对《Hierarchical geometric models for visible surface algorithms(可见表面算法的分层几何模型)》的简单个人整理
由于选择课题的原因,需要了解相关的图形学知识,所以阅读了James H. Clark 在1976年所发布的《Hierarchical geometric models for visible surface algorithms(可见表面算法的分层几何模型)》论文。在查找资料时发现好像没有相关的资料,所以写下了这篇文章。
此处叠甲
本片文章纯属个人对该论文的理解整理,尊重不同读者的不同想法,有错误之处可以指出讨论。另外,这是我第一次写文章,文笔并不好,可能有奇怪的语法问题,请见谅喵。
论文地址:https://dl.acm.org/doi/10.1145/360349.360354
引言部分
Clark在引言部分指出当前提升图像质量的三种基本方法。第一种是设计巧妙的方法来增加场景的信息价值,并且不显著增加场景数据库的信息容量。第二种是采用更加精细的数学模型来渲染对象。第三种是增加场景数据库中的信息量,并采用更结构化的方法来处理信息。
这三个方法中,Clark认为第三种结构化信息是最有前景的,因为其能够同时提高算法效率和图像质量。但也带来了如下的问题:
一、随着分辨率接近极限,场景复杂性或场景数据库信息的增加,物体的价值会降低。比如一个物体在场景中只占很小一部分(20栅格),但却需要大量的多边形来描述。这显然是浪费资源的。那么要如何才能只选择数据库中与显示设备分辨率相关的信息?(栅格:我们可以将显示器分为被横纵线切割的大小一致长方形,随着显示设备分辨率变化,组成栅格的像素点数量变化。)
二、如何满足额外信息的储存要求
三、为呈现场景信息内容,需要呈现至少多少信息
以上便是该论文所需要解决的问题。
对现有算法的概述
Polygon-Based Algorithms(基于多边形的算法)
该方法是根据算法对场景中潜在可见的图像空间多边形进行排序,分为深度优先排序和深度后置(水平优先)排序。
Depth-first sort(深度优先排序)
对于深度优先排序,Clark引入了两位的方法,分别是Schumacker,Newell。两位首先根据多边形在图像空间中到屏幕的距离计算其优先级,从而确定给定扫描线哪些多边形段具有可见性优先级。(距离越远,优先级越低)
Newell先将优先级较低的片段写入扫描线缓冲区,然后再写入优先级较高的片段,从而实现了半透明多边形的优先级较高的片段指挥修改缓冲区的强度值而不会完全的覆盖,进行了混合计算,形成一些细节程度较高的图像。但这个方法从描述上就知道会对缓冲区产生较大的压力,即使片段会被阻挡,但仍会载入缓冲区。
Schumacker同时将优先级排序的段信息加载到一组硬件寄存器中,随着扫描线的显示,寄存器信息会进行倒计时,组合逻辑网络会根据其在屏幕上的横向位移选择相应的最高级寄存器。(背景时间为1969年,使用的是物理硬件电路与电子束扫描线,所以寄存器可以分为三个优先级,近距离的红色,中距离的绿色,远距离的蓝色。电子束是由左边扫到右边,这个过程就是横向位移,早期使用寄存器中的倒计时计数器,每当电子束向右移动一个单位,倒计时-1,就能够定位位置。对于组合逻辑网络,当几个计时器同时归零,也就是多个像素重合,那么就会让优先级最高的寄存器发光。)
其利用数据库的先验机制来计算多边形簇的固定优先级,如果一组多边形相对位置不变,就形成了一个簇,并被赋予固定的优先级,无论从哪个角度观察该簇,该优先级都有效,所以就形成了部分优先级排序与环境无关,无需重新计算。(文中该数据库指的是3D场景中的所有几何数据,包括顶点坐标、多边形面片、空间位置关系,将这些数据在渲染前提前放在系统中,称为先验。例如:当前场景是静态不变的,算法就在后台把场景分为不同的多边形簇,通过几何分析,提前算出簇之间的遮挡关系,比如无论什么角度,簇A永远不可能遮挡簇B,那么就给簇B分配更高的优先级,那么在移动的时候,就不需要对所有多边形进行距离计算与排序,按照固定的优先级按照顺序即可。)
其次证明,如果环境受到限制,聚类线性可分,则建立一种聚类间优先级,该优先级只有在视角穿过其中一个分离平面才会改变,因此,除非穿过其中一个平面,否则优先级顺序在每一帧之间保持不变。( 这边的线性指的是直线或者平面,lz给数学的思想带歪了好久没搞懂。将这个平面插入3D场景中,平面一侧只有聚A,另一侧只有聚B,且不会切割任意一个多边形,叫做聚类线性可分。我们将聚A看作沙发,聚B看作柜子,当摄像机在左侧,那么摄像机无论怎么移动,沙发永远不会被柜子遮挡,那么优先级A > B。但除非穿过平面,那么集合几何关系就会被打破,优先级发生改变)
Depth-last sort.(深度后置排序)
Clark并没在这边多写什么,只是简单的提了Watkins算法利用扫描线一致性和对数深度搜索,这边就直接略过了
Parametric Surface Algorithms(参数曲面算法)
使用多边形集合对光滑曲面进行建模会导致曲面着色和轮廓边缘渲染问题。Catmull算法对于每个图像块都会询问是否该图像块跨越了多个栅格单元,若肯定,则细分为四个图像块,并递归地对这些图像块询问相同的问题。直到否定才尝试将所得的图像块强度和深度坐标写入栅格单元的缓冲区。如果缓冲区已经存在一个更接近摄像头的深度坐标,那就不会写入。(这个算法lz认为还是蛮好理解的,所以就不再解释了喵)
Catmull的算法的显著特点是,尽管其数学原理更为复杂,但若是仅占据一小部分区域,那么速度将会比基于多边形算法更快,由于采用递归,它对表面的结构化精细程度不会超过显示器分辨率。
Hierarchical Approach(层级式方法)
图形学小白的lz从前面相关算法啃到现在,终于到该论文重点了(哭)
回到论文,Clark指出可见表面算法最卓有成效的成果来自于渲染环境的结构化。但是这种结构多种多样,需要一种统一的方法,能够概括这些算法的思想。在探讨前,先了解利用结构来用于可见表面处理对象的两种方式
Existing Uses of Structure(现有结构用途)
Defining relative placement(定义相对位置).
大多是可见表面算法都预先定义了位置或运动结构来描述彼此之间的相对位置和方向,但除了第二节中提到的少数几种方法外,所有方法都在可见表面算法层面上忽略了这种结构。也就是说组成物体的所有多边形都被转换到可见表面算法运行的屏幕坐标系中。
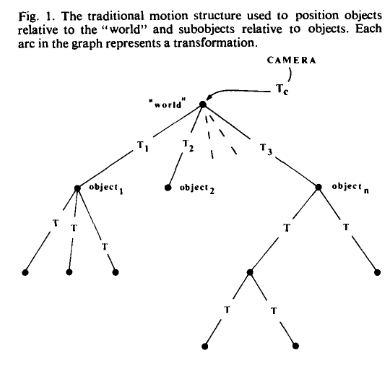
图1展现了这种结构的示例,层级结构的每一个节点代表一组定义该节点的几何图元,通往该节点的弧线代表一个变换,该变换定义了节点相对于父节点的方向和位置
Decreasing clipping time(减少裁剪时间)
这可以通过两种方式实现:一是将每个物体的所有几何图元转换到相机或屏幕坐标系中,然后分别对每个图元进行裁剪;二是先裁剪物体的某个保卫体积,看看它是否与视野边界相交。(lz觉得这个方法好像没什么重要的,半懂不懂的直接就略过了)
New Uses of Structure(结构的新用途)
对于具有一定细节量的物体,可以设定一个最小观看距离,在该距离下物体能够呈现逼真的渲染效果,比如从足够远的距离看,十二面体看起来就像一个球体。因此只要从该距离或更远,就可以拿球体来进行建模,但是如果需要近距离观察,就需要呈现出十二面体。那该如何解决这种远近观察的差别?在第二节中相对粗略地定义物体是解决问题的方法,但是必须使用多层次的结构才能充分表示复杂结构。所以为了表示这些多层次描述,Clark定义了一个如下图2所示的有根树
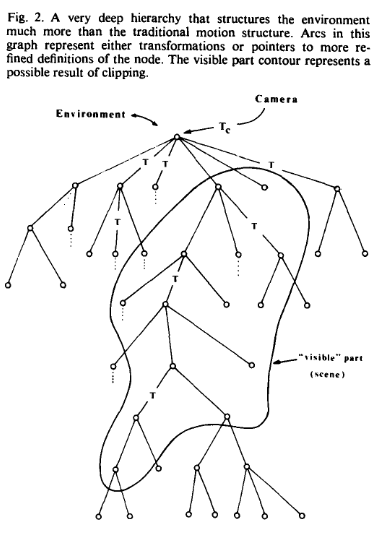
(树中有两种弧:一种是代表局部到整体的空间变换关系,记录子节点相对父节点的平移、旋转和缩放。另一种是细节结构的指针,代表同一物体的不同精度层级)
每个非叶子节点如果仅覆盖显示屏上的一小部分区域,则表示“对象”的“充分”描述,从节点延伸出的弧线指向更详细的“对象”,如果原始对象的描述不足以覆盖更大的屏幕区域,这些对象共同定义了原始版本的最详细版本。树的叶子节点表示组成多边形或曲面片。(把对象看作物体,当物体被放大到一定程度的时候,需要组成的多边形也就越多,细节也就更丰富,缩小反之)。
比如,一个人体在很远观察时只需要占据3-4个栅格单元,只需一个颜色合适的矩形多边体建模即可,如果进行近距离观察,假设最上层节点占据了16个栅格单元,那么最上层(最简陋)的描述就不再足够,需要更精细的描述,那么树就会往下走,直到对象的描述“足够”或到达叶子节点,比如下方Gemini生成的实例
0423
所描述的物体只是环境或者更大层级结构中的“对象”,并可能存在许多这样的物体或其他对象。在复杂环境中,关于环境中各种对象的信息量会根据这些对象占据视野的比例而变化。Clark指出前一节的Catmull算法就隐式地构建了这一结构,即使表面数学运算复杂,但如果仅占据一小部分,其性能仍优于多边形算法.
Clipping: a truncated logarithmic search(裁剪)
这种树结构带来了另外的问题:如何从非常大的层级结构中,选择在视角和观看设备分辨率下有意义的部分?这意味着要找如图2所示的树的可见节点。途中所示的轮廓代表视野范围内可能存在的一组物体,为了高效地执行裁剪操作,必须提供物体尺寸的基本描述信息。例如,提供物体的边界矩形框或边界球体就足以判断物体是否完全位于视野内或视野外,最基本的必要信息时边界球体的中心点和半径。
因此,这种总体结构暗示了一种非常快速的裁剪算法,递归遍历树状结构,并将这些最小信息转换为透视坐标,并测试边界球体占据的面积及其与视野边界的交集。向下遍历每一层的标准是面积测试,而纳入或拒绝的标准是视野边界测试。只有当面积测试终止向下遍历或到达最底层时,才需要对节点表示的多边形或曲面片进行实际的变换。所以该裁剪类似于对数搜索,搜索过程有面积测试截断。
Graphical working set.(图形工作集)
由于该模型解决的是生成复杂环境的图像和图像序列的问题,因此必须要有能够容纳描述这些环境特征的大量存储空间。Clark使用Denning的working set(工作集) 。对及时访问存储器(内存)需求过高的计算机程序会被结构化或分段,使得只有最近使用的段才会保存在及时访问存储器中,其余部分则放置在辅助存储器(磁盘)中。这些段通常由过去程序引用的时间平均值定义,对未被引用的段引用会使其变为工作集的一部分,而一段时间未被使用的段将被删除。(上过数据结构课的读者应该很熟悉这个思路,反正lz在阅读这段的时候去年的记忆就来攻击我了)
这种工作集结合上文所述的裁剪概念,实现了特定类型的帧一致性提供了一种合适的方法。Clark将工作集变换车工层级结构中“靠近”视野、位于视野内部或“靠近”图像空间分辨率的对象合集,只有当对象属于该几何时,其描述才会保存在内存中。当场景差异较小时,集合的变化会比较缓慢,当视野快速运动而导致的大差异场景,可以通过降低对象的细节渲染来解决。所以,这种最小裁剪描述必须始终保存在内存中以便于确定工作集。(其中这个最小裁剪描述其实是根节点或浅层节点,而不是叶子节点。它的意思是,最小能够包围该对象的“包围盒”)为更好的理解,Genimi生成了如下图像
QQ录屏20260423215744
Improving existing algorithms(改进算法)
Clark指出有两种方法能够改进现有算法,一是减少排序所需要的比较次数,二是排除对象遮掩。(根据什么排序?根据节点距离摄像机的远近距离排序。为何排序?解决这趟与透明度混合、遮挡剔除、优化工作集,有些下文会提到)
现在考虑一个理想场景二叉树,树的每个节点关联着一个包围盒,叶子节点均不重叠,如下图3所示
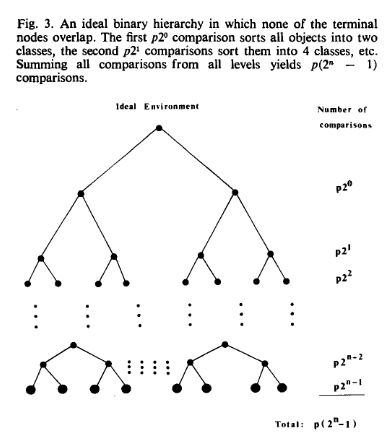
使用快速排序对这些叶子节点需要进行次比较,第一层要
第二层要
以此类推,将所有操作数相加,得到总次数为
。
另一部分改进是深度结构化,可以消除因物体遮挡导致结构中可能存在的较大部分,这种改进需要为每个物体定义一个遮挡体积A和遮挡体积B,如果A被遮挡,则整个物体都被遮挡。
Recursive descent, visible surface algorithm.(递归下降可见表面算法)
在该算法中,每一层都根据所有对象的边界体积(包围盒)进行排序,如果任何边界体积在横向和纵向上都有折叠,那么遮挡测试可能会是一个或多个对象及其所有后代对象完全从考虑范围中排除。(这好像是真的剪枝)
利用获得的排序结果,对这些对象的每一个后代递归地使用相同的排序和遮挡测试,如果两个或多个对象的边界体积在所有三维上重叠,则这些对象的后代是为在下一层递归中具有相同的父节点(相当于这两个对象在同一个包围盒中),直到到达叶子节点,并最终的结果是对叶子节点进行快速排序
Building structured databases(构建结构化数据库)
通过仔细测量真是物体、从简单的数学对象集合“构建”物体或通过三维曲面雕刻获取的数据库,其价值至少与渲染它们的可见表面算法相当。通过现有对象进行巧妙的“自下而上”的精简生成多个描述(多边形),从这些“自下而上”来获得对象粗略、高层级的描述,二通过“自上而下”地分割曲面片,则可以获得对象精细、底层级的描述(lz感觉这一段没什么东西,就是在构建数据库的时候完成分割,减少渲染时的压力)
lz在阅读时产生的一些问题,不知道插在哪里
上面最后一节后就是结语了,就是Clark这篇论文提供了一种可以根据尝尽中物体所占据的屏幕区域以及摄像机速度来调整场景中的细节程度,并利用图形工作集来实现帧一致性,从而快速访问物体。之后就是lz阅读时产生的问题,问了Gemini后的相关解答
Q:既然节点对应的是物体的包围盒,那么在3D空间中,若是这个包围盒后面还有一个被遮挡的包围盒,那么这个被遮挡的包围盒是它的兄弟节点还是子节点还是直接被剪枝剪掉了
A:大概率是前者的兄弟节点或表兄弟节点,并在运行时被剪枝剪掉了
Q:在该论文的后续提到了对节点进行快速排序来改进,这边将树的节点也就是图像进行排序是因为什么?是因为要对图像离摄像机的远近进行区分,进行图像细节的生成吗
A:排序确实是为了区分远近。 但它的核心目的不是为了“生成细节(LOD)”,而是为了“决定渲染的先后顺序(解决透明度)”和“判断能不能干脆不画(遮挡剔除)”,只要父节点被前方的物体遮挡了,系统就不需要再费心去对子节点进行任何操作了
Q:那么这个排序是排当前父节点下的子节点离摄像机的距离吗,排序的大小决定了该子节点靠左还是靠右
A:确实是当前父节点下子节点的距离,但物理内存顺序是定死的,数据结构是不随视角变化的,就像公司的组织架构图,无论老板今天从哪个门进办公室,部门经理下面的员工名单顺序是固定的。而变化的是临时的渲染队列,当计算各个物体的距离后,算法在内存里新建一个临时列表,按照距离塞进去,渲染管道拿着临时队列进行相交测试和逻辑渲染
Q:Recursive descent, visible surface algorithm. The above considerations suggest a totally new recursive- descent visible surface algorithm in which at each level all objects are sorted according to their bounding volume
下文好像提出了对于对象边界体积进行排序,这跟上面的距离排序有什么区别或联系吗
A:这两者本质上是同一件事,但描述的侧重点不同,它的真正含义是:“提取这些包围盒的空间坐标,并以此来代表整个物体进行距离排序 (偷个懒喵,直接拉Gemini的回复)


AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 9
9 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)