多模态大模型(VLM)分享&ALBEF
ALBEF
多模态学习有很多下游任务,比如文本图像检索,它是相对简单的任务,只需要能用模型生成的文本向量检索到模型生成的图片向量,或者根据图片向量索到文本向量就可以。还有更复杂的一些任务,比如图像问答、多模态推理等,他们需要对图片和文本有更进一步的融合理解。
图像和文本多模态模型一般都由三个部分组成,一个是图像进行编码的部分,一个是对文本进行编码的部分,还有就是对图像和文本进行融合的部分。根据各个部分在整个模型中所占比重的不同,可以分为以下四种结构,第一种结构是图像编码器参数比重较大,文本编码器参数量比重较小,而融合编码器参数比重最小。这种结构在早期多模态融合网络结构里很常见。那时候图像编码器这边会用一个目标检测的卷积神经网络提取出多个检测框,每个检测框作为一个语义单元,文本编码器这边一般接一个BERT,然后图片文本编码器输出各自模态的特征,在融合时只做简单的cos相似度计算。这种结构的模型因为目标检测网络比较大,所以导致图像编码器部分的参数量较大。在模型训练和推理过程中,大部分的计算都花费在图像部分。
第二种结构是图像编码器和文本编码器参数占比差不多。比如我们之前讲过的clip模型,它因为图像部分已经不用目标检测的网络了,采用了resnet或者VIT,所以图像编码器和文本编码器参数量类似。这种结构的融合编码器还是和第一种结构一样,不同模态只是进行简单的计算。比如像clip模型里只是计算了不同模态特征向量的余弦相似度。我们在讲clip模型时也说过,增加视觉部分的网络大小,模型的精度会有所提升。但是对于文本编码器部分,增加模型大小后变化不大。可见视觉模型参数占比比文本模型参数占比大还是很有必要的这是因为图像数据输入的是单个像素,还没有语义信息,但是文本输入的是token,本身就具有语义的抽象。所以图像编码器这边应该多一些层来做从原始的像素信息提取语义信息的工作。
第一种结构和第二种结构。因为融合编码器都很简单,对于文本图像检索任务还可以,但是对于像图像问答、多模态推理等任务表现就差强人意了。因为后者需要对两种模态进行更深度的融合才能很好的完成。
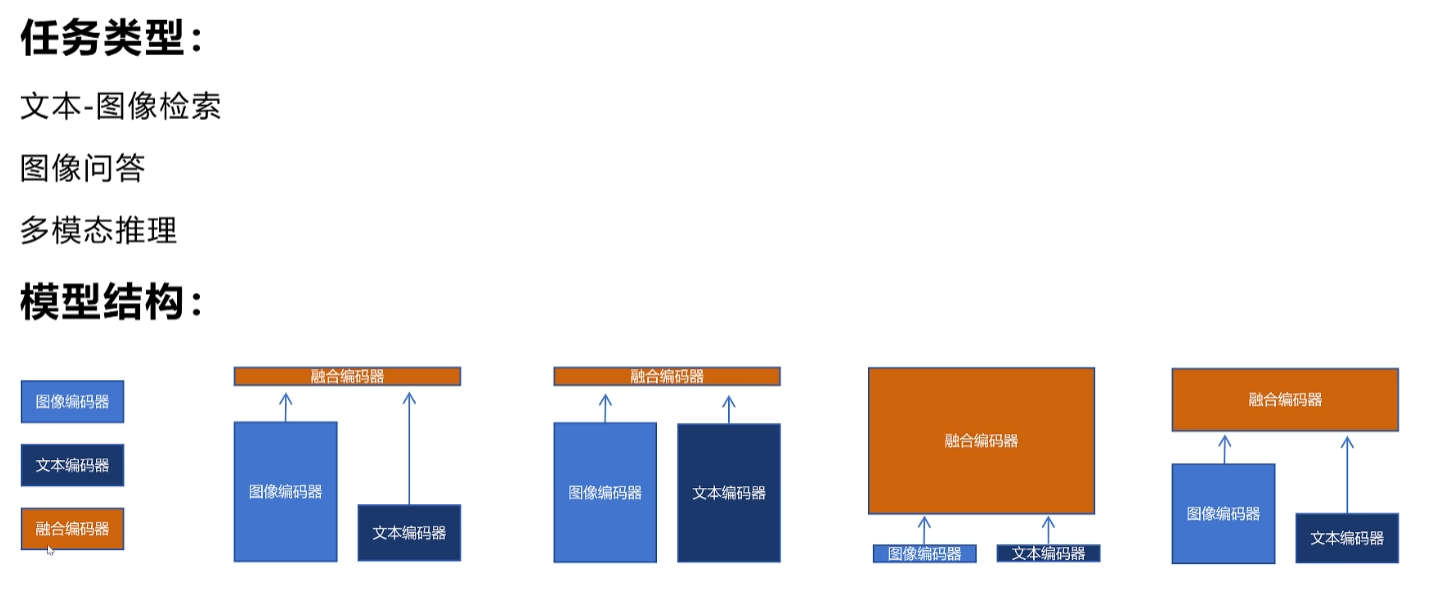
我们再看第三种结构,他的想法是让图像编码器和文本编码器都尽可能的简单。图像编码器这边就直接按照VIT的思路,把图像分别分割成多个patch,每个patch用线性映射转换为图像token。然后文本编码器这边直接token ized和embedding之后转化为文本的token,然后给他们加上各自的模态编码和位置编码,送入transformer的融合编码器。这种结构实现简单推理速度快,但是效果一般。
结合前三种结构的优缺点,我们可以总结如下。第一,最好是图像和文本各自用不同的编码器先分别进行编码,然后再进行多模态融合。第二,图像编码器应该是要比文本编码器更大。第三,融合编码器不能太简单,因为它对于复杂的多模态任务是很有帮助的。第四种结构就是结合了前三种结构的优点,也是l bas所采用的模型结构。
下面我们就来看ALBEF的具体模型结构。首先左边是一个图片,编码器采用的是VIT结构。右边是一个文本编码器,采用的是bot结构。可以看到图像这边采用了12层文本编码器,这边采用了六层图片编码器,网络层数是大于文本编码器的。然后每个编码器都有一个额外的CLS token,用来分别提取图片和文本的特征。接着用它们提取的特征计算余弦相似度,计算对比loss。
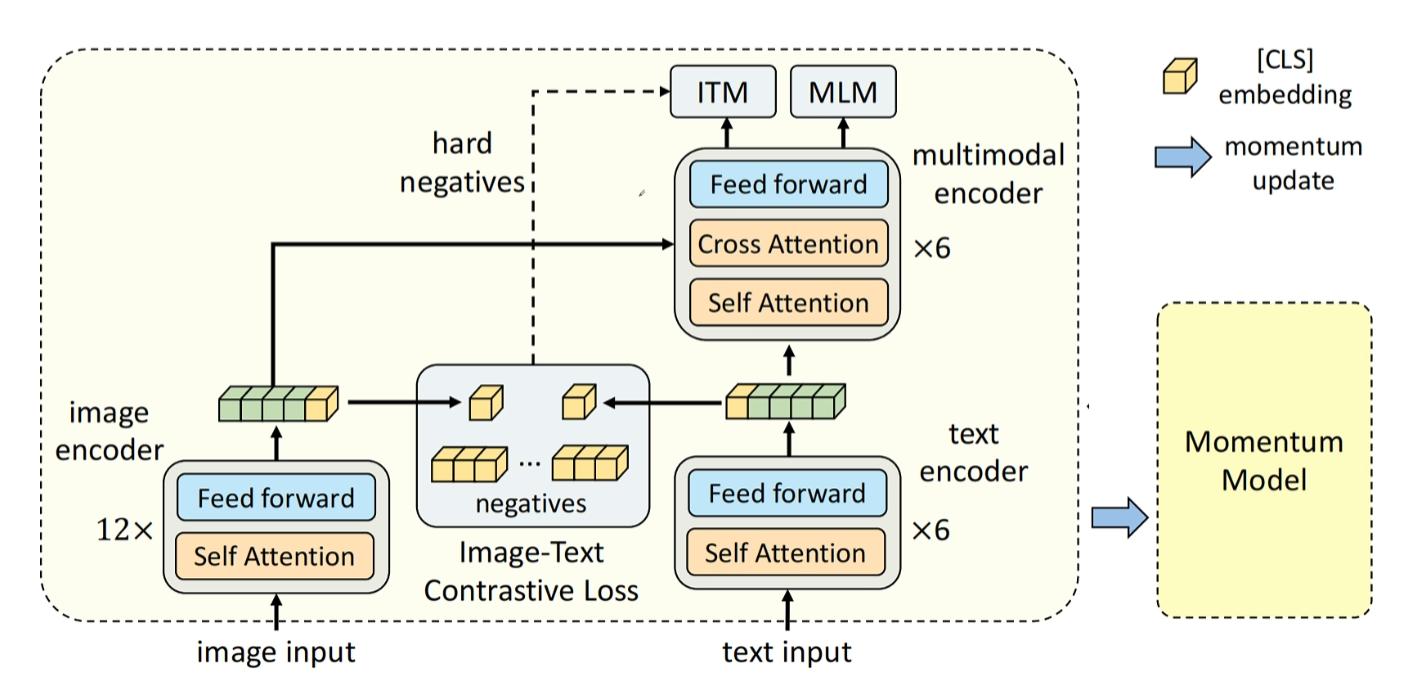
目前的这个结构和clip是非常相似的,不同的是clip文本编码器部分用的是带mask的注意力机制,提取最后一个token的向量来代表整个文本。L buff里用的是双向注意力机制,提取的是第一个CLS token的向量来代表整个文本。除此之外其他都是完全一致的。所以到目前为止,l bus里有一个clip模型,它通过图像和文本的对比学习对齐了模型文本和图像的特征的表示,这也是这篇论文的最重要的部分。Align before fuse在融合前对齐。
另外ALBEF结合了moco的思想,对clip进行了改进,那就是增加了动量模型。这个动量模型既有图片encode的参数,也有文本encode的参数。这样动量模型就可以通过队列缓存给图片和文本分别提供又多又一致的文本和图像特征的复利了。需要注意的是,这里训练模型生成的图像向量是和动量模型生成的文本向量队列进行对比。训练模型生成的文本向量是和动量模型生成的图片向量队列进行对比。每个batch训练模型更新完自己的参数后会去动量更新动量模型的参数。
接下来就进入到了ALBEF多模态融合的网络部分,可以看到它在文本编码器上已经有了六层的基础上又增加了6层。不同的是新增加的这六层每一层都有一个cross attention。Cross attention里的query是来自文本编码器K和value来自图像编码器的输出,这样就实现了多模态的融合。这个cross attention就是transformer架构里decoder的里面的cross attention。在transformer架构里解码器部分就是通过cross attention来从编码器那边获取信息。在ALBEF里面cross attention就是用来从图像这个模态获取信息的。
除了上面介绍类似clip部分的图像文本特征对齐的image text contrast任务,简称ITC。
通过图像文本匹配任务和带掩码的语言模型任务,可以让多模态融合部分充分的进行模态融合。这里还有一个点需要注意,那就是在进行图像文本匹配任务时会选择难负例。选择的标准是一个batch里那些非匹配的文本队里相似度最高的负例对,难的负例可以迫使模型注意细节,学到更多有用的特征。
ALBEF论文还有另外一个贡献,就是他所谓的动量蒸馏。什么是动量蒸馏呢?我们就来详细介绍一下。因为在进行多模态模型训练时,图文对都是在互联网采集的,这些图文对未必非常匹配。就是数据会有噪声。
动量蒸馏就是用来解决这个问题的。它的解决办法就是在计算loss时,不光考虑采集数据中的标准答案,而且考虑当前训练模型和缓慢稳定更新的动量模型输出的分布不能差别太大。
衡量两个概率分布差距最常用的指标就是KL散度,KL散度是一个大于零的值,如果两个分布完全一致,则KL散度值为零,如果不一致就大于0。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 3
3 0
0- 0



 已为社区贡献18条内容
已为社区贡献18条内容

所有评论(0)