本地跑LLM模型哪家强:Qwen3.5+3.6 vs Gemma4 的个人实测
文章目录
(零)前言
之前接触过GPT4All,Ollama,用过Deepseek和千问模型。
也开发过小的演示程序来进行RAG和联网搜索,但那时模型不够强,包括RAG总感觉没啥实际作用。
这次乘着Gemma4和Qwen3.6发布,我也想知道我的电脑上能部署啥模型。
于是舍弃了比较慢的Ollama,换了自己编译的llama.cpp + OpenWebUI。
名词解释:
💡 GPT4All
能在消费级CPU上本地运行的开源生态系统,用于训练和部署无需连接GPU或互联网的轻量化大语言模型。在普通用户和文档处理场景中更受欢迎。
💡 Ollama
轻量级、可扩展的框架,用于在本地一键式运行、管理和打包如Llama 3等开源大语言模型。在开发者生态和社区热度上更为主流。
💡 llama.cpp
用C++实现的轻量级推理框架,能在消费级CPU上高效运行量化后的LLaMA等大语言模型,也可以适配GPU,比如CUDA和其它架构。
📖 DeepSeek
深度求索公司创造的开源、高性能AI助手,支持超长上下文、文件上传与联网搜索,文本性能比肩全球顶尖模型。它也有视觉模型VL,VL2 tiny的体量不大,但暂时无法在llama.cpp框架下跑起来。所以这次先排除❌。
📖 Qwen3.6
阿里通义千问于2026年4月发布的新一代大模型系列,包含旗舰版Qwen3.6-Plus、MoE架构的Qwen3.6-35B-A3B以及专为本地部署优化的稠密模型Qwen3.6-27B,以旗舰级的智能体编程能力和原生多模态支持为最大亮点。
📖 Gemma4
谷歌于2026年4月发布的新一代开源大模型家族,基于Gemini 3同源技术打造,采用Apache 2.0协议,提供从端侧到数据中心的四种规格,其中31B版本以310亿参数登上全球开源模型排行榜第三名
(一)理论评测
硬件环境是i9-12900F,64GB-DDR4-3000,RTX-4060Ti-16GB。
用llama.cpp的命令行.\llama-bench -m LLM模型文件 -ngl 999,进行基准评测。
| 模型 | 文件大小 | 参数量 | 架构 | 量化 | pp512 | tg128 | 显存占用(无视觉) | 实际观察 |
|---|---|---|---|---|---|---|---|---|
| Qwen3.5-9B-Q4_K_M.gguf | 5.28 GiB | 8.95B | Dense | Q4_K_M | 2886.95 ± 43.07 | 46.79 ± 0.02 | 速度尚可,但容易陷入重复/死循环,稳定性较差 | |
| gemma-4-E4B-it-Q5_K_M.gguf | 5.09 GiB | 7.52B | Dense | Q5_K_M | 4477.40 ± 126.12 | 65.79 ± 0.05 | 小模型里很均衡,速度快 | |
| gemma-4-E4B-it-UD-Q8_K_XL.gguf | 8.05 GiB | 7.52B | Dense | UD Q8_K_XL | 4650.44 ± 185.74 | 44.30 ± 0.04 | 6.8GB | 高保真量化,decode 明显变慢 |
| gemma-4-26B-A4B-it-UD-IQ2_M.gguf | 9.28 GiB | 25.23B | MoE | UD IQ2_M (2.7 bpw) | 2938.30 ± 19.49 | 89.02 ± 0.22 | 10.6GB | RAG表现明显更强,decode 极快 |
| gemma-4-26B-A4B-it-UD-IQ3_S.gguf | 10.43 GiB | 25.23B | MoE | UD IQ3_S (3.44 bpw) | 2643.51 ± 11.70 | 79.57 ± 0.21 | 更高质量量化,加载视觉后显存吃紧 | |
| gemma-4-26B-A4B-it-UD-IQ4_NL.gguf | 12.48 GiB | 25.23B | MoE | IQ4_NL (4.5 bpw) | 2981.59 ± 106.44 | 67.71 ± 0.15 | 13.6GB | 16GB显存可能无法完全加载视觉 |
| Qwen3.6-27B-UD-IQ2_M.gguf | 10.09 GiB | 26.90B | Dense | UD IQ2_M (2.7 bpw) | 849.07 ± 7.90 | 22.40 ± 0.01 | Dense 27B 在16GB上明显偏重 | |
| Qwen3.6-35B-A3B-UD-IQ2_M.gguf | 10.72 GiB | 34.66B | MoE | UD IQ2_M (2.7 bpw) | 2394.80 ± 16.46 | 86.45 ± 0.06 | 11.6GB | Qwen MoE 后速度暴增,接近 Gemma4 A4B |
名词解释:
用gemma-4-26B-A4B-it-UD-IQ3_S.gguf为例子,它是一个 Gemma4 系列、260亿参数、MoE激活40亿参数、指令微调版、采用特殊动态量化、并使用 IQ3_S 3bit量化压缩的 GGUF 模型。
💡 Dense:Dense Transformer:稠密结构,所有参数层都参与推理。
💡 MoE:Mixture of Experts:混合专家结构
💡 26B:26 Billion Parameters :260亿参数规模
💡 A4B: Active 4B: MoE结构中“激活参数”约 4B
💡 it: instruction-tuned :指令微调版,适合聊天/问答
💡 UD: Unsloth Dynamic / Ultra Dynamic(常见推测): 一种特殊量化或动态量化方案标记,具体取决于发布者
💡 IQ3_S :Integer Quantization 3-bit Small :一种 3bit IQ 量化格式,IQ3比Q3更小更好,还有Q4_K,Q5_K,Q8_0等等。
💡 gguf :GPT-Generated Unified Format:llama.cpp 使用的量化模型格式
📖 pp512 : Prompt Processing(提示词处理阶段)输入长度为 512 tokens。
📖 tg128 : Token Generation(逐 token 生成阶段)生成 128 个 token。
(二)实际场景
(2.1)测试内容
(2.1.1)跳舞机图片识别
测试无RAG和有RAG(DDR和PIU简介文本)情况下能否回答。
呃,为啥不加联网搜索?试过,如果没有先判断为跳舞机,模型无法用正确关键词搜,搜的结果也无意义。所以干脆给提示加RAG。
又因为用了图,所以各个模型都加载了与之配套的视觉mmproj模型。
💡 RAG:Retrieval-Augmented Generation:检索增强生成:让大语言模型在回答前先从外部知识库检索相关信息,再基于检索结果生成答案的技术。
💡 mmproj :multimodal projector(多模态投影层):视觉模型接入 LLM 时,用来把图像特征转换成大语言模型能理解的token向量的桥接模块。
原始图片:
问题:
请问图中他们在玩什么街机游戏?小提示,注意脚下踏板的按键数量和位置排列。
正确答案的示例: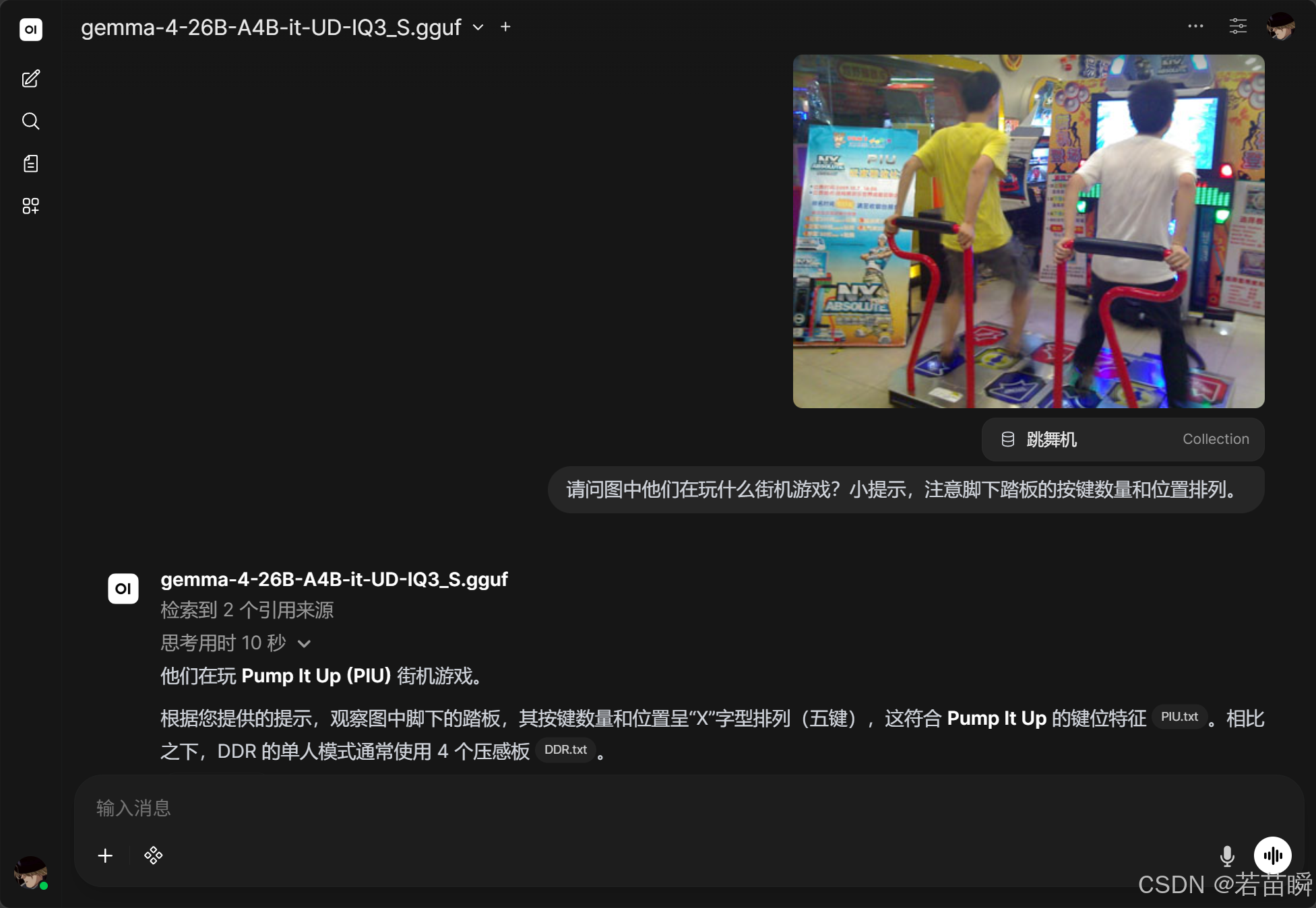
(2.1.2)企业文档RAG
共7个Word文档,总大小11MB左右,包含图和vsd等内容。
使用了BAAI/bge-m3,Chunk400,Overlap80,Topk3。
问题1:某某公司的某某系统支持哪些平台?
问题2:简要介绍某某系统。
(2.2)各个模型表现
gemma-4-26B-A4B-it-UD-IQ3_S 和 IQ2_M 差不太多,不单独列举了。
| 模型 | 企业文档 RAG 表现 | 跳舞机图片识别(无RAG) | 跳舞机图片识别(有RAG/提示) | 稳定性 / 特点 |
|---|---|---|---|---|
| Qwen3.5-9B-Q4_K_M | RAG效果较弱,容易遗漏信息;随便答部分内容 | 只能泛化回答“体感游戏机” | 因错误识别踏板为“上下左右4键”,在 DDR 与 PIU 之间反复纠结并进入死循环 | 小模型在视觉+推理链场景下不稳定;容易被错误前提带偏 |
| Qwen3.6-35B-A3B-UD-IQ2_M | Word 文档 RAG 两次回答都较正常,无明显问题 | 错误判断为 DDR;认为踏板是“上下左右4键”布局 | 即使有RAG也无法纠正视觉误判,但不会进入死循环 | 比小Qwen稳定,不会因矛盾信息无限循环;但视觉误判会导致最终答案错误 |
| gemma-4-E4B-it-Q5_K_M | 使用相同RAG资料时,曾只回答“系统有RHEL平台”等模糊结论,信息提取能力有限 | 能意识到是 DDR 或 PIU 一类跳舞机,但不确定 | 在RAG提示帮助下,能正确判断为 PIU | 小模型但推理比 Qwen3.5-9B 稳定;RAG可明显提升结果 |
| gemma-4-26B-A4B-it-UD-IQ3_S | 与 IQ2_M 类似,RAG结果准确且稳定 | 无需参考即可正确判断是 PIU,并指出“X型五键布局” | 即使不依赖RAG也能正确识别 | 当前测试中视觉+推理综合能力最强;稳定性高;适合作为日常主力模型 |
(2.3)跳舞机关键信息(视觉)
因为千问系列的视觉部分(mmproj)模型识别出了偏差,所以导致后续回答错误。
| 识别线索 | 重要性 | 说明 |
|---|---|---|
| 踏板布局(5键X型) | 极高 | PIU 与 DDR 的核心区别 |
| 屏幕箭头与判定区 | 极高 | 最可靠视觉证据之一 |
NX Absolute 字样 |
较高 | 可直接定位到 Pump It Up NX Absolute |
| 扶杆形状 | 中高 | DDR 更像小写 n;PIU 更像弯曲的大写 R |
| 机体外观 | 中等 | 可辅助判断,但改版机可能误导 |
| 玩家站姿 | 辅助 | 不足以单独判断 |
(2.4)总体结论
| 方向 | 观察结果 |
|---|---|
| MoE架构 | 在16GB显存下明显优于大型 Dense 模型,速度优势巨大 |
| RAG效果 | 不仅依赖检索质量,也依赖模型“读懂并利用上下文”的能力 |
| 小模型问题 | 容易被错误视觉前提带偏,并可能进入循环推理 |
| 大模型优势 | 更稳定、更善于结构化信息提取,也更不容易陷入逻辑循环 |
| 视觉识别 | “先看对”比后续RAG或搜索更重要;错误视觉输入会污染整个推理链 |
| 企业文档RAG | 固定chunk并不总有效;章节结构、表格、流程图本身都可能包含关键语义 |
(三)结束语
资源占用如图: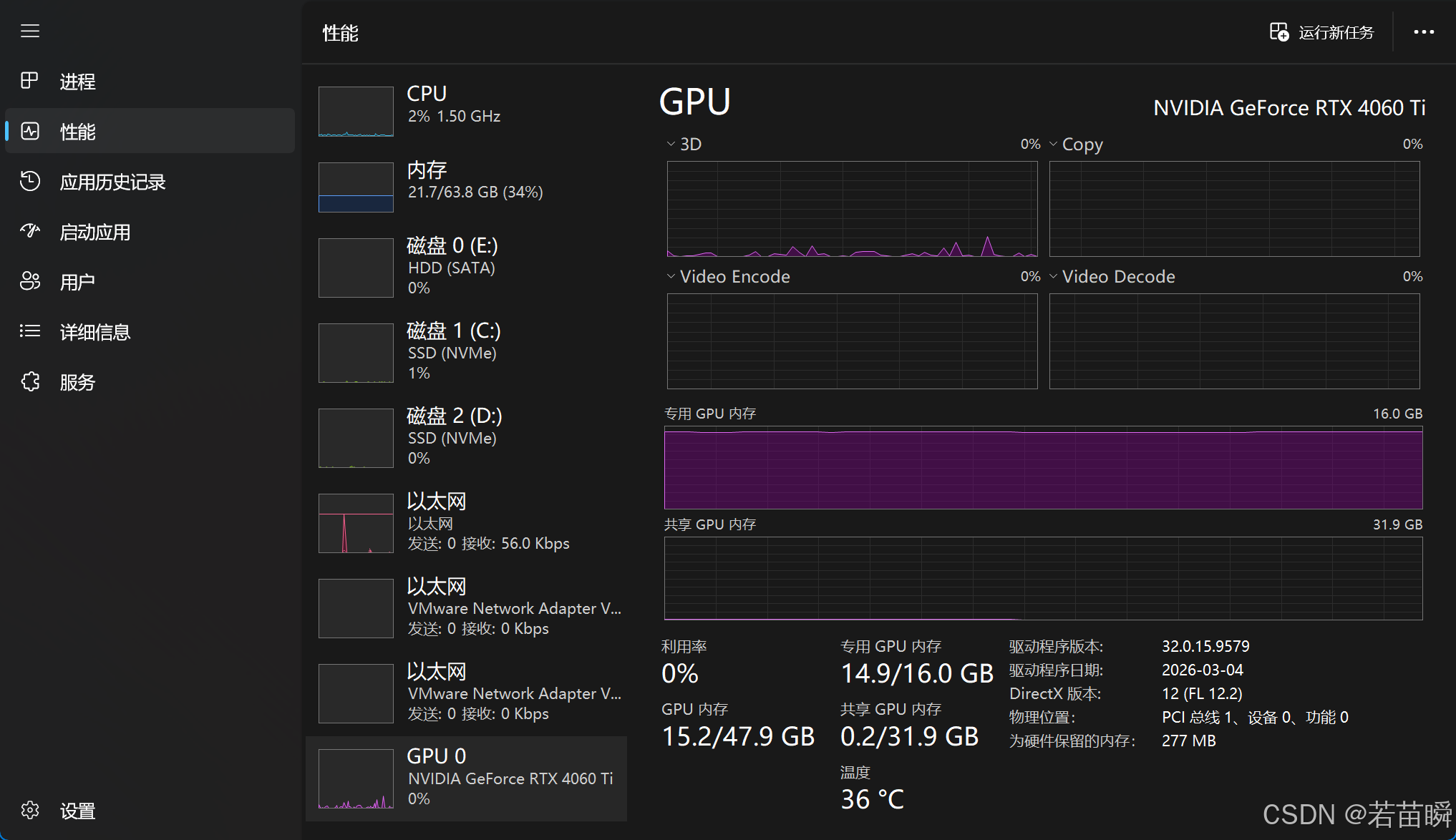
在i9-12900F,64GB-DDR4-3000,RTX-4060Ti-16GB的条件下。
暂时只能用Gemma,最大能用到 gemma-4-26B-A4B-it-UD-IQ3_S 模型了,文件大概10.43 GB,加上其它开销,占14GB多显存,20-30GB内存。
如果以后发现显存爆了,可以换IQ2模型,大概节约1GB显存。
PS:QWEN的小模型容易陷入自我否定的死循环,可见B站这里。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 11
11 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)