RAG真被“替换”了?Mintlify造出ChromaFs假文件系统:冷启动46秒砍到100ms!
导读
【导读】Mintlify在官方工程博客披露:为了让AI文档助手像开发者读代码仓库一样“逛文档”,他们用ChromaFs给模型“造”了一个虚拟文件系统,把会话创建p90从约46秒压到约100毫秒,还宣称边际计算成本接近0——这套“幻觉文件系统”,可能会把RAG的玩法彻底改写。
💥 用户盯着转圈46秒:真沙箱太强,也太贵
做文档助手最尴尬的场景是什么?
你问一个跨多页的配置问题,答案散在几篇文档里;或者你要的是某个精确字符串/精确语法。传统“检索Top-K chunks → 拼上下文”的路子,很容易漏掉关键段落。
Mintlify在官方博客里写得很直白:
“Our assistant could only retrieve chunks of text that matched a query. If the answer lived across multiple pages, or the user needed exact syntax that didn’t land in a top-K result, it was stuck.”
「我们的助手只能取回与查询匹配的文本块。答案如果分散在多个页面,或用户需要的精确语法没有进入top-K结果,它就会卡住。」
那就给agent一个“真实文件系统”让它自己grep/cat/ls/find?
他们确实这么干过:起隔离sandbox、clone仓库、准备环境。
结果:前台用户等不起。
“Our p90 session creation time (including GitHub clone and other setup) was ~46 seconds.”
「p90会话创建时间(含clone与setup)约46秒。」
更离谱的是账单:官方按“850,000次/月对话”的量级估算,即使最小配置也会逼近每年7万美元以上的沙箱成本(还不算更长会话、warm pool等)。
🪄 关键一句话:Agent不需要真文件系统,只要“足够逼真的幻觉”
Mintlify把这次的灵魂结论写成了金句:
“The agent doesn’t need a real filesystem; it just needs the illusion of one.”
「Agent不需要一个真实的文件系统,它只需要一个像真的一样的幻觉。」
于是他们反其道而行:
- 文档本来就已经被索引、切chunk,并存进Chroma数据库(给搜索用)
- 那就把
ls/cat/grep/find/cd这些命令“截获”下来 - 把命令翻译成对Chroma的查询 + 缓存拼装
这套东西他们起了个名字:ChromaFs。
🔧 ChromaFs到底做了什么:让模型以为在敲命令,其实在查数据库
Mintlify的实现堆栈很清晰:
- 上层:LLM Agent(以为自己在跑shell)
- 中间:Vercel Labs 的just-bash(TypeScript版bash子集,负责解析/管道/flags)
- 底层:ChromaFs实现just-bash暴露的
IFileSystem接口,把“文件系统调用”翻译成Chroma查询
官方给出的结果也很炸:
“Session creation dropped from ~46 seconds to ~100 milliseconds … the marginal per-conversation compute cost is zero.”
「会话创建从约46秒降到约100毫秒……由于复用了既有基础设施,边际每次对话的计算成本为0。」
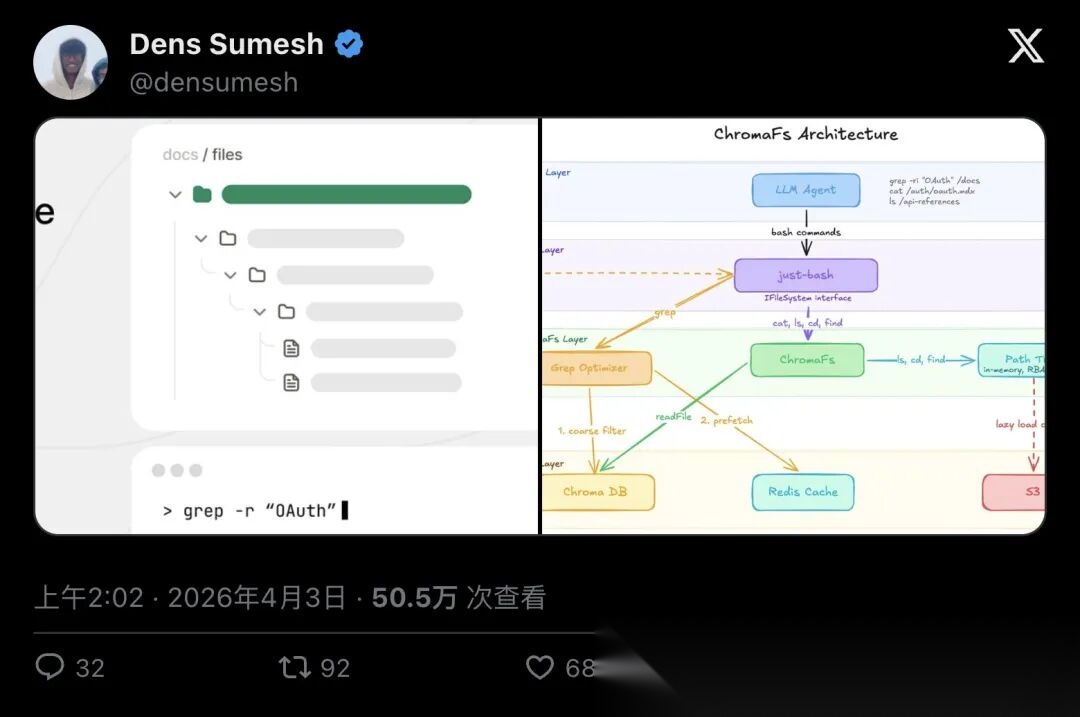
▲ Mintlify工程作者Dens Sumesh发的架构图:上面是agent,下面是Chroma/Redis/S3,中间用just-bash把命令“翻译”成查询
▲ Vercel CTO @cramforce:Mintlify assistant由just-bash驱动,并带自定义文件系统
📦 最狠的不是“快”,而是这套把文档变成“可探索”的结构
官方博客里,ChromaFs把“文档网站”硬生生映射成了一个只读文件系统:
1)先把全站目录树塞进数据库:\_\_path\_tree\_\_
他们把整个文件树做成gzip的JSON,用\_\_path\_tree\_\_作为标识存进Chroma。初始化时取出并解压到内存:
Set<string>:所有路径Map<string, string[]>:目录 → 子项
于是ls/cd/find几乎都能在本地内存完成,后续会话还会命中缓存。
2)RBAC顺手解决:先剪枝路径树,agent连“路径名”都看不到
路径树里带着isPublic和groups字段。
Mintlify的做法是:在构建文件树之前,根据用户session token把没有权限的路径剪掉;后续所有Chroma查询也再做过滤。
这带来一个产品层面的狠招:越权风险不是靠“容器里chmod配到头秃”去堵,而是在‘目录树这张地图’上直接抹掉禁区。
3)cat读整页:按chunk\_index把碎片拼回“完整文件”
文档页在Chroma里是chunk化的。
当agent跑cat /auth/oauth.mdx,ChromaFs会:
- 查出同一page slug的所有chunks
- 按
chunk\_index排序 - join成完整页面
- 缓存结果,避免重复读取
4)写操作一律报错:EROFS(只读)
官方写得很绝对:所有写操作直接抛EROFS(Read-Only File System)。
好处也很工程:无状态、不用清理session、不会互相污染。
⚡ grep才是地狱模式:他们用“粗筛+预取+内存精筛”硬把它拉回毫秒级
在“文件系统隐喻”里,grep是最容易炸的:递归扫文件、跨网络拉内容,慢到离谱。
Mintlify的做法是三段式:
1)粗筛:截获just-bash的grep,用yargs-parser解析flags,把查询翻译成Chroma过滤:固定字符串用$contains,模式用$regex
2)预取:把可能命中的chunks bulk prefetch进Redis cache
3)精筛:把grep改写成只针对命中文件,在内存里做最终匹配
官方结论:大型递归grep可以跑到毫秒级。
▲ Chroma官方账号:ChromaFs把Chroma变成agent的虚拟文件系统,取代有状态sandbox
🔥 HN吵翻了:RAG里的“R”,很多人其实一直理解错了?
这篇文章在Hacker News的讨论区引爆了一个老话题:
很多人把RAG默认等同“向量检索+Top-K chunk”。
但HN评论区有人直接把定义掰正:
“R in RAG stands for retrieval … Nothing in RAG implies vector search and text embeddings …”
「RAG里的R是Retrieval(检索)。它可以是网页搜索、SQL查询、grep、目录遍历……并不天然绑定向量检索与embedding。」
还有人给出一个更尖锐的洞察:
“The directory hierarchy is already a human-curated knowledge graph.”
「目录层级本身就是人类预先整理过的知识图谱。」
换句话说,Mintlify真正“替换”的并非Retrieval,而是把检索锁死在某一种实现上的那条窄路。
🧯 100ms别被带跑偏:快的是“会话创建/启动”,不是回答速度开了外挂
这里有个特别容易被误读的点:
-
46秒 → 100ms
指的是“会话创建/启动”层面的冷启动(clone、setup、起sandbox)被移走了
-
模型推理、数据库查询、缓存命中等依然有成本
-
官方说的“边际成本为0”,更多是指:不再为每次对话额外起一套沙箱/微型VM
把这层说清楚,文章更抗挑刺。
🚪 下一波文档助手的分水岭:从“喂chunks”到“给工具,让它自己探索”
Mintlify这套ChromaFs让人后背发凉的地方在于:
它把“文档”从一堆碎片,重新变成了一个可遍历的结构世界。
对agent来说,最自然的交互层可能会持续向这些“可组合工具”收敛:
ls先看地图find定位范围grep锁定线索cat读全页- 再用LLM把线索组织成答案
当工具链变得足够便宜、足够快,很多团队会开始问同一个问题:
我们还要不要为“每个对话起一个真实sandbox”买单?
学AI大模型的正确顺序,千万不要搞错了
🤔2026年AI风口已来!各行各业的AI渗透肉眼可见,超多公司要么转型做AI相关产品,要么高薪挖AI技术人才,机遇直接摆在眼前!
有往AI方向发展,或者本身有后端编程基础的朋友,直接冲AI大模型应用开发转岗超合适!
就算暂时不打算转岗,了解大模型、RAG、Prompt、Agent这些热门概念,能上手做简单项目,也绝对是求职加分王🔋

📝给大家整理了超全最新的AI大模型应用开发学习清单和资料,手把手帮你快速入门!👇👇
学习路线:
✅大模型基础认知—大模型核心原理、发展历程、主流模型(GPT、文心一言等)特点解析
✅核心技术模块—RAG检索增强生成、Prompt工程实战、Agent智能体开发逻辑
✅开发基础能力—Python进阶、API接口调用、大模型开发框架(LangChain等)实操
✅应用场景开发—智能问答系统、企业知识库、AIGC内容生成工具、行业定制化大模型应用
✅项目落地流程—需求拆解、技术选型、模型调优、测试上线、运维迭代
✅面试求职冲刺—岗位JD解析、简历AI项目包装、高频面试题汇总、模拟面经
以上6大模块,看似清晰好上手,实则每个部分都有扎实的核心内容需要吃透!
我把大模型的学习全流程已经整理📚好了!抓住AI时代风口,轻松解锁职业新可能,希望大家都能把握机遇,实现薪资/职业跃迁~
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】


AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 11
11 0
0- 0



 已为社区贡献241条内容
已为社区贡献241条内容

所有评论(0)