RAG-7-Microsoft GraphRAG
GraphRAG简介
GraphRAG的定义
GraphRAG(Graph-based Retrieval-Augmented Generation)是一种结合知识图谱与检索增强生成 (RAG)的技术框架,旨在通过图结构数据增强大语言模型(LLMs)的推理能力和回答准确性。
(1)知识图谱构建
• 节点与边:节点表示实体(如人物、概念),边表示关系(如“影响”“属于”)。
• 自动化构建:通过LLM从非结构化文本中抽取实体和关系(如“莫奈→创作→《睡莲》”),并存 储于图数据库(Neo4j等)。
• 社区检测:使用Leiden算法将图谱聚类为主题社区(如“艺术运动”“科技公司”),并为每个社 区生成摘要。
(2)图检索与推理
• 检索机制:结合图遍历(如广度优先搜索)和向量相似度,定位相关子图。
• 多跳推理:沿图谱边路径推导答案(如“供应链中断→芯片短缺→汽车减产”)。
(3)生成优化
• 图增强生成:LLM结合检索到的子图结构和文本片段生成回答,提升逻辑性和可解释性
GraphRAG和传统RAG的区别
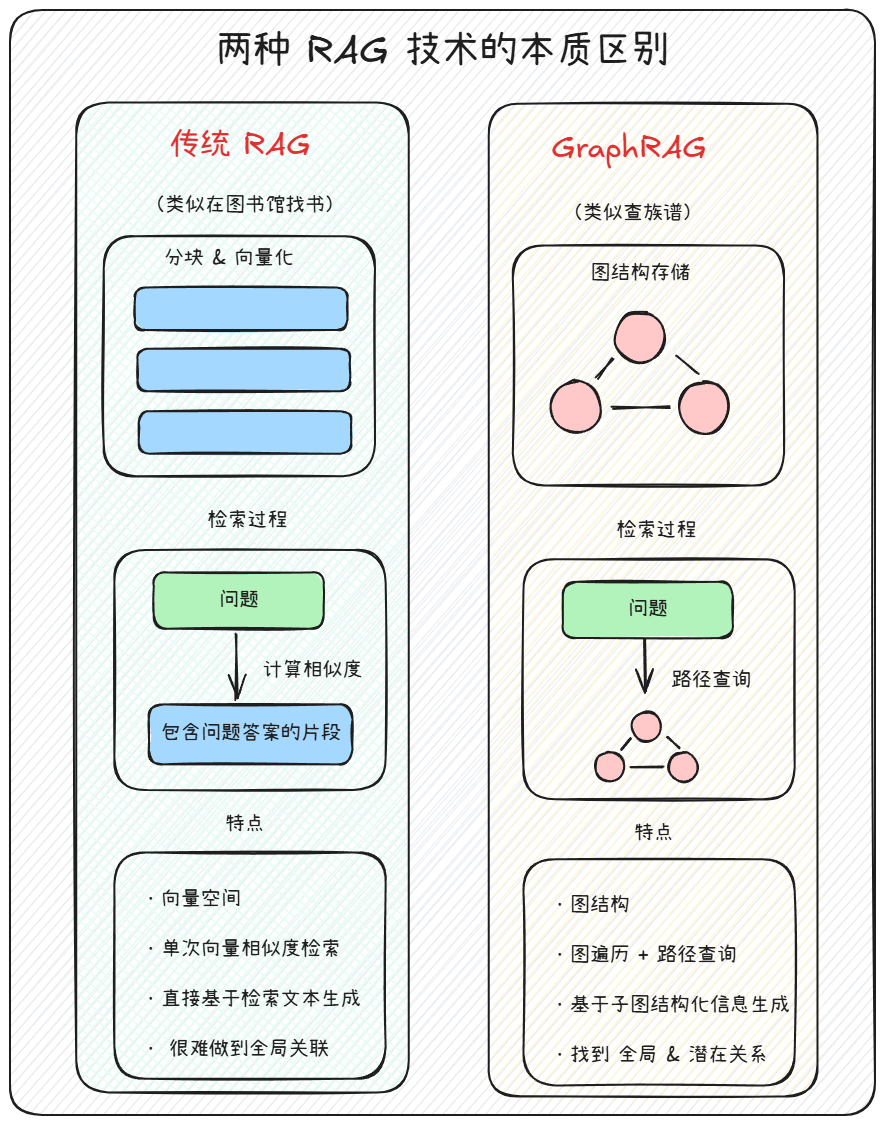
基于00000000000000语义块检索的`RAG`技术,最大的一个问题是很难去检索到全局的信息。比如我们问的问题散落在不同的语义块中,那么基于语义块检索的`RAG`技术就很难去检索到全局的信息。关键词匹配局限就在于如果用户查询“哪些动物吃食物?”,传统方法可能只能检索到“Dog eats Food”或“Cat eats Food”中的一个,而无法同时获取所有相关信息。
图结构的优势就在于:可以在图谱中建立实体之间的关系,从而可以更全面的检索到全局的信息。 如此一来在进行检索时,就可以从图谱中检索到与问题相关的所有信息,从而可以更全面的检索到全局的信息。
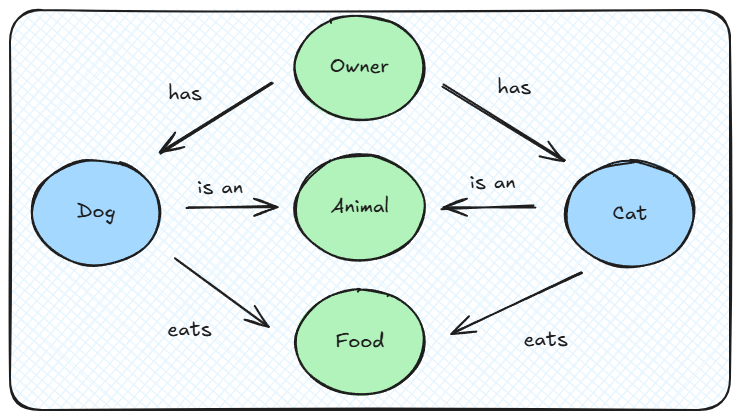
这种创新方法是由NebulaGraph率先提出的概念,所以本质上,GraphRAG技术就是对传统RAG技术的一种增强,其目的是将知识图谱与大语言模型结合起来,以增强信息检索和生成能力。与将纯文本文档块发送到大模型不同,GraphRAG还可以向大模型提供结构化实体信息,将实体文本描述与其属性和关系相结合,借助 GraphRAG中的每个记录更加丰富的上下文表示,从而提高了特定术语/用户意图的可理解性。
GraphRAG是一种技术范式,其目的是将知识图谱与大语言模型结合起来,以增强信息检索和生成能力。在这一技术范式下,衍生出非常多的开源项目、框架或工具会去实现这一流程。比较受欢迎的工具和项目主要如下:

GraphRAG索引流程
安装graphRAG
pip install graphrag安装完成后,我们可以通过以下命令验证是否安装成功:
pip show graphragGraphRAG的CLI基本使用方法
通过graphrag --help 命令返回的参数信息主要设计的就是GraphRAG的构建和检索功能,具体来看:
- init: 初始化`GraphRAG` 的配置文件;
- index: 构建`GraphRAG` 索引,即`Indexing`过程;
- query: 检索`GraphRAG` 的查询,即`Querying`过程;
- update: 更新`GraphRAG` 的索引,即增量更新;
初始化配置文件(init)
构建索引的第一步,就是先执行`graphrag --init` 命令来生成默认的配置文件。即执行命令如下:
graphrag init --root ./其中 `--root` 参数用于指定生成的配置文件的存储路径,`./` 表示当前目录。
当执行`graphrag --init --root ./` 命令后,会生成两个配置文件及一个文件夹,分别是:
settings.yaml:主配置文件,包含 `GraphRAG` 从索引构建到检索的设置;
.env:环境变量文件。里面主要存储的是`API_KEY`密钥等敏感信息,在`settings.yaml`文件中引用;
prompts/: 提示词文件夹。它包含 `GraphRAG` 使用的默认提示;
.env文件配置说明
.env文件中主要存储的是API_KEY密钥等敏感信息,作为环境变量会在settings.yaml文件中被引用。默认的.env文件中只有一个GRAPHRA_API_KEY,用来存储用于GraphRAG构建过程中使用的大模型的有效API_KEY。 我这里使用通义千问

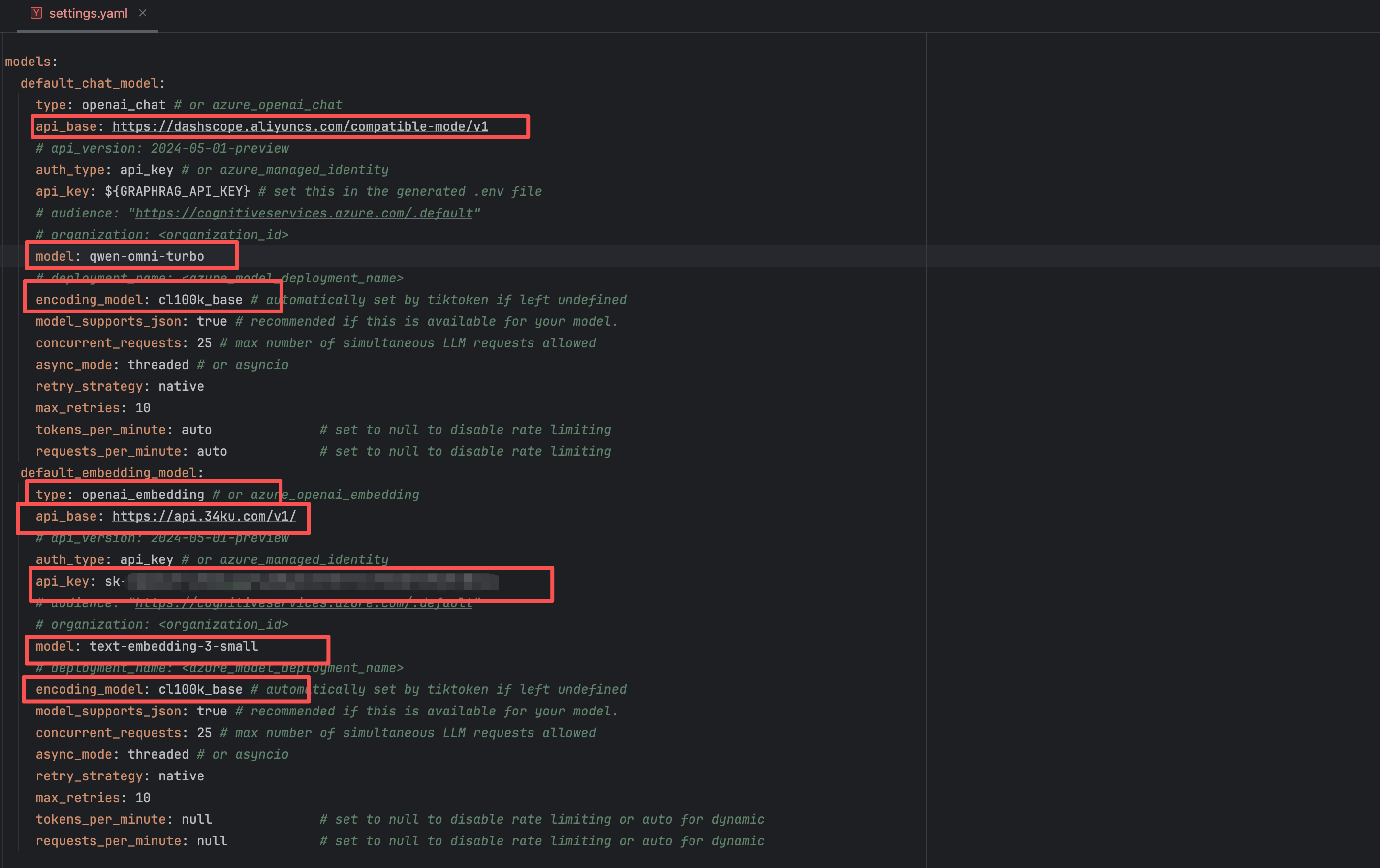
settings.yaml文件配置说明
settings.yaml文件是GraphRAG 的CLI工具的主配置文件,里面主要存储的是GraphRAG的索引构建流程的配置信息。默认的settings.yaml文件中的配置信息非常多,涉及到了GraphRAG的索引构建Pipeline的各个环节中策略的控制。将如下信息改为自己的配置
数据准备
GraphRAG`的索引构建流程中,仅支持 .txt和 .csv两种格式的数据文件,因此如何不是这两种格式的数据文件,是无法直接进行索引构建的。加载文件的方法也非常简单,只需要在graphrag 初始化配置的同级目录下,新建一个input文件夹,然后把.txt或者 .csv文件放入其中即可。
GraphRAG构建索引完整流程(index)
在配置好了.env文件和settings.yaml文件后,同时又准备好了数据文件,接下来我们就可以执行索引的构建了。通过GraphRAG 的CLI工具,执行命令如下:
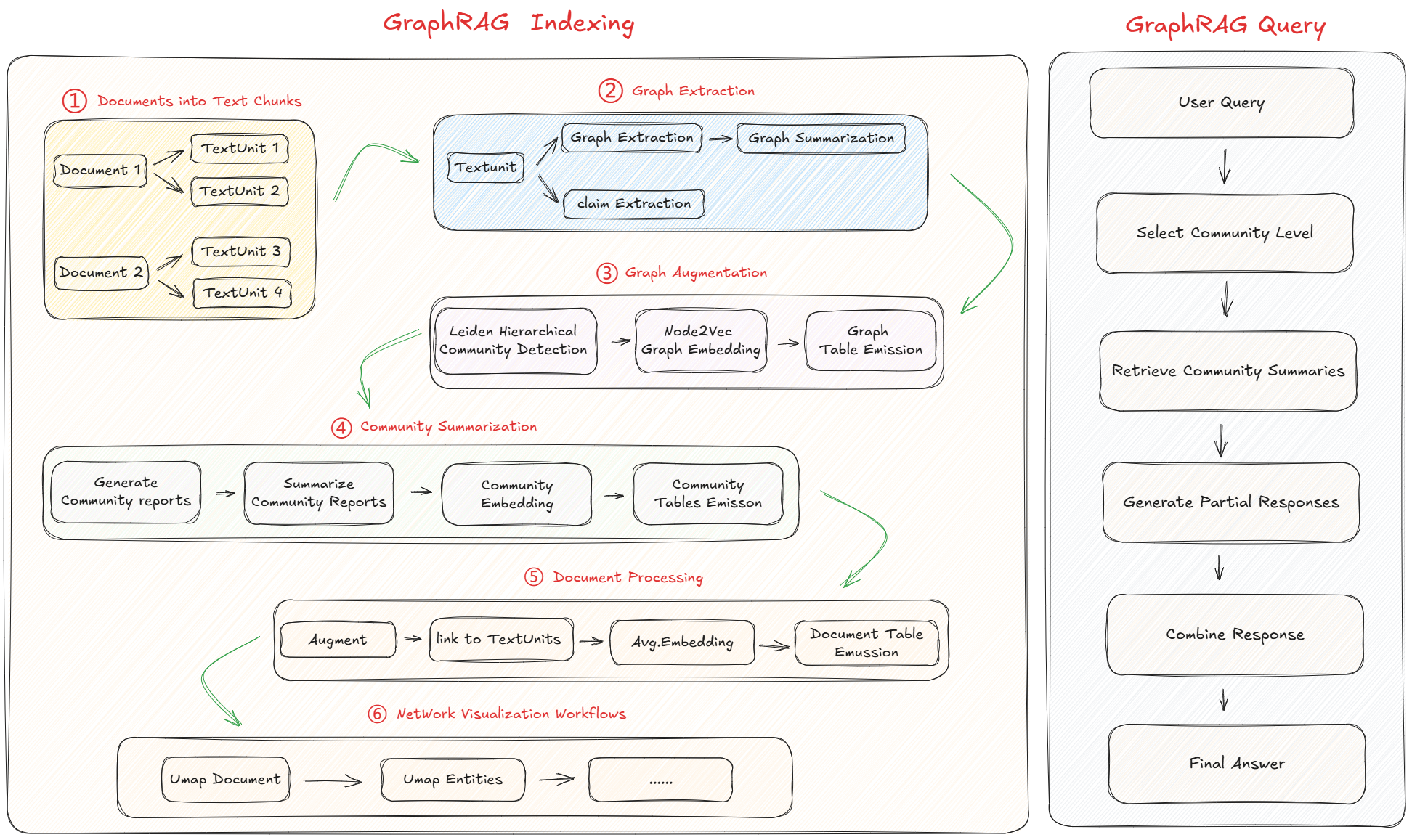
graphrag index --root ./这条命令指的是在当前目录下执行索引的构建。当执行后,会看到GraphRAG的索引构建流程开始执行。下图是构建索引的完整流程:
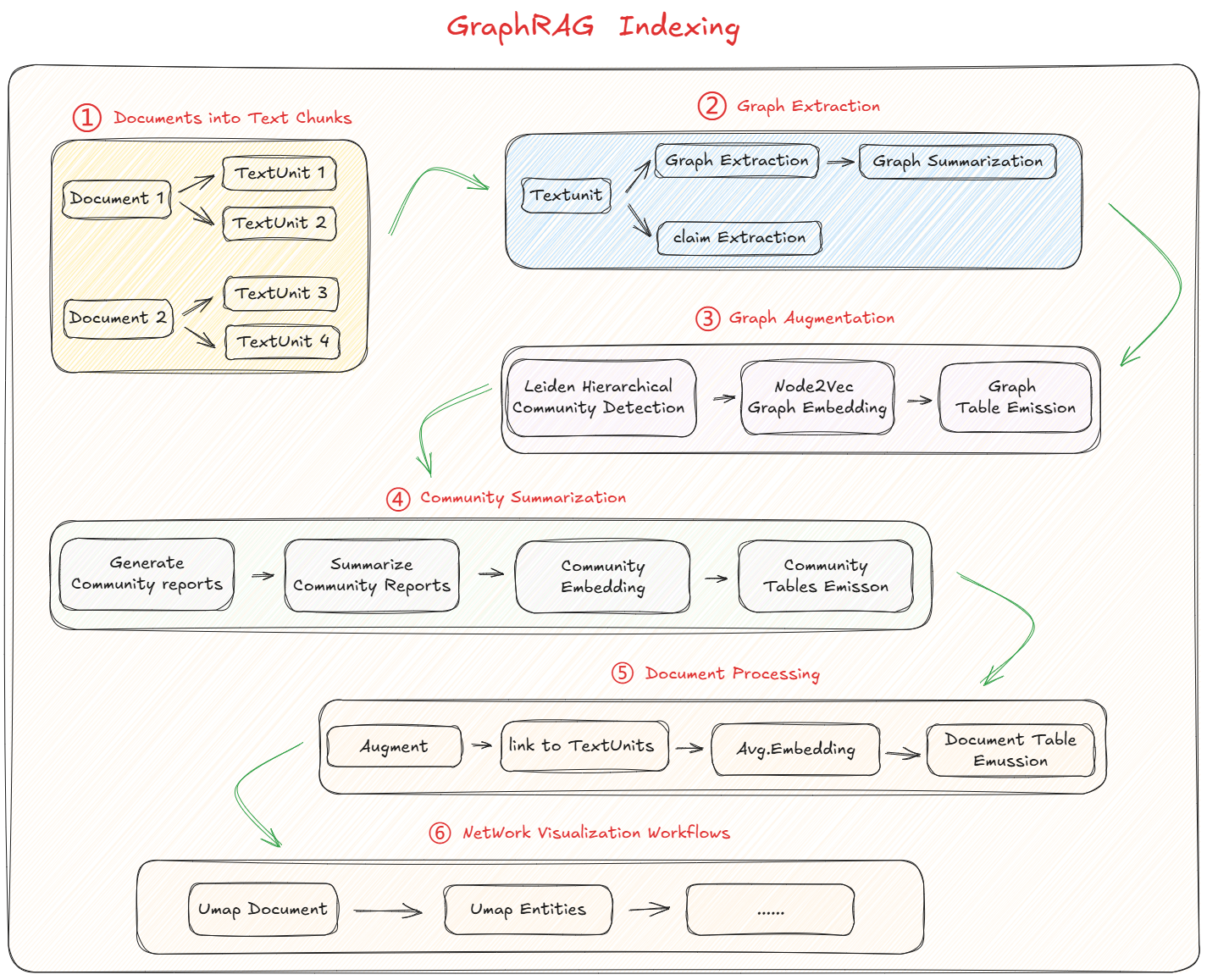
GraphRAG 整个Indexing过程可以通过以下简单的方式来理解:
1. 类似于 Baseline RAG,将源文档分块为较小的子文档;
2. 执行两个并行提取:实体提取用于识别人名、地名、组织名等实体,关系提取:查找不同数据块中实体之间的关系,比如朋友、同事,员工等;
3. 创建知识图谱,其中节点表示实体,边表示它们之间的关系,比如张三是李四的朋友, 张三是王五的同事;
4. 通过识别密切相关的实体来构建社区;
5. 生成不同社区级别的分层摘要;
6. 使用 reduce-map 方法通过逐步组合块来创建摘要,直到实现整体概览;
在构建索引结束后会分别生成cache、logs和output三个文件夹,分别存储了构建索引过程中的缓存文件、日志文件和输出文件。其中output文件夹中会生成很多个xxx.parquet文件,这些文件就是GraphRAG的索引文件,也是我们后续进行检索的依据。
检索
graphrag query --root ./ --method global --query "黑悟空是什么"Microsoft GraphRAG 提供local 和global 两种查询方式,分别对应local search 和global search。是 源于不同的粒度级别而构建出来用于处理不同类型问题的Pipeline, 其中:
• Local Search 是基于实体的检索。
• Global Search 则是基于社区的检索。
Microsoft GraphRAG 在查询阶段构建的流程,相较于构建索引阶段会更为直观。核心的具体步骤包 括:
• 接收用户的查询请求。
• 根据查询所需的详细程度,选择合适的社区级别进行分析。
• 在选定的社区级别进行信息检索。
• 依据社区摘要生成初步的响应。
• 将多个相关社区的初步响应进行整合,形成一个全面的最终答案。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 12
12 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)