从RAG到数据治理:本体论驱动的AI数据底座实践
背景
问题不在模型,而在数据。
在实际的大模型应用中,我逐渐发现模型能力的上限,往往取决于数据的质量与结构,而不完全是模型本身。
尤其在工业领域,大量数据是非结构化的,有各式各样的PDF、手册、规范等。
语义复杂,专业术语多、上下文依赖强。
表达不统一,同一概念有多种说法。
如果直接接入大模型,会导致 RAG 召回不稳定、上下文噪声高、幻觉严重。
因此,这个项目的核心目标,不只是做一个问答系统,更是要构建一套面向大模型的数据治理与数据供给体系。
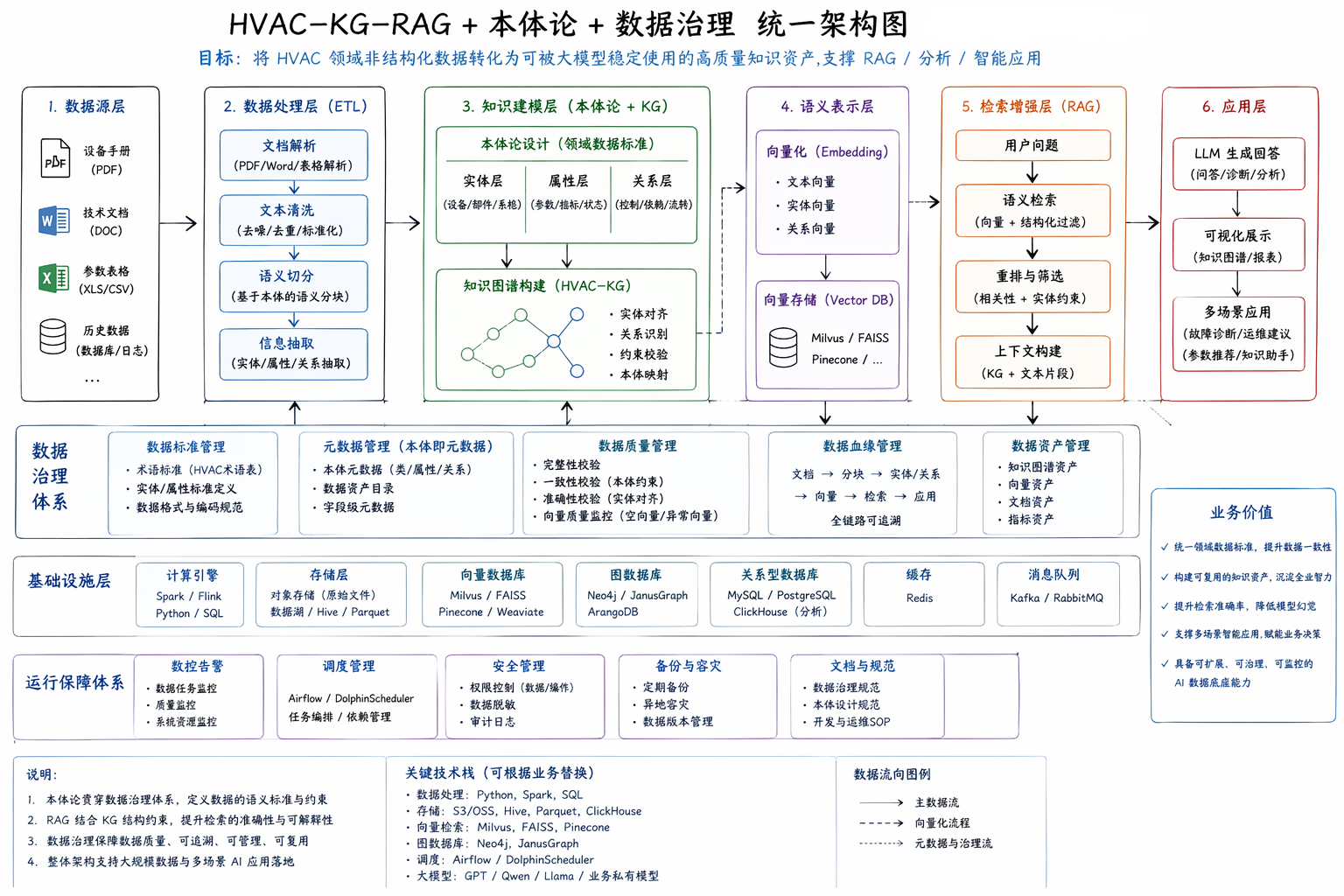
整体架构
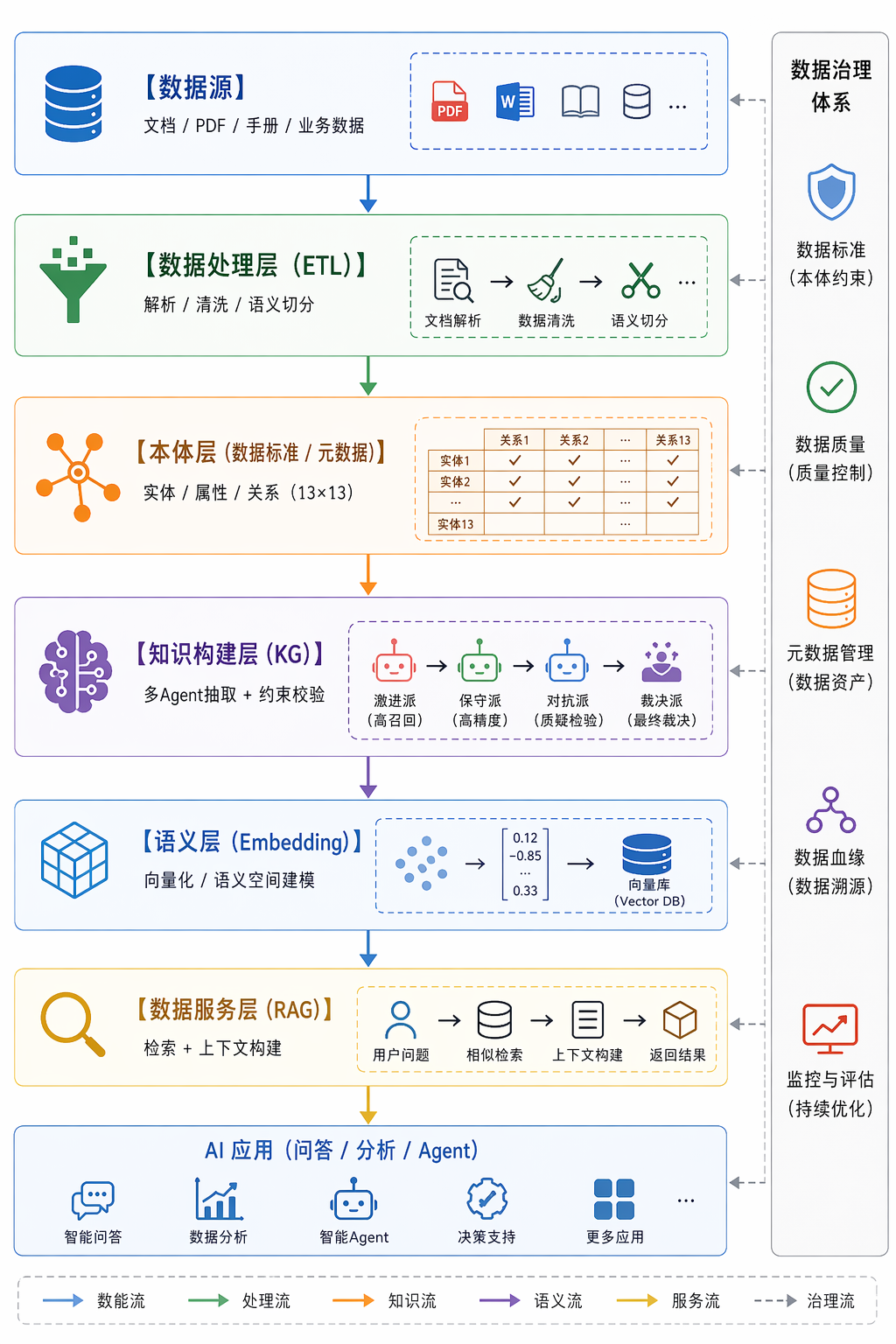
整个系统可以抽象为一条 数据 → 知识 → 语义 → 应用 的链路。
核心设计一:本体论 = 数据标准体系
1. 本体的本质
在这个项目中,本体论是领域数据标准 + 元数据模型。
我定义了一套 HVAC 领域的统一语义结构。
13类实体,如设备、参数、工艺、故障等。
13类关系,如包含、依赖、影响、控制等。
构成一个 13×13 的语义约束体系。
2. 本体解决的问题
(1)术语统一
“空调机组 / 空调设备 / 空调系统” → 统一为标准实体
“制冷量 / 冷量 / 制冷能力” → 统一表达
本质是数据标准化。
(2)关系约束
例如:
空调机组 contains 压缩机
温度 affects 制冷效果
统一关系类型 + 方向性
(3)减少幻觉
通过规则约束只允许13种关系,禁止过度推理,强制语义一致。
本质是数据质量控制。

核心设计二:软本体驱动的AI数据治理
1. 为什么选择软本体
本项目采用 Soft Ontology,也就是基于LLM的本体。
而不是 OWL / RDF 的形式本体。
原因很现实,软本体构建成本低、迭代快、对噪声容忍高,适合工业非结构化数据
2. 本体注入机制(关键)
本体以“宪法”的形式存在,通过 Prompt 注入到所有Agent中。
【全局本体约束】{global_policy}
本质是用本体作为数据治理规则引擎。
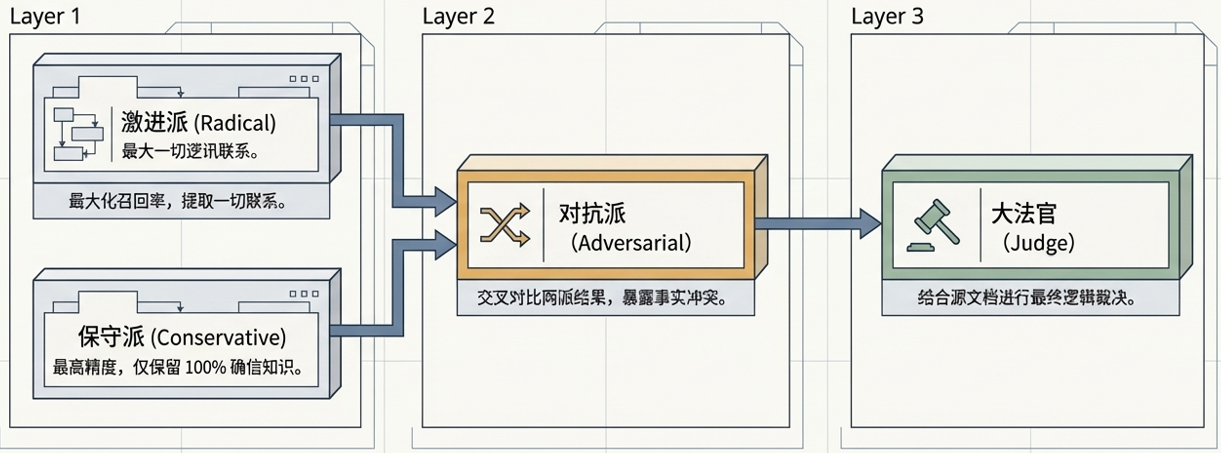
核心设计三:多 Agent 协同的数据质量控制
为了提升数据质量,我设计了一个四阶段协同机制。
本质是构建一套面向AI的数据质量治理机制。
核心设计四:知识图谱 = 数据资产沉淀
输出结果节点478、关系417。
这意味着原始文档转变成为了结构化知识资产。
这一步的意义是数据可复用、可查询(Cypher)、可扩展、可跨场景使用。
本质是数据资产化。
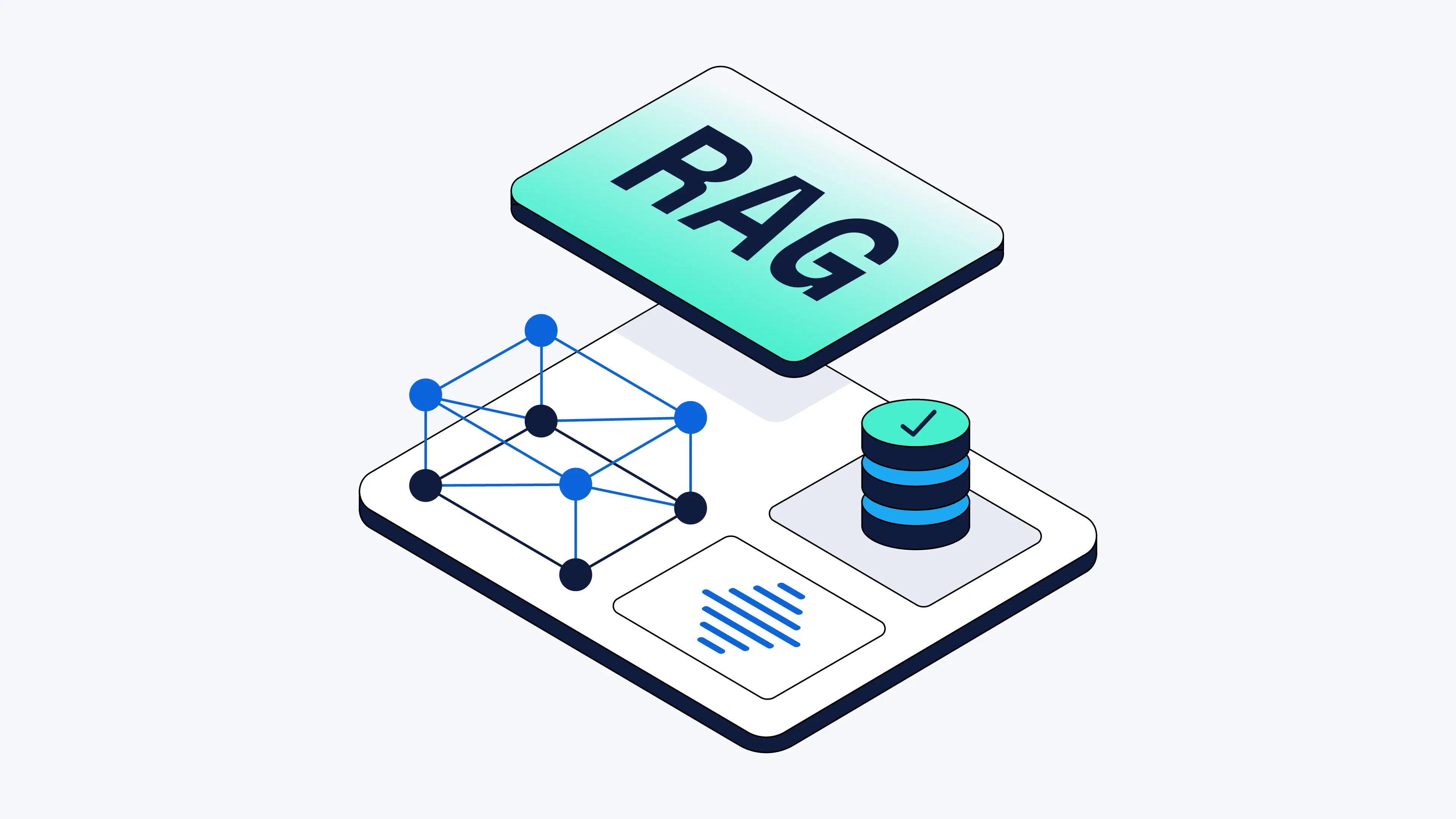
核心设计五:RAG = 数据供给接口
很多人把RAG当问答技术,但在这个系统中,RAG 是数据供给层。
作用是从数据资产中检索上下文、构建模型输入、提供稳定语义支持。
RAG效果问题,本质是数据问题。

升级路径
从软本体到企业级数据治理。
当前方案属于软本体 + AI驱动的数据治理。
未来可以演进为:
阶段1:增强型软本体
增加质量检测
引入置信度评分
阶段2:混合本体
核心概念 OWL 化
引入推理引擎
阶段3:形式本体
标准化建模(OWL/RDF)
企业级知识体系

总结
这个项目最大的提升不是技术,而是对 AI ,对数据的认知。
一开始理解只是做一个普通的RAG系统。
实际最后构建一套面向大模型的数据治理与数据供给体系。
目标是让数据可理解、让数据可复用、让数据可被AI稳定使用。
在AI时代数据不再只是被存储和分析,而是要被模型消费。
而数据治理,也从服务给人看的BI,转向了服务大模型与智能系统
这也是我在这个项目中最核心的收获。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 14
14 0
0- 0



 已为社区贡献28条内容
已为社区贡献28条内容

所有评论(0)