图纸找不到、版本搞混、流程卡住——智橙AI如何一次解决三大研发痛点
周五下午,结构工程师老张接到了一通紧急电话。
客户要一张三个月前交付的零部件图纸,立刻要。
老张登进PLM,在文件夹树里一层层翻,换了三组关键词检索,跳出来的全是不相干的东西。半小时过去了,客户已经在催第二次了。他满头是汗。
同一栋楼,别的层。生产部的物料计划员盯着屏幕发呆——手里的BOM清单,某个零件编号和系统里对不上。
往上一查,设计部昨天改了一版,新版本还没同步到生产端。车间按旧版BOM备的料已经下了。三百多公斤的型材,切都切了。
三楼会议室更惨。一个ECN变更评审在OA里挂了整整四天,卡在工艺部门主管那里。提交人打了两通电话催,主管说这两天项目太多忙忘了。可下游的工装设计和采购全部堵在这个评审结果上,谁也动不了。
三个场景,发生在不同的部门,不同的时间段,看上去互不相干。
但指向的是同一个根本问题——研发数据管理的效率和准确性,远远跟不上制造业企业对响应速度的刚性要求。
图纸散落在各种系统和个人文件夹里,版本信息全靠人工逐一核对,流程推动全靠反复打电话催办。这些环节中的任何一个掉链子,整个研发链条的效率都会被打折。
痛点一:找一张图纸,为什么比大海捞针还费劲?
图纸找不到。这件事没做过制造研发的人,很难理解它有多痛。
PLM的文件夹树动辄几百层。一个项目从立项到量产,图纸可能散落在十几个不同的目录下。
按项目编号存了一批,按零部件分类又存了一批,还有一部分在设计工程师自己的本地硬盘里,压根没上传到系统。
等到某天突然要调取某张图,你连应该去哪个目录找都不知道。
文件命名不规范,是这个行业的老毛病了。
同一个零件,结构组叫“底座”,系统组登记的是“基板”,PLM里存的实际文件名可能是“BASE_001_V2_最终版”。
你用任何一个关键词去搜,都有可能漏掉正确的那张。更头疼的是,很多PLM的检索只支持文件名和属性字段,做不到内容语义层面的理解。
你记得那张图纸上画了一个带法兰接口的泵体,但系统不会因为你输入“法兰泵体”就把它从几万张图纸里捞出来。
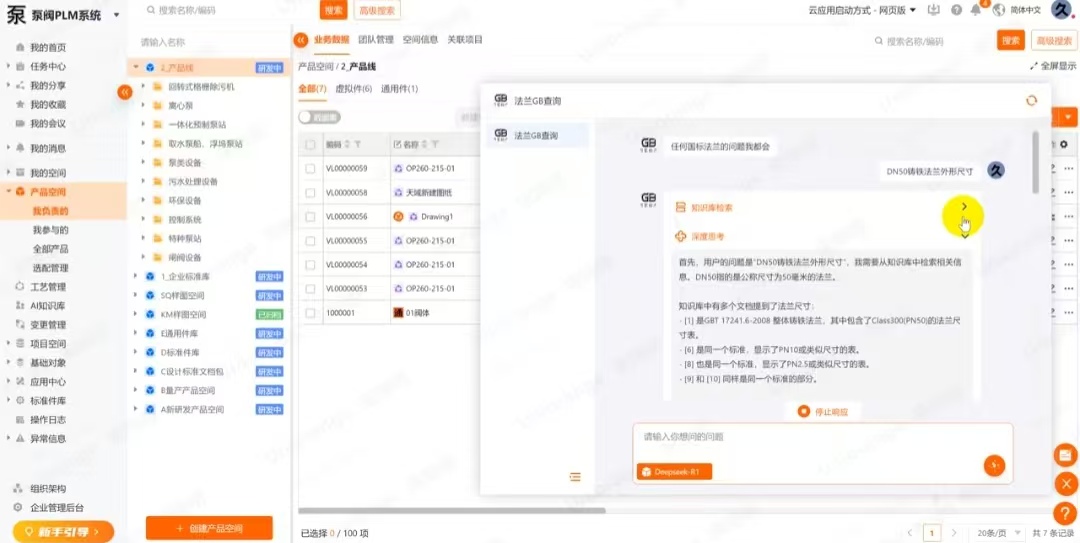
智橙PLM的“智搜”功能,就是在攻克这个难题。
工程师可以用自然语言直接描述自己想找什么。不用记文件名,不用翻目录树,甚至不用知道编号。
你只需要像平时说话那样输入一句描述——比如“上个月王工提交的那个带法兰接口的泵体零件图”——系统就能理解你的意图,跨数据库、跨项目、跨版本地全面检索,把最匹配的结果直接推到你面前。
举个实际的例子。某汽车零部件企业的设计主管要准备一场客户评审会,需要调出过去两年内所有和某款变速箱相关的工程图和三维模型。
按原来的做法,至少要安排三个工程师分别去不同的项目文件夹里翻,预计花半天时间。
用智搜,他只输入了一句话:“2024年至今,所有包含SA-200变速箱关键词的工程图纸和三维模型”。十秒钟,检索结果按相关度排序直接呈现。哪几张是最新的、哪些是历史归档,清清楚楚。
这背后靠的是智橙对研发数据的深度语义建模。
系统不是在做简单的字符串匹配,而是在理解你输入的每一句话的真正含义。
同时从结构化数据——属性字段、BOM层级——和非结构化数据——文档内容、图纸标注、技术说明——两个维度去搜索,给出综合排序的结果。
找图纸这件事,不应该成为一个需要“经验”和“运气”才能完成的工作。
痛点二:版本混乱,一次失误可能烧掉几十万
BOM版本不一致。在制造企业里,这是最让人后背发凉的问题之一。
为什么怕?因为版本一旦搞混,后果远不止改一个文件那么简单。
生产部门按旧版BOM备了料、下了单,零件加工完才发现设计已经改了。那批料可能直接报废。更极端的情况是,错误版本的零部件已经装配到成品上发到了客户手里,退换货的成本和品牌信誉损失根本无法用钱衡量。
这种混乱怎么产生的?很多企业的PLM虽然自带版本管理模块,但版本之间的关联性校验主要依赖人工。
设计工程师改了某张零件图,需要手动更新对应BOM,手动检查装配图引用,手动通知下游部门。一次变更可能牵涉几十甚至上百个关联文件的同步更新,全靠人逐一核对——不出错才叫见了鬼。
智橙PLM的AI校验引擎,就是要把这个“靠人盯”的环节变成系统自动执行。
当任何一张图纸或任何一个BOM条目发生变更时,AI校验引擎会立刻启动全链路扫描。
上下游装配关系、BOM层级、工艺卡片、质量检验标准,逐一核对数据一致性。
发现不一致的地方,系统立刳生成预警,精确标注冲突点并给出修正建议。版本管理系统同时自动维护完整的变更历史链路,谁在什么时间改了什么、修改依据是什么、影响了哪些下游文件,每一步都有据可查。
看个具体场景。一家做工业阀门的企业对某款核心阀体的密封槽做了微调,图纸修改提交审核后,AI校验引擎在几秒内检测到三处不一致:第一,BOM中密封圈的规格参数没有同步更新;第二,关联的工装夹具设计图引用的还是旧版尺寸;第三,供应商收到的采购规格书还是变更前的版本。
三条预警同时推送到设计、工艺和采购三个部门的工作台上。所有人同步拿到信息,同步修正。一个环节没漏。
如果同样的校验交给人工做,至少要拉三个部门开一次碰头会。
时间成本大家都知道,但更关键的问题在于——谁也没法保证坐在会议室里的几个人一定能把所有关联点全部想到。
AI校验不是替代人的判断,而是在人做出判断之前,先把所有需要关注的问题完整地摆到桌面上。
痛点三:流程审批卡壳,等不起的从来不是流程本身
做过研发管理的人,对这种场面一定不陌生。
一个ECN提交上去,在某个审批人的节点一躺就是好几天。审批人可能在出差,可能手头项目太多忘了看,也可能就是纯粹没留意。
提交的人催急了怕得罪人,不催下游全都在干等。本来一天能走完的流程,硬生生拖了一周。
表面上看是“审批人不及时处理”的问题。往深了想,真正的根源在于流程本身缺乏自动推动的能力。审批人的工作台上堆了几十条待办,没有优先级排序,没有超时预警,没有任何东西帮他判断哪件事最紧急。
他只能凭感觉和记性去处理,遗漏和延迟几乎是必然结果。
智橙PLM的“智驱”功能,核心逻辑就是让流程自己跑起来。具体做了三件事。
第一,智能提醒。当一条流程流转到某个审批节点时,系统不是简单地在待办列表里加一条记录完事。
它会根据这条流程关联的项目交付节点、上下游等待状态、历史审批耗时等数据综合评估紧急程度,给审批人一个明确的优先级建议。同时通过企业微信、钉钉、站内消息多渠道同步推送,确保信息触达到位。
第二,超时自动升级。某个审批节点在预设时间内没有处理?系统自动触发升级——先提醒审批人本人,再抄送直属上级,必要时直接推动流程到下一环节或指定替补审批人。
整个过程有完整日志,不需要任何人手动干预。
第三,流程瓶颈分析。系统会持续追踪每条流程在各节点的实际停留时间,定期生成分析报告。哪些环节是瓶颈,哪些审批人的工作量严重不均,流程的设计本身有没有优化空间——数据会说话。
举个例子。某电子制造企业的研发部,上线智驱之前,一个ECN的平均审批周期是6.8个工作日,其中大约40%的时间纯粹消耗在等待审批上。
上线后第一个月,平均周期缩短到了3.2天。超时升级机制全面启用后的第二个月,进一步压缩到了2.1天。
其中一个关键的优化点:系统通过数据分析发现,工艺部门的两名工程师审批量严重失衡,一个人抗了将近四分之三的单子。重新分配后,这个环节的拥堵问题彻底消失。
流程提速的价值,不仅仅是“快了几天”这么简单。它意味着研发团队能更快地响应客户的紧急需求,更快地将设计变更落地到生产线,更快地完成一轮又一轮的产品迭代。
在制造业竞争越来越卷的大环境下,这个“快”字,就是实打实的竞争力。
把这三个痛点放在一起看,你会发现一件有意思的事。
图纸找不到,根源是数据缺乏智能组织能力。
版本搞混,根源是数据缺乏智能关联和自动校验能力。
流程卡住,根源是数据缺乏智能流转能力。归根结底,都是研发数据管理这根弦没绷紧。
好消息是,解决这些问题并不需要推翻现有的PLM系统另起炉灶。
企业已经在PLM里积累了大量的研发数据——项目文件、图纸、BOM、工艺卡片、变更记录。
这些数据本身有价值,只是缺一个足够聪明的引擎来驱动它们。让搜索变得更懂人话,让校验变得全自动化,让流程变得更主动。
不需要上一套复杂的新系统,只需要让现有的PLM变得更聪明。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 4
4 0
0- 0



 已为社区贡献23条内容
已为社区贡献23条内容

所有评论(0)