大模型在医学图像上总翻车?这两篇ICLR 2026给出了不同解法!
ICLR 2026 收录的这两篇论文均致力于解决医学图像AI在实际部署中的可靠性问题。研究背景中,医学影像常面临分布偏移(Distribution Shifts)以及单体大模型缺乏可解释性的严峻挑战。
为了应对这些挑战,第一篇论文聚焦于交互式图像分割,通过在线自适应方法利用医生的实时点击输入来动态更新模型权重,从而克服未见数据的分布偏移;第二篇论文则针对多模态医学视觉推理,提出了一种基于证据的智能体协作框架,将原本大模型的黑盒推理拆解为实体提议、像素级分割定位和基于证据的问答三个透明阶段。
两者的主要创新贡献在于:通过引入直接的人类反馈机制或多专家模块交叉验证,大幅提升了模型在真实场景下的诊断精度与临床责任解释度(Clinical Accountability)。
我整理了这2篇论文的医学AI精读笔记+创新点拆解+选题建议,感兴趣的dd!希望能帮到你!
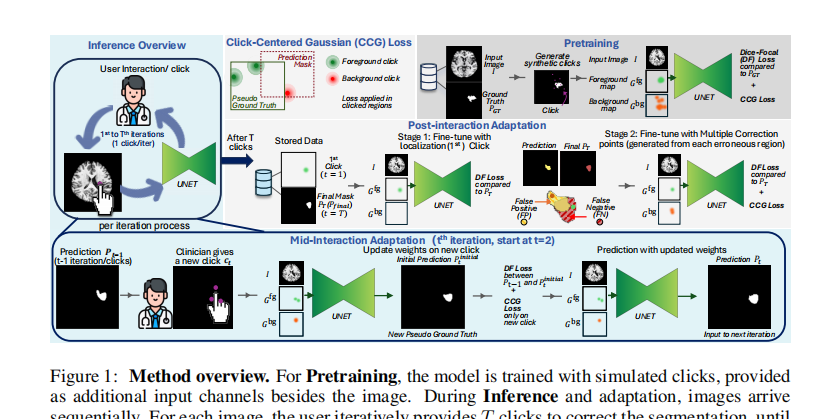
一、论文1:[ICLR 2026] YOU POINT, I LEARN: ONLINE ADAPTATION OF INTERACTIVE SEGMENTATION MODELS FOR HANDLING DISTRIBUTION SHIFTS IN MEDICAL IMAGING
方法:
-
核心思路是将交互式分割(Interactive Segmentation)模型的推理动作转化为一种在线持续学习机制(OAIMS)。
-
包含两个自适应过程:一是交互后自适应(Post-Interaction Adaptation),将用户最终确认的掩码视为伪标签微调模型;二是交互中自适应(Mid-Interaction Adaptation),在每次点击后做增量优化。
-
引入了以点击为中心的高斯损失(Click-Centered Gaussian Loss, CCG),加权惩罚点击周围的预测误差。 关键的CCG损失公式如下:
创新点:
-
摒弃了增加模型复杂度的正则化项,直接凭借“用户精校后的输出足够优质”这一设定,生成可靠的伪基准标签进行在线优化。
-
提出的CCG损失极大地提升了网络对新数据域下局部临床特征的专注度,在多种病理的脑部MRI跨域测试中Dice分数提升超过10%。
-
巧妙结合了交互中与交互后双重更新策略,保证了模型轻量级的高效运算,且未出现传统在线学习常有的灾难性过拟合。
-
代码链接:https://github.com/WenTXuL/OAIMS
-
论文链接:https://arxiv.org/abs/2503.06717
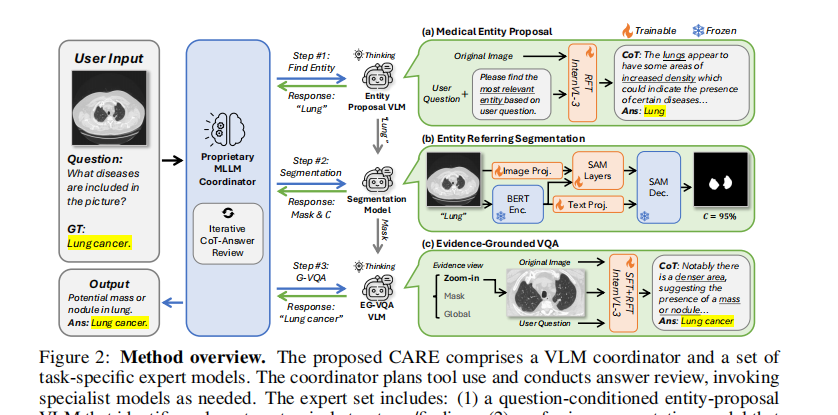
二、论文2:[ICLR 2026] CARE: TOWARDS CLINICAL ACCOUNTABILITY IN MULTI-MODAL MEDICAL REASONING WITH AN EVIDENCE-GROUNDED AGENTIC FRAMEWORK
方法:
-
提出了基于证据的智能体框架(Evidence-grounded Agentic Framework, CARE),将多模态推理过程高度解耦。
-
工作流分三步:小参数大语言模型提出可能的医学实体(Medical Entities);实体指代分割专家输出精确的局部ROI支持证据(掩码);最后由图像与边界证据联合驱动VQA大模型作答。
-
为保证输出的逻辑一致性,对各专家模块引入带可验证奖励的强化学习(Reinforcement Learning with Verifiable Reward, RLVR)。 其中计算实体语义对齐相似度奖励的公式如下:
创新点:
-
提出了首个具有“拟人化诊疗流程”的医疗视觉智能体框架,利用确凿的显式图像线索强有力地解决了大模型易出现幻觉的问题。
-
将黑盒感知“化整为零”,避免单个通用模型出现捷径学习,且即使只有10B参数量表现依然大幅越级打败了目前的SOTA全领域大模型。
-
设计了能够实施动态规划和容错评估的控制中枢机制(CARE-Coord),模拟了医师对初诊报告进行证据复核与纠偏的安全性闭环。
-
代码链接:https://xypb.github.io/CARE-Project-Page/
-
论文链接:https://arxiv.org/abs/2603.01607

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 5
5 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)