PyTorch 实战:MNIST 手写数字识别
本文介绍了基于PyTorch的MNIST手写数字识别项目实现。项目包含数据预处理、CNN网络定义、训练测试流程及结果可视化。使用torchvision自动下载MNIST数据集,构建包含卷积层、池化层和全连接层的CNN网络,采用SGD优化器进行训练。代码结构清晰,包含model.py定义网络结构,train.py处理训练测试流程。项目支持GPU加速,训练10轮后测试准确率可达98%以上,并自动生成损失曲线和预测结果可视化图。运行简单,只需安装依赖后执行train.py即可完成整个流程。
---
## 项目结构
```
mnist_project/
├── data/ # 首次运行后由 torchvision 自动下载 MNIST
├── model.py # CNN 网络定义(Net)
├── train.py # 数据加载、训练、测试、可视化
├── requirements.txt
└── MNIST_PyTorch教程.md # 本说明
```
**依赖安装:**
```bash
pip install -r requirements.txt
```
**运行训练:**
```bash
python train.py
```
---
## 1. 设置设备(GPU / CPU)
根据是否有 CUDA 选择计算设备;无 GPU 时自动用 CPU。
```python
import torch
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(f"Using device: {device}")
```
- **说明**:`torch.cuda.is_available()` 为 `True` 时使用 GPU,可显著加快卷积与矩阵运算。
---
## 2. 导入与预处理数据集
使用 `torchvision.datasets.MNIST` 下载并读入 28×28 灰度图;`ToTensor` 将像素归一化到 \([0,1]\);`Normalize` 使用 MNIST 的常用统计量,有利于训练稳定。
```python
from pathlib import Path
from torchvision import datasets, transforms
data_dir = Path(__file__).resolve().parent / "data"
transform = transforms.Compose(
[
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,)), # MNIST 单通道均值与标准差
]
)
train_dataset = datasets.MNIST(
str(data_dir), train=True, download=True, transform=transform
)
test_dataset = datasets.MNIST(
str(data_dir), train=False, download=True, transform=transform
)
```
- **说明**:`data/` 相对脚本所在目录,首次 `download=True` 会自动建目录并拉取数据。
---
## 3. 使用 DataLoader 批加载
训练集打乱顺序(`shuffle=True`),测试集一般不打乱。批次大小可自定;本仓库为训练 `64`、测试 `1000`。
```python
from torch.utils.data import DataLoader
train_loader = DataLoader(
train_dataset, batch_size=64, shuffle=True
)
test_loader = DataLoader(
test_dataset, batch_size=1000, shuffle=False
)
```
- **说明**:`DataLoader` 负责按 batch 组 batch、多进程可选;测试 batch 大仅加快全部样本一遍的速度。
---
## 4. 定义 CNN 网络(`model.py`)
卷积层提取局部特征,池化下采样,全连接层做 0–9 十类分类。本仓库输出为 **对数概率** `log_softmax`,与下文的 `NLLLoss` / `F.nll_loss` 配套。
> 以下与 `model.py` 中实现一致,可直接整文件复制到 `model.py`。
```python
import torch.nn as nn
import torch.nn.functional as F
class Net(nn.Module):
def __init__(self) -> None:
super().__init__()
self.conv1 = nn.Conv2d(1, 10, kernel_size=5)
self.conv2 = nn.Conv2d(10, 20, kernel_size=5)
self.conv2_drop = nn.Dropout2d()
self.fc1 = nn.Linear(320, 50)
self.fc2 = nn.Linear(50, 10)
def forward(self, x):
x = F.relu(F.max_pool2d(self.conv1(x), 2))
x = F.relu(F.max_pool2d(self.conv2_drop(self.conv2(x)), 2))
x = x.view(-1, 320)
x = F.relu(self.fc1(x))
x = F.dropout(x, training=self.training)
x = self.fc2(x)
return F.log_softmax(x, dim=1)
```
- **结构要点**:
- 输入 1 通道、两次 5×5 卷积 + 2×2 最大池化,展平为 320 维后接两层全连接,输出 10 类。
- `Dropout2d` / `dropout` 缓解过拟合;若最后一层为 **原始 logits** 且使用 `nn.CrossEntropyLoss()`,则 **不要** 对输出再做 `log_softmax`。
---
## 5. 训练与测试(`train.py`)
### 5.1 超参数
本仓库中(可与 `train.py` 中变量对应):
| 项目 | 取值 |
|--------------|---------|
| 训练 batch | 64 |
| 测试 batch | 1000 |
| 学习率 | 0.01 |
| 动量 | 0.5 |
| 训练轮数 | 10 |
| 日志打印间隔 | 每 10 个 batch |
### 5.2 损失函数与优化器
输出为 `log_softmax` 时,使用 **负对数似然** 与 `nll_loss` 一致;优化器为带动量的 SGD。
```python
import torch.optim as optim
import torch.nn.functional as F
from model import Net
network = Net().to(device)
optimizer = optim.SGD(network.parameters(), lr=0.01, momentum=0.5)
```
训练单步中:
```python
output = network(data)
loss = F.nll_loss(output, target) # 与 log_softmax 配套
```
若改为网络最后直接输出 **未归一化 logits** 并去掉 `log_softmax`,可写:
```python
# criterion = nn.CrossEntropyLoss()
# loss = criterion(output, target)
```
### 5.3 训练循环
```python
def train_one_epoch(network, device, train_loader, optimizer, epoch, log_interval=10):
network.train()
for batch_idx, (data, target) in enumerate(train_loader):
data, target = data.to(device), target.to(device)
optimizer.zero_grad()
output = network(data)
loss = F.nll_loss(output, target)
loss.backward()
optimizer.step()
if batch_idx % log_interval == 0:
print(
f"Train Epoch: {epoch} "
f"[{batch_idx * len(data)}/{len(train_loader.dataset)}]\t"
f"Loss: {loss.item():.6f}"
)
```
- **说明**:`model.train()` 会启用 Dropout 等;先 `zero_grad` 再反传、再 `step`。
### 5.4 测试 / 评估
```python
def test_epoch(network, device, test_loader):
network.eval()
test_loss = 0.0
correct = 0
with torch.no_grad():
for data, target in test_loader:
data, target = data.to(device), target.to(device)
output = network(data)
test_loss += F.nll_loss(output, target, reduction="sum").item()
pred = output.argmax(dim=1, keepdim=True)
correct += pred.eq(target.view_as(pred)).sum().item()
test_loss /= len(test_loader.dataset)
acc = 100.0 * correct / len(test_loader.dataset)
print(
f"Test: Avg loss: {test_loss:.4f}, "
f"Accuracy: {correct}/{len(test_loader.dataset)} ({acc:.2f}%)"
)
```
- **说明**:`eval()` 关闭 Dropout 等;`torch.no_grad()` 节省显存、加速推理。
主流程:每个 epoch 先 `train` 再 `test`,重复 `n_epochs` 次(见 `train.py` 中循环)。
---
## 6. 结果可视化
使用 `matplotlib` 可:
1. **训练损失曲线**:用列表记录 `train_losses` 与步数/样本计数 `train_counter`,`plt.plot` 后保存为 `train_loss.png`。
2. **样本预测展示**:从 `test_loader` 取一个 batch,显示若干张图,标题为「真实标签 → 预测」。
以上逻辑已写在 `train.py` 末尾,运行后会生成图片文件路径终端会打印。
---
## 7. 结果图

## 小结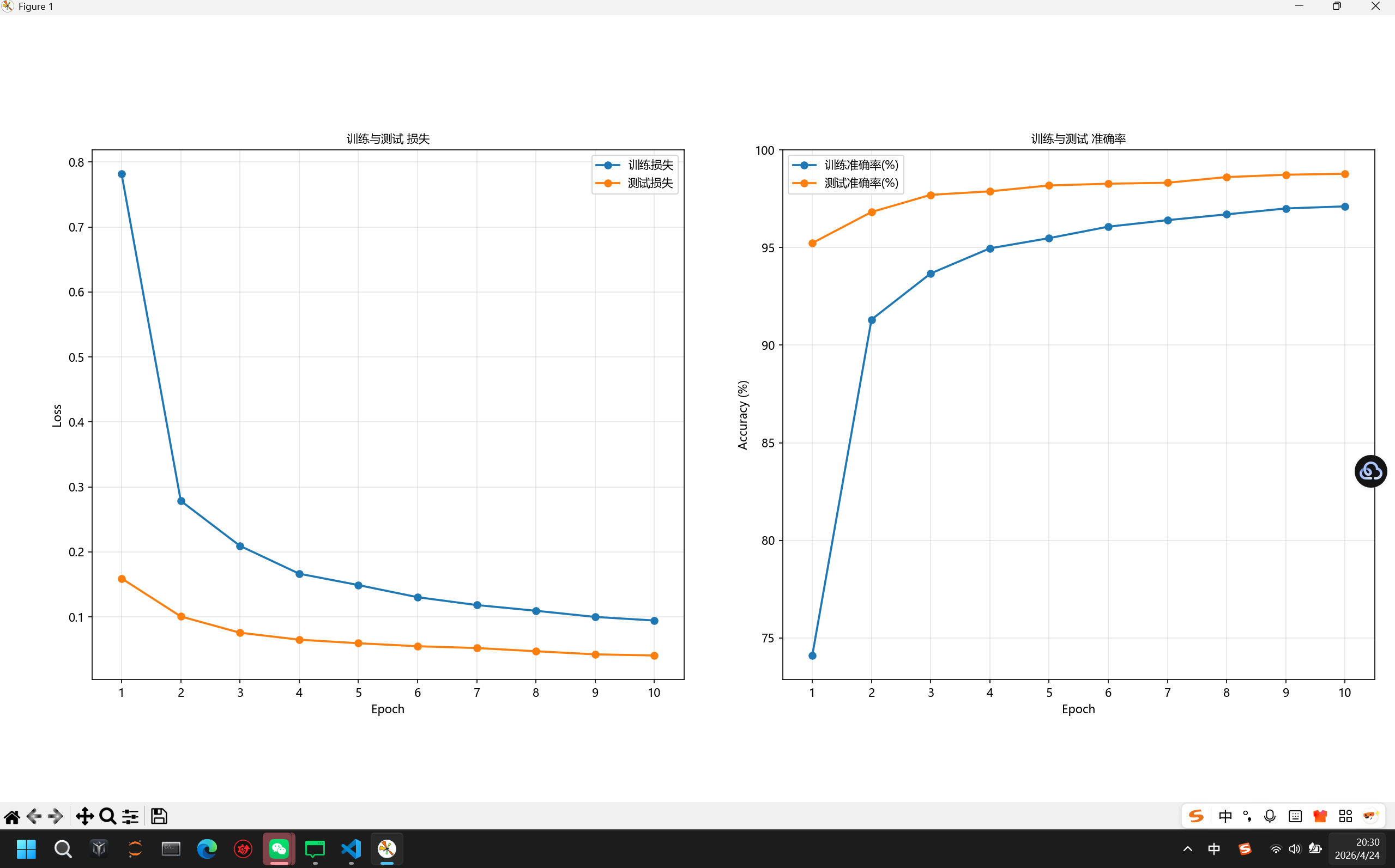
| 步骤 | 文件 / 位置 |
|------------|--------------------|
| 设备与数据 | `train.py` 前半 |
| 网络结构 | `model.py` `Net` |
| 训练与测试 | `train.py` 中函数 |
| 作图 | `train.py` 末尾 |

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 10
10 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)