从源代码文档到知识库:用AI把海量源码和项目文档变成靠谱的Wiki
当开发者说"我需要一份文档"时,他们真正想要的是一个能随时查阅、持续更新、还能跟智能体对话的知识库。
一、传统 Wiki 是怎么来的?
组织内部的项目文档、平台级 Wiki,生成方式大致分三种:
1. 开发者手写
最常见的模式。开发人员在功能上线后(或者更常见的——从来没写过)打开 Confluence、语雀、飞书文档,凭记忆补一份"系统架构说明"或"接口文档"。
2. 产品/技术负责人集中编写
由团队里的"文档担当"集中编写需求文档、接口说明、部署手册,然后通过评审后发布。
3. 自动化工具生成
Swagger 自动导出接口文档、Javadoc/JavaDoc 生成代码级 API 文档、MkDocs/Jekyll 把 Markdown 渲染成网站。
这三种方式构成了绝大多数公司的文档基础设施。但问题也很明显——
二、手写 Wiki 的五个致命弱点
如果你写过文档,你一定经历过以下场景:
1. “写文档的时间够我写完功能了”
开发者天然不爱写文档。一个复杂模块的业务逻辑,要整理成条理清晰、有流程图、有数据表结构说明的文档,少说两三个小时。这个时间拿来写代码,已经合完 MR 了。
2. “文档上次更新还是半年前”
代码改了、接口变了、表结构加了字段,文档还是原来的样子。新人按文档部署,发现跑不通,只好去翻代码——然后得出一个结论:代码才是唯一的真相,文档仅供参考。
3. “我只改了登录模块,但文档是整篇的”
传统文档是"全量式"的。你改了其中一个小功能,要么整篇重写,要么在某个角落加一行——然后读者根本不知道哪个章节是新的、哪个已经过时。
4. “我知道系统架构,但我说不清楚”
手写文档依赖文档撰写者的表达能力和系统理解深度。很多技术细节只有写代码的人才知道,但这些人往往不擅长(或没时间)把隐性知识转化为结构化文档。
5. “文档库是个孤岛,智能客服读不到”
当团队想接入 AI 智能客服、智能问答时,发现 Confluence/语雀的内容很难直接喂给大模型——要么是 API 受限,要么是内容格式不统一,要么是权限管理导致数据拉不全。
那么,我怎么让 AI 来做这件事呢?
三、AI 生成 Wiki 库的核心优势
1. 代码即真相,AI 直接读源码
不需要开发者凭记忆写文档。AI 直接读取 Java 源代码、MyBatis XML 映射、Spring Boot 配置、依赖关系,把业务逻辑翻译成自然语言。代码改了,重新扫描即可。
2. 结构化输出,不是"流水账"
AI 按统一模板输出文档:每个类有业务职责、核心逻辑、数据交互、依赖关系、设计意图。每个模块有文件索引、业务流程、MyBatis 映射关系。项目级有架构图、依赖图、部署架构。
3. 增量更新,只改动过的地方
AI 扫描支持增量模式——只重新生成有代码变更的模块文档,其他保持不变。文档永远跟代码同步。
4. 开发者零成本
不需要开发人员额外编写文档。只需要在 CI/CD 或本地执行一次扫描命令,文档自动产出。
5. 天然适配 AI 智能体
生成的文档是结构化的 Markdown,可以直接放入 VitePress 静态网站,也可以直接喂给 RAG 知识库,供智能客服、智能问答等 Agent 场景使用。
四、从代码到 Wiki:三步构建高可靠知识库
下面介绍一套完整的 AI 生成项目 Wiki 知识库的方法论。整个流程分为三步:扫描工程 → 生成文档库 → 构建 VitePress 站点。
这里仅针对java工程,其他工程也可以类似参考。
第一步:扫描工程源码,生成 L1~L3 级解析文档
这一步的目标是:读取项目源代码,逐模块生成结构化文档。
这里使用了两个专门设计的 AI Skill 工具:
全局扫描:project-analyzer-generate-doc
适用于整个 Maven 多模块 Java 项目的全面文档生成。它的工作方式是自底向上的三步流水线:
- L3(文件级):逐个 Java 类生成业务逻辑详解文档,包含业务职责(200~300 字自然语言)、核心方法逻辑(触发条件、输入数据、业务规则、处理流程、输出结果、异常处理)、数据交互(数据库/Redis/外部服务)、依赖关系和设计意图。自动跳过 DTO/VO/枚举/接口等纯数据类。
- L2(模块级):在所有 L3 完成后生成,包含模块职责总览、文件索引表、MyBatis 映射关系、公共 API、模块依赖、核心业务流程。
- L1(项目级):最后生成项目级架构文档,包含技术栈、系统架构图、Maven 依赖关系、跨模块业务流、部署架构。
以 1000+个 Java 文件的项目为例,整个扫描过程约 50 分钟,L3 级文档每篇均 70+ 行。
局部扫描:module-analyzer-generate-doc
如果只需要分析项目中的某个特定模块(比如只关心订单模块或支付模块),可以使用这个 Skill,只生成该模块的 L3(文件级)+ L2(模块级)文档。速度更快——80 个文件约 25 分钟即可完成。
两个工具都支持增量更新、断点续传、自动清理低质量旧文档。扫描结果输出到项目的 .ai-doc/ 目录下,按模块和包路径组织。
第二步:结合设计文档和产品文档,生成完整 Wiki 文档库
第一步产出的是"源码视角"的文档。但一个完整的知识库还需要:
- 产品需求文档(PRD)
- 系统设计文档(架构设计、数据库设计、接口设计)
- 产品手册/用户指南
- 部署运维文档
这一步将上述所有文档源(源码解析文档 + 已有知识文档库 + 源代码库本身)进行整合,生成完整的 Wiki 文档库。
核心做法: 让 AI 读取第一步生成的 .ai-doc/ 目录下的所有源码解析文档,同时读取已有的产品/设计文档目录,然后:
- 生成统一的目录结构:按"快速入门 → 项目概览 → 系统架构 → 核心业务模块 → 数据管理 → API 接口 → 开发指南 → 运维部署 → 故障排查"等标准分类组织。
- 补充缺失内容:如果某个模块只有源码解析但缺少概览文档,AI 会根据 L2 文档自动生成模块概览。
- 统一写作风格:所有文档采用统一的 Frontmatter(tags、audience、accuracy)、Mermaid 图表、表格排版。
- 建立交叉引用:文档之间的相互引用使用标准 Markdown 链接,确保可导航。
最终输出的文档库形如:
XXX管理平台/
├── README.md # 项目入口,含快速导航
├── wiki.json # 元数据(文档数、更新时间、技术栈)
└── content/
├── 快速入门/
│ ├── 开发环境搭建.md
│ ├── 项目编译与打包.md
│ └── 分支与提交规范.md
├── 项目概览/
│ ├── 平台介绍.md
│ ├── 技术架构总览.md
│ └── 技术栈清单.md
├── 系统架构/
│ ├── 整体架构设计.md
│ ├── 消息队列架构.md
│ └── 缓存架构/
│ ├── Redis缓存策略.md
│ └── 缓存一致性.md
├── 核心业务模块/
│ ├── xxx-core核心业务模块.md
│ ├── xxx-admin-api管理端API模块.md
│ └── xxx-domain领域模型模块.md
├── 数据管理/
│ ├── 数据库设计.md
│ └── IoTDB时序数据.md
├── API接口/
│ ├── 管理端API总览.md
│ └── 对外工程接口.md
├── 开发指南/
│ ├── 代码规范.md
│ └── API开发指南.md
└── 运维部署/
├── 部署架构.md
└── 日志管理.md
第三步:构建 VitePress 静态站点
有了文档库后,下一步是让文档"活起来"——搭建一个可浏览、可搜索、可部署的 Wiki 站点。这里选择 VitePress(VuePress 的下一代),原因很简单:配置简单、性能优秀、支持中文搜索、构建产物是纯静态文件。
从零初始化 VitePress 工程
如果你从零开始搭建一个类似的 Wiki 站点,只需要以下步骤(当然,也可以直接丢给AI来生成):
1. 初始化项目并安装 VitePress
mkdir my-wiki && cd my-wiki
npm init -y
npm install -D vitepress
2. 运行向导生成基础配置
npx vitepress init
向导会提示你设置站点标题、描述、主题偏好等,完成后会自动生成:
my-wiki/
├── .vitepress/
│ └── config.mts # 自动生成的基础配置
├── index.md # 默认首页
└── package.json
3. 放入文档内容
将第二步生成的文档库(各子项目的 content/ 目录和 README.md)复制到项目根目录下。单项目直接放根目录,多项目则按子目录组织。
4. 配置导航与侧边栏
编辑 .vitepress/config.mts,设置 themeConfig.nav(顶部导航)和 themeConfig.sidebar(侧边栏)。如果是多工程聚合站点,sidebar 的 key 使用路径前缀(如 /项目名/),VitePress 会自动根据当前访问路径匹配对应的侧边栏配置。
5. 自定义主题(可选)
创建 .vitepress/theme/index.js 和 style.css,实现自定义样式、组件注入等:
// .vitepress/theme/index.js
import DefaultTheme from 'vitepress/theme'
import './style.css'
export default { extends: DefaultTheme }
6. 安装依赖并启动
npm install
npm run dev
# → http://localhost:5173
整个初始化过程通常不超过 5 分钟。后续只需将新生成的文档复制到对应目录,VitePress 的热更新会自动刷新页面。
项目结构
wiki/
├── .vitepress/
│ ├── config.mts # 核心配置:导航、侧边栏、主题
│ ├── theme/
│ │ ├── index.js # 自定义主题入口
│ │ └── style.css # 自定义样式
│ └── public/
│ └── favicon.ico # 站点图标
├── index.md # 首页(Hero 区域 + 项目卡片)
├── XXX1智慧系统/ # 子工程 1 文档
├── XXX2管理平台/ # 子工程 2 文档
├── XXX3管理平台/ # 子工程 3 文档
├── XXX4管理平台/ # 子工程 4 文档
├── XXX5管理平台/ # 子工程 5 文档
├── XXX-AI服务/ # 子工程 6 文档
├── package.json
└── .gitignore
关键配置
1. 导航栏与侧边栏(config.mts)
每个子工程在顶部导航有一个入口,通过 activeMatch 正则匹配,当前所在项目的导航项会自动加粗加大高亮显示。侧边栏按文档目录分类,支持折叠展开。
nav: [
{ text: '首页', link: '/', activeMatch: '^/$' },
{ text: 'XXX1智慧系统', link: '/XXX1智慧系统/...', activeMatch: '/XXX1智慧系统/' },
{ text: 'XXX2管理平台', link: '/XXX2管理平台/...', activeMatch: '/XXX2管理平台/' },
// ...
]
2. 本地开发
npm install
npm run dev
# → http://localhost:5173
3. 构建与部署
npm run build
# → 输出到 .vitepress/dist/
构建产物是纯 HTML/CSS/JS 静态文件,可部署到任意静态服务器:Nginx、GitHub Pages、阿里云 OSS、AWS S3 等。
4. 多工程聚合
如果公司有多个独立项目,可以将每个项目的文档作为子目录聚合到同一个 VitePress 站点中。config.mts 的 sidebar 配置支持按路径前缀匹配,实现"进入某个子工程目录,侧边栏自动切换为对应工程的菜单"。
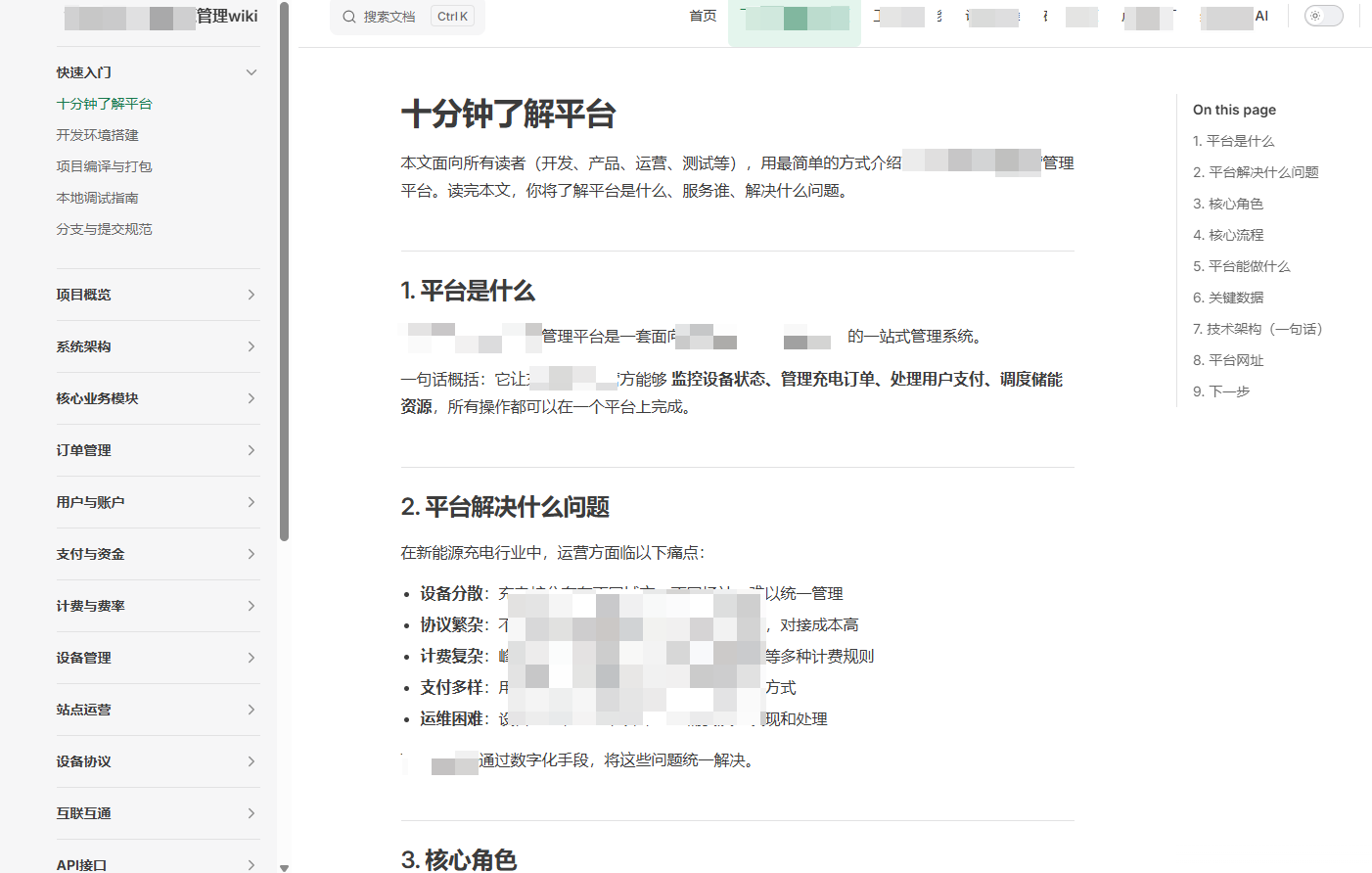
五、效果展示
以"XXX2管理平台"为例,最终生成的知识库包含:
- 60 篇文档,覆盖项目概览、系统架构、核心业务模块、邀约管理、申报计划、执行调度、设备监控、API 接口、数据管理、定时任务、开发指南、运维部署、故障排查等 16 个分类
- 每篇文档含 Mermaid 架构图/流程图,系统架构一目了然
- 统一的技术标签和元数据(tags、audience、accuracy),支持按标签筛选
- 侧边栏完整导航,点击进入任一章节,页面顶部导航自动高亮当前所属子工程
六、Wiki 知识库的价值与 AI 智能体场景
Wiki 知识库的作用
一个结构化的项目 Wiki 不只是"给新人看的入职手册",它是团队的知识基础设施:
- 新人 Onboarding:新人通过 Wiki 快速了解项目架构、业务模块、开发规范,从"看代码摸索"变成"查文档上手",入职周期从周级缩短到天级。
- 跨团队协作:前端、后端、测试、运维共享同一份文档,减少"这个接口怎么调"、"这个配置在哪改"的反复沟通。
- 知识沉淀与传承:资深开发者的业务理解通过 AI 生成的文档固化下来,不因人员流动而丢失。
- 审计与合规:系统架构、数据流向、安全策略有文档可查,满足合规审查要求。
结合 AI 智能体的应用场景
当 Wiki 知识库以结构化的 Markdown 形式存在时,它可以无缝对接多种 AI 智能体场景:
1. 智能客服 / 智能问答
将 Wiki 文档灌入 RAG(检索增强生成)知识库后,智能客服可以回答诸如:
- “申报方案的状态流转有哪些?”
- “设备离线怎么排查?”
- “这个接口的鉴权方式是什么?”
用户得到的是基于实际项目文档的精准回答,而非大模型"编造"的答案。
2. 开发助手 / 代码审查 Agent
结合源码解析文档(L3 级),AI 开发助手可以理解某个类的业务职责、数据交互方式和设计意图。在 Code Review 时,AI 可以基于文档判断新代码是否符合模块的既有设计规范。
3. 运维排障 Agent
将"故障排查"类文档接入运维 Agent 后,当监控告警触发时,Agent 可以自动检索相关的排查流程和常见解决方案,辅助运维人员快速定位问题。
4. 产品需求追溯
将产品文档与源码解析文档关联后,可以追溯"某个需求在代码中是如何实现的"、“某段代码对应的需求背景是什么”,形成需求 → 设计 → 代码 → 文档的完整闭环。
七、总结
传统的手写 Wiki 文档面临"写不动、更不上、查不到"三大难题。让 AI 直接读取源代码和已有文档来生成知识库,不仅解决了成本和时效问题,还让文档的结构化程度和可检索性大幅提升。
核心路径:
- 用 AI 扫描源码,生成 L1~L3 级结构化解析文档
- 整合产品/设计文档,构建完整的 Wiki 文档库
- 用 VitePress 搭建可浏览、可搜索、可部署的 Wiki 站点
- 将文档接入 RAG 知识库,赋能智能客服、开发助手等 AI 场景
这套方法已经在多个实际项目中验证——从 60 篇文档的中型项目到 900 篇文档的大型聚合站点,构建过程从周级缩短到小时级,文档质量从"仅供参考"提升到"可靠可查"。
附:工具与资源
project-analyzer-generate-doc
Java 多模块项目 AI 文档生成器。自动扫描整个 Maven 项目,生成 L1(项目级)→ L2(模块级)→ L3(文件级)三层结构化文档。支持增量更新、断点续传、并行子 Agent 加速。
发布地址:https://clawhub.ai/endcy/project-analyzer-generate-doc
module-analyzer-generate-doc**
Java 单模块深度分析工具。针对单个 Maven 模块生成 L2 + L3 级详细文档,速度更快,适合局部模块分析场景。
发布地址:https://clawhub.ai/endcy/module-analyzer-generate-doc
base-ai-assistant
基于 Spring Boot、Spring AI、Spring AI Alibaba 实现的 RAG、MCP、Agent 智能体基础服务框架应用。智能客服、智能运维、智能助手、简单工作流/垂直领域智能体的基础应用架构版本,按需拓展。
开源地址:https://github.com/endcy/base-ai-assistant

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 9
9 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)