双路架构和码本量化的时间序列研究方法
这篇关于轻量级时间序列预测的论文。
论文基本信息
| 项目 | 内容 |
|---|---|
| 标题 | ReCast: Reliability-aware Codebook Assisted Lightweight Time Series Forecasting(ReCast:可靠性感知的码本辅助轻量级时间序列预测) |
| 作者 | 马翔、陈泰华、王鹏程、李雪梅、张彩明(山东大学) |
| 发表会议 | AAAI 2026(人工智能顶级会议) |
| 核心创新 | 双路径架构 + 可靠性感知的码本更新机制 |
研究背景与动机
现有方法的两大痛点
-
全局分解的局限:传统方法(如Autoformer、Fedformer)将时间序列全局分解为趋势、季节性和残差成分,但真实世界数据往往由局部、复杂、高度动态的模式主导,全局分解对此无能为力
-
模型过于复杂:Transformer等模型参数量大、计算开销高,难以部署在资源受限的实时环境中
核心观察
许多真实世界的时间序列表现出" recurring local shapes( recurring 局部形状)"而非清晰的全局规律性
这启发了作者:能否用**向量量化(Vector Quantization)**将局部模式编码为离散码本,实现轻量级且鲁棒的预测?
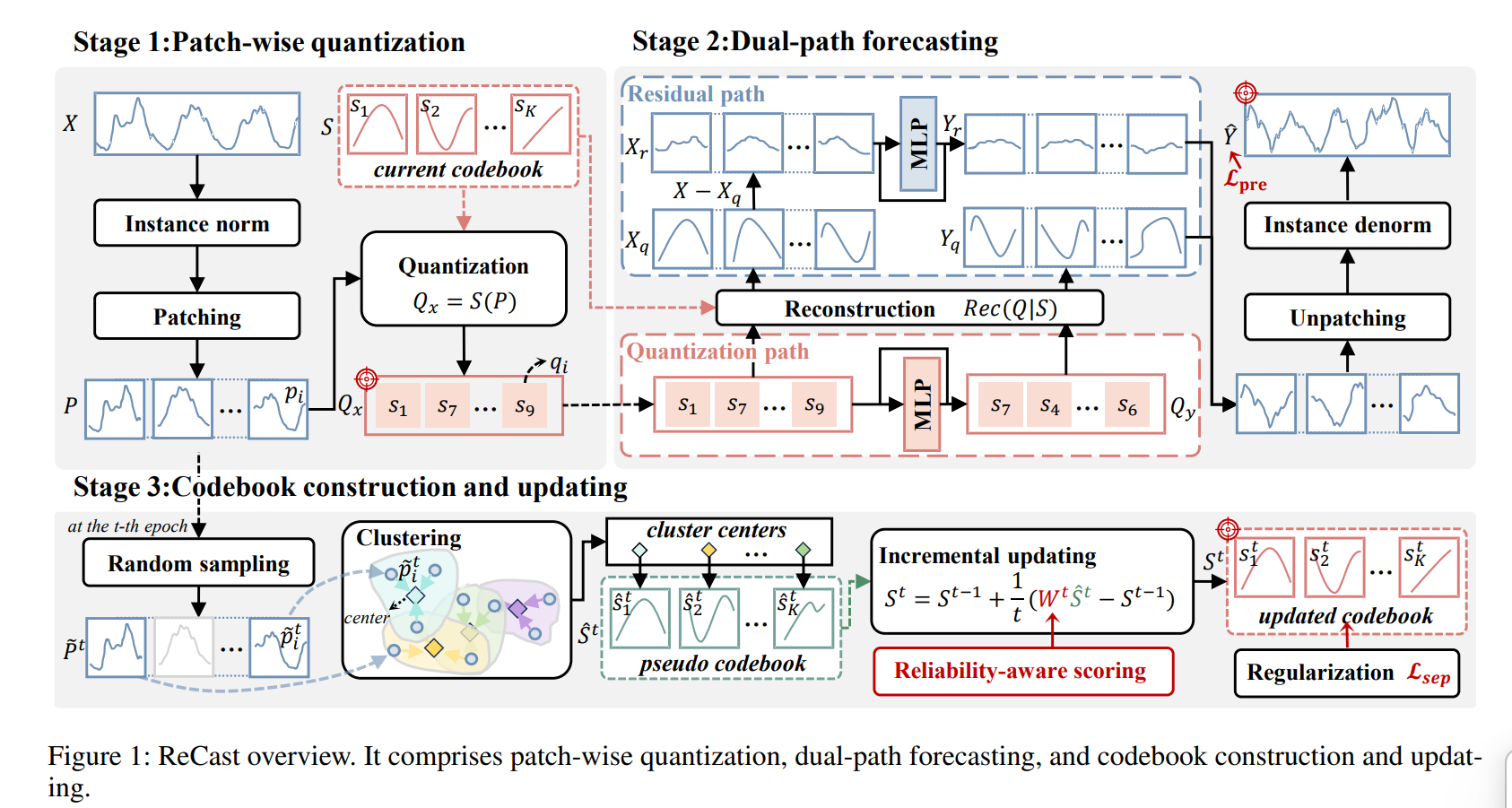
ReCast 整体架构(三阶段)
┌─────────────────────────────────────────────────────────────┐
│ Stage 1: Patch-wise Quantization(分块量化) │
│ Stage 2: Dual-path Forecasting(双路径预测) │
│ Stage 3: Codebook Construction & Updating(码本构建与更新) │
└─────────────────────────────────────────────────────────────┘
Stage 1: 分块量化(Patch-wise Quantization)
流程:
原始序列 X → Instance Norm(实例归一化)→ Patching(分块)→ Downsampling(下采样)→ Quantization(量化)
关键操作:
| 步骤 | 说明 | 公式 |
|---|---|---|
| 实例归一化 | 消除量纲差异 | X^=(X−μin)/σin2+ε\hat{X} = (X - \mu_{in}) / \sqrt{\sigma^2_{in} + \varepsilon}X^=(X−μin)/σin2+ε |
| 分块 | 将序列切分为长度为 LpL_pLp 的patch | P={pi}i=1C×N,N=⌈L/Lp⌉P = \{p_i\}_{i=1}^{C \times N}, N = \lceil L/L_p \rceilP={pi}i=1C×N,N=⌈L/Lp⌉ |
| 下采样 | 降维至 Lp/2L_p/2Lp/2,聚焦显著结构 | p~i=Dsamp(pi)\tilde{p}_i = D_{samp}(p_i)p~i=Dsamp(pi) |
| 量化 | 映射到码本中最邻近的码字 | qi=S(p~i)=argminsk∈S∣p~i−sk∣22q_i = S(\tilde{p}_i) = \arg\min_{s_k \in S} |\tilde{p}_i - s_k|_2^2qi=S(p~i)=argminsk∈S∣p~i−sk∣22 |
为什么下采样?
- 降低计算成本(码本匹配、存储、投影)
- 抑制冗余局部波动,提升对噪音和分布偏移的鲁棒性
- 基于时间序列的尺度不变性假设:局部模式在不同分辨率下形态相似
Stage 2: 双路径预测(Dual-path Forecasting)
这是论文的核心架构创新,将预测任务分解为两个互补路径:
┌─────────────────┐ ┌─────────────────┐
│ Quantization │ │ Residual │
│ Path │ + │ Path │
│ (量化路径) │ │ (残差路径) │
└─────────────────┘ └─────────────────┘
↓ ↓
预测未来离散索引 预测不规则波动
Q_y = M_quant(Q_x) Y_r = M_res(X_r)
↓ ↓
↓ 融合 ↓
Ŷ = σ_in(Y_q + Y_r) + μ_in
| 路径 | 功能 | 输入 | 输出 | 模型 |
|---|---|---|---|---|
| 量化路径 | 捕获规则结构,轻量高效 | 离散嵌入 QxQ_xQx | 未来离散索引 QyQ_yQy | 轻量MLP(隐藏层32) |
| 残差路径 | 重建量化丢失的细微变化 | 残差 Xr=X−XqX_r = X - X_qXr=X−Xq | 未来残差 YrY_rYr | MLP(隐藏层512) |
残差计算:
Xq=Rec(Qx∣S)=Upsample([sq(i−1)⋅N+1∣∣⋯∣∣sqi⋅N])X_q = Rec(Q_x|S) = Upsample([s_{q_{(i-1)\cdot N+1}} || \cdots || s_{q_{i\cdot N}}])Xq=Rec(Qx∣S)=Upsample([sq(i−1)⋅N+1∣∣⋯∣∣sqi⋅N])
最终预测:
Y^=σin(Yq+Yr)+μin\hat{Y} = \sigma_{in}(Y_q + Y_r) + \mu_{in}Y^=σin(Yq+Yr)+μin
损失函数:Lpre=∥Y^−Y∥1L_{pre} = \|\hat{Y} - Y\|_1Lpre=∥Y^−Y∥1(L1损失,对异常值更鲁棒)
Stage 3: 码本构建与更新(Codebook Construction & Updating)
这是论文的另一大核心贡献——解决码本如何适应非平稳数据的难题。
3.1 伪码本构建(每轮迭代)
随机采样 patches → 聚类 → 得到聚类中心 = 伪码本 Ŝ^t
能量函数(矩阵形式):
Lc=Tr((P~t−MS^t)⊤I(P~t−MS^t))L_c = Tr((\tilde{P}^t - M\hat{S}^t)^\top I (\tilde{P}^t - M\hat{S}^t))Lc=Tr((P~t−MS^t)⊤I(P~t−MS^t))
聚类中心更新:
S^t=(M⊤IP~t)/(M⊤IM)\hat{S}^t = (M^\top I \tilde{P}^t) / (M^\top I M)S^t=(M⊤IP~t)/(M⊤IM)
3.2 增量更新策略
关键问题:静态码本无法适应分布偏移,但剧烈更新会导致不稳定
解决方案:增量加权更新
St=St−1+1t(W^tS^t−St−1)S^t = S^{t-1} + \frac{1}{t}(\hat{W}^t \hat{S}^t - S^{t-1})St=St−1+t1(W^tS^t−St−1)
性质:递归展开后可得
St=1t(W1S^1+W2S^2+⋯+WtS^t)S^t = \frac{1}{t}(W^1\hat{S}^1 + W^2\hat{S}^2 + \cdots + W^t\hat{S}^t)St=t1(W1S^1+W2S^2+⋯+WtS^t)
即各轮伪码本以均匀形式贡献,但影响程度由 W^j\hat{W}^jW^j 调节
3.3 嵌入正则化
防止码字坍塌(codebook collapse):
Lsep=log∑i,j=1Kexp(−∥s^it−s^jt∥22)/τL_{sep} = \log \sum_{i,j=1}^K \exp(-\|\hat{s}^t_i - \hat{s}^t_j\|_2^2)/\tauLsep=logi,j=1∑Kexp(−∥s^it−s^jt∥22)/τ
其中 τ=∥S^t∥22\tau = \|\hat{S}^t\|_2^2τ=∥S^t∥22 确保嵌入空间大小各轮一致
核心创新:可靠性感知评分(Reliability-aware Scoring)
这是论文最具理论深度的部分,通过**分布鲁棒优化(DRO)**融合三个互补的可靠性因子:
┌─────────────────┐ ┌─────────────────┐ ┌─────────────────┐
│ 表征质量 w_rep │ │ 历史一致性 w_Δ │ │ OOD敏感度 w_je │
│ (Representational│ │ (Historical │ │ (Out-of-Distribution│
│ Quality) │ │ Consistency) │ │ Sensitivity) │
└─────────────────┘ └─────────────────┘ └─────────────────┘
↓ ↓ ↓
└────────┬────────┘
↓
融合函数 M_fus(·)
↓
分布鲁棒优化(DRO)
↓
可靠性权重 Ŵ^t
三个可靠性因子
| 因子 | 计算方式 | 物理意义 | 高值含义 |
|---|---|---|---|
| wrepw_{rep}wrep | 1−exp(∣Bk(Rec(S^t(P~t)∣S^t)−P~t)∣22)exp(∣Rec(S^t(P~t)∣S^t)−P~t∣22)+ε1 - \frac{\exp(|B_k(Rec(\hat{S}^t(\tilde{P}^t)|\hat{S}^t) - \tilde{P}^t)|_2^2)}{\exp(|Rec(\hat{S}^t(\tilde{P}^t)|\hat{S}^t) - \tilde{P}^t|_2^2)+\varepsilon}1−exp(∣Rec(S^t(P~t)∣S^t)−P~t∣22)+εexp(∣Bk(Rec(S^t(P~t)∣S^t)−P~t)∣22) | 簇内重建误差 | 该码字能更好表征其分配的patches |
| wΔw_{\Delta}wΔ | exp(∣Bk(S^t−St−1)∣22)exp(∣S^t−St−1∣22)+ε\frac{\exp(|B_k(\hat{S}^t - S^{t-1})|_2^2)}{\exp(|\hat{S}^t - S^{t-1}|_2^2)+\varepsilon}exp(∣S^t−St−1∣22)+εexp(∣Bk(S^t−St−1)∣22) | 与上轮码本的偏差 | 历史码字对新数据拟合不足,需更大调整 |
| wjew_{je}wje | 1−exp(∑i=1C×Np∣p~it−s^kt∣)exp(∑k=1K∑i=1C×Np∣p~it−s^kt∣)+ε1 - \frac{\exp(\sum_{i=1}^{C\times N_p} |\tilde{p}^t_i - \hat{s}^t_k|)}{\exp(\sum_{k=1}^K \sum_{i=1}^{C\times N_p} |\tilde{p}^t_i - \hat{s}^t_k|)+\varepsilon}1−exp(∑k=1K∑i=1C×Np∣p~it−s^kt∣)+εexp(∑i=1C×Np∣p~it−s^kt∣) | 联合能量(选择频率+方差) | 防止嵌入空间坍塌,增强OOD适应性 |
DRO融合(分布鲁棒优化)
问题:三个指标互补但重要性随数据 regime 变化,固定权重不稳定
方案:在KL散度约束下,求最坏情况分布下的期望可靠性
w^kt=minθ∈Uγ⟨θ,zkt⟩,Uγ={θ∈Θ3∣DKL(θ∥u)≤γ}\hat{w}^t_k = \min_{\theta \in U_\gamma} \langle \theta, z^t_k \rangle, \quad U_\gamma = \{\theta \in \Theta^3 | D_{KL}(\theta \| u) \leq \gamma\}w^kt=θ∈Uγmin⟨θ,zkt⟩,Uγ={θ∈Θ3∣DKL(θ∥u)≤γ}
其中 zkt=[wrep,kt,wΔ,kt,wje,kt]z^t_k = [w^t_{rep,k}, w^t_{\Delta,k}, w^t_{je,k}]zkt=[wrep,kt,wΔ,kt,wje,kt],u=[1/3,1/3,1/3]u = [1/3, 1/3, 1/3]u=[1/3,1/3,1/3]
闭式解(推导见附录A.2):
w^kt=−γ⋅log∑i=13exp(−zk,itγ)\boxed{\hat{w}^t_k = -\gamma \cdot \log \sum_{i=1}^3 \exp\left(-\frac{z^t_{k,i}}{\gamma}\right)}w^kt=−γ⋅logi=1∑3exp(−γzk,it)
解读:这是软最小值(soft-minimum):
- γ→0\gamma \to 0γ→0:趋向 min(zkt)\min(z^t_k)min(zkt)(最保守)
- γ→∞\gamma \to \inftyγ→∞:趋向 mean(zkt)\text{mean}(z^t_k)mean(zkt)(平均)
优势:自适应地让最可靠的指标主导,同时柔和地抑制其他指标,缓解异常值或瞬时不一致的影响
实验结果
数据集
| 数据集 | 变量数 | 时间步 | 采样间隔 | 领域 |
|---|---|---|---|---|
| ETTm1/m2 | 7 | 57,600 | 15分钟 | 电力 |
| ETTh1/h2 | 7 | 14,400 | 1小时 | 电力 |
| ECL | 321 | 26,304 | 1小时 | 电力 |
| Traffic | 862 | 17,544 | 1小时 | 交通 |
| Weather | 21 | 52,696 | 10分钟 | 气象 |
| Solar | 137 | 52,560 | 10分钟 | 能源 |
主结果(表1)
ReCast在16个指标中的12个取得SOTA:
| 模型类型 | 代表模型 | 表现 |
|---|---|---|
| Transformer类 | iTransformer, PatchTST, TQNet | 对噪音敏感,表现不稳定 |
| CNN类 | TimesNet | 长程依赖建模能力有限 |
| MLP类 | PatchMLP, CycleNet, DLinear | 轻量但难以捕捉复杂模式 |
| ReCast (Ours) | 码本辅助双路径 | 12/16 SOTA,兼顾精度与效率 |
消融实验(表2)
| 变体 | 修改 | 关键发现 |
|---|---|---|
| -Residual | 移除残差路径 | 性能下降 → 残差路径对恢复细粒度变化至关重要 |
| -Updating | 冻结码本 | 显著恶化 → 动态更新对分布偏移必不可少 |
| -Random | 移除下采样和随机采样 | 性能下降 → 降采样和随机采样防过拟合 |
| -Scoring | 禁用可靠性评分(等权重) | 下降 → 可靠性加权有效 |
| -DRO | 均匀加权三指标 | 比-Scoring好但不如完整版 → DRO融合更鲁棒 |
计算效率(图3)
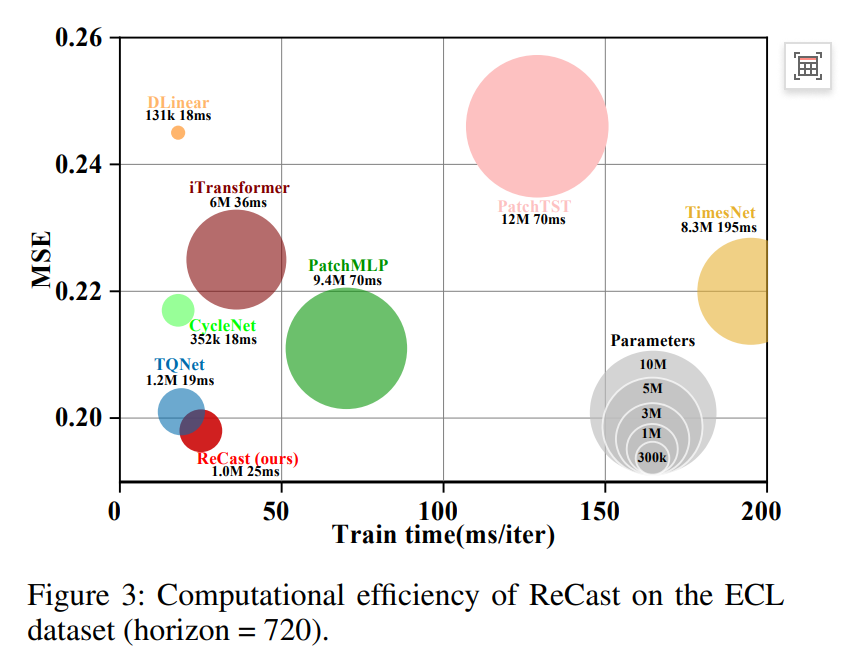
气泡图解读:
- X轴:训练时间(ms/iter)
- Y轴:MSE(越低越好)
- 气泡大小:参数量
ReCast: 1.0M参数, 25ms/iter, MSE≈0.195
PatchMLP: 9.4M参数, 70ms/iter
iTransformer: 6M参数, 36ms/iter
TimesNet: 8.3M参数, 195ms/iter
结论:ReCast以最少参数、中等速度达到最低MSE,效率-精度平衡最优
码本演化可视化(图4)
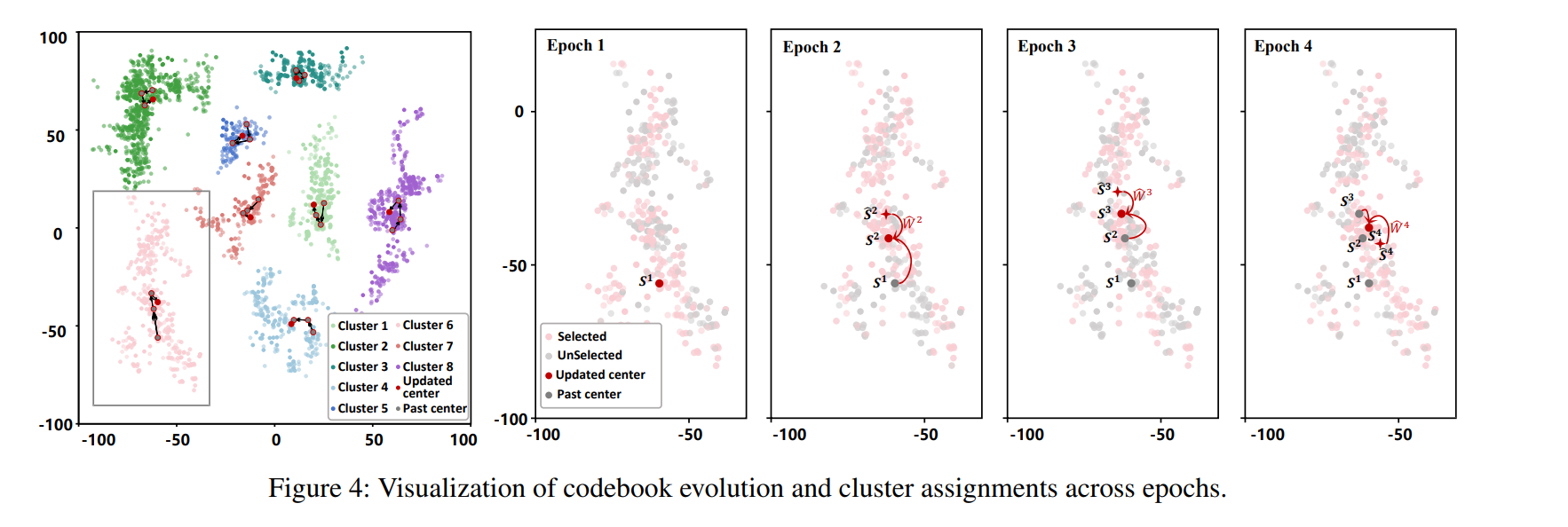
左图:8个簇的聚类结果(t-SNE降维)
- 不同颜色代表不同簇
- 随机采样下聚类分配稳定,中心平滑收敛
右图:4轮迭代中的码本更新
- Epoch 2: 伪码本 Ŝ² 比 S¹ 更适配当前分布
- 可靠性更新赋予 Ŝ² 更高权重,S² 向其偏移
- 证明机制有效平衡"适应"与"稳定"
超参数敏感性(图5)
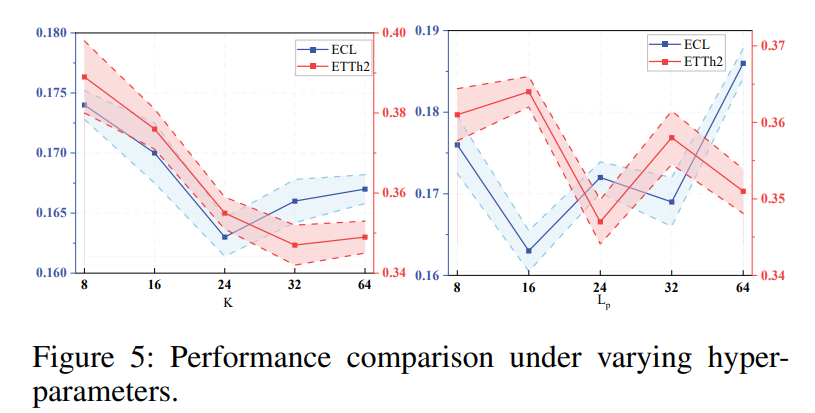
- K(码本大小):K=32时性能趋于饱和,过大无益
- LpL_pLp(patch长度):Lp=16L_p=16Lp=16 或 24 较优,存在波动
局限性:K和LpL_pLp目前凭经验设定,缺乏自适应理论指导
核心贡献总结
| 贡献 | 说明 |
|---|---|
| 1. 码本辅助轻量预测框架 | 将局部模式量化为离散嵌入,显著降低模型复杂度 |
| 2. 双路径架构 | 量化路径捕获规则结构 + 残差路径重建不规则波动 |
| 3. 可靠性感知更新机制 | DRO融合三因子,实现稳定且自适应的码本演化 |
| 4. SOTA性能 | 8个数据集验证,精度、泛化、鲁棒性兼优 |
与第一篇论文的关联
| 维度 | 残差分析论文(Pattern Recognition) | ReCast(AAAI) |
|---|---|---|
| 核心问题 | “残差中是否有可解释模式?” | “如何用残差提升预测性能?” |
| 残差角色 | 研究对象(挖掘隐藏模式) | 辅助路径(补偿量化损失) |
| 方法 | 矩阵轮廓 + 模体发现 | 向量量化 + 双路径MLP |
| 量化/离散化 | 无(关注连续残差) | 核心(码本量化局部形状) |
| 应用场景 | 知识发现、可解释性 | 实时预测、资源受限环境 |

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 0
0 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)