基于 LiteLLM 接入 NVIDIA NIM 全指南
基于 LiteLLM 接入 NVIDIA NIM 全指南(含 VSCode Claude Code 配置、踩坑与解决方案)
本文为作者本文全程实验测试,走通后由由chatgpt辅助生成,经作者本人审核修改后发布
如果你希望把 NVIDIA NIM(GLM / DeepSeek / Kimi 等模型)统一接入 VSCode、OpenAI SDK、Claude Code 插件,那么 LiteLLM 是目前非常高效的一套方案。【目前NIM可以白嫖1年的使用】
一、整体架构
VSCode Claude Code / Continue / OpenAI SDK
↓
LiteLLM Proxy
↓
NVIDIA NIM / OpenAI / Claude
作用:
1. 统一接口
2. 统一 API Key
3. 多模型切换
4. 兼容 VSCode 插件
5. 做企业内部模型网关
二、NVIDIA NIM 可接模型示例(太多了,具体请去build.nvidia.com上查看)
z-ai/glm5.1
z-ai/glm5
z-ai/glm4.7
deepseek-ai/deepseek-v3.2
moonshotai/kimi-k2.5
接口:
https://integrate.api.nvidia.com/v1
三、Docker Compose 部署 LiteLLM
基本步骤按照官方文档来即可:https://docs.litellm.ai/docs/proxy/docker_quick_start
docker-compose.yml【作者本人使用的】
services:
litellm:
build:
context: .
args:
target: runtime
image: ghcr.io/berriai/litellm:main-stable
#########################################
# Uncomment these lines to start proxy with a config.yaml file ##
volumes:
- ./config.yaml:/app/config.yaml
command:
- "--config=/app/config.yaml"
##############################################
ports:
- "4000:4000" # Map the container port to the host, change the host port if necessary
environment:
DATABASE_URL: "postgresql://llmproxy:dbpassword9090@db:5432/litellm"
STORE_MODEL_IN_DB: "True" # allows adding models to proxy via UI
env_file:
- .env # Load local .env file
depends_on:
- db # Indicates that this service depends on the 'db' service, ensuring 'db' starts first
healthcheck: # Defines the health check configuration for the container
test:
- CMD-SHELL
- python3 -c "import urllib.request; urllib.request.urlopen('http://localhost:4000/health/liveliness')" # Command to execute for health check
interval: 30s # Perform health check every 30 seconds
timeout: 10s # Health check command times out after 10 seconds
retries: 3 # Retry up to 3 times if health check fails
start_period: 40s # Wait 40 seconds after container start before beginning health checks
db:
image: postgres:16
restart: always
container_name: litellm_db
environment:
POSTGRES_DB: litellm
POSTGRES_USER: llmproxy
POSTGRES_PASSWORD: dbpassword9090
ports:
- "5432:5432"
volumes:
- postgres_data:/var/lib/postgresql/data # Persists Postgres data across container restarts
healthcheck:
test: ["CMD-SHELL", "pg_isready -d litellm -U llmproxy"]
interval: 1s
timeout: 5s
retries: 10
prometheus:
image: prom/prometheus
volumes:
- prometheus_data:/prometheus
- ./prometheus.yml:/etc/prometheus/prometheus.yml
ports:
- "9090:9090"
command:
- "--config.file=/etc/prometheus/prometheus.yml"
- "--storage.tsdb.path=/prometheus"
- "--storage.tsdb.retention.time=15d"
restart: always
volumes:
prometheus_data:
driver: local
postgres_data:
name: litellm_postgres_data # Named volume for Postgres data persistence
四、.env 配置【作者本人的,替换下NVIDIA_NIM_API_KEY即可】
NVIDIA_NIM_API_KEY:这个属于自定义命名,和config.yaml中对应即可
LITELLM_MASTER_KEY=sk-1234
LITELLM_SALT_KEY=sk-1234
NVIDIA_NIM_API_KEY=nvapi-xxxxxx
五、LiteLLM config.yaml(推荐稳定版)
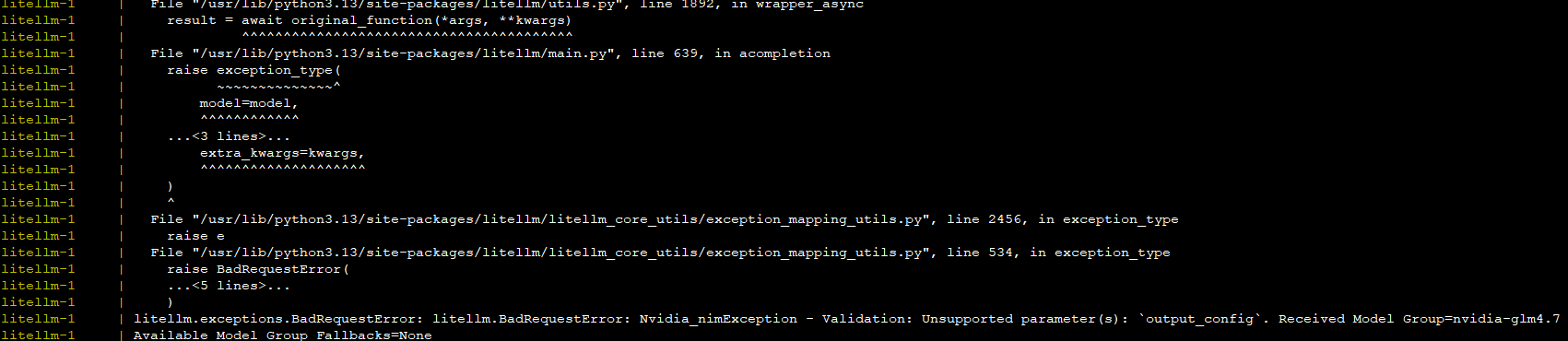
注意drop_params和additional_drop_params这两个参数,官方参考样例里没有写这两个参数,但使用NIM时需要配置这两个参数,因为claude的请求里会有output_config这个参数,LiteLLM也会封装这个参数,但NIM是不支持这个参数的,所以这两个参数配置后,就可以过滤掉output_config参数,不然调用NIM接口时会报错,提示不支持output_config
model_list:
- model_name: nvidia-glm-5.1
litellm_params: # all params accepted by litellm.completion() - https://docs.litellm.ai/docs/completion/input
model: nvidia_nim/z-ai/glm5.1 ### MODEL NAME sent to `litellm.completion()` ###
api_base: https://integrate.api.nvidia.com/v1
api_key: os.environ/NVIDIA_NIM_API_KEY # does os.getenv("AZURE_API_KEY_EU")
rpm: 6 # [OPTIONAL] Rate limit for this deployment: in requests per minute (rpm)
drop_params: true
additional_drop_params: ["output_config"]
- model_name: nvidia-glm5
litellm_params:
model: nvidia_nim/z-ai/glm5
api_base: https://integrate.api.nvidia.com/v1
api_key: os.environ/NVIDIA_NIM_API_KEY
rpm: 6
drop_params: true
additional_drop_params: ["output_config"]
- model_name: nvidia-glm4.7
litellm_params:
model: nvidia_nim/z-ai/glm4.7
api_base: https://integrate.api.nvidia.com/v1
api_key: os.environ/NVIDIA_NIM_API_KEY
rpm: 6
drop_params: true
additional_drop_params: ["output_config"]
- model_name: nvidia-deepseek-v3.2
litellm_params:
model: nvidia_nim/deepseek-ai/deepseek-v3.2
api_base: https://integrate.api.nvidia.com/v1
api_key: os.environ/NVIDIA_NIM_API_KEY
rpm: 6
drop_params: true
additional_drop_params: ["output_config"]
- model_name: nvidia-kimi-k2.5
litellm_params:
model: nvidia_nim/moonshotai/kimi-k2.5
api_base: https://integrate.api.nvidia.com/v1
api_key: os.environ/NVIDIA_NIM_API_KEY
rpm: 6
drop_params: true
additional_drop_params: ["output_config"]
# Use this if you want to make requests to `claude-3-haiku-20240307`,`claude-3-opus-20240229`,`claude-2.1` without defining them on the config.yaml
# Default models
# Works for ALL Providers and needs the default provider credentials in .env
# - model_name: "*"
# litellm_params:
# model: "*"
general_settings:
master_key: sk-1234 # [OPTIONAL] Only use this if you to require all calls to contain this key (Authorization: Bearer sk-1234)
database_url: "postgresql://llmproxy:dbpassword9090@db:5432/litellm"
litellm_settings:
num_retries: 2 # retry call 3 times on each model_name (e.g. zephyr-beta)
request_timeout: 30 # raise Timeout error if call takes longer than 10s. Sets litellm.request_timeout
六、为什么 model 必须写 nvidia_nim/ 前缀
LiteLLM解析的需要,详见 https://docs.litellm.ai/docs/providers/nvidia_nim
错误写法:
model: z-ai/glm4.7
报错:
LLM Provider NOT provided
正确写法:
model: nvidia_nim/z-ai/glm4.7
七、VSCode Claude Code 插件配置(重点)
如果你想让 Claude Code 插件调用 LiteLLM,再由 LiteLLM 调用 NVIDIA NIM,可在 VSCode settings.json 中加入:
{
"python.defaultInterpreterPath": "/bin/python",
"http.systemCertificates": true,
"claudeCode.preferredLocation": "panel",
"claudeCode.environmentVariables": [
{
"name": "ANTHROPIC_BASE_URL",
"value": "http://10.11.11.124:4000"
},
{
"name": "ANTHROPIC_AUTH_TOKEN",
"value": "sk-你的LiteLLM密钥"
},
{
"name": "ANTHROPIC_DEFAULT_OPUS_MODEL",
"value": "nvidia-glm4.7"
},
{
"name": "ANTHROPIC_DEFAULT_SONNET_MODEL",
"value": "nvidia-glm4.7"
},
{
"name": "ANTHROPIC_DEFAULT_HAIKU_MODEL",
"value": "nvidia-glm4.7"
},
{
"name": "CLAUDE_CODE_DISABLE_NONESSENTIAL_TRAFFIC",
"value": "1"
},
{
"name": "CLAUDE_CODE_DISABLE_EXPERIMENTAL_BETAS",
"value": "1"
}
]
}
密钥:LiteLLM启动后,访问http://10.11.11.124:4000/ui/,然后在Virtual Keys页面创建密钥即可
八、这几个环境变量是什么意思(非常重要)
1. ANTHROPIC_BASE_URL
Claude 插件请求地址:
http://你的LiteLLM服务器:4000
2. ANTHROPIC_AUTH_TOKEN
LiteLLM 的 master_key:
sk-xxxx
3. 默认模型映射
OPUS → nvidia-glm4.7
SONNET → nvidia-glm4.7
HAIKU → nvidia-glm4.7
Claude 插件以为自己在调 Claude,实际走 GLM。
4. 禁用额外流量
CLAUDE_CODE_DISABLE_NONESSENTIAL_TRAFFIC=1
关闭遥测、非必要请求。
5. 禁用实验特性(强烈建议)
CLAUDE_CODE_DISABLE_EXPERIMENTAL_BETAS=1
避免发送:
output_config
thinking
beta params
这对 NIM 非常关键。
九、常见问题汇总
问题1:LLM Provider NOT provided
原因:
model: z-ai/glm4.7
解决:
model: nvidia_nim/z-ai/glm4.7
问题2:OPENAI_API_KEY missing
原因:
启用了:
model_name: "*"
LiteLLM 默认兜底走 OpenAI。
解决:删除 * 模型。
问题3:Unsupported parameter output_config
原因:
Claude 插件走 Anthropic 协议,会发送私有字段。
解决:
drop_params: true
additional_drop_params:
- output_config
同时建议 VSCode 配:
CLAUDE_CODE_DISABLE_EXPERIMENTAL_BETAS=1
问题4:LiteLLM UI 报错 crypto.randomUUID
解决:
升级 LiteLLM:
docker pull ghcr.io/berriai/litellm:main-stable
十、OpenAI SDK 调用示例
from openai import OpenAI
client = OpenAI(
api_key="sk-1234",
base_url="http://服务器IP:4000/v1"
)
resp = client.chat.completions.create(
model="nvidia-glm4.7",
messages=[{"role":"user","content":"你好"}]
)
print(resp.choices[0].message.content)
十一、生产环境建议
1. 做限流
rpm: 6
2. 多模型统一管理
glm4.7
glm5
deepseek-v3.2
kimi-k2.5
十二、个人实战总结(重点)
如果你是:
VSCode 用户
想用 Claude 插件
又想走国产/第三方模型
最佳方案就是:
Claude Code 插件
↓
LiteLLM
↓
NVIDIA NIM(GLM)
关键点只有三个:
1. provider 前缀写对
2. 去掉星号模型
3. 过滤 output_config
十三、最终推荐组合
VSCode Claude Code 插件(前端体验)
LiteLLM(协议转换)
NVIDIA NIM(模型能力)
十四、如果你也踩坑了
欢迎留言讨论:
你卡在 LiteLLM 配置?
Claude 插件参数?
VSCode 远程 SSH?
NIM Key?

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 11
11 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)