Minimind-训练过程(暂时使用kaggle)
Minimind 是一个“小”语言模型,系统较为轻量,主线最小版本体积约为GPT-3的1/2700。完整的模型同时开源了大模型的极简结构与完整训练链路,覆盖 MoE、数据清洗、预训练(Pretrain)、监督微调(SFT)、LoRA、RLHF(DPO)、RLAIF(PPO / GRPO / CISPO)、Tool Use、Agentic RL、自适应思考与模型蒸馏等全过程代码。从该模型中可以初步感受模型训练过程,入门LLM。
模型简述
Minimind-3 Dense 使用 Transformer Decoder-Only 结构,整体配置向Qwen3生态对齐。
由于其采用预标准化(Pre-Norm)+ RMSNorm;使用 SwiGLU 激活函数;使用 RoPE 旋转位置编码,并支持 YaRN 外推等因此其方便后续转换到transformers/ollama等模型。
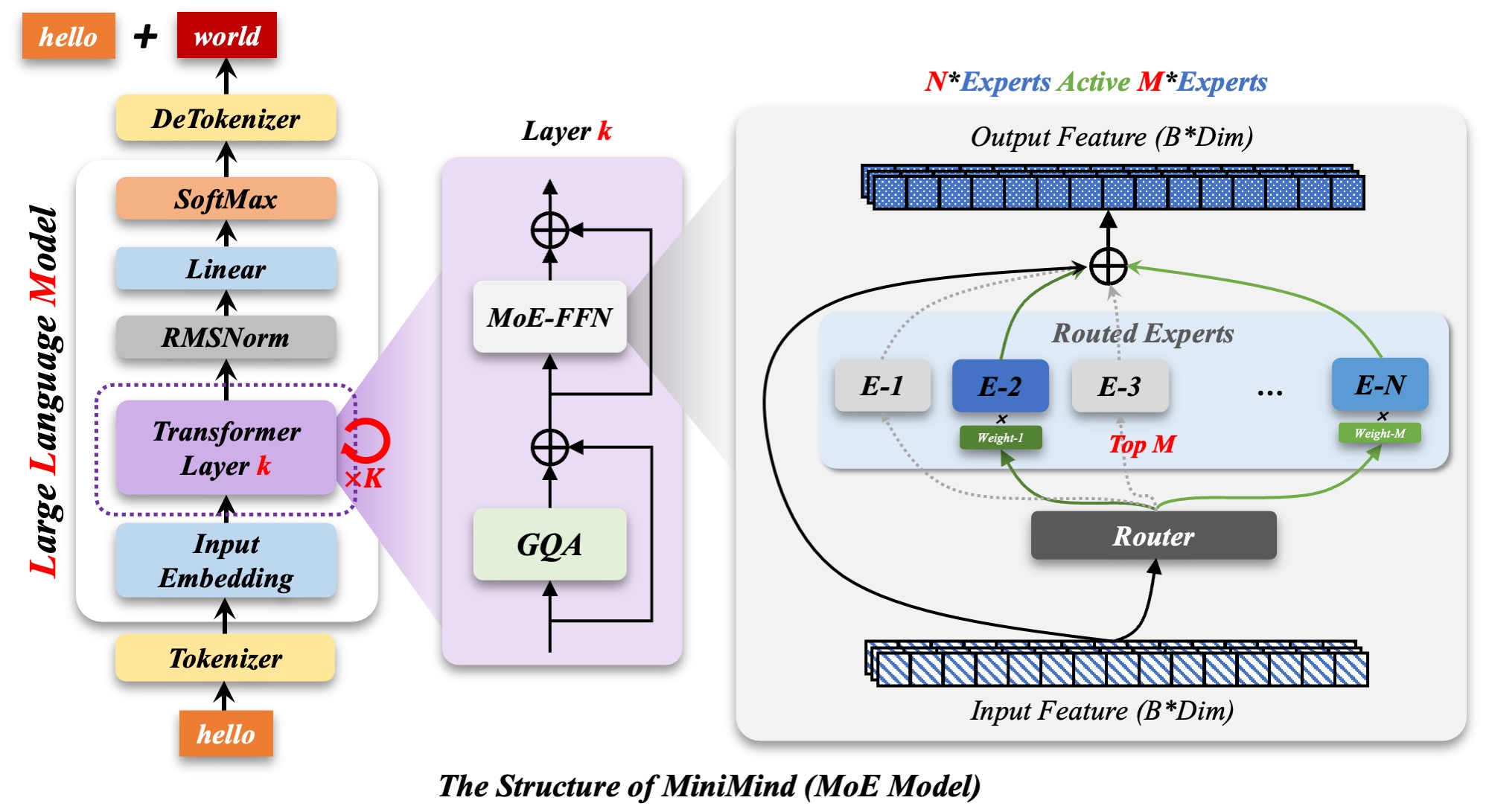
minimind-3-moe在相同结构上扩展 MoE 前馈层,实现上兼容Qwen3-MoE风格配置。当前默认配置为4 experts/top-1 routing,用于以更低激活参数获得更高容量。当Experts 继续增加后,实际耗时往往比同尺寸规模的 dense 模型高非常多,这和 “MoE 推理更快” 放在一起看会有点反直觉,但训练时 token 先按专家分桶、再分别做 forward,原生训练时带来的 kernel 启停和调度开销会急剧变重,这本身是很自然的事情。得靠支持 MoE kernel-fused 的算子库来优化,比如基于Triton的自定义 kernel、DeepSeed-MoE、Megatron-LM等等。当然,这个项目还是希望保留原生 PyTorch 的普适性,所以这里做的是现实的折中。
minimind-3系列结构如下图: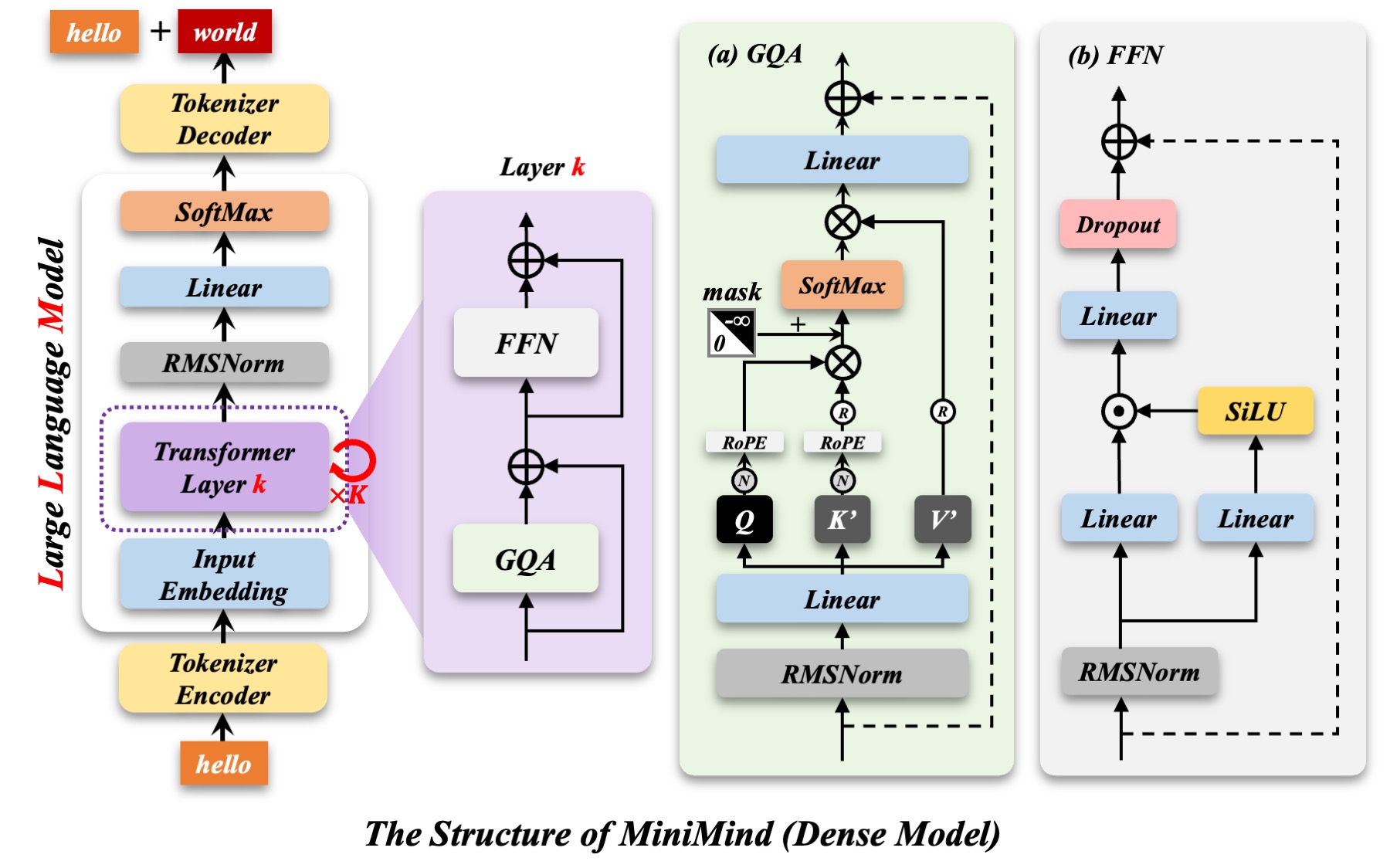
主要训练过程
预训练
LLM最重要的是先把尽可能多的基础知识和语言规律吸收到参数里,这样模型后面才有能力去理解问题、组织表达,并逐步形成像样的生成能力。预训练做的事情,就是让模型从Wiki 百科、新闻、书籍、对话语料等阅读大量文本,从中学习事实知识、语言模式以及上下文之间的统计关系。这个阶段通常是“无监督”的:人类不需要逐条告诉模型哪里对、哪里错,而是让它自己从海量文本里总结规律,逐步建立起对世界知识和语言结构的内部表征。
有监督微调
SFT 并不只是把模型调成“更会聊天”,它同样可以继续向模型中灌入新的知识、行为模式和回答风格。如果把预训练理解为先让模型广泛地读书、积累基础语言能力,那么 SFT 更像是在高质量、更有目标的数据上继续深加工。一方面,它会让模型适应多轮对话、问答、工具调用和思考标签等交互形式;另一方面,它也会继续把特定知识分布、任务模式和助手风格压进参数里。
其他训练
也可以完成知识蒸馏、LoRa、强化学习等,但介于实验只完成最小模型,因此先不做过多描述
实验部分
实验部分主要使用项目:https://github.com/jingyaogong/minimind。实验部分会尽可能讲述有部分踩过的坑和相对详细的细节。
环境准备
Minimind 作者的软硬件配置(仅供参考):
- CPU: Intel® Core™ i9-10980XE CPU @ 3.00GHz
- RAM: 128 GB
- GPU: NVIDIA GeForce RTX 3090(24GB) * 8
- Ubuntu 20.04
- CUDA 12.2
- Python 3.10.16
- requirements.txt
我所使用的配置(暂时):
kaggle上免费时长试用
GPU T4 x2
以及后续会用到的调用requirements.txt如下:
datasets==3.6.0
datasketch==1.6.4
Flask==3.0.3
Flask_Cors==4.0.0
jieba==0.42.1
jsonlines==4.0.0
marshmallow==3.22.0
# matplotlib==3.10.0
ngrok==1.4.0
nltk==3.8
numpy==1.26.4
openai==1.59.6
# peft==0.7.1
psutil==5.9.8
pydantic==2.11.5
rich==13.7.1
scikit_learn==1.5.1
sentence_transformers==2.3.1
simhash==2.1.2
tiktoken==0.10.0
transformers==4.57.6
jinja2==3.1.2
jsonlines==4.0.0
trl==0.13.0
ujson==5.1.0
wandb==0.18.3
streamlit==1.50.0
einops==0.8.1
swanlab==0.7.11
modelscope==1.30.0
# torch==2.6.0
# torchvision==0.21.0获取代码
这一步比较简单主要是从GitHub上面拉取代码。首先呢一定要装好git,之后就把仓库克隆,并安装依赖。这里如果使用kaggle在代码块运行的话命令行语句前面要加上!。
git clone --depth 1 https://github.com/jingyaogong/minimind 
cd minimind
pip install -r requirements.txt -i https://mirrors.aliyun.com/pypi/simple
在看到Successfully installed即可ok,在使用kaggle的notebook里由于本身有环境会有一个error,但是不影响后续过程。
之后可以下载模型:
# 方式1
modelscope download --model gongjy/minimind-3 --local_dir ./minimind-3
# 方式2
git clone https://huggingface.co/jingyaogong/minimind-3紧接着使用:
# 方式1:使用 Transformers 格式模型
python eval_llm.py --load_from ./minimind-3
# 方式2:基于 PyTorch 模型(确保./out目录下有对应权重)
python eval_llm.py --load_from ./model --weight full_sft就可以使用最简单的问答了,当然显然只是之前提到的看过所以机械回答片段。那么我们要训练就要首先下载数据了。
下载数据
首先要进入minimind项目根目录!!!
正确来说我们要使用代码下载如下模块的数据:
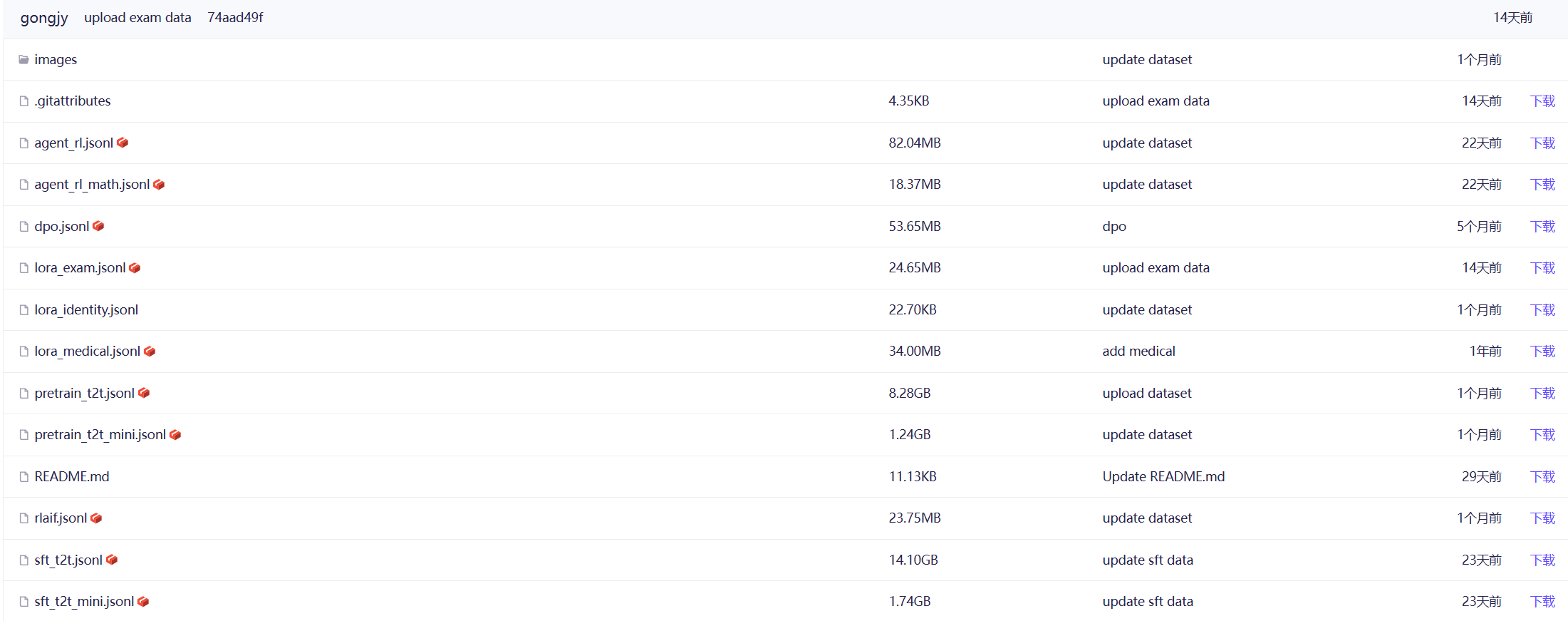
但是从数据大小而言其实很多。而且根据上述表达我们主要使用Pretrain数据以及SFT数据,仔细观察数据描述其实真正训练最小模块要用到的pretrain_t2t_mini + sft_t2t_mini来训练Minimind Zero模型,因此我认为只需要下载这两个数据(目前为猜想需要进一步尝试,虽然作者也这样讲了但我还是下载了全部。不过rlaif.jsonl为必下)。
这里给出全部下载的代码:
pip install modelscope
modelscope download --dataset gongjy/minimind_dataset --local_dir ./dataset这里多话一嘴,kaggle的下载刷新让人难受,而且这里有一个大雷就是kaggle给的working空间大约在20g完全下载是下载不了的,一定要放到tmp或者是本地下载上传到input!!!!!
还有就是在下载中win终端发现会重复下载,真的很费时间。
这里给出数据集介绍:
agent_rl.jsonl:Agentic RL 主线训练数据,用于 train_agent.py 的多轮 Tool-Use / CISPO / GRPO 训练
agent_rl_math.jsonl:Agentic RL 纯数学补充数据,适合带最终校验目标的多轮推理/工具使用场景(用于RLVR)
dpo.jsonl:RLHF阶段偏好训练数据(DPO)
pretrain_t2t_mini :minimind-3 轻量预训练数据,适合快速复现(推荐设置max_seq_len≈768)
pretrain_t2t :minimind-3 主线预训练数据(推荐设置max_seq_len≈380)
rlaif.jsonl:RLAIF训练数据集,用于PPO/GRPO/CISPO等强化学习算法训练
sft_t2t_mini.jsonl:minimind-3 轻量SFT数据(用于快速训练Zero模型),推荐设置max_seq_len≈768,其中已混入一部分 Tool Call 样本
sft_t2t.jsonl:minimind-3 主线SFT数据,适合完整复现,其中同样已混入 Tool Call 样本
预训练
下载之后我们需要预训练,这里需要知道所有脚本都是可以断点续传的,比较适合长时间训练或者不稳定环境。
这里我们要进入trainer文件夹下:
cd trainer
python train_pretrain.py
# 断点续传,存放在./checkpoints/,命名为<权重名>_<维度>_resume.pth
python train_pretrain.py --from_resume 1训练后,可以得到out/pretrain_*.pth作为输出权重。
指令微调
cd trainer
python train_full_sft.py
# 断点续传,存放在./checkpoints/,命名为<权重名>_<维度>_resume.pth
python train_full_sft.py --from_resume 1训练后,可以得到out/full_sft_*.pth作为输出权重。
后续
以上就是我暂时的minimind体验,当然踩了很多坑做了很久,但还是因为时间关系没有完全复现完,指令微调你怎么还跑不完。预训练模型和微调模型都只训练了一个 epoch其实表现还是不佳,后续还是希望换卡体验完整的minimind3。
ok,上述暂写因为跑了好久不仅有坑而且跑的真的感人,真的想后续换卡重跑了。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 6
6 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)