深度学习六大经典模型深度剖析:从LeNet到Xception的架构演进与核心思想
引言
卷积神经网络的发展是一段持续的结构革命史。从1998年LeNet定下“卷积-池化-全连接”的基本范式,到2017年Xception用深度可分离卷积彻底解耦空间与通道相关性,每个里程碑都直面了一个核心难题:网络深度、梯度传播、计算效率、特征复用。
本文旨在通过PyTorch代码和可视化配图,深入拆解LeNet、AlexNet、VGG、GoogLeNet、ResNet、Xception这六大经典模型的设计动机、结构特点与核心创新。每个模型除了完整的定义代码,还配有特征图或结构图的可视化代码,用以印证理论上的理解。
目录
-
LeNet — 卷积范式的奠基者
-
AlexNet — 深度学习的引爆点
-
VGG — 深度之美,简约至上的堆叠哲学
-
GoogLeNet — 横向扩展的Inception
-
ResNet — 跳跃连接让深层网络重生
-
Xception — 深度可分离卷积的极致解耦
-
六大模型架构对比与优缺点总结
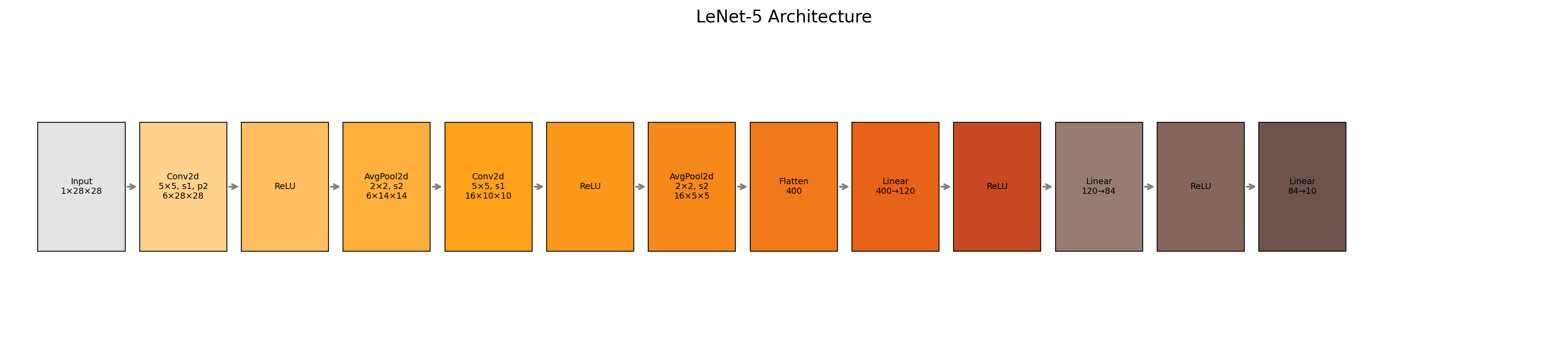
1. LeNet-5 —— 卷积范式的开山之作
设计动机
1998年,LeCun等人提出了用于手写数字识别的LeNet-5。它首次将卷积、池化和全连接组合成一个整体,确立了局部感受野、权值共享和下采样的设计思路。其最独特的C3层采用了非对称连接表,并非全连接前面所有特征图,而是有选择地组合不同低层特征。
原版架构(输入32×32)
-
C1: 6个5×5卷积,步长1 → 28×28×6
-
S2: 2×2平均池化,步长2 → 14×14×6
-
C3: 16个5×5卷积(选择性连接S2的6个特征图)→ 10×10×16
-
S4: 2×2平均池化 → 5×5×16
-
C5: 120个5×5卷积(全连接S4)→ 1×1×120
-
F6: 84个全连接神经元
-
输出: 10个神经元
2. AlexNet —— 深度学习引爆点
设计动机
2012年,AlexNet凭借ReLU激活函数、Dropout正则化、重叠最大池化和双GPU分组卷积一举夺得ImageNet冠军。它的结构深度虽浅(8层),但巧妙的分组设计解决了当时GPU显存不足的问题。
原版架构(双GPU并行,特征图在特定层分组)
-
Conv1: 96个11×11,步长4 → 55×55×96(分成两组各48)
-
MaxPool1: 3×3,步长2 → 27×27×48 / 组
-
Conv2: 256个5×5, pad 2 (仅组内卷积) → 27×27×128 / 组
-
MaxPool2: 3×3,步长2 → 13×13×128 / 组
-
Conv3: 384个3×3, pad 1 (两组间交叉连接) → 13×13×192 / 组
-
Conv4: 384个3×3, pad 1 (组内) → 13×13×192 / 组
-
Conv5: 256个3×3, pad 1 (组内) → 13×13×128 / 组
-
MaxPool5: 3×3,步长2 → 6×6×128 / 组
-
两组特征拼接 → 6×6×256
-
FC6: 4096
-
FC7: 4096
-
FC8: 1000

3. VGG16 —— 极致简约的深度堆叠
设计动机
VGG由牛津大学提出,最大贡献是证明了用规整的3×3小卷积核堆叠就能大幅提升深度和性能。2个3×3卷积的感受野等效于1个5×5,但引入更多非线性且参数量更少。整个网络分为5个卷积块,结构非常统一。
原版架构(16层)
-
Block1: 2 × Conv3-64 → MaxPool2/2
-
Block2: 2 × Conv3-128 → MaxPool2/2
-
Block3: 3 × Conv3-256 → MaxPool2/2
-
Block4: 3 × Conv3-512 → MaxPool2/2
-
Block5: 3 × Conv3-512 → MaxPool2/2
-
分类器: FC-4096, FC-4096, FC-1000

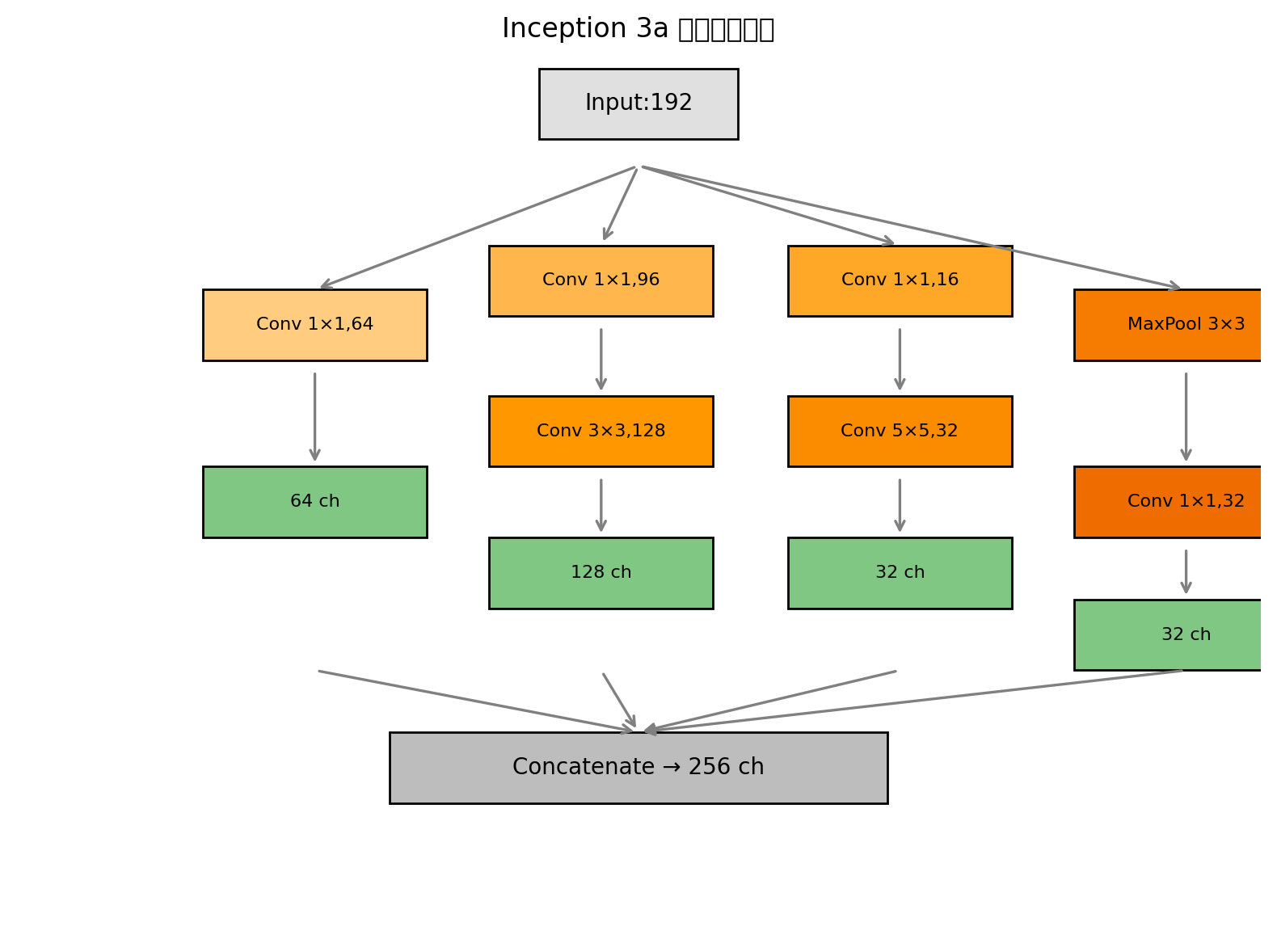
4. GoogLeNet (Inception v1) —— 横向扩展的并行支路
设计动机
GoogLeNet提出了Inception模块,在同一层内并行使用1×1、3×3、5×5卷积和3×3最大池化,再用1×1卷积降维,极大丰富了特征尺度。此外,为了缓解深层梯度消失,网络在中间层引出两个辅助分类器。
原版架构要素
-
主干:卷积→池化→多个Inception模块→全局平均池化→全连接
-
在Inception 4a和4d之后各有一个辅助分类器(AvgPool→1×1 Conv→FC→FC→Softmax)

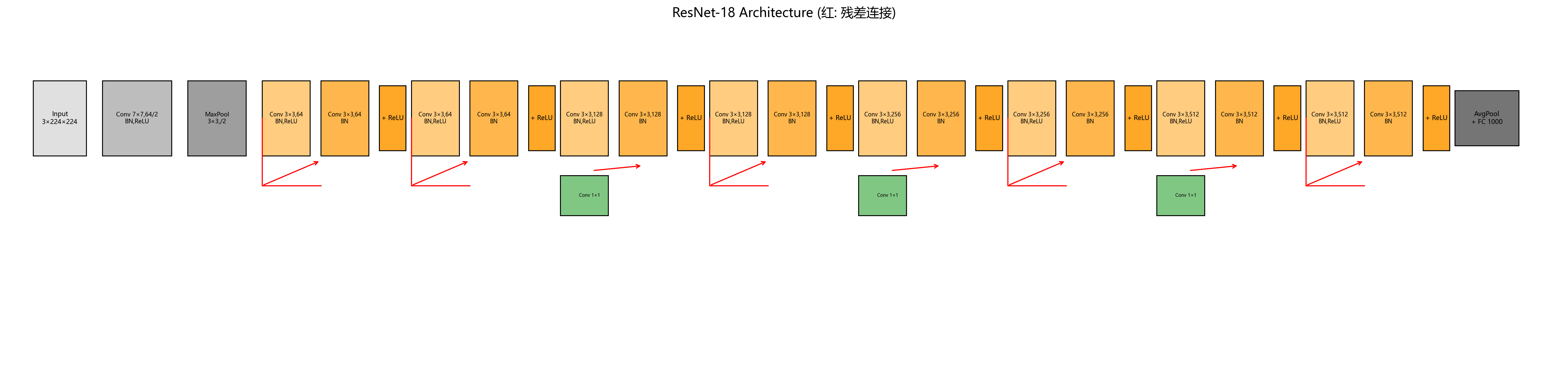
5. ResNet-18 —— 跳跃连接让深层网络重生
设计动机
ResNet通过引入残差连接解决了深层网络的退化问题。对于ResNet-18,每个残差块由两个3×3卷积组成,当特征图尺寸减半时,捷径使用1×1卷积进行投影。
原版架构(ResNet-18)
-
Conv1: 7×7,64, stride 2 → MaxPool 3×3, stride 2
-
Layer1: 2个残差块,通道64,捷径为恒等映射
-
Layer2: 2个残差块,通道128,第一个块用步长2卷积+1×1投影捷径
-
Layer3: 2个残差块,通道256
-
Layer4: 2个残差块,通道512
-
尾层: 全局平均池化 → FC 1000
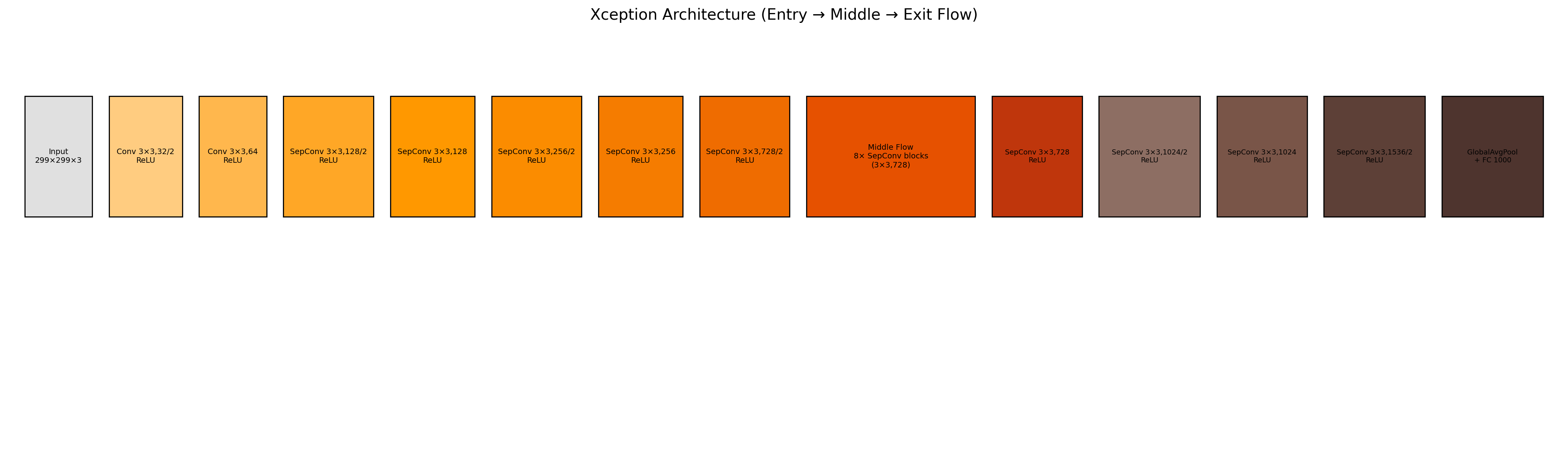
6. Xception —— 深度可分离卷积的极致解耦
设计动机
Xception将Inception思想推向极端:完全用深度可分离卷积替代普通卷积。关键在于其顺序为先1×1逐点卷积,再3×3逐通道卷积,且两者之间未经ReLU激活。这与后来MobileNet的先深度后逐点顺序恰好相反。
架构组成(Entry, Middle, Exit flow)
-
Entry flow: 一系列步长2和步长1的深度可分离残差模块
-
Middle flow: 8个相同的深度可分离残差模块(3×3, 728通道)
-
Exit flow: 进一步用深度可分离模块提取特征,最后接全局平均池化和全连接
7. 六大模型架构对比总结
下表从设计理念、关键创新和参数量等角度,对比这六座里程碑。
| 模型 | 年份 | 层数 | 核心创新 | 连接方式 | 特别说明 |
|---|---|---|---|---|---|
| LeNet | 1998 | 5 | 卷积+池化+全连接 | 顺序 | C3层选择性连接 |
| AlexNet | 2012 | 8 | ReLU, Dropout, 双GPU分组 | 顺序+分组 | 部分层特征图在组内独立 |
| VGG16 | 2014 | 16 | 全3×3小卷积核 | 顺序块 | 参数集中于全连接层 |
| GoogLeNet | 2014 | 22 | Inception多分支, 辅助分类器 | 并行分支 | 引入1×1降维 |
| ResNet | 2015 | 18/34/50... | 残差连接 | 捷径恒等/投影 | 极深网络训练成为可能 |
| Xception | 2017 | 71 | 深度可分离卷积(先1×1后3×3) | 残差+可分离 | 无ReLU置于逐点与深度之间 |

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 14
14 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)