斯坦福-CS236 Lecture 15 生成模型的优劣评估 PPT标注
·
 序言:没办法做到完美,但尽量涵盖
序言:没办法做到完美,但尽量涵盖
-
生成式模型评估的核心思路

- 根据目标任务选择对应的评估方法;
- 密度估计:评估模型对数据分布的拟合程度;
- 数据压缩:评估模型的编码效率(如平均编码长度);
- 采样 / 生成:评估生成样本的质量;
- 隐变量的学习:评估学到的特征在下游任务中的迁移能力。
-
如果你很关心密度估计

对数似然越高,说明模型对真实数据分布的拟合越好;
- 密度估计几乎是与数据压缩效率等价的,一般使用平均编码长度衡量压缩效率,而平均编码长度为
,直观点的理解就是越常出现的符号用短编码,越不容易出现的符号用长编码,比如摩斯密码;
- 最后给出了一个在GPT中也常用的评估标准即困惑度,相当于是
-
我们真的关心压缩吗

- 答案是肯定的,如果你要做到很好的压缩率,你需要能够识别数据中的冗余和结构等;
- 比如F=ma,如果你理解了这个公式,就不需要去记录数据而是通过公式就能算出来,相当于另种的数据压缩
- 人类在文本上的理论极限:约 1.2~1.3 比特 / 字符,而大型语言模型(LLM)的表现:2019 年就已经实现了 0.94 比特 / 字符的压缩效率,超过了人类的理论水平。
-
不是所有模型都有压缩效率这一项的

- 变分模型、生成对抗和基于能量的模型都没有似然性;
- 对于变分模型可以使用ELBO作为评估;
- 而生成对抗模型需要使用一种叫核密度估计的方式;
-
核密度估计
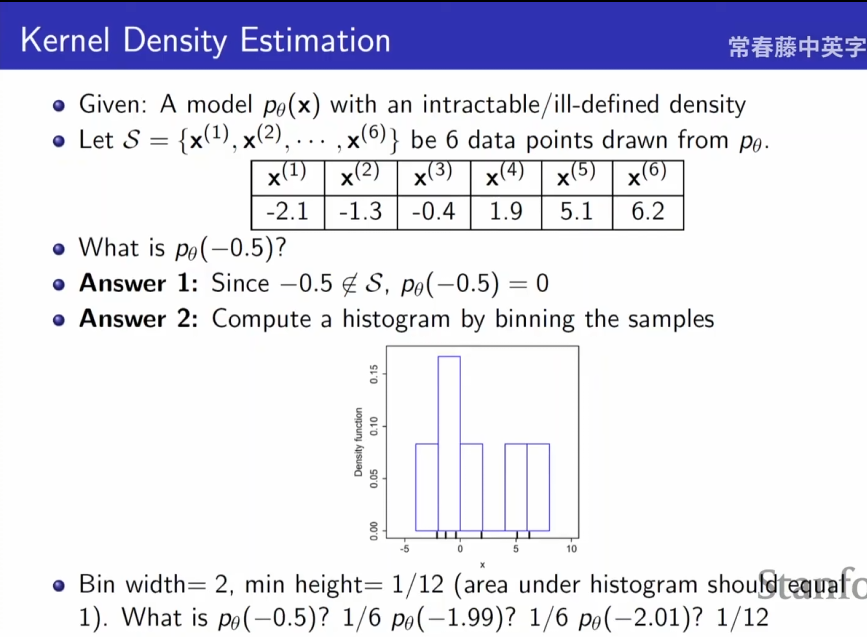
- 如果样本中没有你想要的样本的概率密度,可以通过现有样本先画出直方图,然后通过直方图近似估计-0.5的概率分布;
-
通过直方图来看还是不够平滑
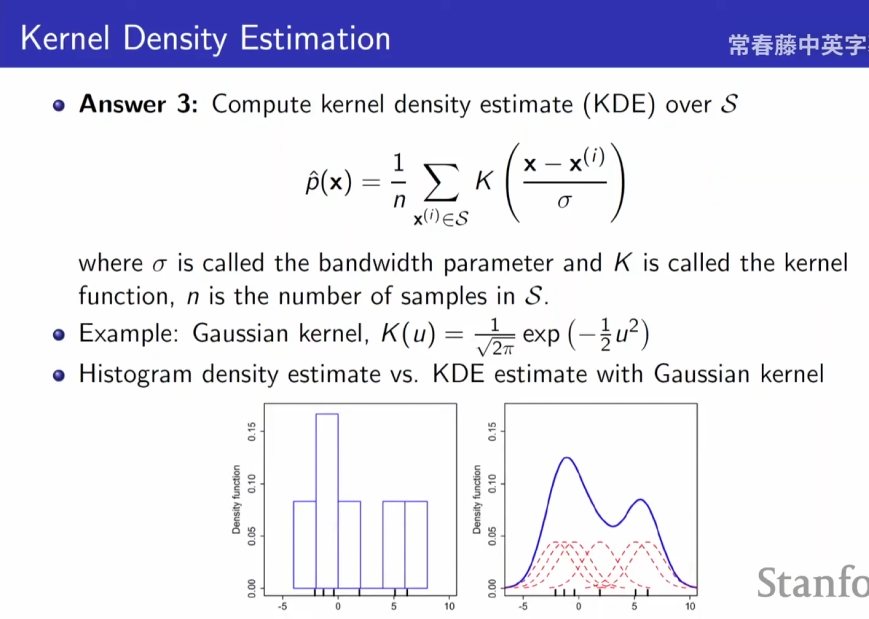
- 高斯核最常用,以高斯核作为的实例,让直方图变得更加的顺滑了;
- 相当于使用多个高斯叠加形成的平滑图形;
-
核函数的选择
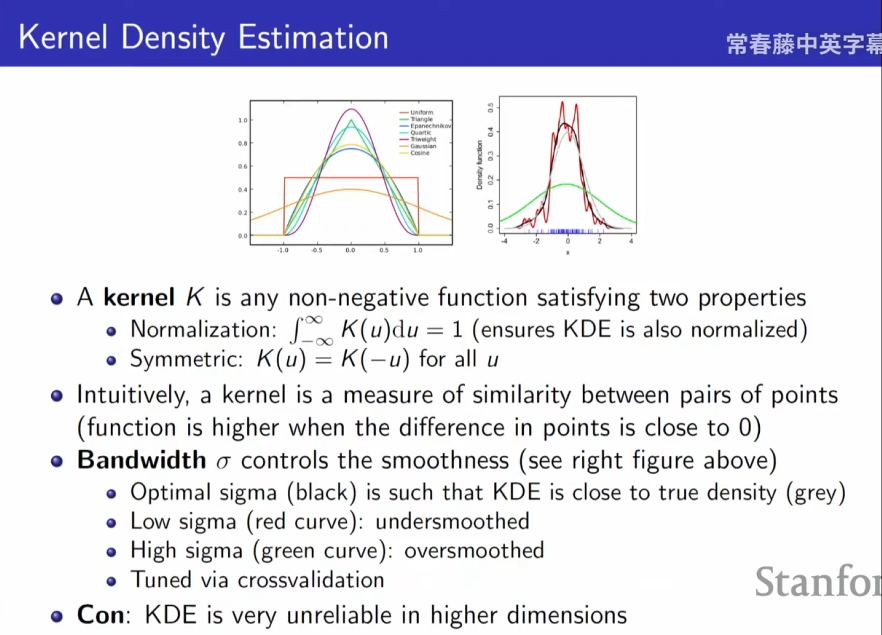
- 核函数K的两个要求,一个是积分为1,另一个是对称的;
- 不同的
如上面右边那个图,红线表示
- 但是一旦进入高维空间后,KDE会变得不可靠了。
-
AIS

- 评估带隐变量的模型优劣一般用分布对数似然,一般带隐变量的变分模型,样本分布的对数似然算不出来
- 我们目的是要求p(x)来评估模型优劣,但是VAE输出的是p(x|z)分布的参数,要求p(x)还得积分求,这个积分算不出来,因此先以Z1为起点去近似Z2,其中Z2为p(x)即p(x,z)对z的积分,Z1为p(z)的积分恰好为1,将Z2/Z1拆解为
,假设有个参数t,对于Z1.4的分布为
,对于Z1.6的分布为
,Z1,8的分布为
,参数都带入后,
,期望再用蒙特卡洛近似,就能算出Z2/Z1的值,又因为Z1 = 1,就得到Z2,Z2就是p(x),就近似评估出了VAE模型的优劣,p(x)越大越好;+
-
基于样本质量的评估

- 如果要评估样本质量很难,一种是让真人看多长时间能分辨出真假图,但这种方式不显示,最后推了集中方式,比如Inception Scores等。
-
Inception Scores
-
清晰度

- 主要开生成图片得清晰度怎么样来评估优劣,可套用公式S计算单张图片在分类器下得熵,越大图越清晰
-
多样性

- D就是多样性的计算公式,最后汇总了S计算IS,IS越大样本质量越好
- (IS) 只从生成分布 pθ 采样,没有直接考虑真实数据分布;这是它的缺陷。
-
-
Frechet Inception Distance

- 需要一个预训练好的分类器,提取模型生成的图片和真实样本的特征,两个都拟合成多维高斯,再使用Wasserstein-2距离计算两个高斯之间的距离,越近则性能越好;
-
kernel inception distance

- 核函数(如高斯核),把数据映射到高维特征空间,然后比较分布的矩(均值、协方差等)差异;
- MMD第一项:分布 p 内部样本的平均相似度;
- MMD第二项:分布 q 内部样本的平均相似度;
- MMD第三项:p 和 q 之间样本的平均相似度;
- 最终 MMD 值越小,代表两个分布越相似;
- KID就是加了MMD的FID;
-
评估潜在表征

- 无监督表征的三大核心评价指标:聚类性、压缩效率和解耦性;
-
聚类性
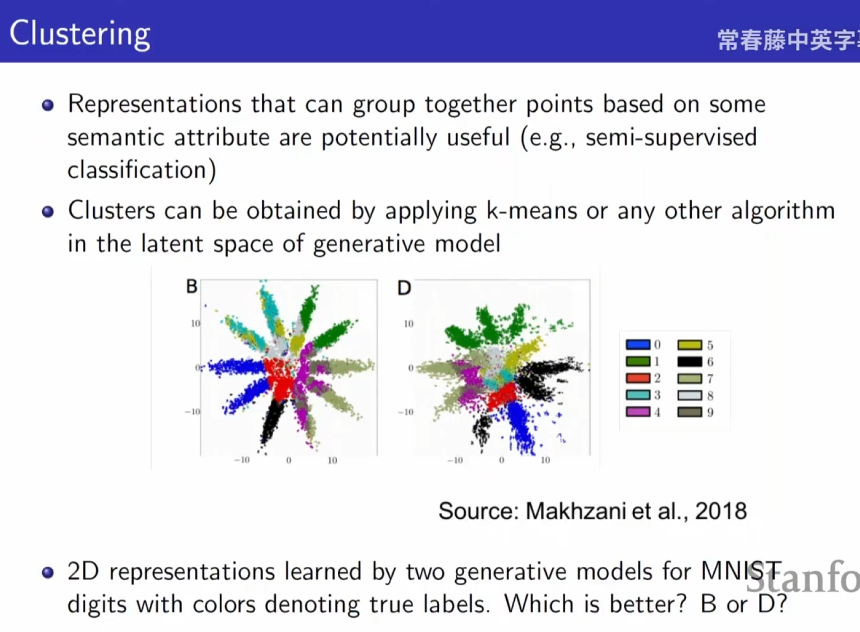
- 直接在生成模型的潜在空间中运行 k-means 等聚类算法,再用聚类指标(如轮廓系数、ARI)量化效果,并不好说你更喜欢B还是更喜欢D;
-
有损压缩和重构

- 一个优质的潜在表征,应当能在尽可能低的比特率 / 高压缩比下,仍能还原出高质量的原始数据
-
解耦性

- 比如肤色有肤色的Z,年龄有年龄的Z,不会互相影响;

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 8
8 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)