Vul-LMGNNs:结合CodeLM与图神经网络的跨层漏洞检测方法
“ 随着开源社区的快速发展,软件漏洞检测已成为保障系统安全的关键任务。传统的符号执行和规则匹配虽然有效,但容易产生高误报率,且难以适应复杂代码场景。深度学习方法的引入为自动化漏洞检测带来了新可能,但如何同时捕捉代码的语义信息与结构特征,依旧是一个核心挑战。”
论文标题:Vul-LMGNNs: Fusing language models and online-distilled graph neural networks for code vulnerability detection
作者:Ruitong Liu, Yanbin Wang, Haitao Xu等
单位:深圳北理莫斯科大学、西安电子科技大学杭州研究院、浙江大学网络空间安全学院、中国人民公安大学
发表期刊:Information Fusion, 2025
01
—
方法介绍
当前的代码漏洞检测方法主要分为两类:基于序列的模型和基于图的模型。前者通过序列化代码,利用 LSTM、Transformer 等架构学习语义特征;后者将代码转化为语法树、控制流图等异构图结构,借助图神经网络(GNN)捕捉依赖关系。但两类方法各有局限:语言模型难以理解复杂结构,GNN 则受限于信息跨层传播能力。
为此,本文提出 Vul-LMGNNs —— 一种融合预训练代码语言模型(CodeLM)与在线蒸馏图神经网络的新框架。它结合了代码语义与结构特征,旨在提升跨层信息传递与漏洞检测精度。
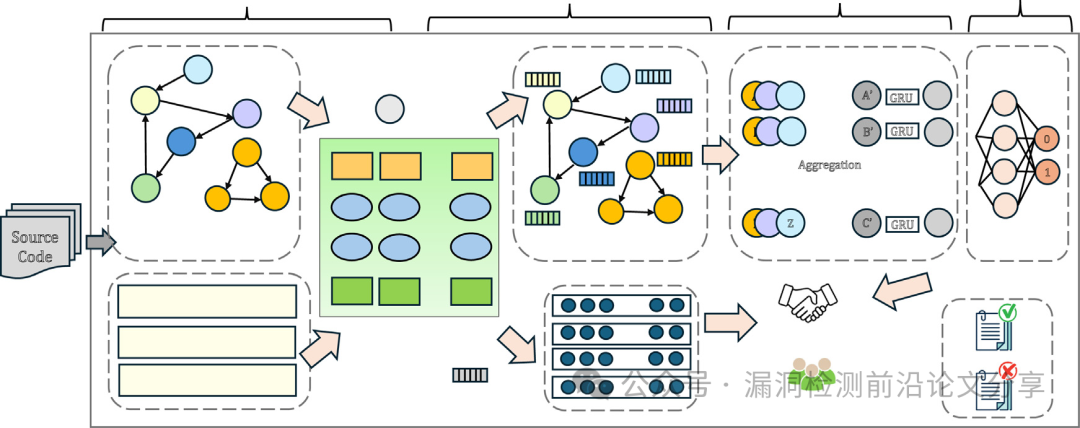
图1 Vul-LMGNNs的漏洞检测框架
小结:Vul-LMGNNs 立足于融合语义与结构,解决了现有方法在单一视角下的不足。
02
—
关键机制
Vul-LMGNNs 的核心有三个方面:
- 代码属性图(CPG)建模
将语法、控制流与数据依赖统一到图表示中。
- 在线知识蒸馏 GNN
通过交替训练的方式,让学生 GNN 学到跨层结构信息,突破传统 GNN 层级受限的问题。
- 隐式 + 显式 融合训练
隐式阶段用 CodeLM 初始化图节点嵌入并与 GNN 联合优化;显式阶段通过线性插值融合 CodeLM 与 GNN 的预测,实现语义与结构的最终整合。
小结:通过知识蒸馏与双阶段训练,模型实现了语义与结构的深度协同。
03
—
实验结果
研究团队在四个真实世界漏洞数据集上进行了系统评估,Dataset 链接:https://github.com/Vul-LMGNNs/ vul-LMGGNN:
- DiverseVul:覆盖 150 种 CWE,包含 18,945 个漏洞函数。
- Devign:来自 GitHub 的真实项目代码。
- VDISC:百万级函数规模,存在样本不平衡。
- ReVeal:基于 Chrome 与 Debian 的漏洞历史。
与 17 种主流方法的对比,Vul-LMGNNs 在准确率与 F1 值上均取得领先,特别是在不平衡数据集上,F1分数提升约10%,显著降低了漏报率。
|
模型 |
DiverseVul ACC |
DiverseVul F1 |
ReVeal ACC |
ReVeal F1 |
|---|---|---|---|---|
|
CodeBERT |
92.4% |
23.4% |
88.6% |
38.2% |
|
GraphCodeBERT |
93.0% |
21.4% |
89.2% |
41.7% |
|
Vul-LMGNNs (CodeT5-Base) |
94.8% | 32.6% | 91.7% | 53.1% |
小结:实验结果显示,Vul-LMGNNs 在语义与结构结合的复杂场景下均显著优于现有方法,尤其在 Recall 与 F1 上提升明显。
📌 总结
Vul-LMGNNs 通过语言模型与图神经网络的深度融合,以及跨层知识蒸馏的机制,在漏洞检测任务上实现了更强的表现力与稳定性,为大规模代码安全检测提供了新思路。
📣 欢迎留言讨论
-
你认为未来漏洞检测模型应更依赖结构增强,还是大规模预训练?
-
在企业实践中,静态检测和深度学习结合会产生怎样的化学反应?
📌 点赞 + 收藏 + 分享,是对我们持续更新最大的鼓励!

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 20
20 0
0- 0



 已为社区贡献21条内容
已为社区贡献21条内容

所有评论(0)