solo-别再让AI写到一半失忆:这套 Harness 架构,正在把“短跑助手”变成“长跑工程师”
别再让AI写到一半失忆:这套 Harness 架构,正在把“短跑助手”变成“长跑工程师”
你给 AI 一个复杂任务,它第一轮写得很好,第三轮开始偏航,第五轮已经忘了最初目标。问题往往不在模型,而在你有没有给它一套能跨上下文窗口持续推进的工程外骨骼。本文拆解一套真实可运行的 harness 架构,讲清它为什么稳、怎么搭、如何迁移到你的项目里。

先把问题说透:为什么“聪明模型”仍然做不好长任务
大多数团队第一次用 AI Coding Agent,体验都类似:
- 开局惊艳,几分钟能产出可运行代码
- 中段开始漂移,重复改同一个问题
- 收尾阶段失控,修一个点牵出三个回归
这不是“模型笨”,而是任务生命周期和上下文窗口天然冲突。
单次上下文本质是短期记忆。任务一旦跨越多个会话,代理就会不断丢失状态:
- 它忘记上一个会话为什么这么改
- 它不确定哪些 feature 已经通过验证
- 它缺少可复盘的执行轨迹
你会发现,真正难的不是“让它写出代码”,而是让它持续在同一条工程主线上前进。
AI 代理在复杂项目里最大的问题,不是能力上限,而是连续性下限。
这也是为什么近两年大家都在谈 harness engineering。与其寄希望于一次完美 prompt,不如给代理一套制度化运行机制,让它每一轮都知道“我是谁、我在哪、下一步做什么”。

这套架构的核心:不是一个 Agent,而是“运行系统”
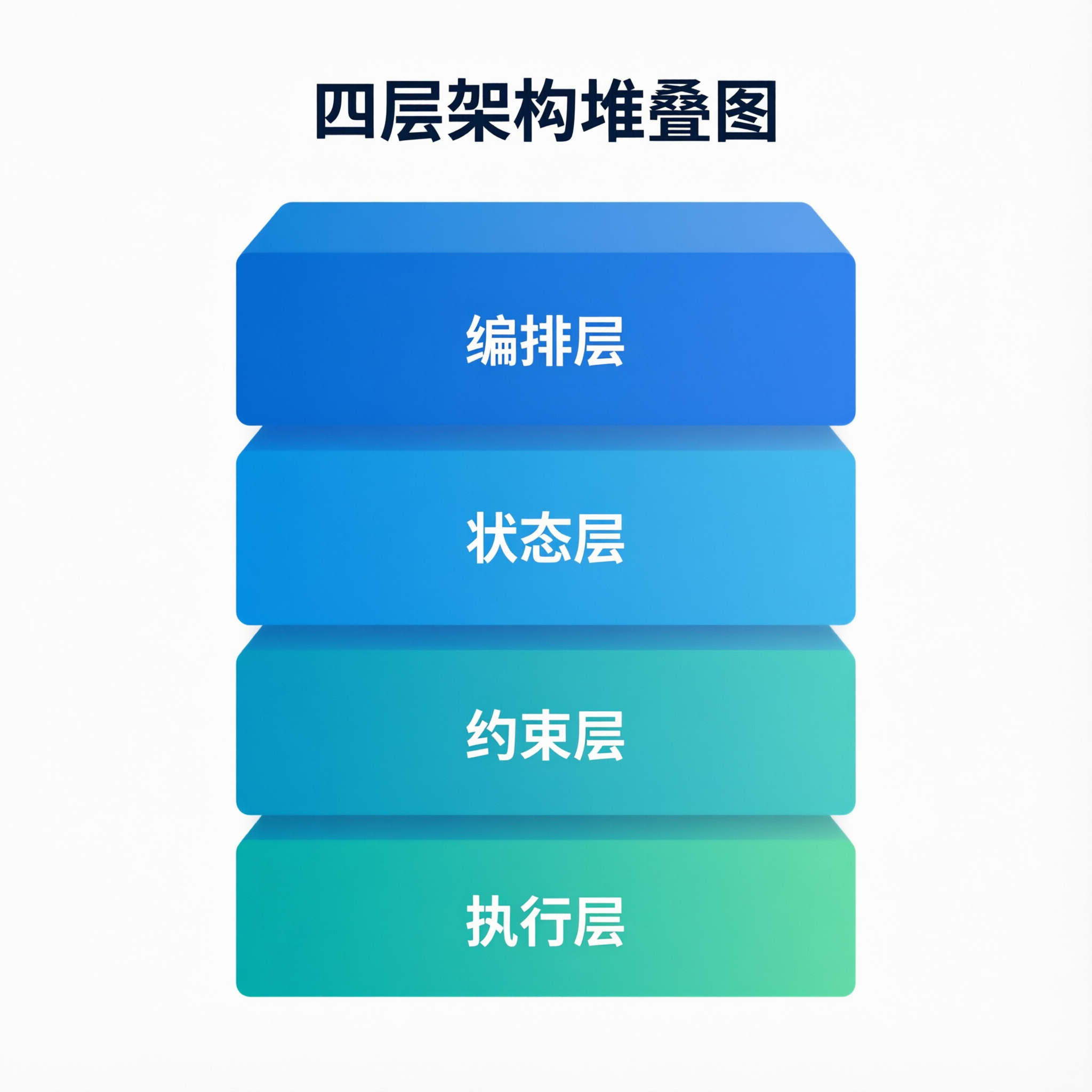
你给的 solo_runtime 代码里,最重要的不是某个单一模块,而是几个模块拼在一起形成了闭环。这个闭环可以概括成四层:
- 编排层:
harness/runner.py决定当前处于初始化阶段还是编码阶段 - 状态层:
harness/session.py和harness/features.py负责“记住进度” - 约束层:
plan/mode.py与hooks/registry.py对危险工具调用做门控 - 执行层:
loop.py驱动 LLM 与工具循环,按规则执行而不是随意执行
这就像把“能写代码的模型”升级成“有操作系统的工程体”。
在 HarnessRunner 里,流程很清晰:
- 如果没有
feature_list.json,走初始化代理 - 如果已有 feature 列表,进入编码代理循环
- 每次推进都会写入进度、更新状态、同步当前 feature
这意味着代理不是凭空工作,而是在一个显式状态机中工作。
从“生成答案”到“推进状态”,是 AI 工程化最关键的一步。
为什么它能跨窗口稳定推进:三份关键工件
很多人会把“记忆”理解成向量库或长上下文,但这套架构给了一个更实用的答案:先把关键状态落到文件。
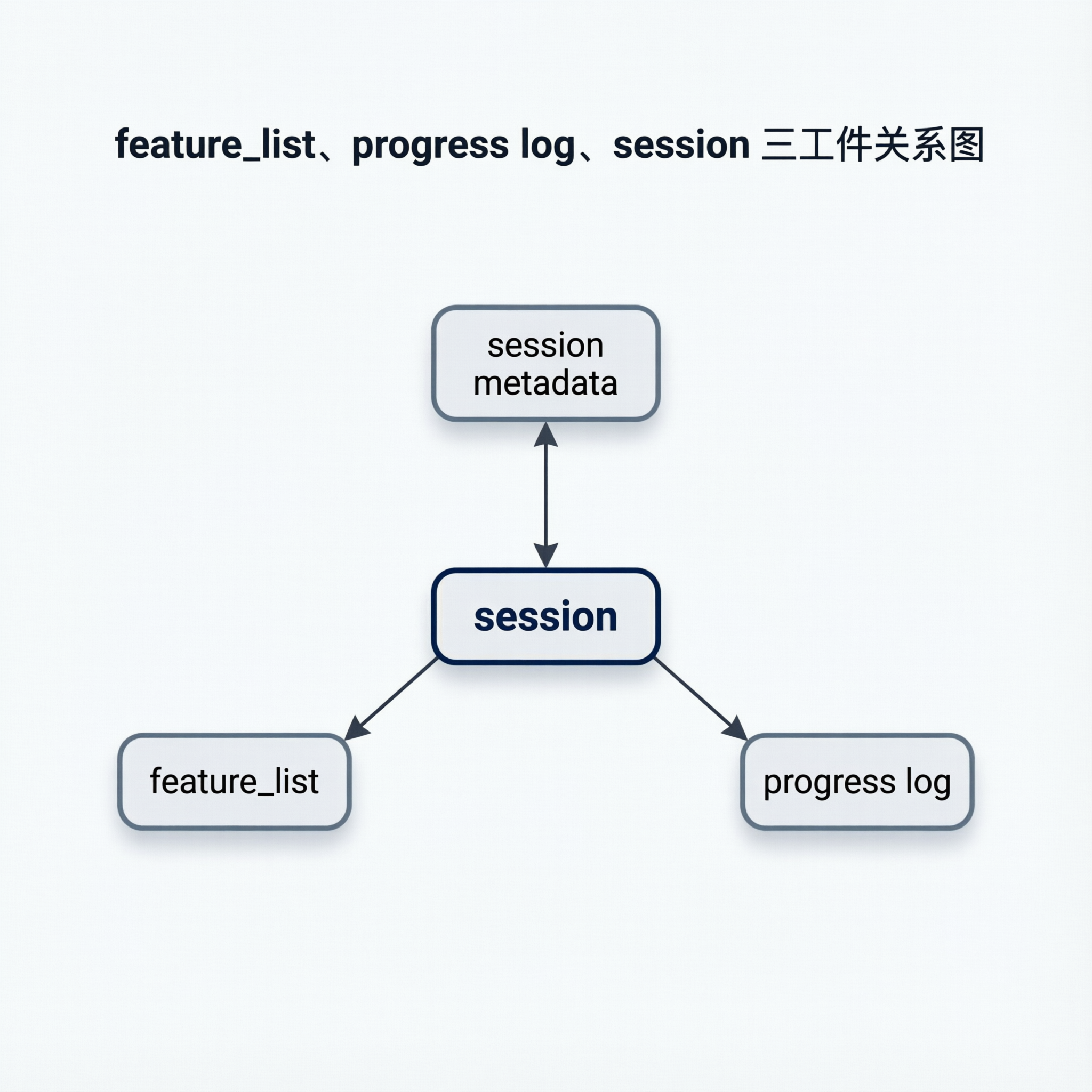
它依赖三份核心工件:
feature_list.jsonclaude-progress.txt.nanobot/session.json
三者分工非常明确。
1) feature_list.json:任务真相源
FeatureListManager 把 feature 做成了可机读状态机,状态包含 failing、in_progress、passing 等。代理每轮只做一件事:拿最高优先级待处理 feature,推进,再回写状态。
这解决了“代理一次干太多、最后什么都没验证”的常见问题。
2) claude-progress.txt:人类可读的操作日志
ProgressTracker 用 Markdown 记录每一轮动作、上下文窗口编号、状态结果。它不是数据库,却足够适合团队排障。
你回头看日志,能快速知道:
- 哪一轮开始偏航
- 哪个 feature 卡住最久
- 失败是逻辑问题还是环境问题
3) .nanobot/session.json:会话与阶段控制
SessionManager 把 phase、feature 计数、当前 feature、context window 次数持久化,哪怕进程重启也能续跑。
这点对长任务太关键了。没有 session state,重启一次就像失忆一次;有了它,重启只是换气,不是重来。
长任务稳定性,不靠“更长的上下文”,先靠“更硬的状态锚点”。
安全与治理:Plan Mode + Hooks 才是“敢放权”的前提
很多团队卡在一个矛盾里:不给代理权限,它做不动;给太多权限,它可能误伤仓库。
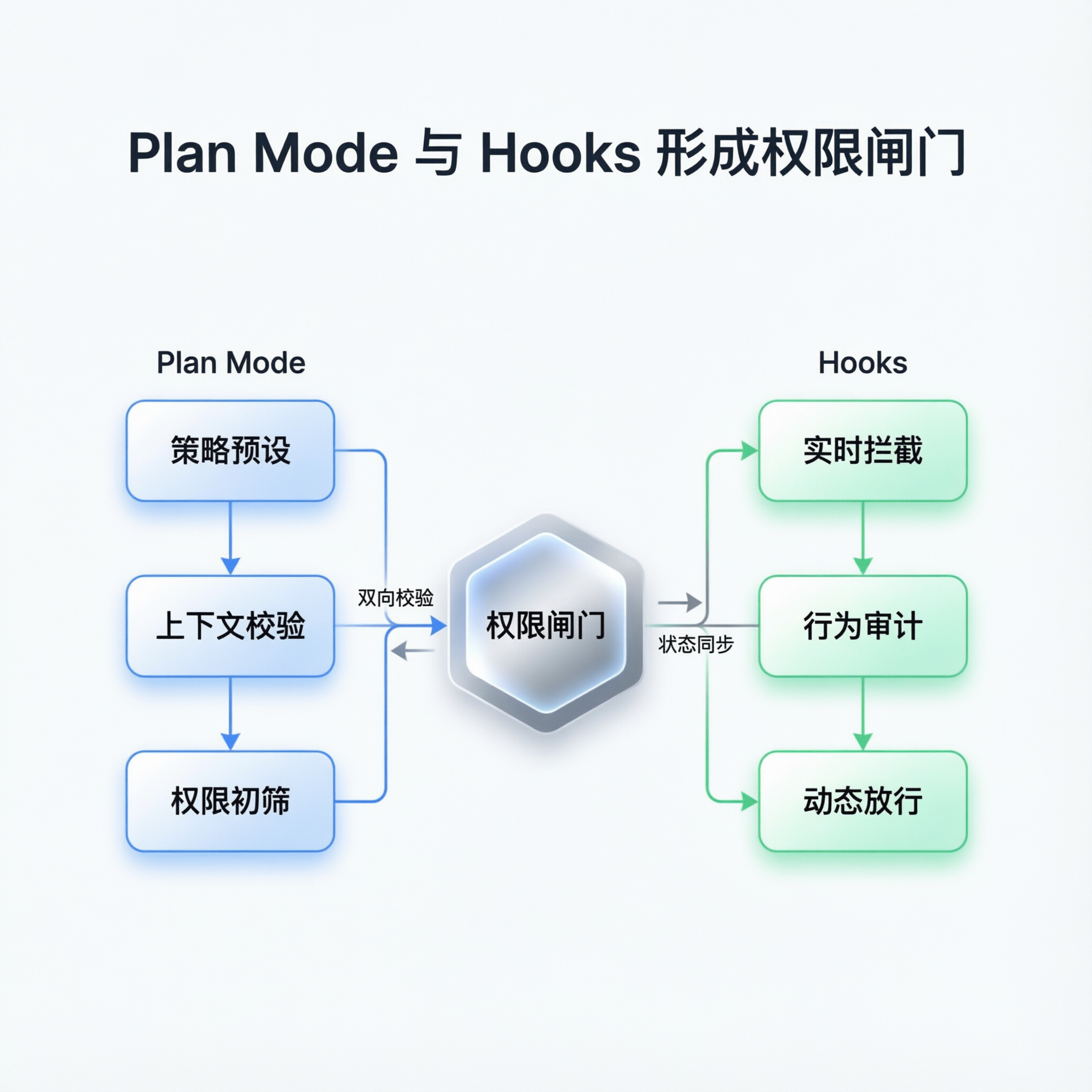
这套架构给的解法是“先计划、再执行”的权限切换。
在 plan/mode.py 里,plan mode 会限制写入和执行类工具,只保留读取与任务管理能力。代理先把计划铺出来,退出 plan mode 后才进入执行。
配合 hooks/registry.py 的 PreToolUse/PostToolUse,每次工具调用都可以被拦截、审计、阻断。
这相当于给 agent 加了一个“操作前闸门”:
- 先判断这步该不该做
- 再判断是否满足安全规则
- 最后才真正调用工具
对企业团队来说,这一层比“模型选哪家”更重要。因为生产事故从来不是由模型参数导致的,更多来自缺乏执行约束。
真正可上线的代理,不是最会写代码的代理,而是最会遵守边界的代理。
双代理分工:Initializer 负责打地基,Coder 负责持续施工
harness/presets.py 的提示词设计非常有代表性:它没有让一个 agent 包打天下,而是做了职责拆分。
- Initializer Agent:首轮只做环境初始化、feature 拆解、日志与初始提交
- Coding Agent:后续每轮按启动例程读取进度、选择 feature、实现、验证、提交
这种分工有两个直接好处:
- 第一次会话不再“边想边写边改”,而是先建立公共坐标系
- 后续会话不依赖上轮上下文全文,只依赖结构化工件与启动检查
你会注意到,Coder 的启动例程并不花哨,但非常有效:
- 读进度
- 读 feature 列表
- 看 git 历史
- 跑 init 脚本
- 做基础验证
这本质上是把“经验”写成机器可重复执行的 SOP。AI 代理一旦有 SOP,稳定性会明显上一个台阶。

对比行业实践:它为什么属于“能落地”的 Harness 形态
从公开资料看,这套设计思路与 Anthropic 在长任务代理上的实践高度一致:
- 首会话使用专门初始化提示词
- 通过进度文件和特征列表跨窗口传递状态
- 让后续 coding 会话按固定启动流程逐轮推进
不同之处在于,你这套实现把工程约束进一步前置到了 runtime:
- 有 plan mode 的权限切换
- 有 hooks 的调用拦截
- 有 session 文件的原子化持久化
也就是说,它不是“理念上的 harness”,而是“已经进入执行平面”的 harness。
如果你正在搭自己的 agent 平台,这里有三个可直接复用的原则:
- 先定义状态,再定义提示词:没有状态模型,再强提示词也会漂
- 先定义边界,再开放工具:没有门控,自动化等于自动冒险
- 先定义复盘,再追求速度:没有可观测性,效率提升不可持续
长跑代理不是“让 AI 一口气跑完”,而是“让 AI 每一段都可控地跑下去”。
写在最后
今天大家都在聊“哪个模型最强”,但真正决定交付质量的,往往是 harness。
模型是发动机,harness 是底盘。没有底盘,再强发动机也容易翻车。
你这套 solo_runtime 架构最有价值的地方,不是某个炫技点,而是它把长期任务拆成了可管理、可审计、可恢复的工程流程。它回答了一个非常现实的问题:
当上下文会过期时,AI 代理如何不失忆地持续做正确的事。
如果你也在做 AI Coding Agent,建议从最小版本开始:
- 先把
feature_list.json和 progress log 做出来 - 再引入 phase 切换与 session 持久化
- 最后加 plan mode 与 hook 门控
你不需要一次做完所有高级能力。先让代理“稳定地慢慢变好”,比“偶尔惊艳后全面失控”更有商业价值。

关键架构速查
- 核心编排:
HarnessRunner(按有无 feature 列表切换初始化/编码阶段) - 会话状态:
SessionManager(phase、window 计数、当前 feature 持久化) - 特性状态:
FeatureListManager(failing -> in_progress -> passing) - 进度记录:
ProgressTracker(可追踪、可复盘的人类可读日志) - 执行约束:
PlanMode+HookRegistry(先计划、再执行,调用可拦截) - 主循环:
AgentLoop(工具调用 gate + 迭代上限 + 错误收敛)
参考来源
- Anthropic Engineering: Effective harnesses for long-running agents
- Claude prompting guide: multi-context window workflows
- 代码实证:solo_runtime 源码模块(harness/session/progress/features/plan/hooks/loop)

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 8
8 0
0- 0



 已为社区贡献12条内容
已为社区贡献12条内容

所有评论(0)