3工程师5个月0手写代码,竟交付百万级代码库?揭秘AI Agent爆产背后的“套件工程”革命!
本文揭秘了OpenAI惊人实验背后的真相——并非AI模型突破,而是工程范式的转变。文章提出“套件工程”(Harness Engineering)概念,即通过设计约束机制、反馈回路和工作流控制,确保AI Agent的可靠性。核心内容涵盖上下文架构、Agent专业化、持久化记忆和结构化执行四大支柱,并辅以OpenAI、Anthropic、Stripe等实战案例,强调工程师角色将从代码编写转向环境设计与系统编排。文章最后提供开源工具与框架推荐,旨在帮助团队快速落地Harness Engineering,实现AI Agent的高效稳定产出。
当 3 名工程师用 5 个月交付了 100 万行代码、1500 个 PR,却一行代码都没手写——这不是魔法,而是工程范式的彻底转变。
01 导语:为什么 AI Agent 总是"Demo 惊艳、量产崩溃"?
2025 年 8 月,OpenAI 公开了一个震撼行业的实验:
- 3 名工程师
- 5 个月
- 0 行手写代码
- 约 100 万行代码
- 约 1500 个 PR 合并
这是什么概念?按传统工程效率,这相当于一个中型团队一年的产出。但背后的真相更值得深思:AI Agent 不是突然变强了,而是有人为它设计了一套精密的"套件系统"。
现实中的另一面却触目惊心:无数团队兴奋地接入 GPT-4、Claude,写出漂亮的 Demo,然后发现——
进入量产阶段,Agent 开始上下文耗尽、目标漂移、级联幻觉。Demo 到生产的转化率,低得可怜。
问题的核心不在于模型不够强大,而在于缺少 Harness——让蛮力保持在正确轨道上的约束机制。

02 什么是 Harness Engineering
核心定义
Harness Engineering(套件工程):围绕 AI Agent 设计和构建约束机制、反馈回路、工作流控制和持续改进循环的系统工程实践。
解决的核心问题是:如何确保 AI Agent 输出的可靠性、一致性和长期可维护性。
Harness 的本意
"Harness"本意是马具——把马的蛮力引导到正确的方向上。LLM 就像一匹力气巨大但方向感不强的马,跑得快但容易跑偏。
三层演进关系
| 层级 | 定位 | 说明 |
|---|---|---|
| Prompt Engineering | 基础指令设计 | 提示词编写与优化 |
| Context Engineering | 给 Agent 看什么 | 上下文管理与注入 |
| Harness Engineering | 系统怎么防崩、怎么量化、怎么修 | 约束机制与反馈循环 |
Prompt Engineering 是基础,Context Engineering 决定给 Agent 什么信息,而 Harness Engineering 决定了系统如何防止崩溃、如何量化进展、如何修复错误。三层层层递进,构成完整的 Agent 工程体系。

03 为什么模型能力不是瓶颈
颠覆认知的量化证据
| 实验 | 结果 |
|---|---|
| Can.ac 实验 | 仅改变 Harness 工具格式,Grok Code Fast 1 从 6.7% 跳到 68.3% |
| LangChain Terminal Bench | 同一模型靠 Harness 改进,Terminal Bench 2.0 从 42% 跃升至 78% |
| LangChain Terminal Bench | 同模型排名从第 30 名跳到第 5 名 |
同一个模型,换了一套 Harness 工具,能力提升 10 倍。这说明什么?
真正卡住 Agent 的不是模型智能,而是围绕它的结构、工具和反馈机制跟不上。
Agent 三大死亡陷阱
陷阱一:One-shotting(一波流)
Agent 试图在一个上下文窗口内完成所有任务,上下文耗尽后留下大量半成品。下一次新会话面对的是一个状态未知的烂摊子。
陷阱二:目标漂移(Goal Drift)
Agent 在执行过程中逐渐偏离原始目标,用更多的代码去弥补之前的错误,最终导致级联灾难。
陷阱三:级联幻觉(Cascading Hallucination)
一次小错误引发一连串的"修复",每一轮"修复"又引入新的错误,最终输出完全偏离需求。
HumanLayer 的工程团队花了一年多时间观察 hundreds of 编码 Agent 的失败模式,发现了几个反复出现的共性问题:
- 需求不明确时不主动澄清,而是凭猜测继续执行;
- 不检查边界条件,走到哪里算哪里;
- 无法验证结果是否正确,在偏离轨道时毫无知觉地继续;
- 遇到错误就卡住,而不是尝试替代方案。
上下文窗口的甜蜜区间
经验法则:上下文填到约 40% 就开始走下坡路,之后进入"Dumb Zone"。
| 区间 | 表现 |
|---|---|
| Smart Zone(前 40%) | 聚焦、准确的推理 |
| Dumb Zone(超过 40%) | 幻觉、循环、格式错误的工具调用、低质量代码 |
给 Agent 塞一堆 MCP 工具、冗长文档和累积对话历史,不会让它更聪明——反而会让它变笨。
04 四大支柱
支柱一:上下文架构(Context Architecture)
核心原则:Agent 应当恰好获得当前任务所需的上下文——不多不少。
分层加载机制:
| 层级 | 加载时机 | 内容示例 |
|---|---|---|
| Tier 1 | 每次会话自动加载 | AGENTS.md、项目结构概览 |
| Tier 2 | 特定子 Agent 被调用时 | 专业化 Agent 的上下文、领域知识 |
| Tier 3 | Agent 主动查询时 | 研究文档、规格说明、历史会话 |
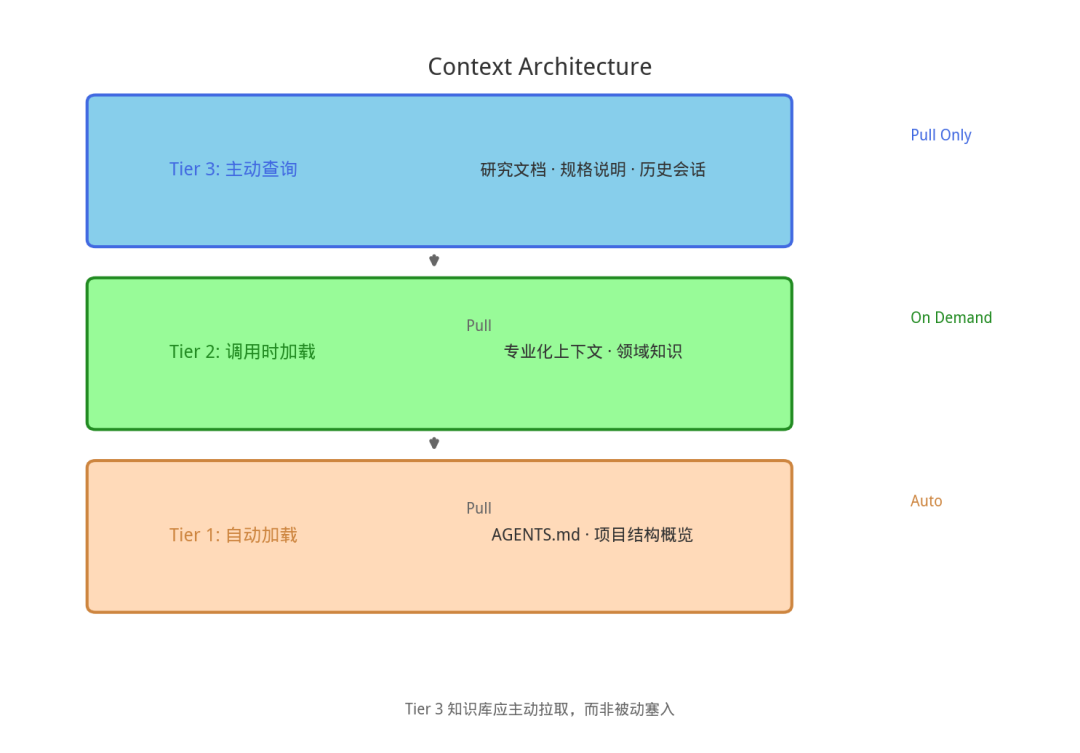
关键洞察:上下文不是越多越好。Tier 3 的知识库应该是 Agent "主动拉取"而非"被动塞入"的。
支柱二:Agent 专业化(Agent Specialization)
核心原则:专注于特定领域、拥有受限工具的 Agent 优于拥有全部权限的通用 Agent。
实践中的角色分工:
| Agent 角色 | 职责范围 | 工具权限 |
|---|---|---|
| 研究 Agent | 探索代码库、分析实现细节 | 只读(Read, Grep, Glob) |
| 规划 Agent | 将需求分解为结构化任务 | 只读,无写入权限 |
| 执行 Agent | 实现单个具体任务 | 限定范围的读写权限 |
| 审查 Agent | 审计完成的工作,标记问题 | 只读 + 标记权限 |
| 调试 Agent | 修复审查发现的问题 | 限定范围的修复权限 |
| 清理 Agent | 对抗熵积累,清理低质量代码 | 读写权限 |
单一通用 Agent 容易陷入"权限过大导致自我纠结"的困境。专业化分工让每个 Agent 的职责单一、边界清晰。
支柱三:持久化记忆(Persistent Memory)
核心原则:进度必须持久化在文件系统上,而非依赖上下文窗口的记忆。
每次新 Agent 会话从零开始,通过文件系统制品重建上下文。不信任模型的记忆——这是 Harness Engineering 的第一法则。
Anthropic 两阶段方案:
| 阶段 | 操作 | 产出 |
|---|---|---|
| 初始化 | 创建 | feature_list.json(结构化任务清单)、init.sh(环境启动脚本)、claude-progress.txt(进度记录) |
| 编码 | 每次会话循环 | 读取进度文件 → 增量完成一个任务 → 更新进度文件 → git commit |
关键发现:使用 JSON 格式追踪 feature 状态比 Markdown 更有效。JSON 的结构化特性让 Agent 不太可能不恰当地修改——Agent 只能修改 passes 字段,而不会删除或篡改测试用例本身。
支柱四:结构化执行(Structured Execution)
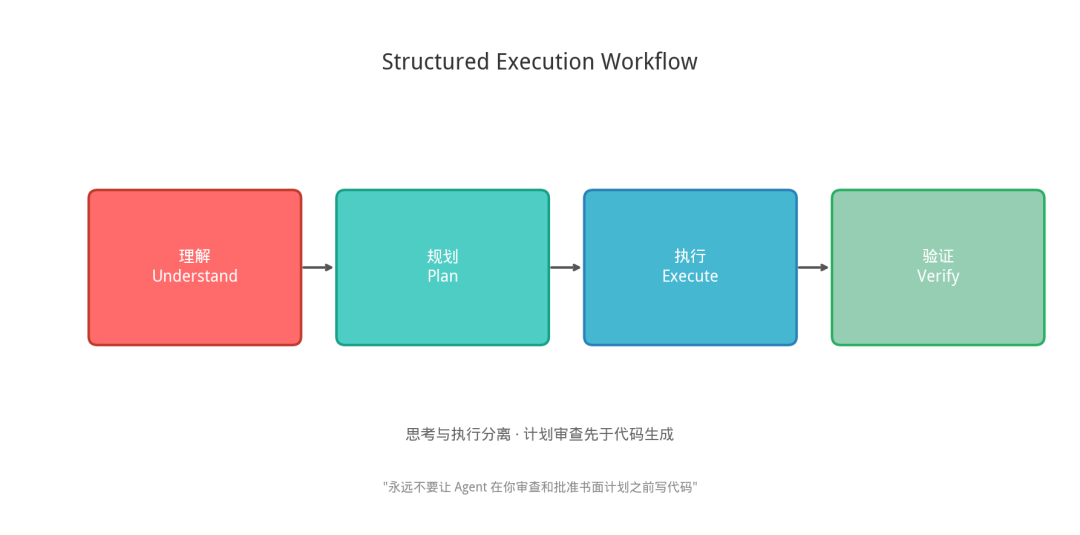
核心原则:将思考与执行分离。
执行序列:理解 → 规划 → 执行 → 验证
“永远不要让 Agent 在你审查和批准书面计划之前写代码。” —— Boris Tane
人工检查点的价值:审查计划远比审查代码快速。当规格正确时,实现自然可靠;当规格有误时,可以在 500 行代码生成之前及时纠正。
熵管理与"垃圾回收":
定期运行的"清理 Agent"负责:
- 扫描文档不一致
- 检测架构约束违规
- 清理冗余或低质量代码
05 实战案例
案例一:OpenAI 百万行代码实验
| 指标 | 数值 |
|---|---|
| 团队规模 | 3 名工程师 |
| 持续时间 | 5 个月 |
| 代码规模 | 约 100 万行 |
| 手写代码 | 0 行 |
| 合并 PR 数 | 约 1500 个 |
| 日均 PR/人 | 3.5 个 |
| 效率提升 | 约 10 倍 |
五大 Harness 原则:
- 设计环境,而非编写代码——诊断"缺少什么能力"并让 Agent 自己构建
- 机械化地执行架构约束——自定义 Linter 自动检测违规,文档记录不够
- 将代码仓库作为唯一事实源——所有团队知识放在仓库中,不在 Slack/Google Docs
- 将可观测性连接到 Agent——Chrome DevTools、日志/指标查询
- 对抗熵——后台 Agent 定期清理低质量生成物
核心洞察:工程师的角色从"写代码"转变为"设计环境"——构建让 Agent 能自我完成任务的系统。
案例二:Anthropic 16 Agent 构建 C 编译器
| 指标 | 数值 |
|---|---|
| 持续时间 | 约 2 周 |
| 并行 Agent 数 | 16 个 Claude Opus 4 实例 |
| Claude Code 会话数 | 约 2000 次 |
| Rust 代码量 | 100,000 行 |
| GCC torture test 通过率 | 99% |
| 可编译的真实项目 | 150+(PostgreSQL、Redis、FFmpeg、CPython、Linux 6.9 Kernel 等) |
| 总 API 成本 | 约 $20,000 |
关键 Harness 设计:
- 上下文窗口污染缓解:最小化控制台输出,日志写入文件,grep 友好的错误格式
- Agent 时间盲区:确定性测试子采样(随机 1-10%,但对单个 Agent 保持确定性)
- 专业化角色分工:编译器核心、去重、性能优化、文档
花 2 万美元,99% 通过 GCC torture test,覆盖 PostgreSQL、Redis、Linux Kernel——这在传统工程中可能需要一支团队一整年。
案例三:Stripe Minions 系统
Stripe 构建了一套连接到近 500 个工具的集中式 MCP 服务器:
- 隔离的预热 Devbox:每次任务在独立环境中执行
- 自主完成到 PR:开发者发起任务后,Agent 自主完成整个流程
- 人只在最后审查介入:大幅降低工程师的日常负担
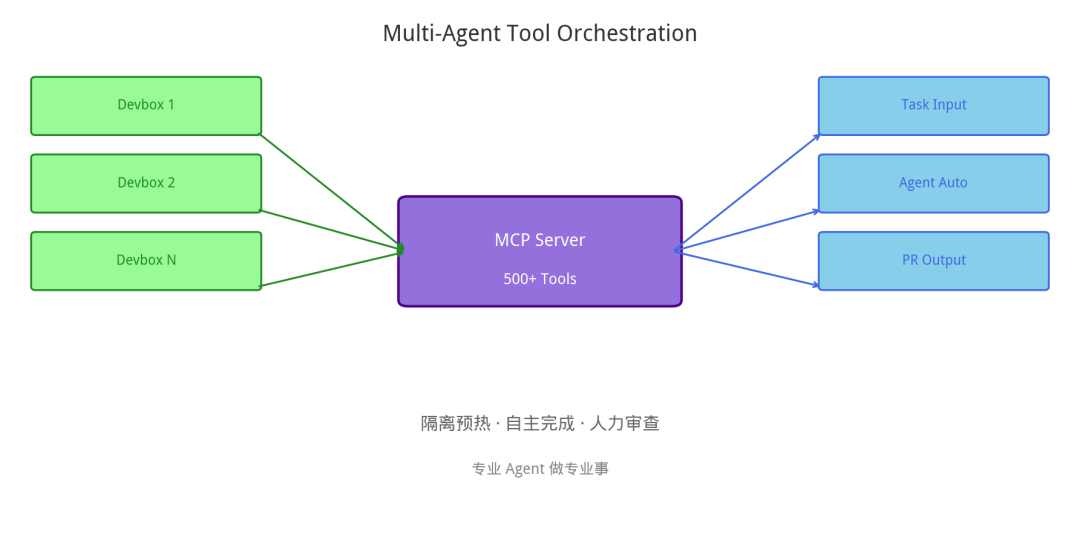
本质:把 500 个工具封装成 Agent 可控的工具链,让专业 Agent 做专业事。
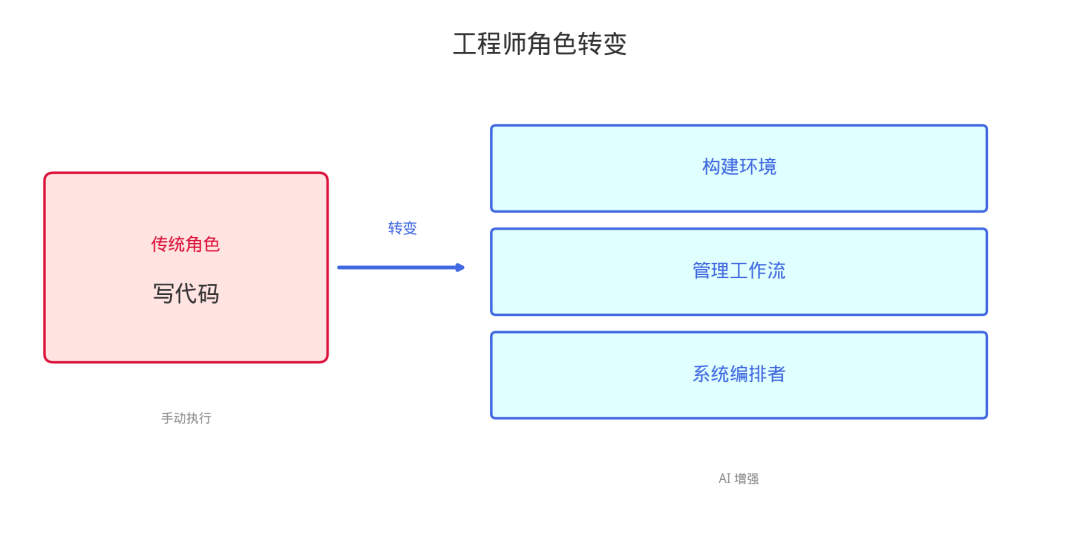
06 工程师角色的转变
| 传统角色 | 新角色 |
|---|---|
| 写代码 | 构建环境 + 管理工作流 |
| 手动实现功能 | 设计约束系统 |
| 代码执行者 | 系统编排者(System Orchestrator) |
Chad Fowler 用"Relocating Rigor"描述这个现象——严谨性没有消失,只是从写代码转移到了设计约束系统。
规划是新的编码。 在让 Agent 写代码之前,先花时间设计好计划、约束和反馈机制,往往事半功倍。
07 开源工具与框架推荐
以下项目均为开源,下载即用,按需选择。
🛠️ 拿来就能用的框架
Letta(原 MemGPT)⭐ 22k Stars
有状态记忆的 Agent 框架,Harness 工程中记忆层的参考实现。
| 指标 | 数值 |
|---|---|
| GitHub Stars | 22k |
| 核心特性 | 三层记忆架构(Core / Archival / Recall) |
| 代表产品 | Letta Code — Terminal-Bench #1 模型无关 Coding Agent |
| 安装 | pip install letta |
| 官网 | https://github.com/letta-ai/letta |
适用场景:需要 Agent 跨会话记住用户偏好、长期学习的场景。
OpenHarness(HKUDS)⭐ 新秀
最小实现的 Agent Harness 架构,兼容 Anthropic Skills 格式。
| 指标 | 数值 |
|---|---|
| 核心公式 | Harness = Tools + Knowledge + Observation + Action + Permissions |
| 亮点 | 兼容 anthropics/skills,复制 .md 文件到 ~/.openharness/skills/ 即可 |
| 安装 | pip install openharness |
| 官网 | https://github.com/HKUDS/OpenHarness |
适用场景:快速搭建自己的 Agent Harness,开发自己的工具链。
AutoAgent ⭐ 2026年4月新发布
让 AI 自动迭代 Harness 的元框架——给任务,跑一晚上,明天看分数。
| 指标 | 数值 |
|---|---|
| 核心思路 | meta-agent 自动修改 system prompt / tools / orchestration,跑 benchmark 保留涨分改动 |
| 每个任务结构 | task.toml(配置)+ instruction.md(指令)+ tests/(评测) |
| 评测方式 | 确定性检测 或 LLM-as-Judge |
| 官网 | https://github.com/kevinrgu/autoagent |
适用场景:有明确评测指标的任务型 Agent(代码生成、API 调用等)。
OpenClaw
多 Agent 协作框架,awesome-openclaw-agents 收录了大量预制 Agent,可直接部署。
| 预制 Agent | 用途 |
|---|---|
| 🐛 Bug Hunter | 错误分析与根因定位 |
| 🧪 API Tester | API 监控与健康检查 |
| 💸 Cost Optimizer | 云成本监控与优化建议 |
| ✅ Compliance Checker | 合规监控与截止日期追踪 |
| 安装 | 官网 |
|---|---|
pip install openclaw |
https://github.com/mergisi/awesome-openclaw-agents |
适用场景:需要多角色 Agent 协作的企业/团队场景。
📚 资源合集
| 列表 | Stars | 定位 |
|---|---|---|
| ai-boost/awesome-harness-engineering | 活跃更新 | 最全 Harness Engineering 资源汇总,含 AGENTS.md 模板 |
| walkinglabs/awesome-harness-engineering | 1.4k | 分类清晰的 Awesome List:记忆/约束/Evals/Benchmarks |
🔬 Benchmark 与效果验证
| 项目 | 说明 |
|---|---|
| Terminal-Bench | Coding Agent 标杆榜单,Letta Code 排名 #1 |
| Can.ac 实验 | 同一模型换 Harness 工具格式,准确率从 6.7% → 68.3%(10 倍提升) |
| LangChain Terminal Bench | 同模型排名从第 30 → 第 5 |
快速选型指南
| 需求 | 推荐 |
|---|---|
| 想快速落地 | OpenHarness / OpenClaw |
| 想让 Agent 有记忆 | Letta |
| 想自动优化 Harness | AutoAgent |
| 想了解全貌 | awesome-harness-engineering 合集 |
08 总结与行动清单
核心结论
Harness Engineering 是 AI Agent 时代工程范式的根本转变。
瓶颈不在模型智能,而在基础设施。模型越强大,Harness 反而越重要——因为更强的模型产生更大的破坏力,如果没有完善的约束系统,后果更严重。
“Agents aren’t hard; the Harness is hard.”
立即可行的行动清单
- 创建并维护
AGENTS.md(活文档,每次 Agent 犯错后更新) - 在仓库中建立单一事实源,放弃 Slack/Google Docs 中的知识孤岛
- 构建自定义 Linter,错误消息嵌入修复指令(而非仅标记违规)
- 为 Agent 提供端到端测试工具(Puppeteer MCP 等浏览器自动化)
- 实施增量执行策略:一次只做一个 feature,完成后更新状态
- 分层管理上下文(Tier 1/2/3),保持上下文利用率在 40% 以下
- 使用 JSON 格式追踪 feature 状态,而非 Markdown
- 建立定期"垃圾回收"机制,对抗熵增
成熟度评估
| 阶段 | 特征 | 工程师角色 |
|---|---|---|
| Level 0 | 无 Harness | 手动写代码 + 偶尔使用 AI |
| Level 1 | 基础约束 | 主要写代码,AI 辅助 |
| Level 2 | 反馈回路 | 规划 + 审查为主,部分 AI 编码 |
| Level 3 | 专业化 Agent | 环境设计 + 管理为主 |
| Level 4 | 自治循环 | 架构师 + 质量把关者 |
未来三年,软件工程最重要的分水岭,不是你用哪个模型,而是你为 Agent 搭建了怎样的 Harness。
常见问题 Q&A
Q:Harness Engineering 和传统 DevOps 有什么区别?
A:DevOps 主要关注人、流程和部署自动化;Harness Engineering 专注于 AI Agent 的行为约束、反馈回路和工作流控制。两者有重叠但核心关注点不同。
Q:小团队适合引入完整的 Harness 系统吗?
A:可以从 Level 1 开始——先建立 AGENTS.md 文档和简单的 feature 状态追踪。不必一开始就引入 16 个专业化 Agent。
Q:Harness Engineering 会取代工程师吗?
A:不会。它改变的是工程师的工作重心——从写代码转向设计环境、规划流程、管理系统。创造性问题解决和架构设计依然需要人类。
结语:抓住大模型时代的职业机遇
AI大模型的发展不是“替代人类”,而是“重塑职业价值”——它淘汰的是重复性、低附加值的工作,却催生了更多需要“技术+业务”交叉能力的高端岗位。对于求职者而言,想要在这波浪潮中立足,不仅需要掌握Python、TensorFlow/PyTorch等技术工具,更要深入理解目标行业的业务逻辑(如金融的风险控制、医疗的临床需求),成为“懂技术、懂业务”的复合型人才。
无论是技术研发岗(如算法工程师、研究员),还是业务落地岗(如产品经理、应用工程师),大模型都为不同背景的职场人提供了广阔的发展空间。只要保持学习热情,紧跟技术趋势,就能在AI大模型时代找到属于自己的职业新蓝海。
最近两年大模型发展很迅速,在理论研究方面得到很大的拓展,基础模型的能力也取得重大突破,大模型现在正在积极探索落地的方向,如果与各行各业结合起来是未来落地的一个重大研究方向
大模型应用工程师年包50w+属于中等水平,如果想要入门大模型,那现在正是最佳时机
2025年Agent的元年,2026年将会百花齐放,相应的应用将覆盖文本,视频,语音,图像等全模态
如果你对AI大模型入门感兴趣,那么你需要的话可以点击这里大模型重磅福利:入门进阶全套104G学习资源包免费分享!
扫描下方csdn官方合作二维码获取哦!

给大家推荐一个大模型应用学习路线
这个学习路线的具体内容如下:
第一节:提示词工程
提示词是用于与AI模型沟通交流的,这一部分主要介绍基本概念和相应的实践,高级的提示词工程来实现模型最佳效果,以现实案例为基础进行案例讲解,在企业中除了微调之外,最喜欢的就是用提示词工程技术来实现模型性能的提升

第二节:检索增强生成(RAG)
可能大家经常会看见RAG这个名词,这个就是将向量数据库与大模型结合的技术,通过外部知识来增强改进提升大模型的回答结果,这一部分主要介绍RAG架构与组件,从零开始搭建RAG系统,生成部署RAG,性能优化等

第三节:微调
预训练之后的模型想要在具体任务上进行适配,那就需要通过微调来提升模型的性能,能满足定制化的需求,这一部分主要介绍微调的基础,模型适配技术,最佳实践的案例,以及资源优化等内容

第四节:模型部署
想要把预训练或者微调之后的模型应用于生产实践,那就需要部署,模型部署分为云端部署和本地部署,部署的过程中需要考虑硬件支持,服务器性能,以及对性能进行优化,使用过程中的监控维护等

第五节:人工智能系统和项目
这一部分主要介绍自主人工智能系统,包括代理框架,决策框架,多智能体系统,以及实际应用,然后通过实践项目应用前面学习到的知识,包括端到端的实现,行业相关情景等

学完上面的大模型应用技术,就可以去做一些开源的项目,大模型领域现在非常注重项目的落地,后续可以学习一些Agent框架等内容
上面的资料做了一些整理,有需要的同学可以下方添加二维码获取(仅供学习使用)


AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 8
8 0
0- 0



 已为社区贡献149条内容
已为社区贡献149条内容

所有评论(0)