大模型学习6-模型量化与推理部署
LLM中的量化技术
本部分将系统介绍如何通过模型量化(Quantization)技术压缩LLM。首先,从量化背景出发,说明当前模型压缩的现实需求;其次,概述深度学习中的通用量化原理;最后,结合LLM的特点,详解其专用的量化方法与工具链。
1.1 量化背景
深度学习模型的训练与推理主要包括前向计算、反向传播与参数更新三个阶段,本质上都属于大规模数值运算,其中以矩阵乘法和张量运算为主。这类运算具有高度并行性,对计算效率要求较高。相比而言,CPU虽然通用性强,但并行能力和内存带宽有限,难以高效处理大规模矩阵运算;而GPU采用大规模并行架构,尤其擅长执行矩阵乘法等高密度计算任务,因而成为当前深度学习的主流计算平台。
随着深度学习模型规模不断扩大,尤其是LLM参数量从7B、14B、34B增长至数百亿甚至更高,模型对显存容量和计算资源的需求急剧增加。由于LLM模型参数、激活值及中间结果均需占用显存,将完整模型加载至单张GPU上在实际中几乎不可行。即便是高端消费级GPU(如RTX 5090,约32GB显存)或数据中心级GPU(如H100,约80GB显存),在超大LLM模型面前仍存在明显瓶颈。虽然多GPU并行技术可以分担计算与存储压力,但会显著增加显存占用、通信开销和系统复杂度,甚至影响推理效率。因此,在有限算力和显存条件下,如何降低计算量和显存占用,同时尽量保持模型推理性能,已成为LLM训练与部署中的关键问题。
在这一背景下,数值表示格式的选择对LLM的计算效率和显存占用具有决定性影响。当前深度学习训练与推理中常用的浮点格式(如FP32、FP16、BF16)提供了大动态范围和高数值精度,但同时带来显著的存储与计算开销。相比之下,定点或低比特整数(如INT8、INT4)可大幅减少模型参数与中间激活的存储需求,从而缓解显存与算力瓶颈,但也会带来数值精度下降的问题。不同数值格式对比如下图所示,其中:
- 红色块(Sign):就1位,管数字是正还是负,
- 蓝色块(Exponent):管数字的大小范围,位数越多,能存的数的范围越大,
- 绿色块(Mantissa):管数字的精度细节,比如是存1.2还是1.2345,位数越多,数字的精度就越高,
- 黄色块(Regime,只在Posit16里有):类似Exponent的加强版,也是管数字的大小范围。

FP32凭借更多的指数位和尾数位兼顾了动态范围与精度,却带来了较高的存储和计算开销;FP16与BF16通过缩减位宽在效率与精度间实现折中,其中BF16会保留更多指数位,以此维持动态范围;INT8与INT4则几乎不单独表示指数部分,仅保留有限精度,适合对性能和存储开销敏感的推理场景;而Posit16通过Regime机制在有限比特下提供了一种更灵活的数值表示方案。下面的Python示例直观展示了不同数值格式在相同数组长度下的存储开销差异:
import numpy as np
import matplotlib.pyplot as plt
# -----------------------------
# 1️⃣ 定义数组长度
# -----------------------------
N = 1_000_000
# -----------------------------
# 2️⃣ 创建不同数值格式的数组
# -----------------------------
arr_fp32 = np.zeros(N, dtype=np.float32) # 32 位浮点
arr_fp16 = np.zeros(N, dtype=np.float16) # 16 位浮点
arr_bfloat16 = np.zeros(N, dtype=np.uint16) # 使用 uint16 存储 BF16
arr_int8 = np.zeros(N, dtype=np.int8) # 8 位整型
arr_int4 = np.zeros((N + 1) // 2, dtype=np.uint8) # 4 位整型打包存入 uint8
arr_posit16 = np.zeros(N, dtype=np.uint16) # 16 位 Posit 格式(此处为占位)
# -----------------------------
# 3️⃣ 计算存储大小(字节)
# -----------------------------
storage_bytes = {
'FP32': arr_fp32.nbytes,
'FP16': arr_fp16.nbytes,
'BF16': arr_bfloat16.nbytes,
'INT8': arr_int8.nbytes,
'INT4': arr_int4.nbytes,
'Posit16': arr_posit16.nbytes
}
# 转换为 MB
storage_mb = {k: v / (1024 ** 2) for k, v in storage_bytes.items()}
print("各数值格式存储大小(MB):")
for k, v in storage_mb.items():
print(f"{k}: {v:.2f} MB")
# -----------------------------
# 4️⃣ 绘制柱状图对比
# -----------------------------
plt.figure(figsize=(8, 5))
types = list(storage_mb.keys())
sizes = list(storage_mb.values())
bars = plt.bar(types, sizes, color=['red', 'blue', 'green', 'orange', 'purple', 'cyan'])
plt.ylabel("Storage Size (MB)")
plt.title(f"Storage Comparison of Different Numeric Formats (Array length={N})")
plt.grid(axis='y', linestyle='--', alpha=0.7)
# 在柱上方标注数值
for bar in bars:
yval = bar.get_height()
plt.text(bar.get_x() + bar.get_width() / 2, yval + 0.05, f"{yval:.2f}",
ha='center', va='bottom')
plt.show()
通常,模型训练阶段常采用较高精度(如FP32/BF16),而在推理阶段则可通过精度转换以提升效率。基于不同数值表示的特点,研究者提出了模型量化方法,即将模型中的高精度浮点数映射至低比特定点数或整数表示,在尽量保持模型性能的前提下,显著降低模型的存储需求与计算开销。量化不仅能减少模型参数与中间激活值所占用的显存,还可充分发挥GPU、TPU等硬件对低精度运算的加速能力,从而为资源受限环境下的模型部署提供有效支持。
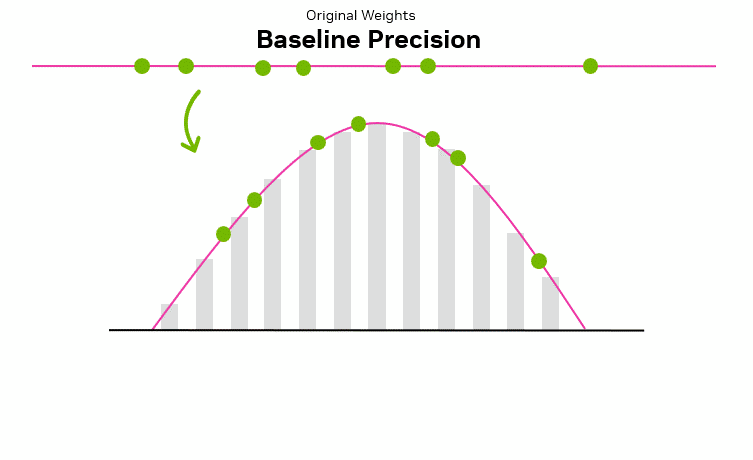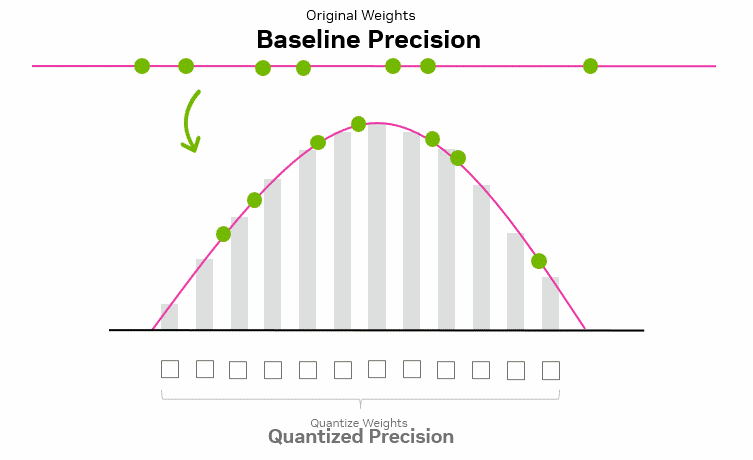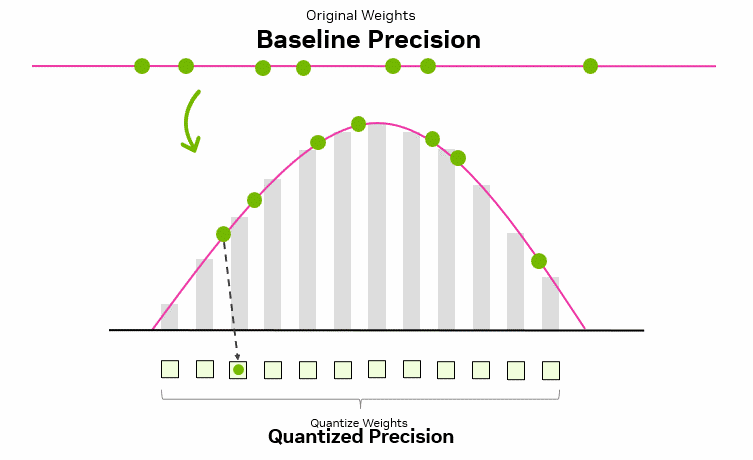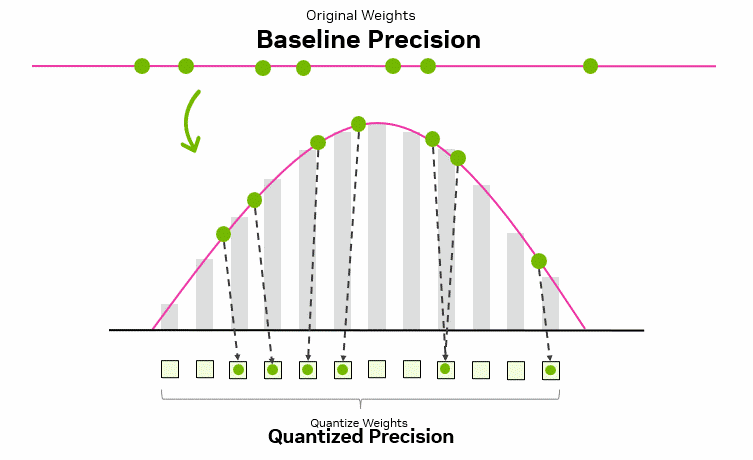
1.2 量化基本原理
1.2.1 核心思想
量化的核心思想可以概括为用更少的比特,在可接受的误差范围内近似表示原本的高精度浮点数值。一般是通过将高精度浮点数(如FP32)映射为低比特整数(如INT8/INT4)。类似于将高清图像转为缩略图:在保留整体结构的前提下丢失部分细节,从而提升处理与传输效率。关于量化更详细和更加生动可视化的介绍见:A Visual Guide to Quantization。
从工程实现角度看,量化方法通常分为线性量化和非线性量化:
- 线性量化Linear quantization(主流方案):将浮点数区间线性映射到固定的整数区间,计算简单、数值稳定,易于在现有CPU/GPU/NPU上高效实现,是当前训练后量化和推理部署中最常用的方法。
- 非线性量化Non-linear quantization:采用非线性映射或离散化策略(如对数量化、分段量化、k-means量化),在特定分布下可降低量化误差,但实现复杂、推理支持受限,工程落地成本较高。
常见的线性量化公式如下:
- 使浮点数零点与整数零点对齐,计算时先把原始数值按比例缩放,再四舍五入成整数,也就是对称量化:
�=round(��)
其中�是原始浮点值,�是缩放因子scale,�是量化后的整数。 - 当浮点数的取值全部为正时,若仍采用对称量化方式,整数表示范围内近一半的负数位将无法被利用,从而降低量化精度。为此,可通过引入零点,将浮点数的取值范围整体平移到整个整数区间上,以充分利用所有整数位来更好地保持精度,这种方法即非对称量化。后续将重点介绍非对称量化,对称量化仅需将零点设为0即可:
�=round(��)+�
其中�为零点(zero-point,整数),用于把浮点的零对齐到整数域的某个值,让浮点取值范围适配整数表示范围。 - 常见的反量化(把整数变回浮点):
�^=�⋅(�−�)
量化误差即 (� - �^),其来源于取整(round)操作以及可能的数值截断,这也是模型精度损失的主要来源。 - 计算缩放因子�和零点�:
- 目标整数范围:
通常设定为[�min,�max],8位有符号整数的标准范围是[−128,127],为了简化对称量化的处理,很多框架在对称量化时会把有效映射范围设为[−127,127],使得零点严格为0。8位无符号整数的标准范围则为[0,255]。 - 缩放因子:
�=�max−�min�max−�min
其中�min和�max指的是当前要量化的那一组具体浮点数数据的实际最大值、实际最小值。- 零点是浮点数0对应的量化后整数,计算时一般以原始浮点数的最小值�min和目标整数范围的最小值�min为基准:
�=�min−round(�min�)
其中�会被计算并存储为整数,以确保浮点零值�=0能够精确对应到整数�=�。 - 目标整数范围:
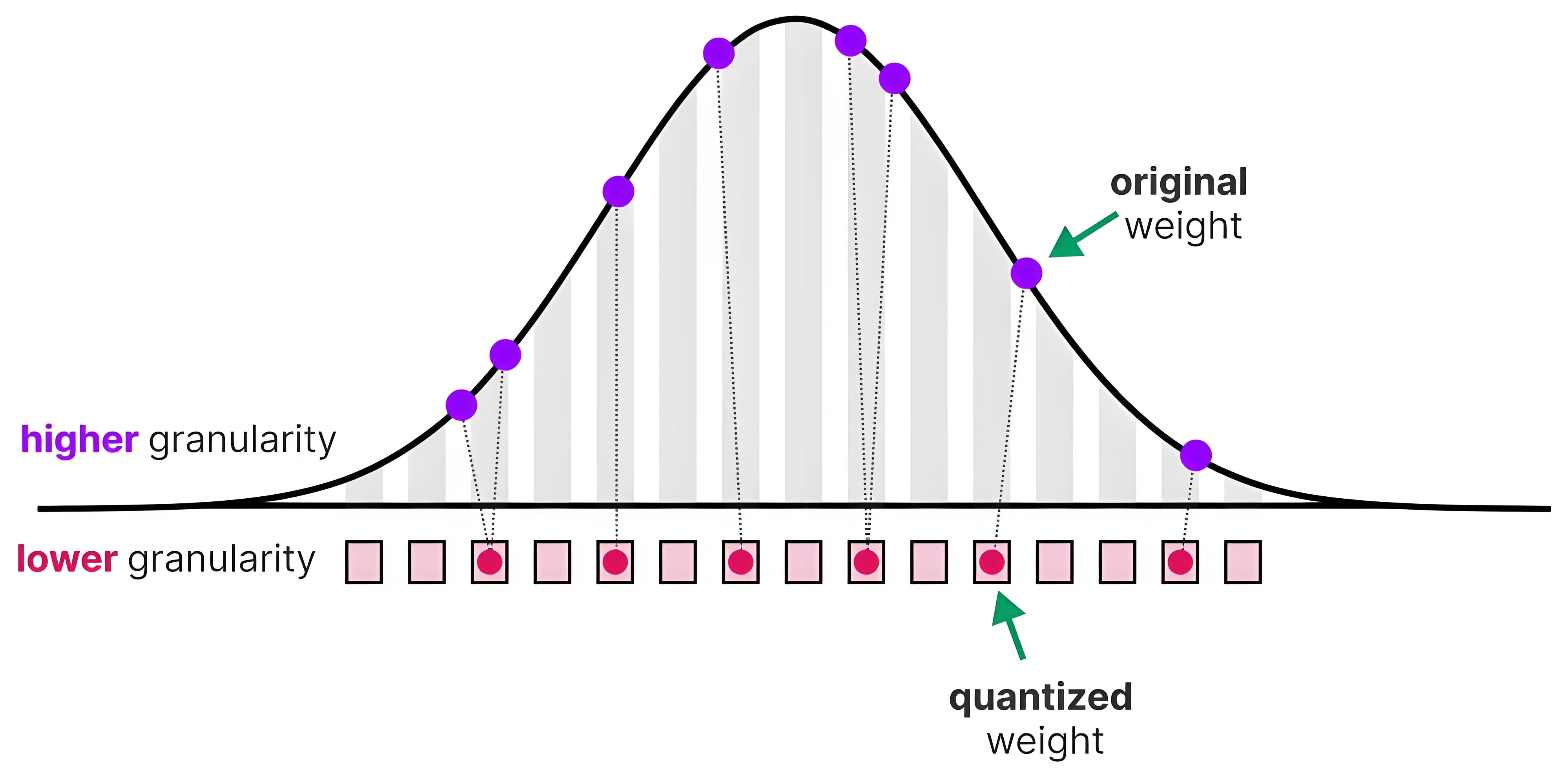
举例:假设权重的浮点取值范围为 ([-1.0, 0.9]),使用非对称量化,目标整数范围为 ([0, 255])。
- 计算缩放因子(scale)
整数范围整数范围�=max−min整数范围=0.9−(−1.0)255−0=1.9255≈0.00745
- 计算零点(zero-point)
�=round(−min�)=round(−−1.00.00745)≈134
- 量化权重
�=round(��)+�
对 w = 0.123:
�=round(0.1230.00745)+134≈round(16.5)+134=151
- 反量化回浮点
�^=(�−�)⋅�=(151−134)⋅0.00745≈17⋅0.00745≈0.1267
- 计算误差
�=�−�^=0.123−0.1267≈−0.0037
可以看到,非对称量化引入的误差仍然很小(约0.0037),并且零点的存在让浮点0能精确对应整数值,从而在推理中避免了偏移误差累积。在此基础上,为了进一步平衡计算效率与模型精度,还可以根据实际需求,将量化精细化为2比特(INT2)、4比特(INT4)以及8比特(INT8)等多种位宽类型。
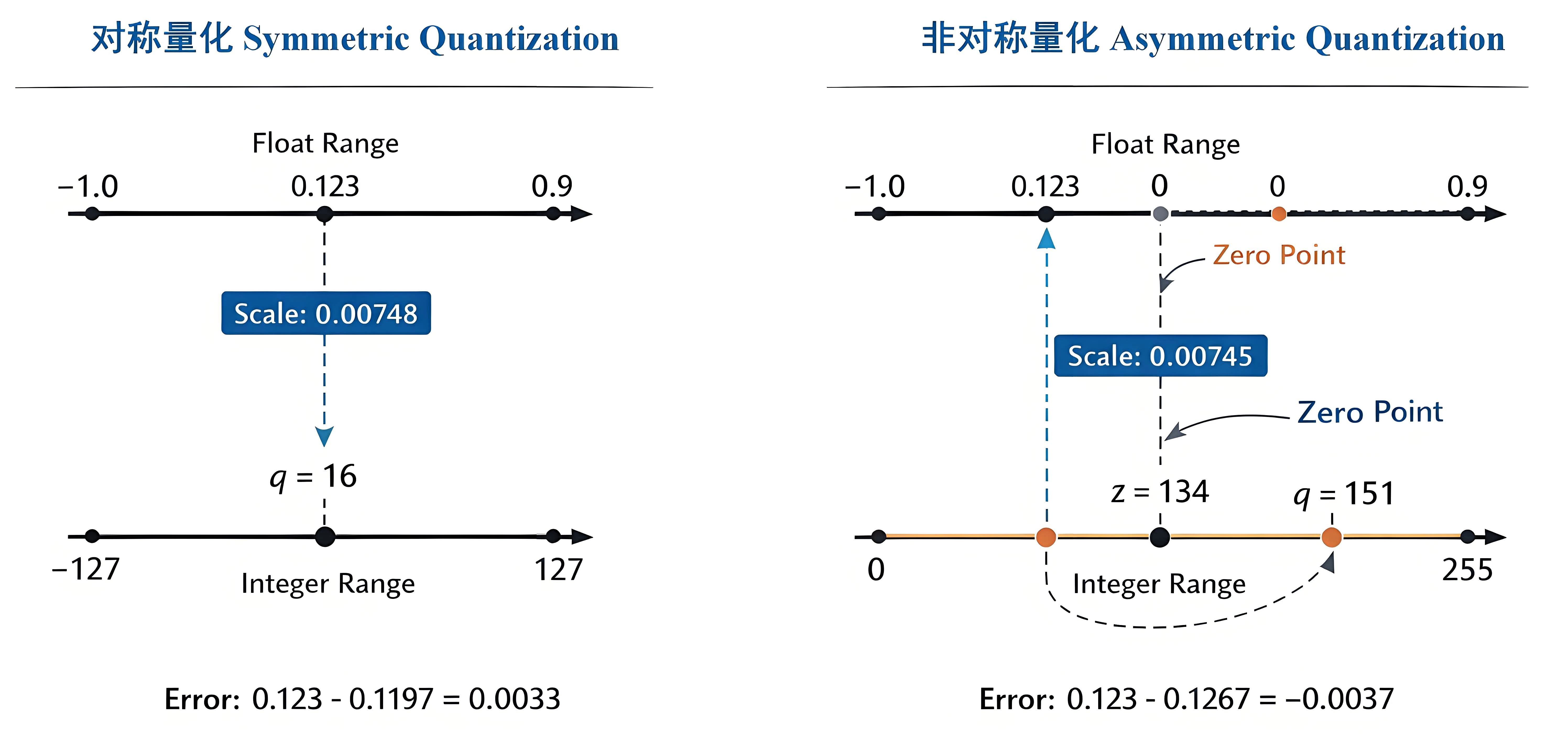
此外,还需理解量化粒度(granularity)的概念。它决定了权重或激活是以逐张量(per-tensor)、逐通道(per-channel)还是按组(per-group)为单位进行量化。粒度越细,量化参数越贴合数据分布,通常能提高精度,但也会增加存储与计算开销。
另一个相关概念是饱和量化(saturated quantization)与不饱和量化(non-saturated quantization)。饱和量化会裁剪分布两端的极端值,将更多的整数表示空间留给数据的主要分布区域,从而提升整体精度,但会损失极端值信息;不饱和量化则保留全部数据范围,但可能降低常用值的分辨率。
在实际部署中,为平衡精度与硬件效率,通常对权重采用逐通道量化(per-channel),对激活采用逐张量量化(per-tensor)。理解这些概念的基本作用即可,无需深入细节。
1.2.2 量化时机
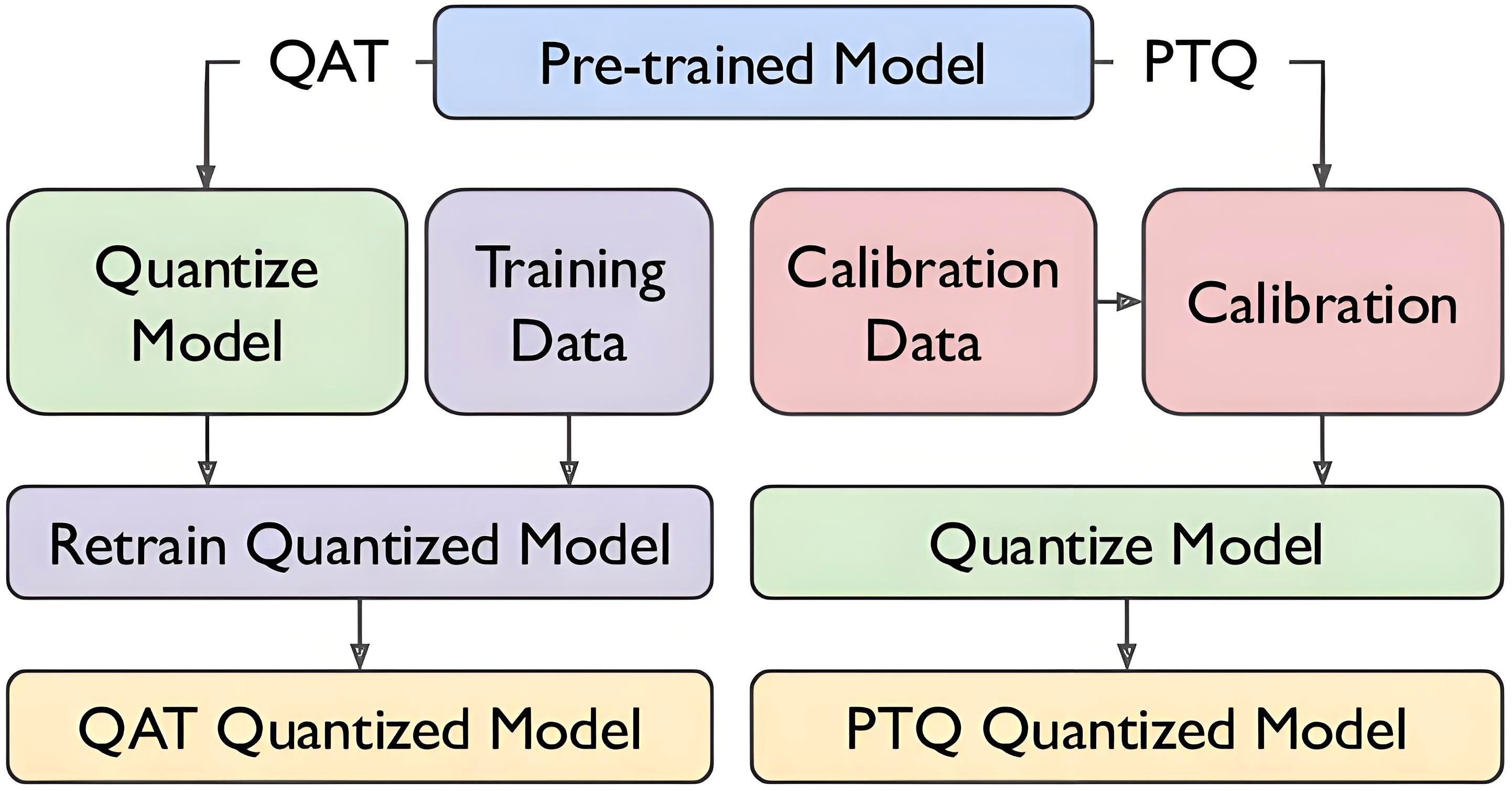
量化可以在不同阶段对模型进行操作,主要分为训练后量化和量化感知训练。
PTQ(Post-Training Quantization,训练后量化)
- 原理:PTQ是指在模型训练完成后,对权重或激活进行量化。可以理解为模型已经训练好了,然后再用更少的比特表示数据,以减少存储和计算成本。
- 特点:
- 优点:流程简单,通常不需要重新训练,或者只需极少量校准数据。
- 缺点:当量化位宽很低(如 4-bit、2-bit)或者模型本身对量化操作较为敏感时,模型的推理精度可能下降明显。
- 实现方式:
- Data-free(无数据校准)
- 方法:不依赖真实数据,只用一些基于权重的固有统计或假设就算出量化参数(scale/zero-point)。
- 优势:速度快,操作简单。
- 劣势:精度可能较低。
- Calibration(基于校准数据)
- 方法:使用少量代表性数据,通过统计方法(如 min/max、percentile、KL 散度等)计算最佳量化参数。
- 优势:精度更高,量化效果更稳定。
- 劣势:需要额外时间和数据样本。
- Data-free(无数据校准)
- 极简示例:
def post_training_quantize(model, bits=8):
"""
这是weight-only、per-layer、symmetric的int8量化
forward仍然使用 float(通过反量化后的权重)
"""
# int8 对称量化的整数范围
qmin = -(2 ** (bits - 1))
qmax = (2 ** (bits - 1)) - 1
for layer in model.layers:
# 仅对包含权重参数的层进行量化(如 Conv / Linear)
if hasattr(layer, 'weights'):
# 将权重展平成一维,便于统计最大绝对值
w = layer.weights.flatten()
# 使用权重的最大绝对值来确定量化scale
# 这是 PTQ 中常见的per-layer symmetric量化方法
max_abs = np.max(np.abs(w))
# 避免全0权重导致除零
if max_abs < 1e-8:
scale = 1.0
else:
# float_value ≈ int_value * scale
scale = max_abs / qmax
# ---------- 量化(float → int) ----------
# 将 float 权重映射到整数域
q = np.round(w / scale)
# 裁剪到 int8 可表示范围
q = np.clip(q, qmin, qmax).astype(np.int8)
# ---------- 反量化(int → float) ----------
# 用反量化后的 float 权重近似原始权重
w_hat = q.astype(np.float32) * scale
return model
QAT(Quantization-Aware Training,量化感知训练)
- 原理:QAT在训练过程中模拟量化影响,使模型在量化噪声中进行训练或微调,提前适应压缩,从而在低比特量化下仍保持高精度。
- 实现方式:
- 伪量化(fake-quant):在前向传播中模拟量化效果,让模型看到量化后的数据。
- 反向传播:把量化操作当作恒等映射(即假设它不改变数值)来传递梯度,从而正常更新浮点权重。
- 特点:
- 优点:在低比特量化下精度恢复明显,效果接近原始模型。
- 缺点:训练成本高,实现复杂,需要额外计算资源。
- 极简示例:
import torch
import torch.nn as nn
import torch.nn.functional as F
class QuantizedLinear(nn.Module):
def __init__(self, in_features, out_features, bits=8):
super().__init__()
# 浮点权重参数
self.weight = nn.Parameter(torch.randn(out_features, in_features))
self.bits = bits
# 量化比例(scale),在模型保存/加载时保持
self.register_buffer("scale", torch.tensor(1.0))
def quantize_weights(self, w):
"""
将浮点权重压缩到整数范围,再映射回浮点
"""
qmax = 2 ** (self.bits - 1) - 1 # 对称量化最大值
scale = w.abs().max() / qmax # 动态计算比例
q = torch.clamp(torch.round(w / scale), -qmax, qmax) # 整数化并限制范围
# STE:保持梯度流
w_quantized = (q * scale).detach() - w.detach() + w
return w_quantized, scale
def forward(self, x):
if self.training:
# 训练阶段
w_q, scale = self.quantize_weights(self.weight)
self.scale.copy_(scale) # 保存 scale
return F.linear(x, w_q)
else:
# 推理阶段:直接使用量化后的权重
qmax = 2 ** (self.bits - 1) - 1
q = torch.clamp(torch.round(self.weight / self.scale), -qmax, qmax)
return F.linear(x, q * self.scale)
实际部署首选PTQ量化,因为它简单高效,用少量数据校准就能让模型在8-bit下基本不掉精度;只有对超低精度(4-bit以下)或精度损失敏感的场景才用QAT,它通过训练让模型提前适应量化,但代价是重新训练成本高。
1.2.3 策略选型
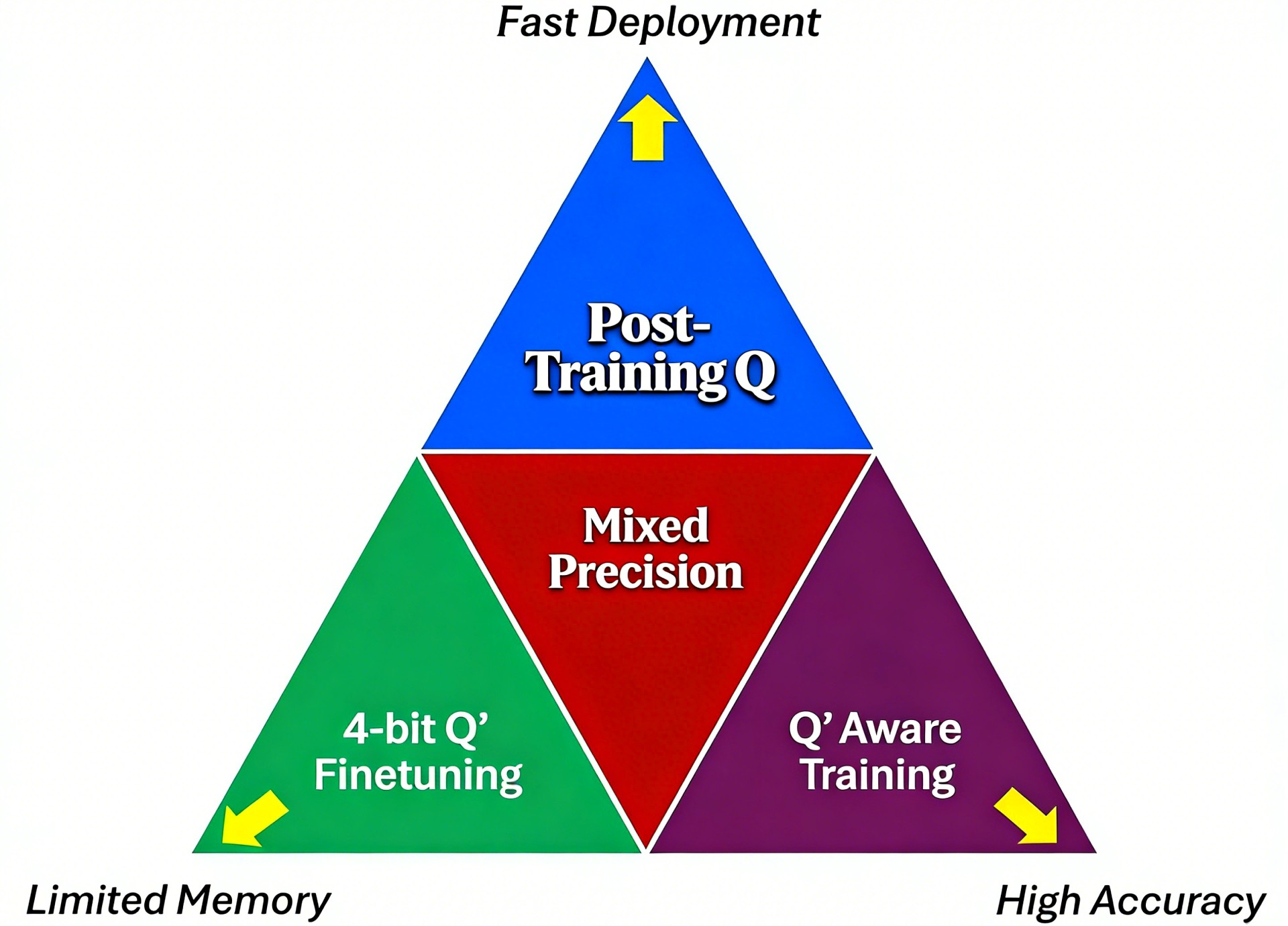
量化是在精度与效率间权衡的工程方法,关键在于理解缩放因子(scale)、零点(zeropoint)、量化粒度(逐张量/逐通道)和量化时机(PTQ/QAT)。通过有效的校准与工程实践,可在节省资源的同时控制精度损失。量化通常不会导致精度大幅下降,但无法完全无损。非线性量化在特定分布或极低位宽下或有优势,但往往牺牲硬件友好性。对于4bit及以下量化,常需配合剪枝、蒸馏或专门的QAT流程才能获得可用精度。关于这些技术的详细解析,可参考:一文详尽大型语言模型的四种量化技术。在工程实践中,量化策略的选择通常受具体约束条件影响,可总结如下:
| 首要约束 | 推荐技术 | 核心优势 | 潜在挑战 |
|---|---|---|---|
| 上线时间紧 | PTQ | 数小时内完成部署 | 极低比特(<4-bit)时精度崩塌 |
| 显存严重不足 | 4-bit Finetuning | 显存需求大幅度降低 | 需要一定的微调数据和时间 |
| 必须保证准确率 | QAT | 几乎无精度损失 | 训练开销极大,需大量数据 |
| 综合性能最优 | Mixed Precision | 硬件加速效果最好 | 实现逻辑相对复杂 |
提升量化效果可遵循以下要点:
- 从PTQ校准开始:用少量代表性数据校准模型,常可显著提高精度;
- 权重用逐通道,激活用逐张量:硬件支持时可对激活尝试逐通道;
- 敏感层或首尾层用混合精度:如保留首尾层为FP16/FP32;
- PTQ不足再做QAT:如精度不满足要求,QAT下微调通常可恢复大部分精度;
- 量化前做统计分析:依据权重与激活分布选择合适截断策略;
- 实测推理性能:需测端到端延迟并确认硬件支持整型运算。
1.3 量化算法在LLM中的实现与工具链
1.3.1 适用于LLM的量化方法
随着LLM的规模扩大,其参数量通常达到数十亿至上千亿级别。在这种规模下,传统量化方法面临以下挑战:
- 显存占用高:即使8-bit权重量化,部分模型仍难以在单GPU部署;
- 低位量化误差累积:4-bit或更低精度的量化中,误差在网络层间传播,显著影响生成质量;
- 激活分布不均:某些层如注意力矩阵或前馈网络激活值范围大,统一量化比例容易产生严重截断;
- 层间特性差异大:不同层对量化的敏感度不同,需要差异化策略。
因此,传统量化方法在LLM上的应用效果受限,亟需更为精细的量化方案。为应对上述挑战,业界与开源社区在传统量化方法的基础上,发展出多种适应LLM的量化技术,涵盖推理优化、低显存微调和激活量化等关键场景。以下内容基于开源社区采纳度、工程实践应用及相关文献引用情况进行梳理,旨在提供一份简要的技术概览,仅供参考:
GPTQ(流行的PTQ方法之一)
- 核心思路:对权重分组,逐组最小化量化误差,并进行局部调整
- 优点:4bit量化精度高、推理速度快、社区生态成熟
- 受欢迎程度:★★★★★
- 典型采用者:
- LLaMA 系列(社区量化版)
- Qwen3(社区量化)
- DeepSeek系列
BitsAndBytes(最常用的8bit/4bit加载方案)
- 核心思路:加载时直接转换为8bit或NF4权重格式,支持快速推理
- 优点:简单、兼容性强,HuggingFace默认支持
- 受欢迎程度:★★★★★
- 典型采用者:
- HuggingFace上几乎所有主流模型
- LLaMA、Qwen等
QLoRA(低显存微调方案)
- 核心思路:4bit权重+LoRA适配器微调
- 优点:显存占用极低,可微调百亿参数模型
- 受欢迎程度:★★★★★
- 典型采用者:
- 开源模型指令微调(LLaMA、Qwen等)
- 企业内部定制模型
GGUF(通用量化文件格式)
- 核心思路:统一量化模型存储格式,便于快速加载与推理
- 优点:兼容性强,简化工程化流程,可和GPTQ/BitsAndBytes/QLoRA等配合使用
- 受欢迎程度:★★★★★
- 典型采用者:
- 社区模型分发
- 工程化部署
KV-Cache量化
- 核心思路:量化KV缓存(Key-Value缓存)以降低推理显存占用
- 优点:显著降低LLM生成时的显存需求
- 受欢迎程度:★★★★☆
- 典型采用者:
- 低显存部署LLM
- 高速生成场景
AWQ(高质量 4bit 推理方案之一)
- 核心思路:保护重要通道,减少量化对敏感激活的影响
- 优点:4bit性能稳定,尤其适合指令微调模型
- 受欢迎程度:★★★★☆
- 典型采用者:
- Qwen2.5/Qwen3
- LLaMA3/LLaMA3.1
SmoothQuant(主流激活量化方法)
- 核心思路:平滑激活峰值,使权重和激活更易量化
- 优点:有效应对量化中精度与效率失衡的问题
- 受欢迎程度:★★★☆☆
- 典型采用者:
- 企业推理引擎
- 大规模在线服务
HQQ(快速工程化量化方案)
- 核心思路:快速优化算法,几乎无需校准数据
- 优点:量化速度极快,支持2bit/1bit
- 受欢迎程度:★★★☆☆
- 典型采用者:
- 边缘部署
- 需要快速量化的LLM模型
LLM-QAT(超低比特量化方案)
- 核心思路:训练中模拟量化,使模型适应低比特误差
- 优点:2bit 性能最佳
- 受欢迎程度:★★☆☆☆(研究或企业内部使用)
- 典型采用者:
- 企业内部模型(搜索、广告等)
- 边缘低比特部署模型

关于这些技术的详细介绍见:LLM Quantization Techniques和大模型量化技术解析和应用。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 16
16 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)