别卷了,DeepSeek V4 来交卷了
别卷了,DeepSeek V4 来交卷了
最近这一周,我的状态基本上就是:早上起来装一个模型,中午吃饭测一个模型,晚上睡觉前又发一个模型。
昨天最离谱。下午刚跑完 MiMo 的测试,代码还没关,字节的 HY3 就发了。紧赶慢赶把测评写完,凌晨 GPT-5.5 又砸过来了。我寻思这下总能睡了吧,结果今天早上闹钟还没响,DeepSeek V4 的发布公告直接把我炸醒了。
我现在打开 GitHub 的姿势,你感受一下:
这波模型大战的密度,我已经记不清上一次是什么时候了。一周七个,一天四个,大厂们跟商量好了似的集体秀肌肉。
先聊个被很多人问的问题:R2 去哪了?
简单说两句,不然评论区又要被刷屏。
去年 DeepSeek 的产品线是分开的:V3 干通用的活,R1 专门搞推理。到了今年,Claude、GPT 这些头部玩家全都在搞“混合模型”——就是一个模型,你让它多想一会儿它就多想一会儿,不想多想的场景它就秒回。不再分两个产品了。
DeepSeek 从 V3.1 开始也走了这条路,V4 当然也是混合架构。所以 R2 这个代号,大概率就这么退休了。就像 OpenAI 的 o3,也成了最后一代独立推理模型,直接被吞进了 GPT-5。
这个行业正在统一:推理能力不再是独立产品的卖点,而是基础模型的标配开关。
跑分到底怎么样?我帮你捋一下
官方放了不少数据,我一个个点开看了。先说结论:有惊喜,但不炸裂。
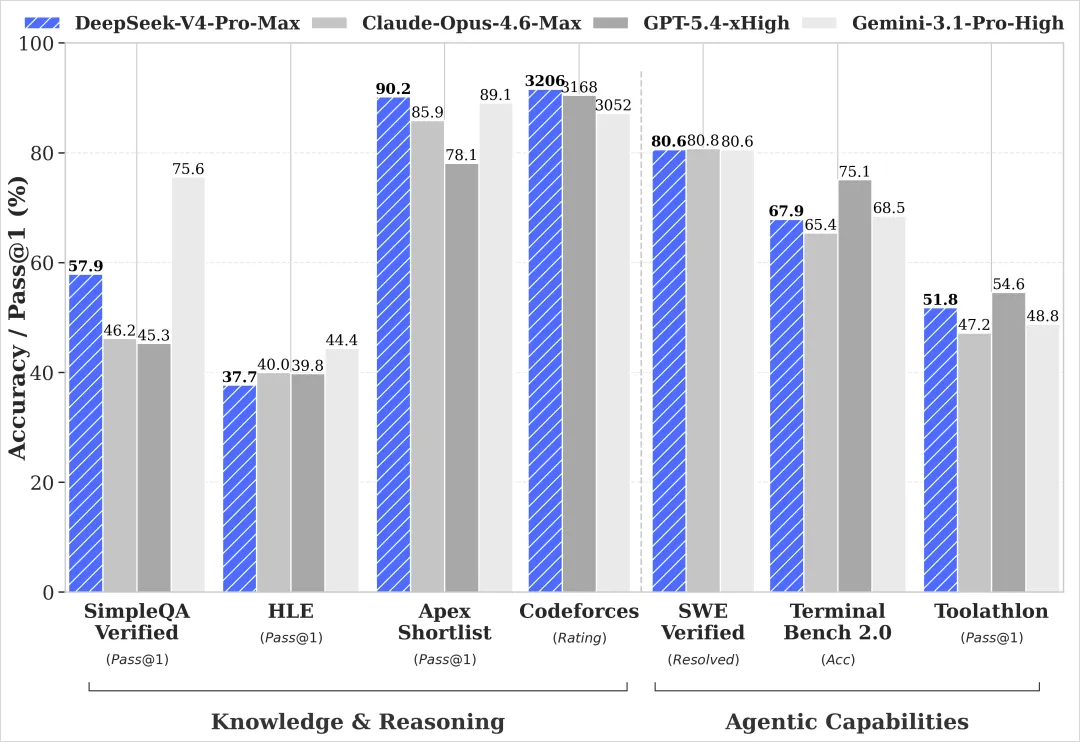
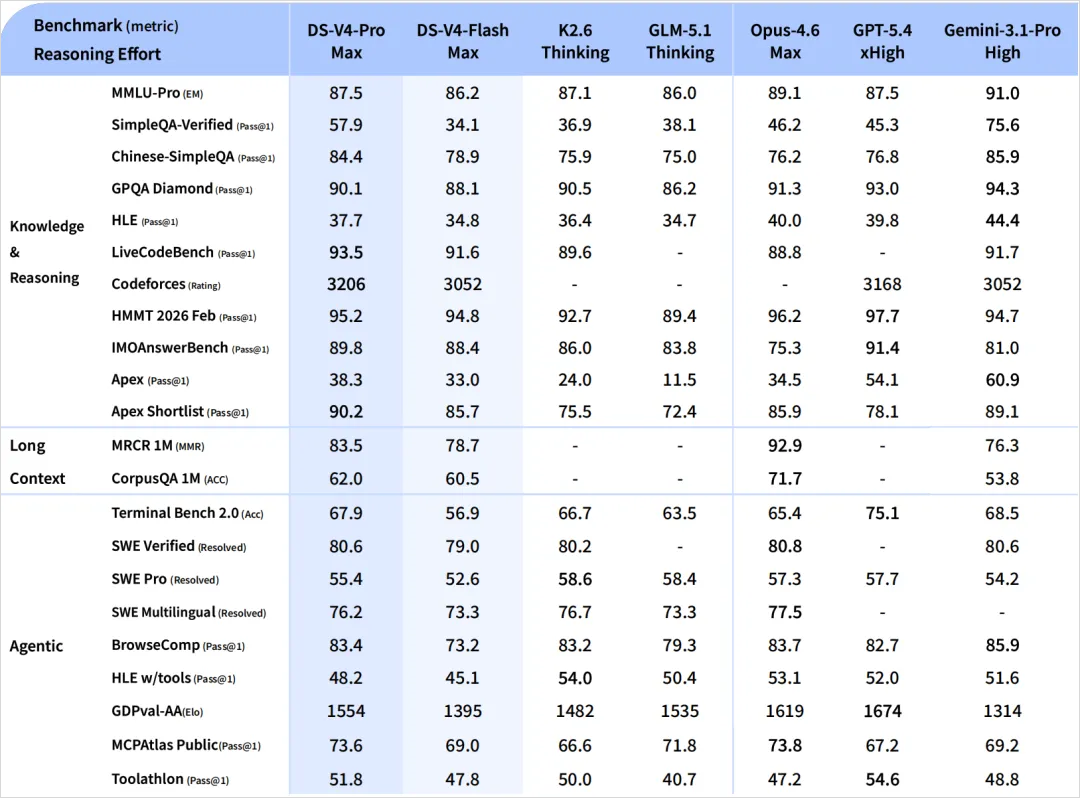
我先拉了一张知识推理类的对比表,把最近几个主力模型放在一起看了下。表格数据来源各家的技术报告,口径不一定完全一致,看个大概趋势就行。
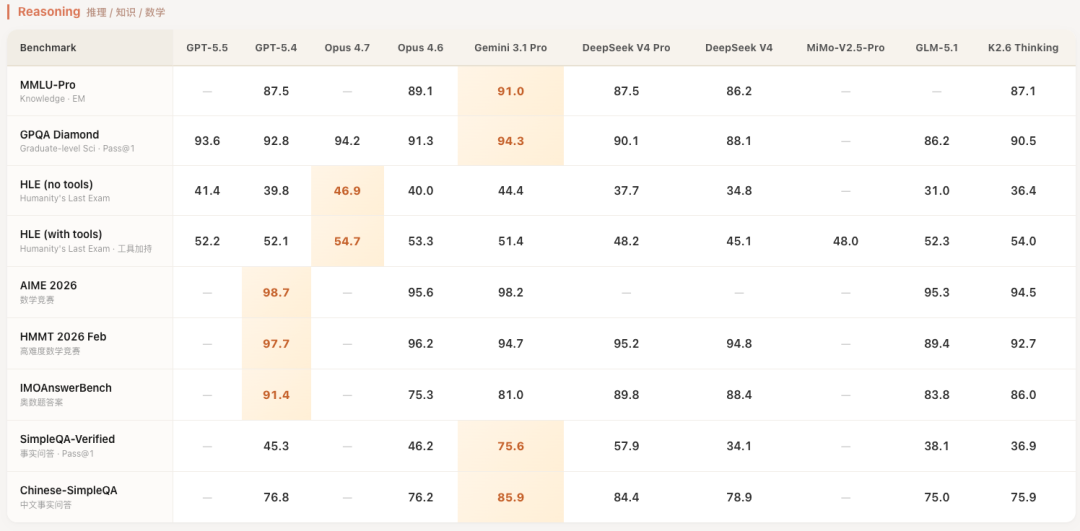
DeepSeek V4 最拿得出手的是 SimpleQA 这类知识型测试,跟 Gemini 3.1 Pro 咬得很紧,在开源圈属于断档领先。其他几项就比较中规中矩,第一梯队是稳的,但没有拉开明显差距。
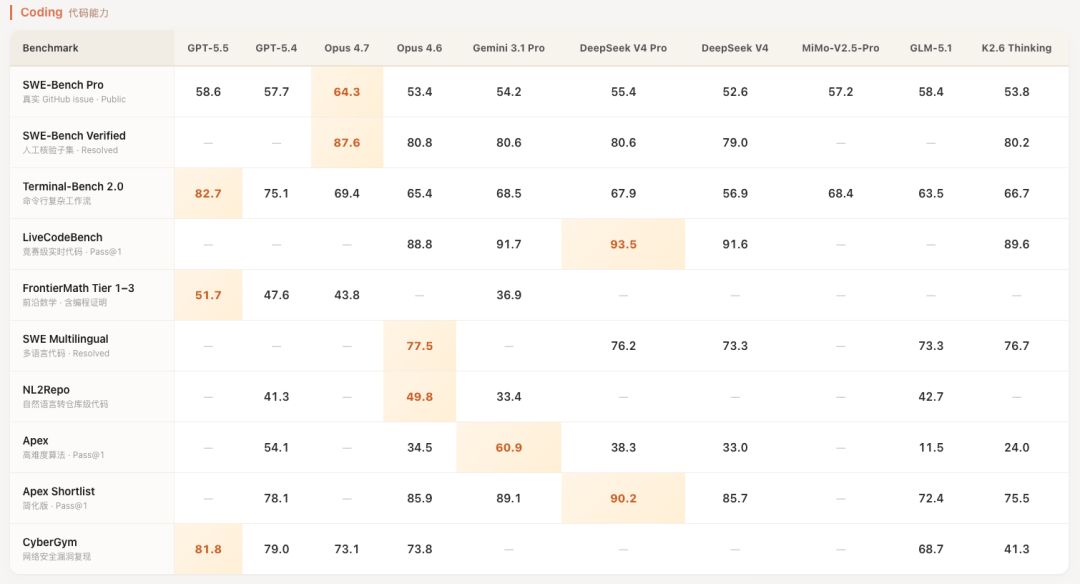
代码这块更有意思。分数上看,算法竞赛类的表现非常抢眼,Codeforces 拿了 3206 分,把 GPT-5.4 都踩下去了。但一到真实工程能力的测试,比如 SWE Verified 这种模拟改 Bug、重构代码的场景,分数就跟顶级闭源模型贴得很近,属于第一梯队但不是压倒性优势。
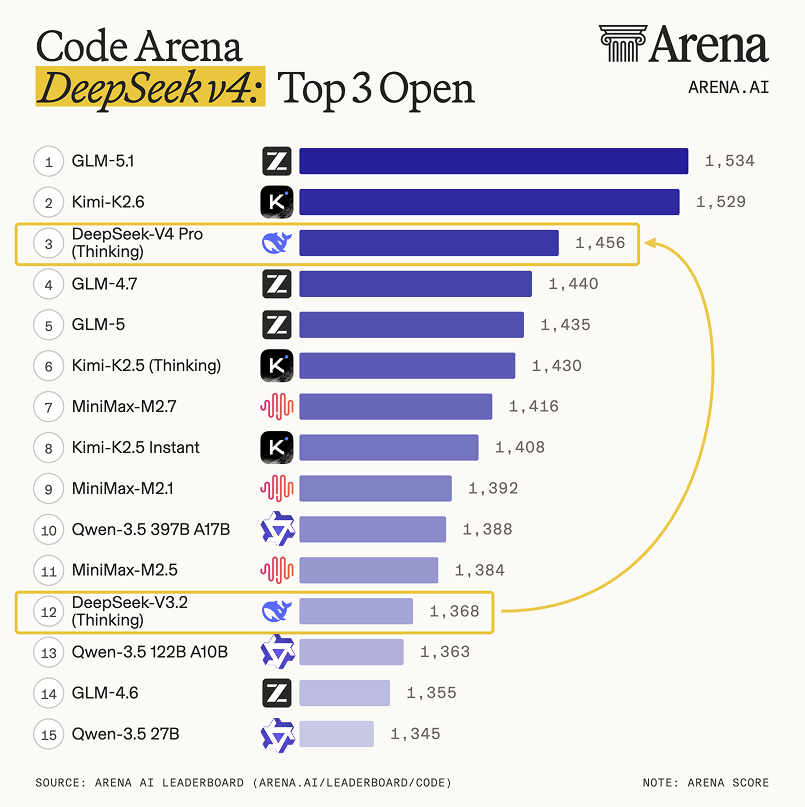
我顺便截了一张 Arena 的最新排名。DeepSeek V4 目前排第三,压在前面的是 GLM-5.1 和还没完全开源的 MiMo。这个榜单变化很快,今天你是第三,明天可能就第五了,且看且珍惜。
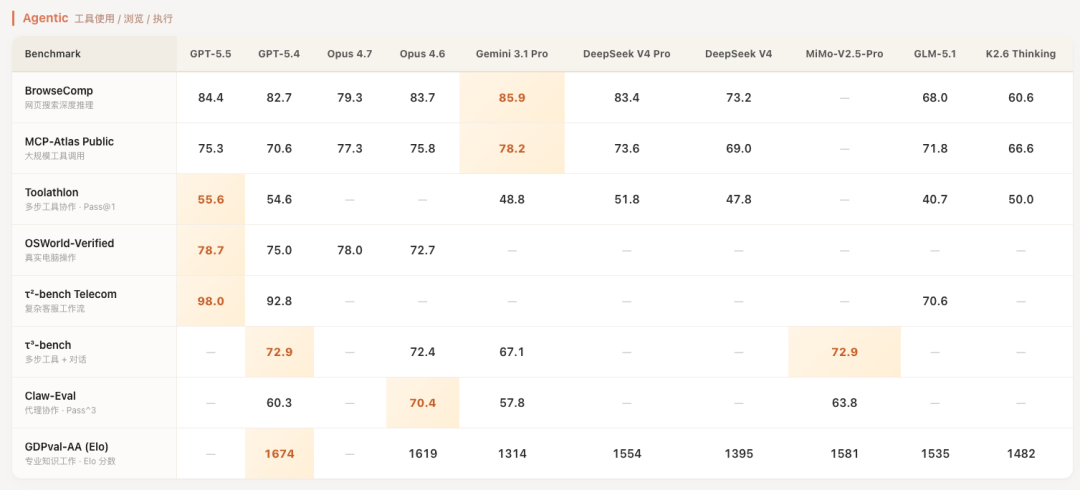
Agent 能力那一栏我多看了两眼。这个方向的评测目前还没有特别统一的标准,但各家内部测试和第三方机构的反馈,V4-Pro 的 Agent 表现确实很能打。
1.6 万亿参数,大了两倍半
V4-Pro 的总参数量是 1.6 万亿。前一代 V3.2 是 6710 亿。翻了将近两倍半。
在很多人觉得“参数规模不太重要了”的今天,DeepSeek 用 V4 说了一句:大就是有效,大就是聪明,大就是领先。
但“大”也有代价。参数涨了,推理成本就压不住。
V4-Pro 的定价是输入 12 元/百万 Token,输出 24 元。V4-Flash 便宜很多,输入 1 元,输出 2 元。换算成美元的话,Pro 输入 3.48。Flash 输入 0.28。
跟海外选手比,还是便宜了大概 60%。 但你要是拿它跟 DeepSeek 自己以前的“价格屠夫”人设比,那确实是涨了。

我拉了一张主要模型的比价图,一目了然:
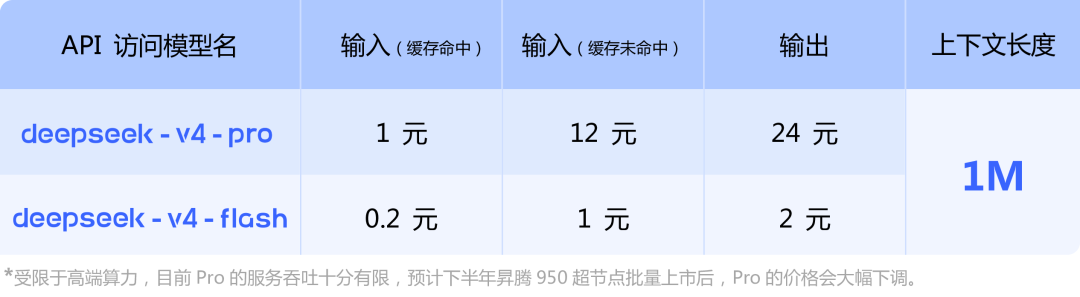
有个细节务必注意。 DeepSeek 在定价页面底下写了一行小字,大意是:Pro 的推理服务目前“吞吐十分有限”,得等下半年昇腾 950 超节点量产之后,Pro 的价格才能大幅降下来。
翻译一下:不是不想便宜卖,是算力真的不够用。
三驾马车:这次真正的核心
跑分和定价都不是这次的重点。重点在架构。
这次 V4 有三大底层创新,业内已经讨论了挺久,发布前就有各种代码泄露的猜测。现在官宣了,我用人话给你过一遍。
CSA + HCA:让长文本不再“吃”算力
这是 V4 最狠的一招。
你想想传统大模型怎么处理长文本的。每生成一个 Token,它要把前面所有的 Token 都算一遍注意力,计算量跟上下文长度的平方成正比。100 万 Token 的长文本,技术上有,但一直没法大规模商用,因为太贵了。
DeepSeek 这次改了一个东西:它不再“一视同仁”地算注意力了。
CSA 负责快速扫描所有 Token,找出真正相关的那些。HCA 负责把不太重要的部分做一个超强压缩,留下核心信息但不占算力。
效果有多夸张?在 100 万 Token 的极限测试下,V4 的单 Token 推理计算量只有前代的 27%,KV 缓存直接砍到 10%。
这意味着,以前百万 Token 上下文是实验室里的奢侈品,现在是普通人用得起的日用品了。
mHC:给训练装个“限速器”
这个名字看着吓人,其实你可以这么理解:
万亿级参数的大模型,训练的时候有几百层网络。信息在这几百层里传来传去,传统架构下信号的放大倍数能到 3000 倍,训练过程就跟开一辆油门忽大忽小的车一样,很容易翻。
mHC 就是给每一层的信息传递上了一道交通规则,把放大倍数死死压在 1.6 以内。训练稳了,学习率就能调高,整个训练周期就缩短了。
Muon 优化器
这个属于内行看门道的创新。它替代了大家用了多年的 AdamW 优化器,专门为 V4 这种超大规模模型设计的,能让收敛更快更稳,节省大量训练时间。
三驾马车总结一下:一个让推理变便宜,一个让训练变稳定,一个让收敛变快。全打在效率上。
比架构更值得关注的:国产算力 V4 发布当天,华为云就宣布昇腾超节点完成全栈适配。
这背后工程量有多大?DeepSeek 需要把大量原本跑在 NVIDIA GPU 上的 CUDA 代码,迁移到华为的 CANN 架构上。业内管这个叫“飞行中换引擎”,意思是从底层硬件到上层软件全得重新适配,而飞机还不能停下来。
智源 FlagOS 更猛,直接完成了 V4 在 8 款国产芯片上的全量适配,包括海光、沐曦、昇腾、摩尔线程、昆仑芯这些。

我画了一张适配全景图,你感受一下这个阵势:

这件事比任何一个跑分都值得关注。 DeepSeek 作为国内最强开源力量,正在用 V4 把国产算力生态拉进真正的实战场景。而且 MIT 许可证全开源,任何人都能拿去用、拿去改、拿去商用。
写在最后
V4 这次发布,没有去年 R1 那种颠覆式的震撼。跑分没有碾压所有闭源巨头,价格也没有延续“屠夫”的人设。
但它做了一件更难的事:在算力被限制的前提下,靠架构创新把百万 Token 长上下文的门槛打了下来,并且在国产芯片的地基上把这栋楼真正盖了起来。
强不强,是个动态的事。今天你是第一,下周可能就有新模型把你超了。但能不能在最前沿的赛道上,用工程智慧和系统创新杀出一条路,这件事的意义比任何跑分都大。
好了,我去继续跑复杂项目测试了。V4 在真实工程环境的交付质量到底怎么样,测完回来跟你们唠。
⭐ 关注我,星标我,带你第一时间看懂 AI 底层逻辑。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 8
8 0
0- 0



 已为社区贡献22条内容
已为社区贡献22条内容

所有评论(0)