什么是渐进式知识封装?核心原理及其具体的实践场景
渐进式知识封装并不是一个像机器学习那样有标准定义的、广为人知的术语,但它非常精准地描述了当前人工智能,尤其是大语言模型的一种核心能力和演进趋势。
一、核心概念拆解
知识:这里指模型从训练数据中学到的信息、规律、推理能力和技能。比如,事实知识(北京是中国的首都)、语法知识、编程技巧、逻辑推理链等。
封装:这是一个软件工程概念,指将复杂的数据和操作细节隐藏起来,只暴露简单的接口。比如,你不需要知道手机触摸屏的物理原理,只需知道滑动这个简单操作即可。
渐进式:指这个过程是逐步的、分阶段的、由浅入深的。
合起来理解:渐进式知识封装指的是AI模型以一种由简到繁、由表及里的方式,将复杂、原始的数据和信息,逐步内化和组织成高度结构化、可被灵活调用的内部能力的过程。
二、核心原理:从信息碎片到知识晶体
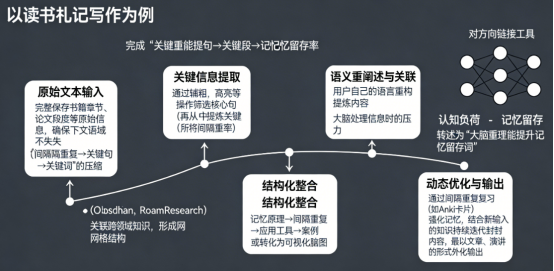
渐进式封装的本质是知识的分层过滤与价值沉淀。以读书札记写作为例,其典型路径包括五个递进步骤:
1、原始文本输入:完整保存书籍章节、论文段落等原始信息,确保上下文语境不丢失。
2、关键信息提取:通过加粗、高亮等操作筛选核心句,如“间隔重复能提升记忆留存率”,再从中提炼“间隔重复”“记忆留存”这样的关键词,完成从关键段到关键句再到关键词的压缩;
3、语义重述与关联:用自己的语言重构提炼内容,比如将“认知负荷”转述为“大脑处理信息时的压力”,并通过Obsidian、Roam Research这一类双向链接工具关联跨领域知识,形成网状结构;
4、结构化整合:将关联后的知识点按逻辑重组为树状大纲,类似记忆原理→间隔重复→应用工具→案例的大纲,或转化为可视化脑图;
5、动态优化与输出:通过间隔重复复习强化记忆,结合新输入的知识持续迭代封装内容,最终以文章、演讲等形式外化输出。
这一过程类似工业生产中的“原材料→精炼→加工→成品”流程,每个环节都在降低信息熵,提升知识的纯度与可用性。
三、实践场景:从个人学习到组织创新
渐进式封装的价值在不同场景中呈现差异化形态:
(1)个人知识管理
阅读深化:通过五级归纳法处理书籍——从完整文本到加粗关键句,再到高亮核心词,最终形成个性化知识卡片。例如阅读《认知科学》时,可将“工作记忆容量有限”这一结论关联至“注意力管理技巧”和“番茄工作法”。
技能内化:学习编程时,先摘录官方文档代码片段(原始输入),再用注释提炼核心逻辑(语义重述),最后通过LeetCode题目实现知识迁移(动态优化)。
(2)学术研究
文献综述:用Zotero收集论文(原始层),通过Paper Digest生成摘要(提取层),再用Obsidian建立理论→方法→结论关联网络(关联层),最终形成可视化研究图谱。
论文写作:借鉴卢曼卡片盒笔记法,将每个研究发现写成原子化笔记(如“2023年XX实验证明AI可预测蛋白质结构”),通过编号系统(如1.1a、1.1b)建立逻辑链,最终自动生成论文大纲。
(3)企业知识沉淀
流程标准化:将员工经验通过问题场景→解决方案→适用条件三层封装,形成可复用的SOP(如客服话术库)。某电商企业通过该方法将新人培训周期缩短40%。
创新孵化:使用Miro构建跨部门知识网络,市场部的客户画像的笔记可直接关联产品部的功能规划卡片,促进跨界协作。
四、为什么这个概念很重要?
渐进式知识封装不仅是描述AI如何工作的一个精准比喻,它更指明了AI未来发展的方向:
可解释性:理解模型如何封装知识,是打开AI“黑箱”的关键一步。如果我们能追踪其封装和调用过程,就能更好地理解模型的决策逻辑。
可靠性:封装良好的知识模块更稳定、更可靠。这有助于减少模型的幻觉和错误。
能力扩展:这是构建更强大AI系统的核心路径。未来的AI进步,很大程度上将依赖于其能否以渐进式知识封装的方式,更高效、更可靠地内化和组织更复杂的知识体系。
总结来说,渐进式知识封装是AI从记忆走向理解,从模仿走向创造的内在驱动力。它描绘了一个将世界的复杂性转化为内部简单性的美妙过程。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 20
20 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)