Agent 四大核心组件详解 + 通用架构图
Agent 的本质是以大语言模型(LLM)为核心大脑,通过四大核心组件的协同,实现「目标→规划→执行→反馈→优化」的自主闭环。你之前学的所有内容(CoT/ToT 思维链、反思机制、Prompt 工程、API 调用、多轮对话),都是这四大组件的底层技术支撑。
下面我会逐个拆解每个组件的定义、核心价值、技术实现、落地场景,完全贴合你的学习路径,最后给你可直接复用的通用架构图。
一、四大核心组件详解
1. 规划(Planning):Agent 的「大脑中枢」
核心定义
规划是 Agent 接收用户的模糊 / 复杂目标后,自动拆解任务、制定执行计划、动态调整策略的核心模块,解决大模型「一步错、步步错」的致命问题,让复杂目标可落地。
核心价值
普通大模型只能处理单轮、简单的指令,而 Agent 靠规划模块,能处理「帮我做一个完整的学生管理系统」这种多步骤、跨环节的复杂目标,无需人类逐步骤引导。
核心技术实现(完全对应你之前学的内容)
规划模块的技术,都是你已经学过的 Prompt 工程与推理框架,分为两大核心能力:
(1)目标拆解:把大目标拆成可执行的小步骤
- 基础方案:CoT 思维链,让 LLM 把大目标拆成连续的执行步骤
- 进阶方案:ToT 思维树,对复杂任务生成多个分支路径,评估后选最优路径
- 工业级方案:任务分解 Prompt,强制 LLM 按固定格式拆解任务,输出结构化的执行计划
(2)动态规划与反思:根据执行结果调整计划
- 核心框架:ReAct 框架(推理 + 行动),每执行一步就先思考「下一步该做什么」,再执行动作
- 纠错能力:反思机制(Reflection),执行失败后自动复盘问题、修正计划、重新执行
- 行业方案:Reflexion、RAP 等进阶反思框架,提升复杂任务的完成率
典型示例
用户目标:「帮我做一个学生成绩数据分析报告」规划模块的输出:
- 读取本地的 students.csv 文件,检查数据完整性
- 处理缺失值、异常值,清洗数据
- 执行描述性统计(平均分、最高分、最低分、及格率)
- 按班级、性别分组分析成绩差异
- 生成可视化图表(直方图、箱线图)
- 撰写完整的数据分析报告,输出 markdown 文件
2. 记忆(Memory):Agent 的「知识库 + 日记本」
核心定义
记忆是 Agent 负责存储、检索、管理全生命周期信息的模块,解决大模型「上下文窗口有限、跨会话失忆、无法积累经验」的问题,让 Agent 越用越贴合你的需求。
核心价值
普通大模型的记忆仅限于当前会话的上下文,对话结束就重置;而 Agent 的记忆模块,能长期存储你的偏好、历史任务经验、外部知识库,实现跨会话、跨任务的信息复用。
核心分类与技术实现(对应你学过的上下文管理、嵌入接口)
行业内通用的记忆分层,完全匹配你的学习内容:
表格
| 记忆类型 | 核心定义 | 存储载体 | 对应你学过的技术 | 典型用途 |
|---|---|---|---|---|
| 短时记忆(工作记忆) | 存储当前任务的对话历史、执行步骤、中间结果,生命周期仅限当前任务会话 | 内存、会话上下文列表 | 多轮对话的 messages 列表、上下文管理 Prompt | 记住当前任务的执行进度、用户的实时指令 |
| 长时记忆(永久记忆) | 存储用户长期偏好、历史任务经验、外部知识库,生命周期永久 | 向量数据库(Chroma/Pinecone)、本地文件、数据库 | 文本嵌入接口、RAG 检索、Prompt 库 | 记住你的代码风格、学习进度、常用技术栈、私人知识库 |
核心操作
- 存储:把用户输入、执行结果、反思内容,转成嵌入向量,存入向量数据库
- 检索:执行新任务时,自动检索相关的历史信息、知识库内容,注入到 LLM 上下文
- 遗忘机制:自动过滤无效信息、压缩冗余内容,避免上下文窗口爆炸
典型示例
你之前让 Agent 写过 FastAPI 代码,指定了「代码要符合 PEP8 规范、带完整异常处理、中文注释」,记忆模块会把这个偏好永久存储。下次你再让它写代码时,会自动检索这个偏好,直接生成符合你要求的代码,无需你重复说明。
3. 工具调用(Tool Use):Agent 的「手脚与感官」
核心定义
工具调用是 Agent 突破大模型能力边界,调用外部系统、API、函数、软件来完成大模型本身做不到的事的核心模块,解决大模型「知识截止、无法获取实时信息、无法执行物理操作、无法对接外部系统」的问题。
核心价值
普通大模型只能输出文本,无法和外部世界交互;而 Agent 靠工具调用,能实现搜索、代码执行、文件读写、API 对接、数据库操作等能力,把文本输出变成真实的动作。
核心执行流程(对应你学过的 API 调用、函数调用)
- 工具定义:提前给 LLM 声明工具的名称、功能、入参出参规范(比如「天气查询工具,入参是城市名,出参是实时天气数据」)
- 工具选择:LLM 自主判断「当前步骤是否需要用工具、用哪个工具、需要传入什么参数」
- 工具执行:Agent 调用对应的 API / 函数,执行工具,获取返回结果
- 结果处理:把工具返回的结果整理后,注入到 LLM 上下文,继续后续规划
常用工具分类(你可以直接对接使用)
表格
| 工具类型 | 典型示例 | 核心用途 |
|---|---|---|
| 信息检索类 | 搜索引擎(Serper / 百度搜索)、RAG 知识库检索 | 获取实时信息、专业知识,解决大模型知识截止问题 |
| 代码执行类 | PythonREPL、Jupyter 内核、代码沙箱 | 执行代码、测试代码、数据分析、数学计算 |
| 系统交互类 | 文件读写、终端命令执行、操作系统接口 | 操作本地文件、安装依赖、启动服务 |
| API 对接类 | 天气 / 股票 API、飞书 / 企业微信 API、FastAPI 自定义接口 | 对接第三方服务、自动化办公 |
| 数据库类 | MySQL、Redis、PostgreSQL 连接器 | 读写数据库、数据处理 |
典型示例
用户问:「今天北京朝阳的天气怎么样?适合出门吗?」
- LLM 判断:需要调用「天气查询工具」,入参是「北京朝阳」
- Agent 调用天气 API,获取实时数据:「晴,22℃,风力 2 级,空气质量优,非常适合出门」
- LLM 把结果整理成自然语言,返回给用户
4. 行动(Action / 执行):Agent 的「落地执行器」
核心定义
行动是 Agent 把规划的步骤、工具调用的能力,落地成具体动作、完成闭环执行、校验结果、反馈迭代的核心模块,是 Agent 和普通大模型最核心的区别 —— 普通大模型只输出「想法」,而 Agent 靠行动模块输出「结果」。
核心价值
规划模块只制定了「要做什么」,而行动模块负责「真的去做」,同时完成「执行→校验→反馈→优化」的闭环,无需人类干预就能完成整个任务。
核心执行流程(对应你学过的反思机制、自我纠错)
- 动作执行:严格按照规划模块的步骤,调用对应的工具,完成具体动作
- 结果校验:自动检查执行是否成功、是否达到预期目标(比如代码是否能运行、接口是否能正常访问)
- 反馈迭代:把执行结果反馈给规划模块和记忆模块 —— 执行成功就进入下一步;执行失败就触发反思机制,定位问题、修正计划、重新执行
- 终止判断:自动判断用户的最终目标是否完成,完成就终止任务,给用户交付最终结果
典型示例
规划模块制定了「写 FastAPI 学生管理接口→启动服务→测试接口」的步骤:
- 行动模块先调用代码生成工具,写出接口代码,保存到本地文件
- 校验代码语法是否正确,有没有语法错误
- 调用终端工具,安装依赖,启动 FastAPI 服务
- 校验服务是否正常启动,端口是否可用
- 调用接口测试工具,发送 POST/GET 请求,校验接口是否正常返回
- 所有步骤都成功,就给用户交付「代码文件 + 访问地址 + 测试报告」;如果启动失败,就把报错信息反馈给规划模块,重新修改代码,再执行
二、四大组件的协同闭环:Agent 完整执行流程
四大组件不是孤立的,而是围绕 LLM 核心大脑,形成完整的执行闭环,这就是 Agent 工作的完整流程:
- 目标输入:用户给 Agent 一个最终目标
- 记忆检索:记忆模块检索和目标相关的历史信息、知识库内容,注入 LLM 上下文
- 规划拆解:规划模块把目标拆解成可执行的步骤,制定执行计划
- 行动执行:行动模块按照计划,调用对应的工具,执行具体动作
- 结果校验:行动模块校验执行结果,判断是否成功
- 反馈迭代:执行成功就进入下一步;执行失败就触发反思,修正计划后重新执行
- 记忆存储:把本次任务的执行过程、结果、经验,存入记忆模块
- 结果交付:所有步骤完成后,给用户交付最终结果
三、Agent 通用架构图
我给你两个版本:文本极简版(一眼看懂核心结构) + Mermaid 可运行版(复制就能生成高清架构图)
1. 文本极简版架构图
plaintext
┌─────────────────────────────────────────────────────────────────┐
│ 用户(目标输入/结果接收) │
└───────────────────────────────┬─────────────────────────────────┘
│
┌───────────────────────────────▼─────────────────────────────────┐
│ 大语言模型 LLM(核心大脑) │
│ (负责逻辑推理、指令理解、工具选择、反思优化、内容生成) │
└───┬───────────────┬───────────────┬───────────────┬────────────┘
│ │ │ │
┌───▼───┐ ┌───▼───┐ ┌───▼───┐ ┌───▼───┐
│ 规划 │ │ 记忆 │ │工具调用│ │ 行动 │
│Planning│ │Memory │ │Tool Use│ │Action │
└───┬───┘ └───┬───┘ └───┬───┘ └───┬───┘
│ │ │ │
└───────────────┼───────────────┼───────────────┘
│ │
┌─────▼─────┐ ┌─────▼─────┐
│ 向量数据库 │ │ 外部工具/API │
└───────────┘ └─────────────┘2. Mermaid 可运行高清架构图
你可以把下面的代码复制到 Mermaid 在线编辑器、语雀、飞书文档里,直接生成高清的架构图,支持自定义修改。
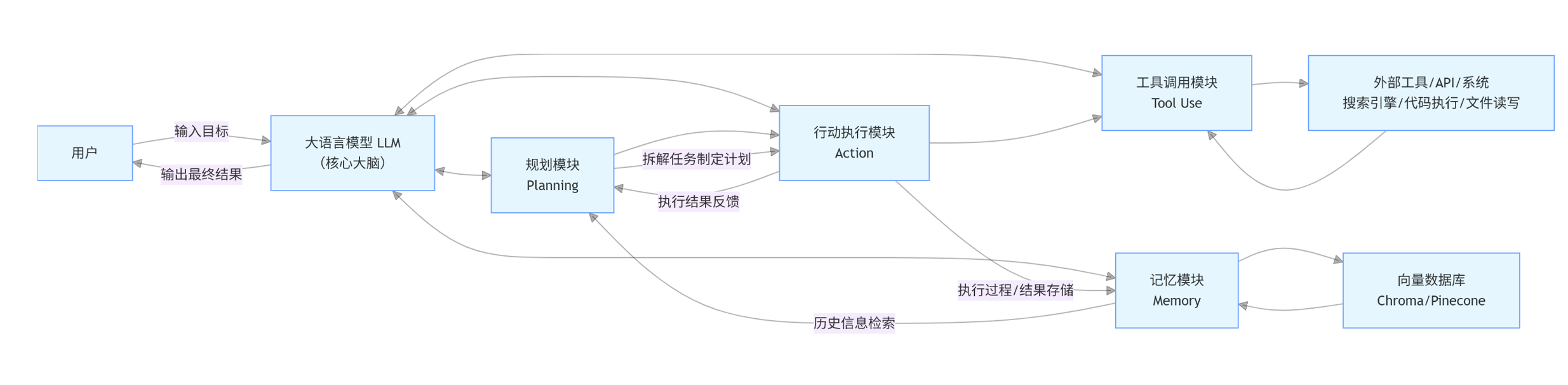
生成后的架构图,会清晰展示四大组件的位置、协同关系、底层支撑,完全符合工业级 Agent 的通用架构。
四、总结
- 四大组件的本质分工:规划模块决定「做什么」,行动模块决定「怎么做」,工具调用模块提供「能力支撑」,记忆模块提供「经验支撑」,四者围绕 LLM 大脑形成完整的自主闭环。
- 和普通大模型的核心区别:普通大模型只有 LLM 本身,只能被动问答;而 Agent 靠四大组件,能主动完成复杂任务,实现从「问答工具」到「执行助手」的跨越。
- 你的学习路径衔接:你之前学的 CoT/ToT、反思机制、Prompt 工程、API 调用、上下文管理,都是这四大组件的底层技术,现在你已经具备了从零搭建一个完整 Agent 的全部基础。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 11
11 0
0- 0



 已为社区贡献14条内容
已为社区贡献14条内容

所有评论(0)