsyncDiamondGraph) {
TaskGraph g;
std::atomic<int> count{0};
g.AddNode(1, "A", [&]{ count.fetch_add(1); });
g.AddNode(2, "B", [&]{ count.fetch_add(1); });
g.AddNode(3, "C", [&]{ count.fetch_add(1); });
g.AddNode(4, "D", [&]{ count.fetch_add(1); });
// diamond: 1→2, 1→3, 2→4, 3→4
g.AddEdge(1, 2);
g.AddEdge(1, 3);
g.AddEdge(2, 4);
g.AddEdge(3, 4);
auto futures = g.ExecuteAsync();
for (auto& f : futures) f.get();
EXPECT_EQ(count.load(), 4);
}
TEST(TaskGraph, StudentTest_ExecuteThrowsOnCycle) {
TaskGraph g;
g.AddNode(1, "A", [](){});
g.AddNode(2, "B", [](){});
g.AddEdge(1, 2);
g.AddEdge(2, 1); // cycle
EXPECT_THROW(g.Execute(), std::runtime_error);
}
测试
cmake --build build --target ThreadPoolTest
./build/tests/ThreadPoolTest
10+3=13
cmake --build build --target SchedulerTest
./build/tests/SchedulerTest
6+2=8
cmake --build build --target TaskGraphTest
./build/tests/TaskGraphTest
10+2=12
Step B:运行所有测试
cmake --build build
ctest --test-dir build --output-on-failure
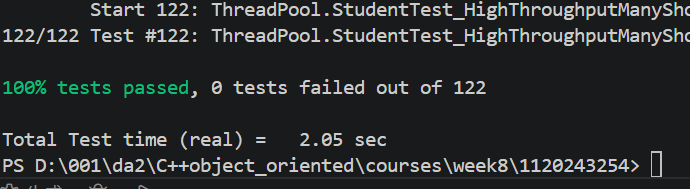
Step C:端到端 demo 行为验证
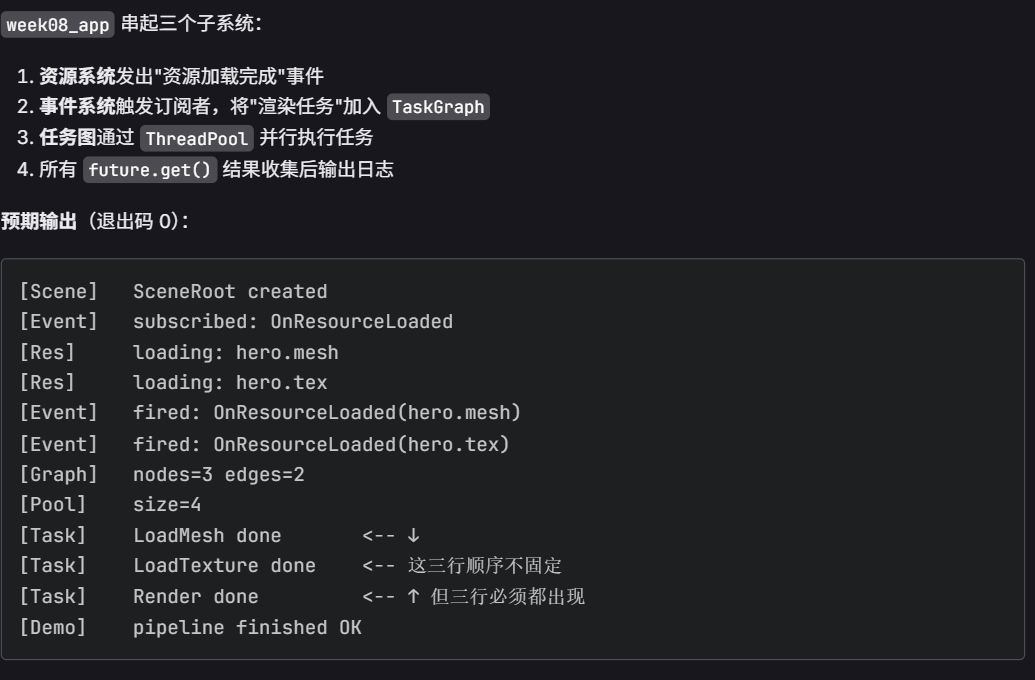
cmake --build build --target week08_app
./build/apps/week08_app
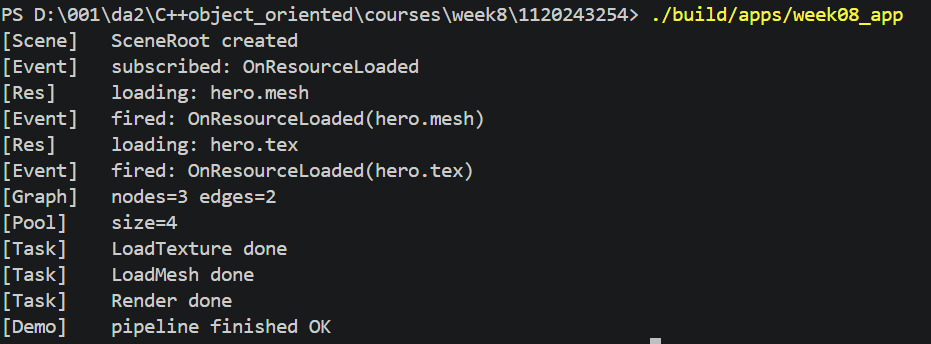
完成上面所有
git add include/ThreadPool.h include/TaskGraph.h \
include/Scheduler.h \
tests/ThreadPoolTest.cpp tests/SchedulerTest.cpp
git commit -m "feat: 实现 ThreadPool,接入 TaskGraph,调度策略,完成端到端 demo"
Task 7:课程收尾反思
课程收尾反思(必做,作为 Task 7 验收项之一)
本周是 8 周课程的最后一个实验。请在项目 README.md 末尾新增一节
课程收尾反思,回答以下两个问题(总计 ≤ 1 页):
范式选型回顾:demo 中哪些地方用了 OOP?哪些地方用了泛型?哪些地方用了函数式(Lambda / std::function / std::visit)?为什么?请引用你自己代码的文件:行号。
一个反例:如果让你用传统继承式 Visitor 重写 demo 中的某个分发点(例如事件订阅、任务提交),代码会膨胀多少?请贴出至少一个前后对比片段。
git add README.md
git commit -m "docs(readme): 补充课程收尾反思(Task 7 验收)"
MR2
git push -u origin lab/week08-integration
发起 MR 2,描述中附 ctest 总输出截图 + week08_app 输出截图。
[Week08] 接入 TaskGraph、调度策略、与端到端 demo

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 7
7 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)