Java开发者AI转型第十课!化繁为简!Spring AI 全能文档解析器 (Document Readers) 与元数据提取实操
大家好,我是直奔標杆!今天继续咱们《Spring AI 零基础到实战》系列的第十节分享,全程实战干货,适合Java开发者跟着练,一起吃透Spring AI文档解析核心能力,共同进步~
在上一节《Java开发者AI转型第九课!突破知识边界!企业级 RAG (检索增强生成) 核心架构与 ETL 管道初探》的分享中,咱们已经明确了企业级RAG落地的第一步——ETL数据管道的E(Extract,抽取)环节,这也是搭建企业知识库的基础前提。
做过企业级开发的小伙伴都清楚,咱们日常接触的文件五花八门:PDF格式的财报、Word版的简历、HTML网页资料,还有平时记笔记用的Markdown文档。但大模型本质上只能处理纯文本字符串,根本没法直接“识别”这些夹杂着图片、表格和复杂排版的二进制物理文件。
所以,咱们迫切需要一款“万能工具”,能把这些千奇百怪的文件格式,统一提取出纯净文本,并且封装到Spring AI标准的Document领域对象中,为后续的RAG流程铺路。
好在Spring AI已经帮咱们集成了Java领域非常强大的文件解析工具(比如Apache Tika和PDFBox),今天咱们就手把手代码实战,把物理文件成功“加载”到内存中,迈出搭建企业知识库的关键一步,建议大家跟着敲一遍代码,加深理解!
本节学习目标(建议收藏)
-
统一抽象:掌握Spring生态下标准化的文件加载方式(org.springframework.core.io.Resource),适配各类文件读取场景。
-
万能解析:实战运用TikaDocumentReader,一键搞定Word/PPT/HTML等上百种文件格式的文本提取,高效又便捷。
-
精准拆分:实战使用PagePdfDocumentReader,实现PDF文件按页精准读取,解决大文件解析痛点。
-
多模态进阶:自定义文档读取器,深度拆解如何同时提取PDF中的文本与图片,打造图文并茂的Document对象,适配多模态大模型需求。
物理文件 → 数字资产:解析流程拆解
在动手写代码之前,咱们先通过架构逻辑,直观理解一下:各类格式的物理文件,是如何通过Spring AI的解析引擎,被“处理”成标准化的Document对象的?
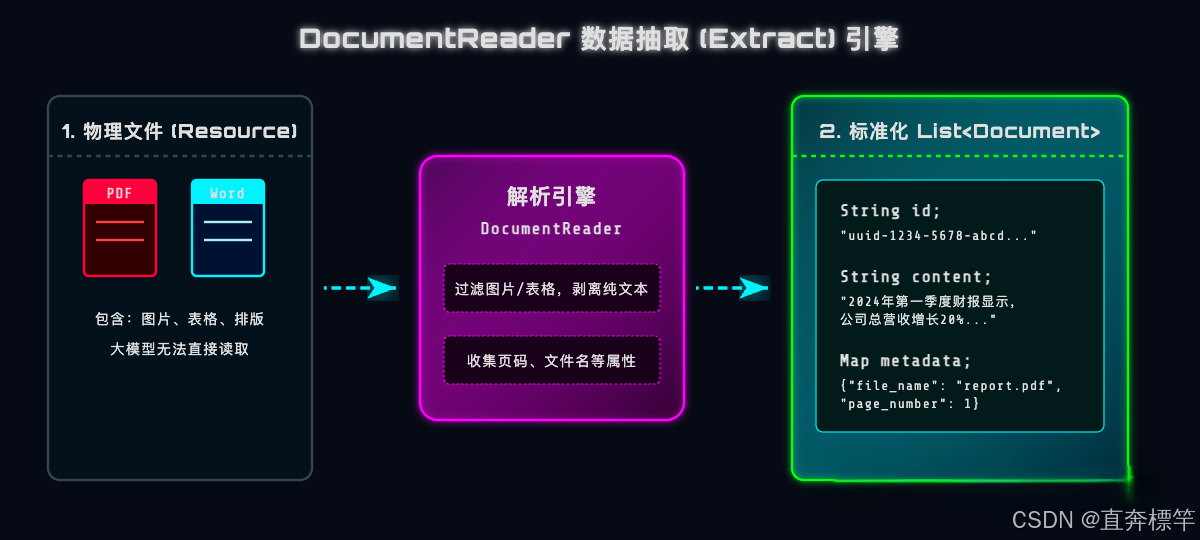
核心逻辑很简单:无论你传入的是哪种格式的文件,只要经过DocumentReader的解析处理,最终输出的一定是结构统一的Document对象集合——每个对象都包含唯一ID、文本内容Content和溯源元数据Metadata,这也是后续RAG检索的核心数据载体。
前置准备:依赖引入与测试文件
在Spring Boot项目中读取文件,咱们可以借助底层的org.springframework.core.io.Resource接口,非常便捷。建议大家把测试用的PDF或Word文档,放在src/main/resources/docs目录下,方便后续读取。
直奔標杆这里准备了两个测试PDF文件,大家可以参考:sample.pdf(纯文字内容)和sample2.pdf(包含图片内容),用于后续不同场景的实战测试。
默认情况下,Spring AI自带JSON和纯文本的简单提取器,无需额外引入依赖。但如果要解析HTML、PDF、Word这类复杂文档,就需要在pom.xml中显式引入对应的读取器组件,咱们后续以PDF解析为例,直接上依赖代码(可直接复制使用):
<!-- 1. Tika解析器:万能解析工具(支持Word、PPT、HTML、TXT等上百种格式) -->
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-tika-document-reader</artifactId>
</dependency>
<!-- 2. PDF专用解析器:按页精准拆分(基于Apache PDFBox,适配PDF专项解析场景) -->
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-pdf-document-reader</artifactId>
</dependency>实战一:TikaDocumentReader——万能解析“神器”
Apache Tika相信很多小伙伴都用过,它能从几乎所有主流文档格式中提取文本,而Spring AI将其封装成了TikaDocumentReader,调用起来非常简单,两行核心代码就能搞定,咱们直接上测试用例(注释很详细,新手也能看懂):
// 直奔標杆:TikaDocumentReader实战测试
@Test
void extractWithTika() {
// 1. 实例化TikaDocumentReader,传入测试文件资源
TikaDocumentReader reader = new TikaDocumentReader(samplePdfResource);
// 2. 调用get()方法,触发底层解析引擎,完成全量解析
List<Document> documents = reader.get();
// 3. 打印解析结果,查看核心信息
Document doc = documents.get(0);
System.out.println("【文档ID】: " + doc.getId());
System.out.println("【文档内容前100字】: " +
doc.getText().substring(0, Math.min(100, doc.getText().length())));
System.out.println("【元数据Metadata】: " + doc.getMetadata());
}运行结果与解析
【文档 ID】: f4e9f440-6047-4318-8b9f-2eed92428eb8
【文档内容前100字】:
1. 《春晓》·孟浩然
春眠不觉晓,处处闻啼⻦。
夜来⻛⾬声,花落知多少。
...
【元数据 Metadata】: {source=sample.pdf}这里和大家拆解一下:TikaDocumentReader的解析逻辑非常直接高效,它会把整个文件的文本内容全部提取出来,封装到一个单独的Document对象中。
✅ 优点:兼容性极强,万物皆可解析,代码极简,适合快速提取各类文件的文本内容,不用单独适配不同格式。
❌ 痛点:解析逻辑比较“粗暴”,如果你的PDF有100页,Tika会把所有内容揉成一个几十万字的“大文本块”。不仅大模型的Token窗口扛不住,更关键的是丢失了页码定位信息,后续RAG检索时无法精准溯源,这在企业级场景中是比较致命的。
实战二:PagePdfDocumentReader——PDF精准按页解析
为了解决Tika解析的痛点,如果咱们的业务场景明确是处理PDF文件,建议使用Spring AI基于Apache PDFBox引擎封装的PagePdfDocumentReader。它的核心优势的是:按页解析,一页生成一个独立的Document对象,完美保留页码信息。
直接上实战代码,包含解析规则配置,大家可以按需调整:
// 直奔標杆:PagePdfDocumentReader实战测试(PDF按页解析)
@Test
void extractWithPdfReader() {
// 1. 配置PDF解析规则,优化解析效果(忽略页眉页脚,避免无关文本干扰)
PdfDocumentReaderConfig config = PdfDocumentReaderConfig.builder()
.withPageTopMargin(0) // 忽略页眉
.withPageBottomMargin(0) // 忽略页脚
.withPageExtractedTextFormatter(ExtractedTextFormatter.builder()
.withNumberOfTopTextLinesToDelete(0)
.build())
.build();
// 2. 实例化PDF专用解析器,传入文件资源和解析配置
PagePdfDocumentReader reader = new PagePdfDocumentReader(sample2PdfResource, config);
// 3. 触发解析,获取解析后的Document集合
List<Document> documents = reader.get();
System.out.println("共解析出 " + documents.size() + " 页独立内容。");
// 4. 遍历打印每一页的核心信息
for (int i = 0; i < documents.size(); i++) {
Document doc = documents.get(i);
System.out.println("\n--- 第 " + (i + 1) + " 个Document对象 ---");
System.out.println("【文档ID】: " + doc.getId());
System.out.println("【纯文本内容】: " + doc.getText().trim());
// 重点关注:元数据中会包含页码信息,方便后续溯源
System.out.println("【元数据Metadata】: " + doc.getMetadata());
}
}运行结果与核心亮点
共解析出 2 页独立内容。
--- 第 1 个 Document 对象 ---
【文档 ID】: f6e8b2d5-e030-4e59-9f57-535b7c5dfd0b
【纯文本内容】: 1. 《春晓》·孟浩然...
【元数据 Metadata】: {page_number=2, file_name=sample2.pdf}这就是企业级场景中推荐的高质量数据清洗方式!解析器会自动将当前内容的“页码”“文件名”等信息存入metadata字典中。后续大模型基于这页内容回答用户问题时,咱们就能从Metadata中提取出page_number,直接在前端标注“此回答参考自第X页”,提升回答的可信度和可追溯性,这一点非常实用~
但这里有个小问题:原生的PagePdfDocumentReader默认只提取文本内容,咱们测试用的sample2.pdf中包含的图片,并没有被解析出来——这在多模态大模型时代,显然满足不了需求,因为图片中往往包含架构图、流程图等关键信息。
实战三:进阶自定义——分离式多模态PDF读取器
随着多模态大模型的普及,图片解析已经成为企业级AI应用的常见需求。为了同时提取PDF中的文本和图片,直奔標杆这里给大家分享一个自定义读取器:SeparatedMultimodalPdfReader,核心思路是“分离提取、分类标注”。
核心设计理念:目前主流向量数据库对图文混排的支持还比较有限,因此我们将文本和图片分离提取——一页PDF中的文本生成一个纯文本Document;页面中的每一张图片生成一个独立的、携带Media属性的图片Document,再通过Metadata给它们打上分类标签,确保两者互不干扰,后续可分别处理。
以下是精简后的核心实现代码(关键逻辑已标注,大家可直接复用改造):
/**
* 直奔標杆:分离式多模态PDF读取器(核心代码片段)
* 核心功能:将PDF中的文本和图片分离提取,分别封装为独立的Document对象,方便后续多模态处理
*/
public class SeparatedMultimodalPdfReader implements DocumentReader {
// 自定义Metadata标签,用于区分Document类型(文本/图片)
public static final String METADATA_CONTENT_TYPE = "content_type";
public static final String CONTENT_TYPE_TEXT = "text";
public static final String CONTENT_TYPE_IMAGE = "image";
// ... 省略构造函数与PDFBox初始化代码(核心是初始化PDF解析相关资源) ...
@Override
public List<Document> get() {
List<Document> readDocuments = new ArrayList<>();
// ... 省略分页遍历逻辑(核心是遍历PDF的每一页,分别处理文本和图片) ...
for (PDPage page : pages) {
// 1. 提取当前页纯文本,生成文本类型Document
String pageText = extractText(page);
if (StringUtils.hasText(pageText)) {
readDocuments.add(createTextDocument(pageText, pageNumber));
}
// 2. 提取当前页所有图片,生成独立的图片类型Document
List<Document> imageDocs = extractImageDocumentsFromPage(page, pageNumber);
readDocuments.addAll(imageDocs);
}
return readDocuments;
}
/**
* 核心方法:将页面中的每张图片提取为独立的Document对象
*/
private List<Document> extractImageDocumentsFromPage(PDPage page, int pageNumber) throws IOException {
List<Document> imageDocs = new ArrayList<>();
PDResources resources = page.getResources();
// ... 省略资源判空与遍历逻辑(核心是遍历页面中的所有图片资源) ...
// 发现图片对象(PDImageXObject),开始提取处理
if (xObject instanceof PDImageXObject pdImage) {
BufferedImage image = pdImage.getImage();
byte[] imageBytes = convertToBytes(image); // 将图片转为字节流,方便后续处理
// 1. 构建Spring AI的Media多媒体对象,封装图片信息
String mimeType = "image/" + pdImage.getSuffix();
Media media = new Media(MimeTypeUtils.parseMimeType(mimeType), new ByteArrayResource(imageBytes));
// 2. 注入自定义Metadata,标记图片类型,方便后续区分
Map<String, Object> metadata = new HashMap<>();
metadata.put("page_number", pageNumber); // 保留图片所在页码,方便溯源
metadata.put(METADATA_CONTENT_TYPE, CONTENT_TYPE_IMAGE); // 关键:标记为图片类型
// 3. 构造携带图片的Document对象,加入集合
imageDocs.add(new Document(media, metadata));
}
return imageDocs;
}
// ... 省略createTextDocument等辅助方法(核心是生成文本类型Document) ...
}多模态解析实战测试(关键一步)
有了这个自定义读取器,咱们就可以同时提取PDF中的文本和图片,并且能直接将图片传入多模态大模型(如GPT-4o)解析图片内容,或者存入向量数据库实现“以图搜图”,完美适配多模态场景需求。
直接上测试代码,演示如何区分文本和图片,并调用大模型解析图片:
// 直奔標杆:多模态解析实战测试(提取文本+图片,并解析图片内容)
@Test
void extractWithSeparatedMultimodalPdfReader() {
SeparatedMultimodalPdfReader reader = new SeparatedMultimodalPdfReader(sample2PdfResource, config);
List<Document> documents = reader.get();
// 遍历解析结果,区分文本和图片,分别处理
for (Document doc : documents) {
// 利用自定义Metadata标签,区分当前Document是文本还是图片
String contentType = (String) doc.getMetadata().get(SeparatedMultimodalPdfReader.METADATA_CONTENT_TYPE);
if (SeparatedMultimodalPdfReader.CONTENT_TYPE_TEXT.equals(contentType)) {
System.out.println("【纯文本内容】: " + doc.getText().trim());
} else {
// 如果是图片Document,直接调用大模型的视觉能力(Vision)解析图片内容
UserMessage userMessage = UserMessage.builder()
.text("详细描述这张图的内容,重点说明核心信息")
.media(Media.builder()
.mimeType(MimeTypeUtils.IMAGE_PNG)
.data(doc.getMedia().get(0).getData())
.build())
.build();
// 调用大模型,获取图片解析结果
String imageDesc = chatClientBuilder.build().prompt()
.messages(userMessage)
.call()
.content();
System.out.println("【图片AI解析内容】: " + imageDesc);
}
}
}运行结果与总结
共解析出 4 页独立内容。
--- 第 1 个 Document 对象 (图片) ---
【图片 AI 解析内容】: 这张图片的内容是关于设计和实现一个基于知识图谱(KG)与检索增强生成(RAG)的考研智能问答系统。核心在于构建结构化知识,并研发能够精准解答问题的智能检索引擎...这样一来,PDF中隐藏的图片就被完美提取并解析了!大模型相当于充当了“高级OCR”的角色,帮我们精准识别图片中的复杂内容(比如架构图、流程图),这在企业级知识库搭建中非常实用,能最大程度保留文件中的关键信息。
本节课核心总结(必看)
今天咱们实战了三种文档解析方式:TikaDocumentReader(万能解析)、PagePdfDocumentReader(PDF精准按页解析)、自定义SeparatedMultimodalPdfReader(多模态解析),虽然用法不同,但它们有一个共同的核心使命——产出标准化的List<Document>。
这个Document对象,就是后续所有RAG检索、向量运算的“通用数据载体”,相当于咱们搭建企业知识库的“基础积木”。
通过本节课的实战,咱们成功跑通了RAG的第一步(ETL - E抽取环节),把物理文件转换成了内存中的标准化数字资产。但新的挑战也随之而来:
如果用Tika解析,100页的PDF会被揉成一个庞大的Document;哪怕是按页解析的PagePdf,一页的文字也可能高达2000字。而大模型的上下文窗口是有限的,咱们绝对不能把这么大段的内容直接用于Embedding(向量化)和入库——必须把它切得更小、更精细,这就是咱们下一节课的核心内容。
下节预告(持续跟进不迷路)
下一节,咱们将进入《Java开发者AI转型第十一课!文本切分术!Spring AI 智能分块 (Text Splitters) 与 Overlap 语义防割裂指南》,重点学习RAG ETL管道中的T(Transform,转换)环节:
-
如何精准将大段文本切分成500字左右的小片段(Chunk)?
-
什么是Chunk Size(块大小)和Overlap(重叠度),核心作用是什么?
-
如果不设置Overlap,会导致“一刀切断上下文”的严重问题吗?如何避免?
干货持续输出,跟着直奔標杆一起,从零基础吃透Spring AI,顺利完成Java开发者的AI转型,咱们下节课见!
往期回顾(方便大家连贯学习)
-
Java开发者AI转型第七课!AI失忆症克星!ChatMemory对话历史管理与上下文实战
-
Java开发者AI转型第八课!避开Token陷阱!Spring AI记忆裁剪源码解析与Token级防溢出核心技巧
-
Java开发者AI转型第九课!突破知识边界!企业级 RAG (检索增强生成) 核心架构与 ETL 管道初探
我是直奔標杆,专注Java开发者AI转型实战分享,每节课都贴合实际开发场景,拒绝纸上谈兵。大家在实战过程中有任何问题,欢迎在评论区留言交流,一起学习、一起进步,共同成为AI时代的Java标杆开发者!

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 8
8 0
0- 0



 已为社区贡献35条内容
已为社区贡献35条内容

所有评论(0)