多模型路由与动态选择架构设计(通俗、可落地、企业级直接用)
🤍 前端开发工程师、技术日更博主、已过CET6
🍨 阿珊和她的猫_CSDN博客专家、23年度博客之星前端领域TOP1
🕠 牛客高级专题作者、打造专栏《前端面试必备》 、《2024面试高频手撕题》、《前端求职突破计划》
🍚 蓝桥云课签约作者、上架课程《Vue.js 和 Egg.js 开发企业级健康管理项目》、《带你从入门到实战全面掌握 uni-app》
文章目录
什么是多模型路由 → 为什么要做 → 架构怎么搭 → 怎么动态选模型 → 避坑

一、先搞懂:多模型路由到底是干嘛的?
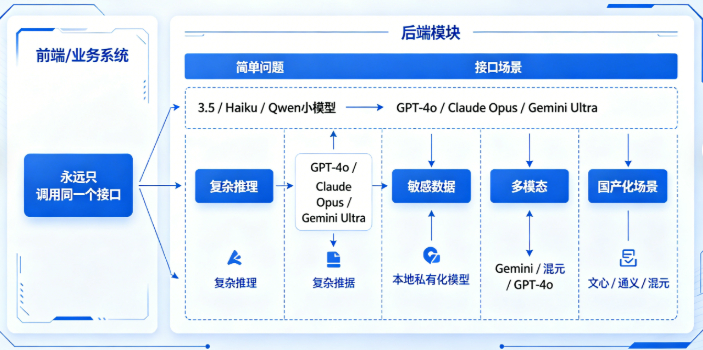
就是你后端搭一个**“AI调度中心”**:
- 前端/业务系统永远只调用同一个接口
- 后端自动根据场景、成本、速度、敏感程度、长度,智能选最优模型:
- 简单问题 → 3.5 / Haiku / Qwen 小模型
- 复杂推理 → GPT-4o / Claude Opus / Gemini Ultra
- 敏感数据 → 本地私有化模型
- 多模态 → Gemini / 混元 / GPT-4o
- 国产化场景 → 文心 / 通义 / 混元
好处:
- 业务系统零改造
- 成本自动最优
- 模型可随时替换、扩容、降级
- 支持国产化平滑替代

二、核心架构(最简单稳定版)
整体就 5 层:
-
统一接入层(Gateway)
鉴权、限流、日志、格式标准化 -
请求解析层(Router Core)
分析用户问什么、需要什么能力 -
策略调度层(Policy Engine)
按规则选模型:场景、成本、安全、长度、并发 -
模型适配层(Adapter)
把所有模型(OpenAI/文心/通义/Claude/Gemini/本地Llama)
统一包装成 一套 OpenAI 风格接口 -
结果处理层
流式返回、格式校验、安全审核、缓存、降级兜底
三、动态选择模型的依据(最关键)
路由不是乱选,是按特征自动判断:
1)按场景类型
- 文案/总结/翻译 → 便宜模型
- 推理/数学/代码 → 强模型
- 多模态(图/视频)→ Gemini / GPT-4o / 混元
- 政策/公文/合规 → 文心
- 电商/批量 → 通义
- 超长文档 → Claude / Gemini
2)按上下文长度
- < 2k → 任意小模型
- 2k–16k → 3.5 / Qwen / Haiku
- 32k+ → GPT-4o / Claude Sonnet
- 100k+ → Claude Opus / Gemini 1.5 Pro
3)按敏感等级(最重要!)
- 公开信息 → 公有云API
- 企业内部数据 → 本地开源模型
- 涉密/合规 → 私有化 + 内网 + 国产模型
4)按成本预算
- 高并发批量 → 最便宜可用模型
- 核心付费用户 → 最强模型
- 测试/免费用户 → 降级小模型
5)按可用性(熔断降级)
- OpenAI 挂了 → 自动切 Claude
- Claude 限流 → 切 Gemini
- 外网全挂 → 切本地 Llama / 通义 / 文心
四、路由策略引擎怎么设计?(直接可实现)
你可以理解为一套 if-else 规则 + 打分机制
1)规则引擎(最简单可用)
if 包含图片/视频 → 选 Gemini / GPT-4o / 混元
elif 长度 > 32k → 选 Claude / Gemini
elif 敏感数据 → 选本地私有化模型
elif 需要合规/国产化 → 选文心/通义
elif 简单问答 → 选 3.5 / Haiku / Qwen
else → 默认 GPT-4o / Claude Sonnet
2)打分机制(更智能)
每个请求给模型打 5 项分数:
- 能力分(推理强弱)
- 速度分(延迟)
- 成本分(越低越高)
- 安全分(是否内网)
- 稳定性分(可用性)
总分最高的模型被选中。
五、模型适配层(架构灵魂)
所有模型接口不一样,必须统一封装:
- OpenAI
- Claude
- Gemini
- 文心一言
- 通义千问
- 混元
- 本地 Llama / Qwen
统一封装成:
POST /v1/chat/completions
参数统一:
- model
- messages
- temperature
- stream
- max_tokens
业务层完全不用关心底层是谁。
六、企业级高可用设计(必须加)
1)熔断降级
- 某个模型 500 / 429 过多 → 自动熔断 30s
- 熔断期间切备用模型
2)重试与 failover
- 主模型失败 → 自动切备用
- 支持多级备用:主 → 备 → 本地兜底
3)缓存
相同问题直接返回,省钱、提速、防重复调用
4)流量灰度
- 10% 流量试跑国产模型
- 观察效果没问题再逐步切量
5)监控大盘
- 每个模型调用量、延迟、成本、错误率、幻觉率
- 自动报警
七、最实用的路由示例(真实业务可用)
场景1:智能客服
- 简单问题 → 通义千问 / 3.5
- 复杂投诉 → GPT-4o / Claude
- 涉及用户隐私 → 本地模型
场景2:企业知识库
- 普通查询 → 小模型
- 长文档总结 → Claude / Gemini
- 内部资料 → 私有化 Llama / Qwen
场景3:国产化替代
- 非敏感 → 通义
- 公文/政策 → 文心
- 多模态 → 混元
- 核心业务双跑对比
场景4:多模态应用
- 图片 → GPT-4o / Gemini
- 视频 → Gemini
- 设计/创意 → 混元
八、架构总结(一句话)
多模型路由 = 统一入口 + 策略调度 + 模型适配 + 高可用降级
让业务不用关心模型,后端自动实现:
最强能力、最低成本、最高稳定、最合规安全。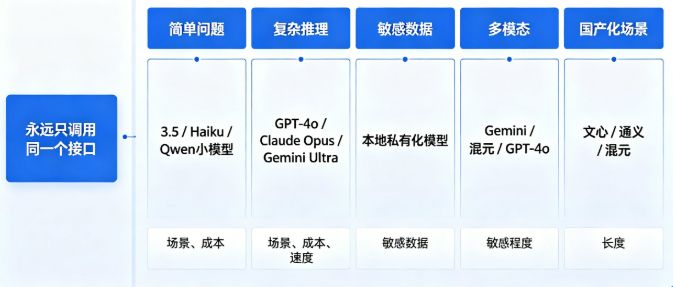

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 19
19 0
0- 0



 已为社区贡献33条内容
已为社区贡献33条内容

所有评论(0)