人形机器人运动控制突破:从半马纪录到工业落地的技术实践
2026年4月,人形机器人“闪电”以50分26秒的成绩完成半程马拉松,超越人类世界纪录近7分钟。这一里程碑事件的技术意义远大于体育意义——它标志着人形机器人的运动控制能力已经达到工业部署的成熟度门槛。
对于技术从业者而言,真正值得关注的是:这种能力跃迁背后的技术逻辑是什么?如何将赛场上的运动控制能力转化为工业场景下的生产力?本文将从技术实践角度,系统解析从能力突破到工业落地的完整技术路径。
一、运动控制突破的三重技术逻辑
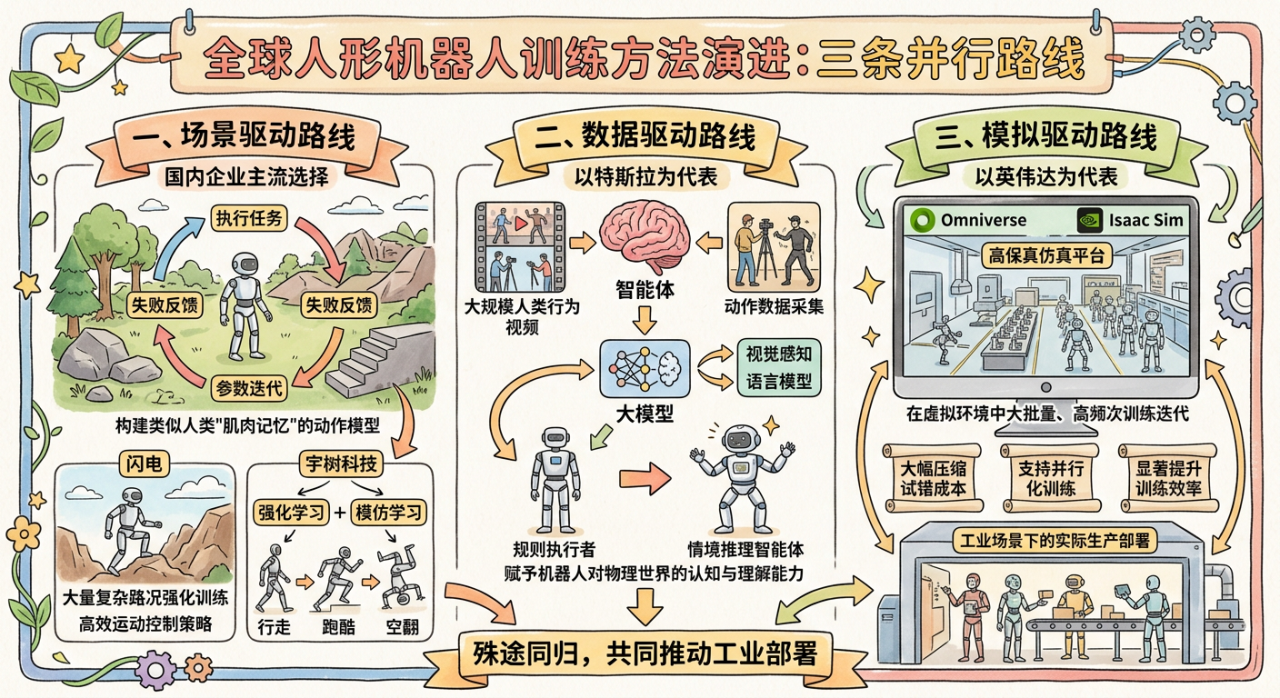
1.1 场景驱动:强化学习与模仿学习的融合实践
国内企业普遍采用的场景驱动路线,其技术核心在于在真实物理环境中构建持续优化的控制闭环。这一路径的技术实现包含三个关键层次:
感知层:通过多模态传感器融合(视觉、IMU、力觉、触觉)实时获取环境状态。以“闪电”为例,其足底配备了高精度六维力传感器,采样频率达到1000Hz,能够实时感知地面反作用力的细微变化。
决策层:采用深度强化学习(DRL)算法,将运动控制建模为马尔可夫决策过程。奖励函数的设计尤为关键——不仅要考虑运动速度、能耗效率,还要加入稳定性惩罚项(防止跌倒)、平滑性约束(避免剧烈抖动)。
执行层:基于模型预测控制(MPC)实现毫秒级关节力矩调整。宇树科技公开的技术方案显示,其机器人采用了分层控制架构:上层DRL生成参考轨迹,下层MPC进行实时跟踪校正,控制频率达到500Hz。
技术挑战:真实环境训练的数据采集成本高、安全风险大。解决方案是建立安全约束下的探索机制,在机器人即将失去平衡时触发保护策略,避免硬件损坏。
1.2 数据驱动:大规模行为数据的表征学习
特斯拉的技术路径代表了另一种范式:通过海量人类行为数据训练世界模型。这一方案的技术栈包括:
数据采集层:构建多视角动作捕捉系统,采集人类在各种场景下的运动数据。关键难点在于数据标注——需要精确的时间对齐和动作语义标注。
表征学习层:使用Transformer架构学习动作序列的时空特征。最新研究表明,扩散模型(Diffusion Model)在动作生成任务上表现出色,能够生成平滑、自然、符合物理规律的动作序列。
迁移学习层:将从人类数据中学到的表征迁移到机器人控制策略。这里需要解决sim2real(仿真到现实)的领域适应问题,通常通过域随机化(Domain Randomization)技术增强模型的泛化能力。
技术优势:避免了在真实机器人上的试错成本,训练过程完全在数据层面进行。但需要解决数据偏差问题——人类动作数据可能无法覆盖机器人所有的运动需求。
1.3 模拟驱动:高保真仿真环境下的并行训练
英伟达的Omniverse + Isaac平台提供了第三条技术路径:在物理精确的虚拟环境中进行大规模并行训练。这一方案的技术要点包括:
物理引擎:采用NVIDIA PhysX 5.0,支持刚体、柔体、流体等多种物理模拟,时间步长可配置到0.001秒级别,确保仿真精度。
传感器仿真:实现相机、激光雷达、IMU等传感器的物理级仿真,包括噪声模型、畸变模型、延迟模型,使虚拟传感器数据接近真实数据。
并行训练架构:在DGX系统上可同时运行数万个仿真实例,每个实例独立训练一个策略副本。采用PPO(近端策略优化) 作为基础算法,结合课程学习(Curriculum Learning)逐步增加任务难度。
关键技术指标:仿真环境中的训练效率可达真实环境的1000倍以上,原本需要数月的训练周期可缩短到数天。
二、AI原生工厂:技术架构与实施路径
2.1 系统架构设计
AI原生工厂的技术架构遵循云-边-端三层体系:
云端:承载数字孪生平台、AI训练平台、数据管理平台。采用微服务架构,各服务通过API网关进行通信。数字孪生引擎基于USD(通用场景描述)格式,支持多用户协同编辑。
边缘层:部署在工厂现场的边缘服务器集群,负责实时推理、数据预处理、本地控制。采用NVIDIA Jetson Orin 或类似平台,提供200TOPS以上的AI算力。
终端层:包括人形机器人、AGV、机械臂等物理设备。机器人本体搭载嵌入式AI芯片,实现低延迟的本地决策(如避障、平衡控制)。
数据流设计:终端传感器数据通过5G专网或工业以太网传输到边缘层,经预处理后部分用于本地控制,部分上传到云端用于模型训练。训练好的模型通过OTA(空中下载)方式下发到终端设备。
2.2 四大核心步骤的技术实现
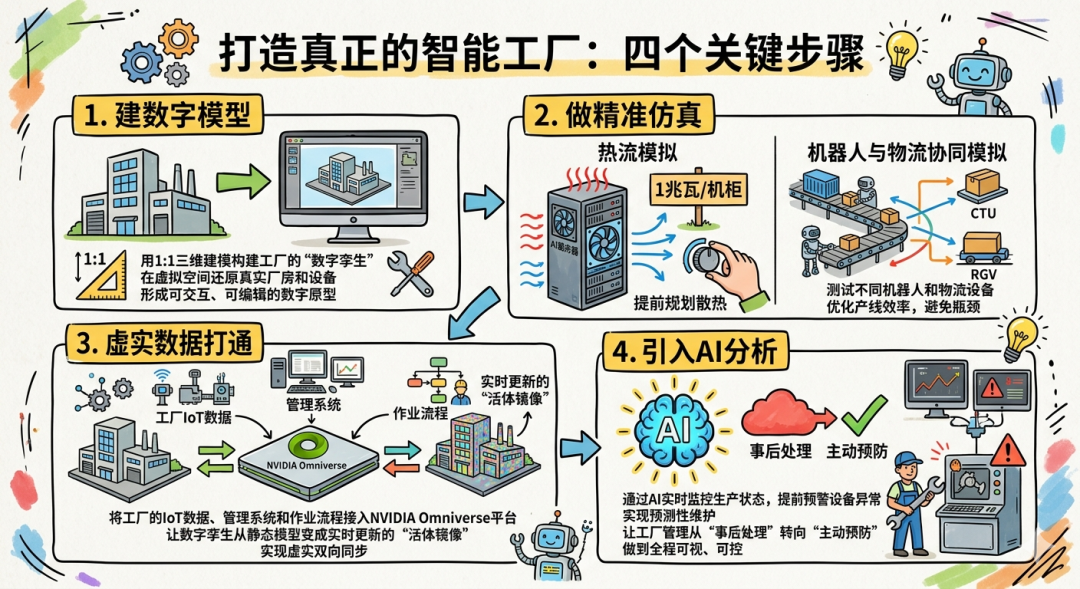
步骤一:建立数字模型
技术选型:采用BIM(建筑信息模型)+ MBD(基于模型的定义)相结合的方式。BIM用于工厂建筑和基础设施,MBD用于生产设备和产品。
数据标准:所有模型遵循ISO 10303(STEP)标准,确保不同软件间的互操作性。关键设备需要提供URDF(统一机器人描述格式)或SDF(模拟描述格式)文件,用于物理仿真。
细节层级(LOD)管理:根据应用场景选择不同的模型精度。布局规划用LOD 200(基本几何),物流仿真用LOD 300(详细几何),维修培训用LOD 400(可拆卸组件)。
步骤二:进行精准模拟
热流模拟(CFD):采用ANSYS Fluent 或 OpenFOAM 进行数值计算。对于AI服务器机房,需要建立包含机柜、空调、通道的完整模型,求解Navier-Stokes方程获得温度场、速度场分布。
关键参数:
-
网格数量:通常需要千万级网格才能保证精度
-
湍流模型:采用k-ε或SST k-ω模型
-
边界条件:准确设置发热功率、进口风速、环境温度
物流仿真:采用FlexSim 或 AnyLogic 进行离散事件仿真。需要建立完整的物料流模型,包括:
-
设备处理时间分布(正态分布、指数分布等)
-
物料搬运逻辑(FIFO、优先级规则)
-
异常处理机制(设备故障、物料短缺)
机器人运动规划仿真:在Isaac Sim中测试不同形态机器人的协同作业。关键技术包括:
-
碰撞检测算法(GJK、EPA)
-
路径规划算法(RRT*、PRM)
-
运动学逆解优化
步骤三:实体数据导入
IoT数据集成:通过OPC UA协议采集设备数据,包括:
-
设备状态(运行、停机、故障)
-
工艺参数(温度、压力、速度)
-
质量数据(尺寸、外观、性能)
数据同步机制:采用变化数据捕获(CDC) 技术,只传输发生变化的数据,减少网络负载。时间同步精度要求达到毫秒级,采用PTP(精确时间协议)实现。
数字线程(Digital Thread):建立从设计、制造到运维的全生命周期数据关联。每个物理实体(设备、产品、工具)在数字孪生中都有唯一标识符,所有相关数据通过该标识符进行关联。
步骤四:导入AI分析
预测性维护模型:采用LSTM(长短期记忆网络) 或 Transformer 分析设备传感器时序数据。训练数据需要包含正常状态和多种故障状态,故障标签需要专家标注。
质量检测AI:基于视觉Transformer(ViT) 或 CNN 架构,实现外观缺陷的自动检测。关键挑战在于小样本学习——实际生产中缺陷样本很少,需要采用数据增强、迁移学习等技术。
生产调度优化:将生产调度问题建模为强化学习任务,状态空间包括设备状态、订单队列、物料库存,动作空间为任务分配决策,奖励函数为生产效率、交货准时率等KPI。
三、柔性制造的技术实现机制
3.1 “换模型即换任务”的架构设计
柔性制造的核心在于将硬件能力与软件技能解耦。技术实现包括:
技能模型仓库:在边缘服务器或云端建立统一的模型仓库,每个技能对应一个AI模型。模型采用ONNX(开放神经网络交换)格式,确保跨平台兼容性。
模型管理服务:提供模型的版本控制、依赖管理、安全验证。采用容器化部署(Docker),每个技能模型运行在独立的容器中,避免环境冲突。
动态加载机制:机器人通过HTTP/REST API从模型仓库下载所需技能。下载后模型缓存在本地,后续调用无需重复下载。模型切换时间控制在5秒以内。
3.2 数据飞轮(Data Flywheel)构建
柔性制造的持续优化依赖于数据闭环:
数据采集:机器人在执行任务时记录多维度数据,包括:
-
操作序列(动作、参数、时序)
-
环境状态(物体位置、光照、干扰)
-
执行结果(成功/失败、精度、耗时)
数据标注:采用半自动标注流程,机器人自动标注大部分数据,疑难案例由人工复核。标注工具需要支持3D点云、图像序列、时序数据等多种格式。
模型训练:在云端训练平台进行增量训练。采用持续学习(Continual Learning) 技术,避免新任务训练导致旧任务性能下降(灾难性遗忘)。
模型部署:训练好的模型通过A/B测试验证效果,效果达标后推送到生产环境。支持金丝雀发布,先在小范围设备上试用,确认无误后再全量推广。
3.3 边缘计算架构
为满足实时性要求,需要在边缘层部署完整的AI推理流水线:
硬件平台:采用NVIDIA Jetson AGX Orin,提供275TOPS的INT8算力,功耗仅15-60W。支持多路摄像头输入和实时推理。
软件栈:
-
操作系统:Ubuntu 20.04 + ROS 2(机器人操作系统)
-
推理引擎:TensorRT,对模型进行量化、剪枝、层融合优化
-
中间件:FastDDS,实现低延迟的进程间通信
资源调度:采用Kubernetes 管理边缘计算资源,根据任务优先级动态分配GPU、内存、网络带宽。
四、技术挑战与未来展望
4.1 当前面临的主要挑战
数据安全与隐私:工厂生产数据涉及商业机密,需要建立完善的数据加密、访问控制、审计追踪机制。联邦学习(Federated Learning)可能是一个解决方案——在本地训练模型,只上传模型参数而非原始数据。
系统集成复杂度:AI原生工厂涉及数十种异构系统(ERP、MES、WMS、SCADA等)的集成。需要建立统一的数据总线(Data Bus) 和 API网关,采用事件驱动架构(EDA)降低耦合度。
人才缺口:同时懂制造业、机器人技术、AI算法的复合型人才严重短缺。需要建立系统的培训体系,并开发低代码/无代码工具降低使用门槛。
标准化滞后:数字孪生、AI模型、机器人接口缺乏统一标准,导致系统间互操作性差。行业需要推动开放标准的制定,如ISO 23247(数字孪生制造框架)。
4.2 技术发展趋势
多模态大模型在机器人领域的应用:GPT-4V、Gemini等多模态大模型展现出强大的场景理解能力,未来可能成为机器人的“通用大脑”,实现真正的场景自适应。
仿真到现实的零样本迁移:通过域随机化、元学习等技术,实现在仿真环境中训练的策略能够零样本(Zero-Shot) 迁移到真实环境,彻底解决sim2real鸿沟。
群体智能(Swarm Intelligence):多个机器人协同完成复杂任务,通过局部交互涌现出全局智能。这在物流仓储、大型装配等场景有巨大应用潜力。
数字孪生与元宇宙融合:数字孪生工厂将不仅仅是生产工具,更可能成为工业元宇宙的入口,支持虚拟巡检、远程协作、培训考核等多种应用。
技术落地需要系统工程思维
人形机器人从赛场破纪录到工业落地,不是单一技术的突破,而是感知、决策、控制、仿真、集成等多个技术领域协同进化的结果。
对于技术团队而言,最大的启示在于:必须建立系统工程思维。不能只关注算法精度,还要考虑实时性、可靠性、安全性、可维护性。不能只追求技术先进,还要兼顾成本、易用性、可扩展性。
AI原生工厂的建设是一个渐进过程,建议采用分阶段实施策略:先从数字化基础做起,再逐步引入仿真、AI、机器人等先进技术。每个阶段都要有明确的KPI和验收标准,确保投资回报。
这场由Physical AI驱动的制造业变革,技术框架已经清晰,实施路径已经明确。接下来需要的,是更多技术团队深入产业一线,将蓝图转化为现实。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 16
16 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)