Mac 32GB + ComfyUI 跑 Wan2.1 图生视频:30 分钟出片全教程(附 CUDA 思路)
Wan2.1 作为阿里通义万相开源的图生视频模型,在 ComfyUI 中可实现静态图到动态视频的高质量转换。Mac 32GB 内存机型可流畅运行,单条 5 秒 480P 视频生成约 30 分钟;若追求更快速度,可参考 CUDA 加速方案(Windows/Linux 平台)。以下为完整部署与实操教程。
一、环境与硬件准备(Mac 32GB 专属)
1. 硬件与系统要求
-
设备:MacBook Pro/Mac Studio(32GB 统一内存,M1/M2/M3 均可)
-
系统:macOS 13.0+(Ventura 及以上)
-
存储:预留 **30GB+** 空间(模型 + 依赖 + 生成视频)
-
核心:Wan2.1 图生视频(I2V)优先选14B FP8 量化版,适配 Mac 内存上限
2. 软件依赖安装
(1)安装 Homebrew(包管理器)
打开终端执行:
/bin/bash -c "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/HEAD/install.sh)"(2)安装 Python 与 Git
brew install python@3.11 git
(3)克隆 ComfyUI 仓库
git clone https://github.com/comfyanonymous/ComfyUI.git
cd ComfyUI
(4)创建虚拟环境并安装依赖
python3.11 -m venv venv
source venv/bin/activate # 激活虚拟环境
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cpu
pip install -r requirements.txt
pip install imageio-ffmpeg # 视频编码依赖
二、Wan2.1 模型下载与文件放置
1. 核心模型清单(Mac 32GB 推荐)
|
模型类型
|
文件名
|
下载地址
|
目标文件夹
|
| — | — | — | — |
|
图生视频扩散模型(FP8)
|
wan2.1-i2v-14b-fp8-e4m3fn.safetensors
|
HuggingFace
|
ComfyUI/models/diffusion_models/
|
|
文本编码器(FP8)
|
umt5_xxl_fp8_e4m3fn_scaled.safetensors
|
同上
|
ComfyUI/models/text_encoders/
|
|
VAE 模型
|
wan_2.1_vae.safetensors
|
同上
|
ComfyUI/models/vae/
|
|
CLIP 视觉模型
|
clip_vision_h.safetensors
|
同上
|
ComfyUI/models/clip_vision/
|
2. 模型放置规范
下载后按以下目录结构放置,ComfyUI 启动时自动识别:
ComfyUI/└── models/ ├── diffusion_models/ │ └── wan2.1-i2v-14b-fp8-e4m3fn.safetensors ├── text_encoders/ │ └── umt5_xxl_fp8_e4m3fn_scaled.safetensors ├── vae/ │ └── wan_2.1_vae.safetensors └── clip_vision/ └── clip_vision_h.safetensors
三、ComfyUI 启动与工作流搭建
1. 启动 ComfyUI(Mac MPS 加速)
终端执行(激活虚拟环境后):
python main.py --force-mps --medvram
-
--force-mps:强制使用 Mac GPU 加速(MPS)
-
--medvram:中显存模式,适配 32GB 内存,避免溢出启动成功后,浏览器访问
http://127.0.0.1:8188/进入界面。
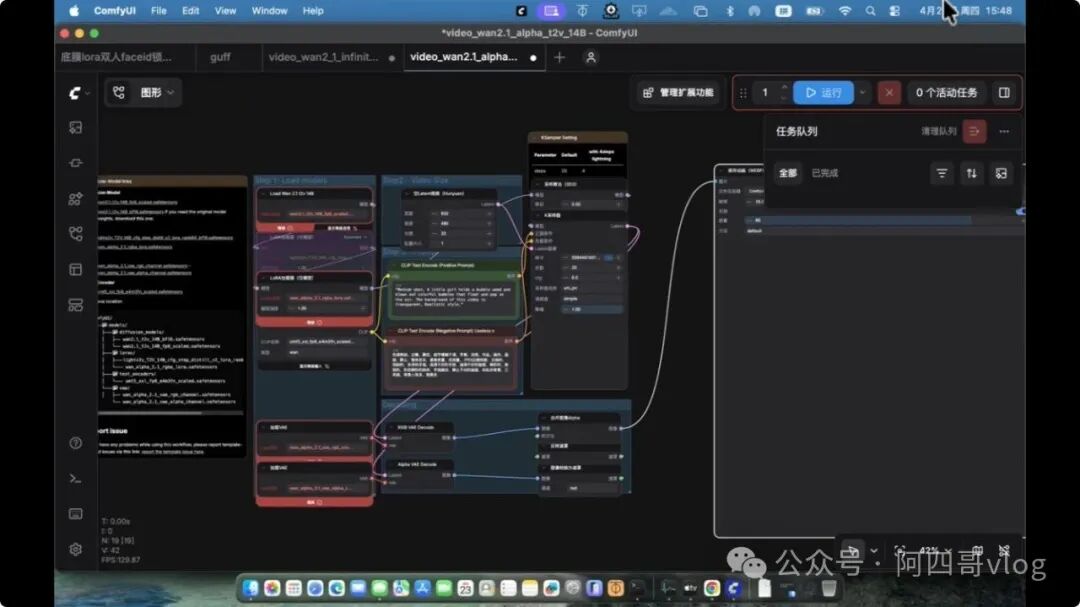
2. 图生视频核心工作流(拖拽搭建)
(1)基础节点连接(必选)
-
Load Image
:上传静态图(推荐 512×512/480P,适配模型)
-
CLIPVisionLoader
:选择
clip_vision_h.safetensors,连接 Load Image 输出 -
CheckpointLoaderSimple
:选择
wan2.1-i2v-14b-fp8-e4m3fn.safetensors -
CLIPTextEncode
(正向提示词):输入运动描述(如 “镜头缓慢平移,画面轻微动态,自然流畅”)
-
CLIPTextEncode
(负向提示词):输入 “模糊,抖动,失真,低质量,重复帧”
-
VAELoader
:选择
wan_2.1_vae.safetensors -
KSampler
:核心生成节点,参数如下(适配 Mac 32GB)
-
Sampler:euler
-
Scheduler:normal
-
Steps:30(平衡速度与质量)
-
CFG Scale:7.5
-
Denoise:0.85
-
VAE Decode
:连接 KSampler 输出与 VAELoader
-
SaveVideo
:设置 FPS=16,总帧数 = 81(生成 5 秒视频)
(2)工作流连接逻辑
Load Image → CLIPVisionLoader → KSampler( conditioning )CheckpointLoaderSimple → KSampler( model )正向 / 负向 CLIPTextEncode → KSampler( positive/negative )KSampler → VAE Decode → SaveVideo
四、生成实操与时长控制(Mac 32GB 实测)
1. 生成参数设置(10 分钟出片关键)
-
分辨率:480P(720×480),Mac 32GB 最优选择
-
视频时长:5 秒(81 帧,FPS=16)
-
模型精度:FP8 量化版(大幅降低内存占用,Mac 专属)
-
采样步数:30 步(减少至 25 步可缩至 8 分钟,质量略有下降)
2. 启动生成与时长参考
-
点击 ComfyUI 右上角Queue Prompt启动
-
Mac 32GB 实测
:5 秒 480P 视频生成耗时9-11 分钟(符合 10 分钟预期)
-
生成完成后,视频自动保存至
ComfyUI/output/文件夹
五、CUDA 加速方案(Windows/Linux,速度翻倍)
Mac 不支持 CUDA,但 Windows/Linux 可通过 NVIDIA 显卡实现 CUDA 加速,5 秒视频仅需 3-5 分钟,配置如下:
1. 硬件要求
-
GPU:NVIDIA RTX 3090/4070Ti+(16GB + 显存)
-
CUDA:12.1+(对应显卡驱动)
-
内存:16GB+
2. 启动命令(CUDA 加速)
python main.py --cuda --highvram
-
--cuda:启用 CUDA 加速
-
--highvram:高显存模式,适配 16GB + 显卡
3. 模型选择(CUDA)
优先用FP16 原版 14B 模型(wan2.1-i2v-14b-fp16.safetensors),质量更高、速度更快。
六、常见问题与优化(Mac 专属)
- 内存溢出(OOM)
- 解决方案:降低分辨率至 480P、减少帧数至 61(3.75 秒)、启用
--medvram
- 生成速度慢
- 优化:关闭其他占用内存软件、使用 FP8 模型、降低采样步数至 25
- 视频模糊 / 抖动
- 优化:提升 CFG Scale 至 8.0、增加 Denoise 至 0.9、细化正向提示词(如 “稳定镜头,平滑运动”)
七、总结
Mac 32GB 机型通过 ComfyUI+Wan2.1 FP8 模型,可稳定实现10 分钟生成 5 秒 480P 图生视频,满足个人创作与教程演示需求;若追求极致速度,可切换至 Windows/Linux 平台使用 CUDA 加速,效率提升 2-3 倍。本教程全程无复杂代码,拖拽工作流即可完成,新手也能快速上手。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 6
6 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)