全链路语音大模型重磅迭代!三大合成模型限时免费,识别模型全面开源
还在吐槽 AI 配音机械生硬、音色同质化严重,日常语音转写方言听不懂、杂音干扰、双语混读识别错乱?随着人工智能技术持续深耕,全新升级版全链路语音模型矩阵正式上线,语音合成三大模型全面开放且限时免费,高精度语音识别模型同步开源发布。从语音生成到语音解析双向技术升级,全方位拉高通用级与专业级语音应用的体验标准。

本次迭代的语音合成系列共包含三款差异化模型,三者共用统一技术底座,具备一致的风格指令理解、音频标签调控、深度文本解析三大核心能力。依托自然语言描述就能精细化调控人声演绎效果,精准覆盖大众日常使用、自定义音色创作、专属声纹复刻三大主流创作场景,完美适配自媒体配音、有声内容制作、角色对话、文创创作等多元落地需求。
第一款为通用基础合成模型,内置多款高品质原生音色,无需复杂参数调试,开箱即可直接使用。模型支持语速调节、多类情绪切换、语气风格改动等精细化操作,兼顾日常播报、情感朗读、文案配音等常规场景,上手门槛低,普通用户也能快速制作自然流畅的真人感音频。
第二款为定制化音色设计模型,大幅降低专属音色创作门槛。仅需一句自然语言描述,即可快速生成全新原创音色,让音色设计流程更简化、创作方式更直观高效,轻松满足小众化、个性化、定制化的声音创作需求。
第三款为高保真声纹复刻模型,依托小样本深度学习技术,仅需少量人声素材,就能完成高还原度、高保真的目标音色复刻。同时完整保留风格指令、音频标签等全维度控制能力,复刻音色不丢失可调性,适合专属角色配音、定制化语音内容、个性化声纹使用等场景。
在核心技术层面,新一代语音合成模型完成三重能力升级,逻辑严谨且落地性拉满,实用性大幅提升。
一、高精度风格指令理解
模型可精准识别短句指令、长段文案描述,甚至完整剧本脚本内容,全面覆盖情绪表达、语气强弱、发声方式、文体风格等调控维度。无需编写复杂结构化参数,只需用通俗语言说明演绎要求,就能实现拟人化、情绪化的人声输出。针对有声读物、虚拟角色对话、剧情演绎等需要长期风格统一的场景,还支持剧本级分层结构化输入。人物设定、场景环境、表演要求可拆分编辑、自由组合,既能固定角色专属声线特质,又能单独控制单段台词的演绎方式,实现精细化内容创作。
二、细粒度音频标签调控
除了整篇文案的全局风格控制,模型新增行内嵌入式音频标签功能,可在文本指定位置精准切换情绪、调整发声状态、改变表达风格。标签兼容中英双语与开放式自定义描述,支持多标签叠加搭配、错落排布,复杂文案也能完成层次丰富的声音编排,在标签组合稳定性、细节表现力上表现优异。
三、强自主化文本理解能力
即便不添加任何提示词、控制标签,仅输入纯文字内容,模型也能自主挖掘文本内在逻辑。自动还原标点停顿、句式起伏,精准捕捉文案里的情绪转折与情感变化;同时智能识别文字背后的人物特征,包括年龄气质、角色定位等,自动匹配适配的发声风格,让普通文本转化为富有层次感、感染力的完整音频内容。
如果说语音合成是人工智能的声音输出端口,那么语音识别就是智能交互的核心听觉输入基座。本次同步开源的新一代识别模型,专门聚焦现实复杂应用环境,针对性解决语种切换、环境噪音、方言口音、多人对话等行业痛点,在多重复杂场景下的综合识别能力达到行业前沿水平,为智能交互、AI 智能体应用提供精准稳定的语音文字转化支撑。
该识别模型核心优势覆盖全场景刚需,适配各类复杂真实环境:
- 方言适配:全面覆盖吴语、粤语、闽南语、西南官话等主流地方方言;
- 复杂英文:适配多场景英文混杂对话,复杂语境识别准确率突出;
- 混读识别:支持中英混杂语句无缝转写,无需提前锁定语种类型;
- 歌词解析:可实现伴奏与人声叠加环境下的词曲精准识别;
- 抗噪优化:高噪音环境、远场收音等复杂声学场景下,保持稳定识别;
- 多人对话:精准区分多人交叉交流内容,适配会议、访谈等场景;
- 专业识别:针对古诗词、专业术语、地名人名等高知识内容精准解析;
- 原生标点:结合语音韵律与语义逻辑自动生成标点符号,转写结果可直接使用,无需二次修改编辑。
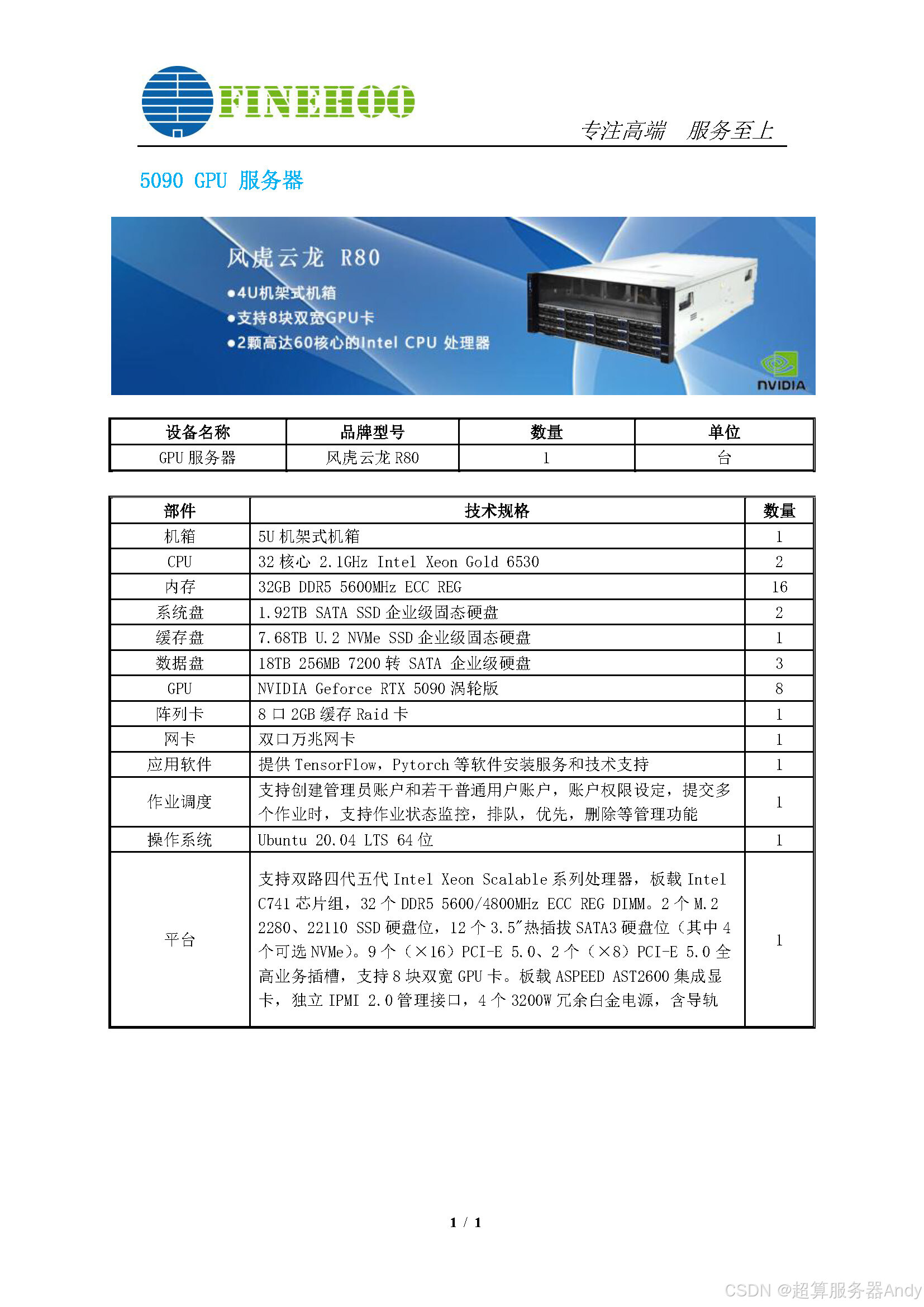
延伸科普:语音 AI 模型与 GPU 科研服务器的关联
很多人并不了解,这类高性能语音 AI 模型的研发、训练、迭代与商用落地,和GPU 服务器、科研级算力服务器密不可分。所有前沿语音算法的突破,都离不开专业算力硬件的底层支撑,这也是科研服务器成为 AI 研发刚需设备的关键原因:
-
大模型训练的核心算力支撑优质语音模型需要投喂数十万小时级别的多语种、方言、降噪、混合场景语音语料,依托深度神经网络进行反复迭代训练。传统 CPU 设备并行计算能力薄弱,训练周期漫长,而 GPU 服务器凭借海量并行计算核心、大显存与高带宽优势,可极速加速矩阵运算,大幅压缩模型训练周期,是大参数语音模型迭代优化的必备硬件。
-
算法实验与模型调优的刚需载体方言识别、强噪降噪、声纹复刻、情绪合成等特色功能,需要研发团队进行大量对照实验、参数微调、多版本测试。科研服务器支持多任务并行运行、算力灵活调度、系统环境稳定可控,完美适配 AI 科研高频试错、快速迭代的研发特性,保障算法优化高效推进。
-
高并发推理稳定落地免费开放服务、开源模型普及应用后,会承载海量用户同时在线使用。科研级 GPU 服务器具备低延迟、高并发、全天候稳定运行的特性,可保障语音实时合成、语音快速转写流畅不卡顿;同时硬件兼容性强,适配开源模型二次开发、学术研究、项目落地等多元场景。
-
分布式集群拓展性强高阶语音大模型研发需要多机多卡分布式协同训练,科研服务器支持高速互联、算力集群拓展,可按需扩容硬件资源,为后续语音技术持续升级、超大参数模型研发,提供可拓展的算力基础。
总而言之,新一代语音技术的全面升级,既是算法架构、模型逻辑优化的成果,更依托于 GPU 科研服务器等专业算力设施的强力加持。专业科研算力设备,已经成为语音人工智能、大模型创新研发与商业化落地的核心底层基石。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 9
9 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)