HMM-GMM语音识别技术深度解析与实战指南
|
核心洞察:HMM-GMM 是理解整个语音识别技术演进的钥匙。它首次将语音识别问题系统化地分解为声学建模和时序建模两个子问题,并提供了可实现的数学框架。 |
语音识别技术的核心挑战在于,如何将连续、多变的声学信号,准确地映射为离散的文本序列。在深度学习席卷人工智能领域之前,隐马尔可夫模型-高斯混合模型(HMM-GMM) 框架是工业界主流的、最为成功的统计建模方案,统治了语音识别领域近三十年。
该框架的精妙之处在于其模块化设计:隐马尔可夫模型(HMM) 负责捕捉语音信号的时序动态特性,即音素如何随时间顺序出现和过渡;而高斯混合模型(GMM) 则负责描述每个发音单元(状态)的静态声学特征分布,即某个音素“听起来是什么样”。
理解HMM-GMM不仅是回顾历史,更是掌握现代端到端语音识别技术(如基于CTC、RNN-T的模型)的基石。其背后的状态建模、动态规划解码等核心思想,至今仍在深刻影响着新一代算法。
在让计算机“听懂”之前,我们需要将声音转化为它能处理的数学形式。这涉及两个关键概念:音素和声学特征。
音素是人类语言中能被区分的最小语音单位,是连接物理声波与抽象文本的桥梁。例如,中文“好(hao3)”可以分解为声母/h/、韵母/a/和韵母/u/(在汉语拼音中ao对应/a/和/u/的组合)。
声学特征提取的目标是从原始波形信号中,抽取出对识别任务最有效、且尽可能鲁棒的信息,同时压缩数据量。其中最经典、应用最广泛的特征是梅尔频率倒谱系数(MFCC)。
MFCC的提取过程模拟了人耳的听觉特性,其标准流程如下图所示:
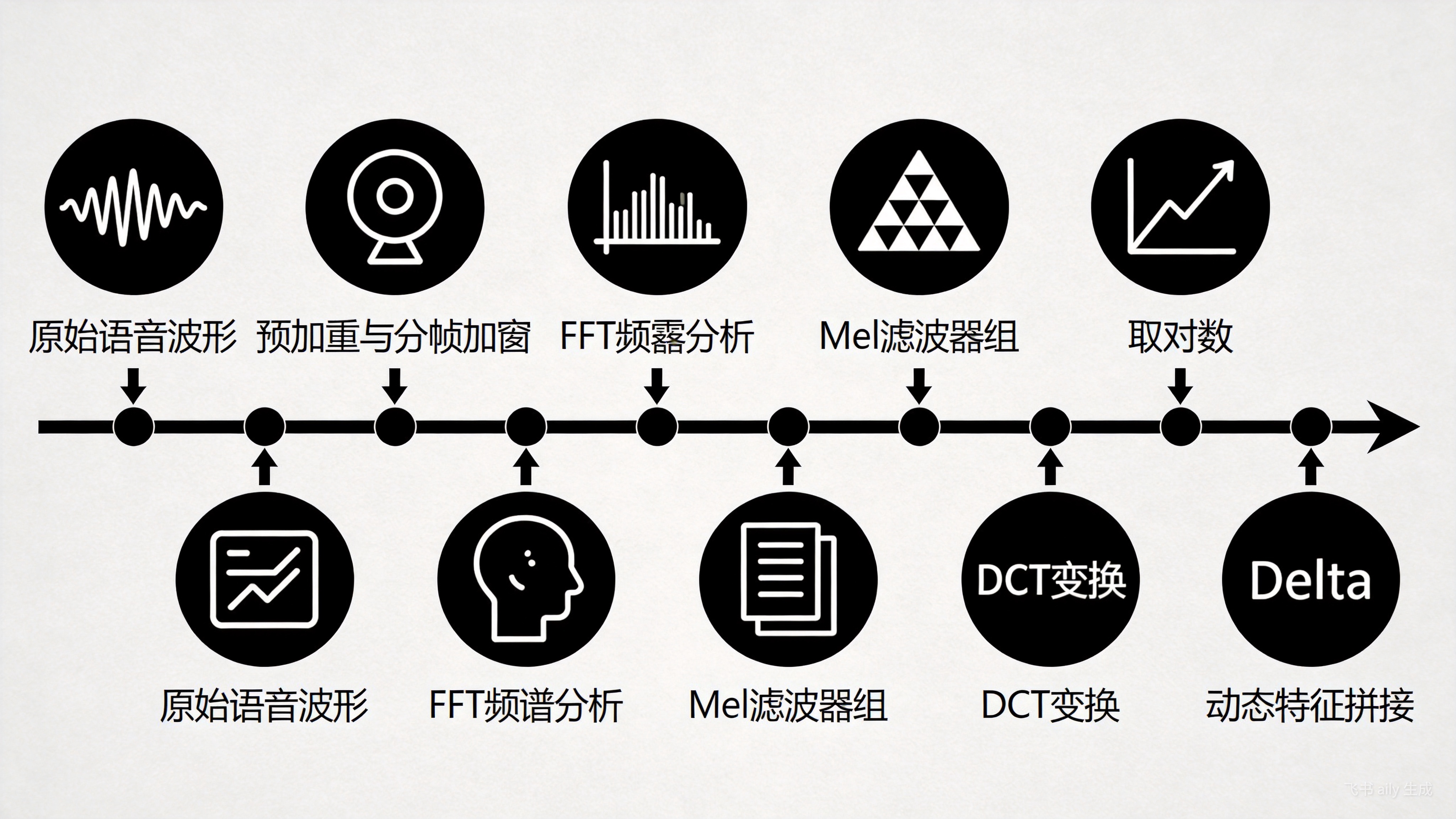
MFCC特征提取完整流程:从原始波形到多维特征向量
整个流程可以概括为以下步骤:
- 预加重、分帧与加窗:对连续语音信号进行高频提升,然后切分为20-40ms的短时帧,并为每帧加上汉明窗以减少频谱泄漏。
- 傅里叶变换(FFT):将每帧时域信号转换为频域能量谱。
- Mel滤波器组:将线性频率尺度映射到更符合人耳听觉的Mel尺度,并通过一组三角形滤波器进行平滑和降维。
- 取对数与离散余弦变换(DCT):对滤波器组输出取对数以模拟人耳对响度的非线性感知,再通过DCT去相关并压缩,得到静态MFCC系数(通常取前12-13维)。
- 动态特征拼接:计算静态MFCC的一阶差分(Delta)和二阶差分(Delta-Delta),以捕捉特征的时序变化信息,最终拼接成39维的特征向量。
MFCC因其对说话人差异和信道变化的一定鲁棒性,以及计算高效的特点,成为HMM-GMM时代乃至早期深度学习语音识别的事实标准特征。
GMM部分:为每个音素建立‘声音画像’
当我们获得了语音的数学表示(MFCC特征向量)后,下一个核心问题是:如何描述一个特定音素(如/a/)的声学特征?同一个音素由不同人、在不同语境下发出,其MFCC特征在空间中会形成一个复杂的、分散的分布。
一个简单的单高斯分布显然无法刻画这种可能具有多个聚集中心(多峰)的复杂结构。高斯混合模型(GMM) 应运而生,其核心思想是:用多个高斯分布(分量)的加权和来逼近任意复杂的概率分布。
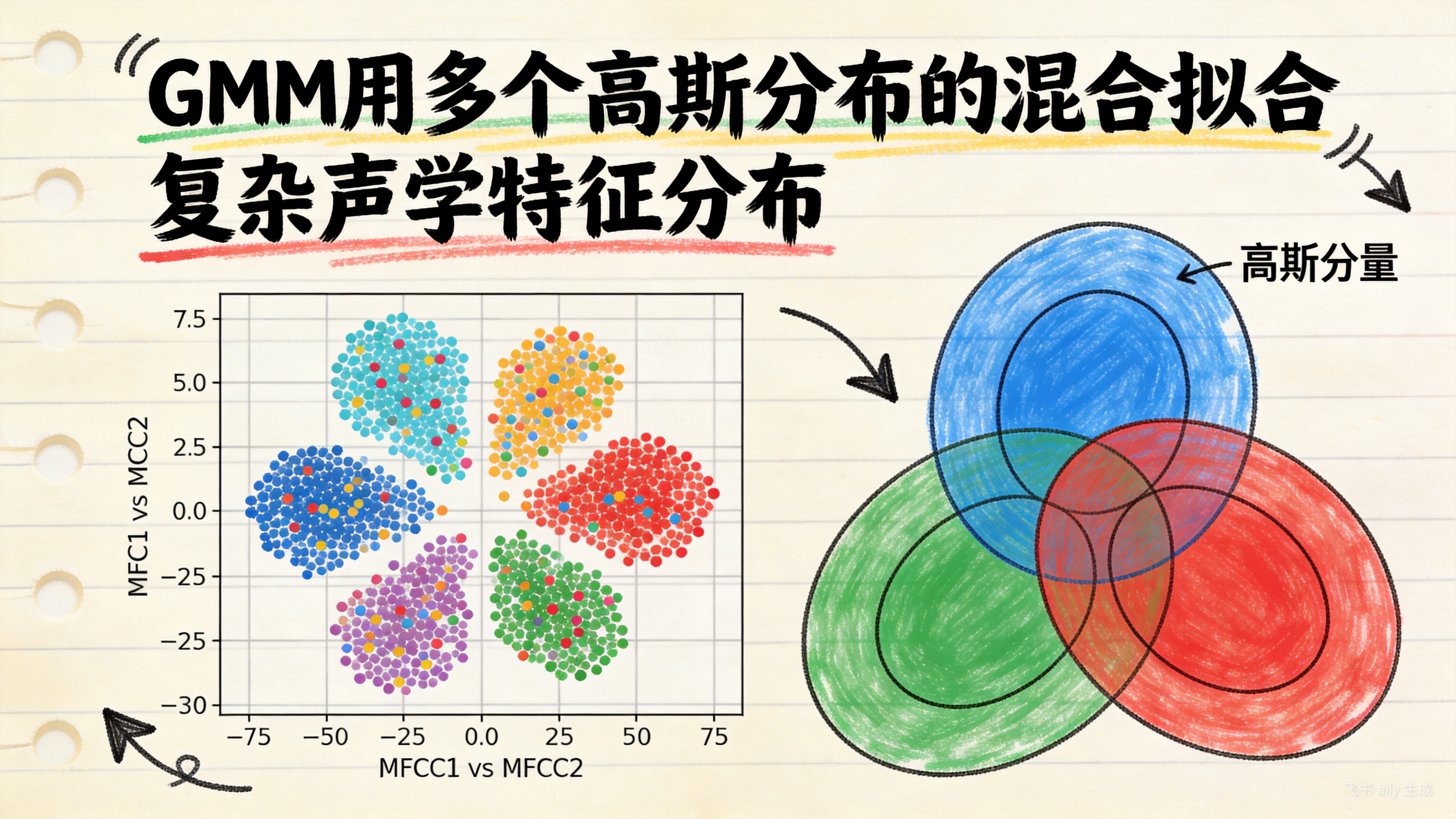
GMM用多个高斯分布(椭圆)的混合来拟合一个音素的复杂声学特征分布
上图中,左侧的散点代表同一个音素/a/的众多发音样本在二维特征空间(如MFCC1和MFCC2)中的分布。可以看到,样本点形成了几个主要的聚集区。右侧的三个椭圆代表了三个高斯分量,它们通过不同的均值、协方差和权重(混合系数)组合在一起,共同覆盖了样本的分布区域。每个高斯分量可以理解为该音素的一种典型“发音原型”。
GMM的数学模型可以表示为:p(x)=k=1Kπk⋅N(x|μk,Σk)![]() 其中,$K$是分量数,$\pi_k$是第$k$个分量的权重,$\mathcal{N}表示高斯分布,
其中,$K$是分量数,$\pi_k$是第$k$个分量的权重,$\mathcal{N}表示高斯分布,![]() \boldsymbol{\mu}_k$和$\boldsymbol{\Sigma}_k$分别是其均值和协方差。
\boldsymbol{\mu}_k$和$\boldsymbol{\Sigma}_k$分别是其均值和协方差。
通过期望最大化(EM)算法,可以从大量标注了音素的语音数据中,自动学习出每个音素对应的GMM的所有参数(πk,μk,Σk![]() )。训练完成后,这个GMM就成为了该音素的“概率密度画像”。在识别时,对于输入的一帧特征向量$\mathbf{x}_t$,GMM可以计算出它属于该音素的似然度 p(xt|音素)
)。训练完成后,这个GMM就成为了该音素的“概率密度画像”。在识别时,对于输入的一帧特征向量$\mathbf{x}_t$,GMM可以计算出它属于该音素的似然度 p(xt|音素)![]() ,这个分数将成为后续时序解码的关键依据。
,这个分数将成为后续时序解码的关键依据。
简单GMM训练代码示意(Python伪代码):
import numpy as np
from sklearn.mixture import GaussianMixture
# 假设 features 是一个 N x D 的数组,包含某个音素的所有训练样本特征(N个样本,D维MFCC)
# 例如,从对齐数据中提取出的所有 /a/ 音素的特征
features_a = load_features_for_phoneme("/a/")
# 初始化一个包含3个分量的GMM
gmm_a = GaussianMixture(n_components=3, covariance_type='diag', max_iter=200)
# 使用EM算法进行训练
gmm_a.fit(features_a)
# 训练后,模型参数已就绪:
# gmm_a.weights_ 对应 π_k (混合权重)
# gmm_a.means_ 对应 μ_k (均值向量)
# gmm_a.covariances_ 对应 Σ_k (协方差矩阵)
# 计算新特征向量的似然度(对数似然)
new_feature = extract_mfcc(audio_frame)
log_likelihood = gmm_a.score_samples([new_feature]) # 得到 p(x_t | /a/)HMM部分:描述语音的‘时间线’
GMM解决了“某一帧声音像哪个音素”的问题,但语音是随时间流动的。音素之间存在协同发音效应,且每个音素的持续时间可变。隐马尔可夫模型(HMM) 正是用来对这种时序动态变化进行建模的利器。
HMM基于两个基本假设:1) 齐次马尔可夫性:当前状态只依赖于前一个状态;2) 观测独立性:当前观测只依赖于当前状态。在语音识别中,一个HMM通常被用来建模一个音素(或一个词)。为了更精细地描述音素的发音过程,一个音素常被拆分为3-5个状态,分别对应发音的起始、稳定、结束等阶段。
|
HMM的核心要素
|
音素 /a/ 的3状态HMM示例
|
语音识别中通常采用从左到右的Bakis模型作为HMM的拓扑结构,禁止状态回跳,这符合语音发音的单向时序特性。
HMM状态转移矩阵示例(Python代码):
import numpy as np
# 定义一个3状态Bakis型HMM的转移概率矩阵A
# A[i, j] 表示从状态i转移到状态j的概率
transition_matrix = np.array([
[0.6, 0.4, 0.0], # 从状态0:60%自循环,40%转到状态1,0%转到状态2(禁止跳转)
[0.0, 0.7, 0.3], # 从状态1:0%回退,70%自循环,30%转到状态2
[0.0, 0.0, 1.0] # 从状态2:0%回退,0%回跳,100%自循环(或视为终止状态)
])
# 初始状态概率π:通常从状态0开始
initial_prob = np.array([1.0, 0.0, 0.0])
print("转移矩阵A:")
print(transition_matrix)
print("\n初始概率π:")
print(initial_prob)协同作战:HMM-GMM的完整识别流程
至此,我们拥有了两大武器:描述“静态声音画像”的GMM和描述“动态时间线”的HMM。在一个完整的HMM-GMM识别系统中,GMM扮演着HMM的观测概率发生器角色。具体来说,为HMM的每个状态$s$都训练一个专属的GMM,用于计算在该状态下观察到特征$\mathbf{x}_t$的概率$p(\mathbf{x}_t | s)$。
识别任务(解码)可以形式化为:给定一段语音的特征序列$\mathbf{X} = (\mathbf{x}_1, \mathbf{x}_2, ..., \mathbf{x}_T)$,寻找最可能产生这个观测序列的HMM状态序列(进而得到词序列)。这需要搜索一个巨大的解空间。
维特比(Viterbi)算法是解决这一搜索问题的核心动态规划算法。它在由“时间帧”和“HMM状态”构成的网格中,高效地寻找一条累计概率最大的路径。
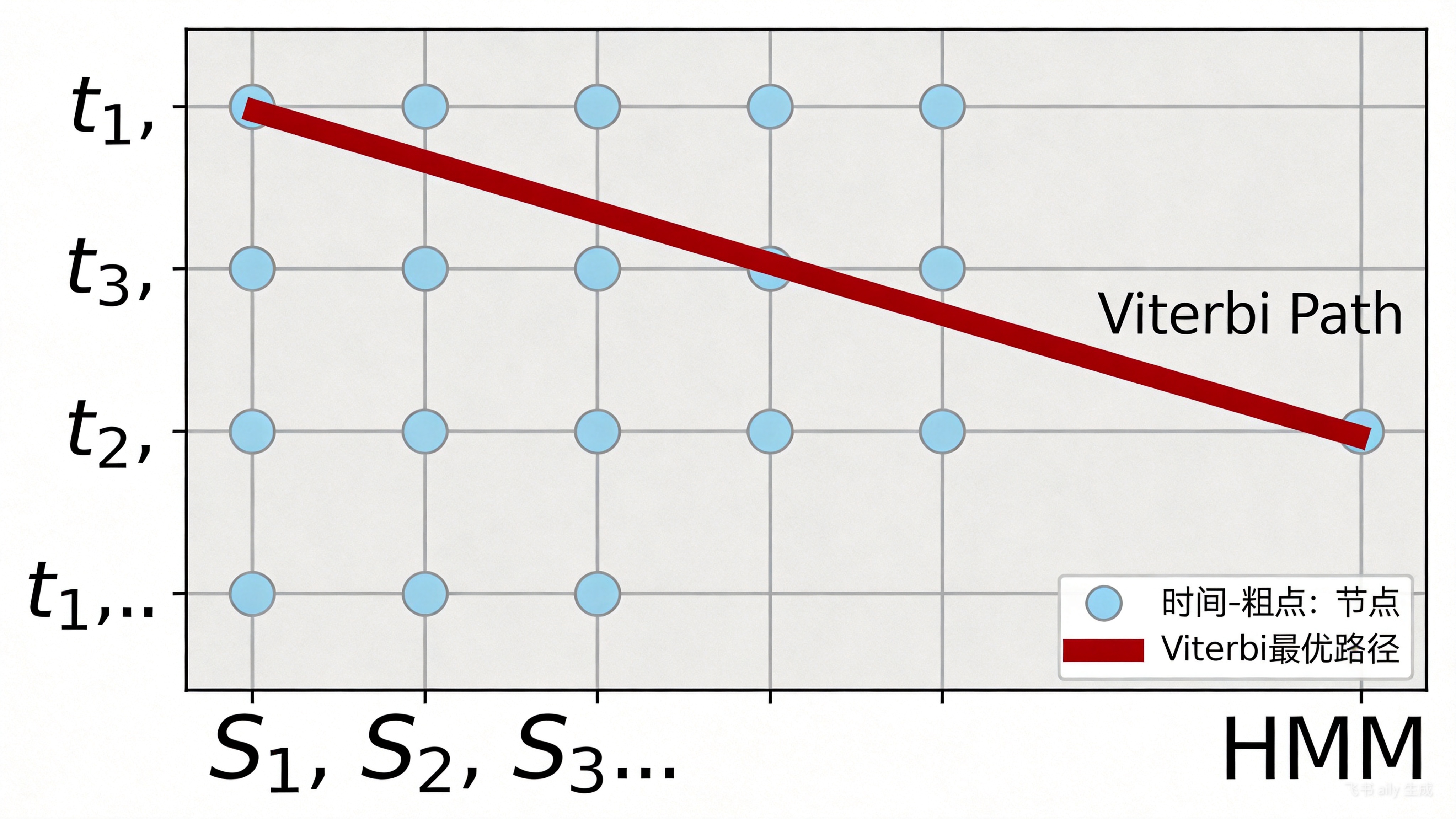
Viterbi算法在时间-状态网格中动态搜索最优路径
算法核心是两步递推:
- 路径概率积累:在每一时刻$t$,对于每个状态$j$,计算从起始时刻到$t$时刻且以状态$j$结束的所有路径中的最大概率$\delta_t(j),并记录最优路径的前驱状态
 \psi_t(j)$。
\psi_t(j)$。
- 路径回溯:在最终时刻$T$,选择概率最大的状态,然后根据$\psi$指针向前回溯,即可得到全局最优的状态序列。
完整的识别流程可分解为以下步骤:
- 特征提取:输入语音经过MFCC处理,得到特征序列$\mathbf{X}$。
- 构建词图:根据发音词典,将待识别的候选词(由语言模型提供)转换为音素序列,再将每个音素的HMM按顺序拼接,形成每个候选词对应的复合HMM。
- Viterbi解码:对于每个候选词的HMM,使用Viterbi算法计算它“生成”观测序列$\mathbf{X}$的概率$P(\mathbf{X} | \text{候选词HMM})$。
- 结合语言模型:将上述声学模型得分与语言模型给出的先验概率$P(\text{候选词})$结合(通常取对数相加),得到最终得分。
- 输出结果:选择最终得分最高的候选词作为识别结果。
实战演练:以识别‘好’字为例
让我们将上述所有概念串联起来,看一个具体例子——识别单字“好”。
步骤一:特征提取用户说出“好(hao3)”,系统对录音进行预处理,得到MFCC特征向量序列:[F1, F2, F3, ..., FT],共T帧。
步骤二:构建‘好’字的复合HMM
- “好”的拼音是hao3,对应音素序列:/h/, /a/, /u/。
- 假设每个音素使用3状态HMM建模。
- 将这三个音素的HMM按顺序拼接,得到一个总共9个状态的复合HMM,其状态转移被约束为依次通过/h/的3个状态、/a/的3个状态、/u/的3个状态。
步骤三:帧级别似然度计算对于每一帧特征Ft,系统利用预先训练好的GMM模型库,计算它属于上述9个状态中每一个状态的似然度,即$p(F_t | \text{状态}_i), i=1,...,9$。例如,第5帧可能在第4个状态(/a/的稳定状态)上得分最高。
步骤四:Viterbi搜索最优路径系统在9个状态 x T个时间帧的网格上运行Viterbi算法。算法会综合考虑:
- 转移概率:从一个状态跳转到下一个状态的概率(由HMM的转移矩阵定义)。
- 发射概率:每一帧在每个状态上的似然度(由GMM计算得出)。最终找出一条从开始到结束、累计乘积概率(或对数概率和)最大的状态序列路径。
步骤五:路径到文本的映射回溯找到的最优状态序列。例如,路径为[状态1(h), 状态2(h), 状态3(h), 状态4(a), 状态5(a), 状态6(a), 状态7(u), 状态8(u), 状态9(u), ...]。根据状态与音素的对应关系,映射回音素序列/h/ /a/ /u/,再通过发音词典映射为汉字“好”。识别完成。
对于更复杂的词句,如“你好”,系统会构建更长的复合HMM(由“你”和“好”的音素HMM拼接),并在更大的网格上进行搜索,原理完全相同。
HMM-GMM的功与过:核心优缺点分析
HMM-GMM框架在语音识别史上留下了不可磨灭的印记,其贡献与局限都非常鲜明。
|
对比维度 |
HMM-GMM |
DNN-HMM(过渡) |
端到端模型(如RNN-T) |
|
核心建模方式 |
GMM(浅层模型) + HMM(时序) |
DNN(深层模型) + HMM(时序) |
单一深度神经网络(如RNN, Transformer) |
|
对帧独立假设 |
强假设:假设帧间声学特征独立。 |
弱化:DNN可通过长时上下文窗口缓解。 |
无:直接建模序列到序列的依赖。 |
|
需要音素对齐 |
必需:训练GMM需音素级强制对齐。 |
训练时需要:用于训练DNN分类目标。 |
非必需:可直接用(词/子词)文本标签训练。 |
|
声学模型容量 |
有限,对复杂模式刻画能力不足。 |
强大,深度学习带来表征能力飞跃。 |
极强,且能与语言建模深度融合。 |
|
训练复杂度 |
相对较低,模块可分开训练。 |
高,需大量数据和GPU资源训练DNN。 |
很高,需要海量数据与强大算力。 |
|
工业成熟度(历史) |
极高:技术非常成熟,工具链完善。 |
高:曾是工业主流,现仍广泛使用。 |
快速提升中,已成为当前研发前沿。 |
优点总结:
- 数学框架清晰优雅:将复杂问题分解为声学模型(GMM)、发音词典、语言模型三个可独立优化、调试的模块。
- 数据效率相对较高:在小规模数据集上也能获得可用的模型,对数据标注量的要求低于深度学习。
- 可解释性与可控性强:每个模块功能明确,错误易于追踪和修复。可以方便地注入领域知识(如调整发音词典)。
- 奠定了工程基础:催生了HTK、Kaldi等经典开源工具,其代码和配方至今仍是学习语音识别的重要资源。
缺点与局限:
- 强独立性假设不符合语音本质:GMM假设各帧声学特征独立,这与语音天然的连续性、上下文相关性相悖。
- 建模能力天花板低:GMM作为浅层生成模型,其表征能力有限,难以刻画复杂和高维的声学模式。
- 依赖精细对齐:训练需要音素级别的强制对齐信息,这本身就是一个需要大量人力或复杂预处理步骤的难题。
- 模块化导致信息损失和错误传播:声学模型与语言模型分开训练,无法进行端到端的联合优化,且前一模块的错误会传递给后一模块。
这些局限性,尤其是建模能力的不足,最终推动了语音识别技术向基于深度学习的范式演进。
理解HMM-GMM是构建完整语音识别知识体系的关键一环。若想深入实践或迈向现代技术,以下资源和建议可供参考。
经典工具链
- HTK (Hidden Markov Model Toolkit):HMM-GMM时代的标志性工具,由剑桥大学开发。它完整实现了从特征提取、HMM训练到解码的整个流程,是学习传统流程的经典教材。
- Kaldi:由Daniel Povey等人开发的开源工具包,堪称语音识别领域的“瑞士军刀”。它虽然以HMM-GMM起家,但无缝集成了DNN、RNN、Transformer等现代模型。其丰富的GMM-HMM配方脚本,是动手实践和理解整个训练解码流水线的最佳入口。
学习路径建议
- 夯实基础:学习数字信号处理(语音信号基础)、概率论与数理统计(HMM/GMM理论基础)、机器学习(EM算法等)。
- 动手实践:在Linux环境下搭建Kaldi,运行其自带的egs/yesno或egs/timit等简单示例。从头到尾走通数据准备、特征提取、单音素GMM-HMM训练、三音素GMM-HMM训练、解码测试的完整流程,观察日志和结果。
- 深入现代:在理解GMM-HMM的基础上,学习Kaldi中的DNN-HMM配方(如nnet1, nnet2),进而探索端到端模型,如基于CTC、RNN-T或Transformer的模型。
经典论文与书籍推荐
- 经典教程:Lawrence Rabiner的 A Tutorial on Hidden Markov Models and Selected Applications in Speech Recognition [1]。这篇论文是理解HMM及其在语音中应用的必读文献。
- 权威书籍:Xuedong Huang, Alex Acero, Hsiao-Wuen Hon 所著的 Spoken Language Processing: A Guide to Theory, Algorithm, and System Development [2]。内容全面,涵盖从基础到HMM-GMM的详细内容。
- 工具书:Daniel Povey等人的 The Kaldi Speech Recognition Toolkit [3] 以及Kaldi官方文档。
|
行动指南:理解HMM-GMM的最佳方式是“动手运行一个Kaldi配方”。从egs/mini_librispeech或egs/wsj等数据集的GMM-HMM基线开始,你能亲眼看到单音素模型如何初始化、如何通过强制对齐迭代优化、三音素模型如何引入上下文信息、以及最终的解码图是如何构建和搜索的。这是将理论转化为实践认知的关键一步。 |

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 8
8 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)