Spring AI Alibaba 1.x 系列【35】工作流(Workflow)的核心概念和入门案例
文章目录
1. 概述
Workflow(工作流)是 Spring AI Alibaba Graph 的核心功能,用于构建复杂的、多步骤的 AI 应用。它基于有向图(Directed Graph)模型,将每个处理步骤抽象为节点(Node),通过边(Edge)连接节点形成可自定义的执行流程。
Spring AI Alibaba Graph 是 Agent 编排背后的核心引擎,在底层,Spring AI Alibaba 框架会将 Agent 编排为 Graph,组成一个由节点串联而成的 DAG 图。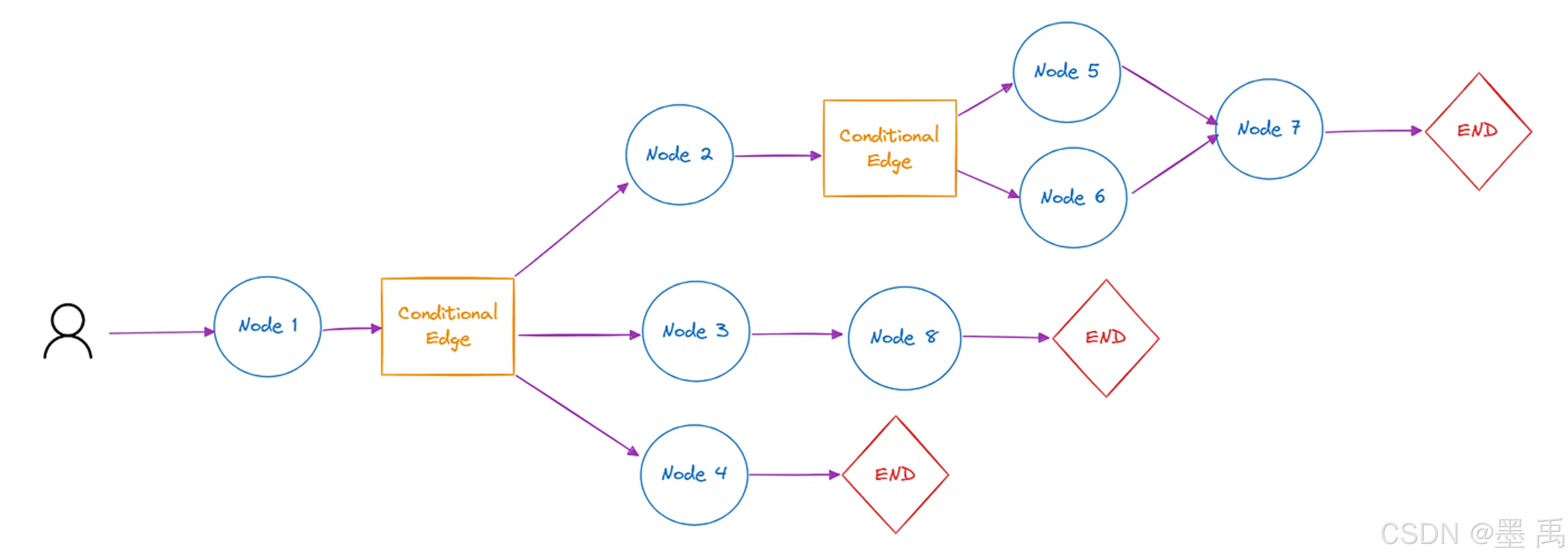
核心价值:
- 解决单个大模型无法处理复杂任务的问题
- 支持多步骤任务编排、条件路由、并行执行
- 提供状态管理和持久化能力
- 支持中断恢复(
Human-in-the-Loop)
2. 核心组件
| 组件 | 作用 | 特性 |
|---|---|---|
| StateGraph(状态图) | 状态图主类,定义工作流结构 | 可视化管理流程、精准控制执行逻辑、支持串行/条件分支/并行汇聚等全场景执行模式 |
| State(状态) | 全局共享数据容器,存储整个工作流的上下文、中间结果与最终数据 | 全局唯一数据源、支持消息累加/状态合并、可自定义数据结构 |
| Node(节点) | 工作流的执行单元,封装具体的业务逻辑/任务操作 | 接收全局状态、返回修改后的状态、支持同步/异步执行 |
| Edge(边) | 定义节点之间的执行流转规则与路径 | 支持无条件顺序跳转、条件分支、并行分叉/汇聚、循环执行 |
2.1 StateGraph
StateGraph 是一种状态感知的图结构,核心是状态驱动的流程引擎,用于建模复杂系统的行为与工作流。它融合了有限状态机 (FSM)与图结构的优势,通过节点、边和共享状态实现对复杂流程的精确控制与可视化管理。
StateGraph(状态图)是 Spring AI Alibaba 图计算框架的核心抽象,用于定义和执行基于状态的 Agent 工作流。它借鉴了 LangGraph 的设计理念,提供了声明式的图结构定义、状态管理、节点执行和边路由能力。
核心设计理念:
- 状态驱动:所有节点共享同一状态对象(
OverAllState),通过状态传递数据 - 声明式定义:通过
addNode/addEdgeAPI 声明式构建图结构 - 异步执行:所有节点动作(
Action)都是异步的,支持非阻塞执行 - 可中断恢复:支持
Human-in-the-Loop和checkpoint机制 - 嵌套子图:支持将另一个
StateGraph作为子节点嵌入
完整执行流程:
定义 StateGraph
↓
添加节点(addNode)
↓
添加边(addEdge, addConditionalEdges)
↓
编译(compile)→ CompiledGraph
↓
执行(invoke/stream)→ GraphRunner
↓
节点执行 → 状态更新 → 边路由
↓
到达 END 或中断点
↓
返回结果或等待恢复
StateGraph 类常量定义、核心成员:
public class StateGraph {
// ==================== 常量定义 ====================
/** 图的终点标识 */
public static final String END = "__END__";
/** 图的起点标识 */
public static final String START = "__START__";
/** 错误节点标识 */
public static final String ERROR = "__ERROR__";
/** 节点执行前钩子标识 */
public static final String NODE_BEFORE = "__NODE_BEFORE__";
/** 节点执行后钩子标识 */
public static final String NODE_AFTER = "__NODE_AFTER__";
// ==================== 核心成员 ====================
/** 节点集合 */
final Nodes nodes = new Nodes();
/** 边集合 */
final Edges edges = new Edges();
/** 状态键策略工厂 */
private final KeyStrategyFactory keyStrategyFactory;
/** 图名称 */
private final String name;
/** 状态序列化器 */
private final StateSerializer stateSerializer;
// ==================== 内部容器类 ====================
/** 节点容器 */
public static class Nodes {
public final Set<Node> elements;
public boolean anyMatchById(String id);
public List<SubStateGraphNode> onlySubStateGraphNodes();
public List<Node> exceptSubStateGraphNodes();
}
/** 边容器 */
public static class Edges {
public final List<Edge> elements;
public Optional<Edge> edgeBySourceId(String sourceId);
public List<Edge> edgesByTargetId(String targetId);
}
}
StateGraph 的核心职责相关方法:
- 结构定义:
addNode():添加节点及其执行动作addEdge():添加无条件边addConditionalEdges():添加条件边addParallelConditionalEdges():添加并行条件边
- 子图嵌入:
addNode(id, CompiledGraph):嵌入已编译子图addNode(id, StateGraph):嵌入未编译子图(编译时自动编译)
- 图验证:
validateGraph():验证节点和边的完整性
- 编译执行:
compile():编译为CompiledGraph(使用默认配置)compile(config):编译为CompiledGraph(使用自定义配置)
- 可视化:
getGraph(type):生成PlantUML/Mermaid等图可视化
构造方式:
// 方式1:使用默认配置(HashMap 作为状态工厂,Jackson 序列化)
StateGraph graph = new StateGraph();
// 方式2:指定键策略工厂
StateGraph graph = new StateGraph(keyStrategyFactory);
// 方式3:指定名称和键策略工厂
StateGraph graph = new StateGraph("my_workflow", keyStrategyFactory);
// 方式4:完整配置(名称、策略工厂、序列化器)
StateGraph graph = new StateGraph("my_workflow", keyStrategyFactory, stateSerializer);
2.2 Node
Node(节点)是 Spring AI Alibaba Graph 模块中状态驱动工作流的执行单元,是封装业务逻辑、模型调用、工具执行等具体操作的核心载体,所有实际计算与处理都在节点中完成。本质是函数式接口,通过 addNode 方法注册到 StateGraph 中。
定义了两种主要的节点接口:
| 函数式接口 | 入参 | 核心作用 |
|---|---|---|
AsyncNodeAction |
OverAllState |
基础节点接口,接收全局状态,执行业务逻辑 |
AsyncNodeActionWithConfig |
OverAllState + RunnableConfig |
增强节点接口,支持接收运行时配置 |
AsyncNodeAction 源码如下:
/**
* 表示一个异步节点操作,用于处理智能体状态并返回状态更新结果
*/
@FunctionalInterface
public interface AsyncNodeAction extends Function<OverAllState, CompletableFuture<Map<String, Object>>> {
/**
* 执行节点操作
* @param state 全局状态(OverAllState)
* @return 异步执行结果:包装为 CompletableFuture 的状态更新数据
*/
CompletableFuture<Map<String, Object>> apply(OverAllState state);
/**
* 【核心适配方法】将同步节点操作转换为异步节点操作
* @param syncAction 同步节点动作 NodeAction
* @return 异步节点动作 AsyncNodeAction
*/
static AsyncNodeAction node_async(NodeAction syncAction) {
return state -> {
// 获取当前上下文
Context context = Context.current();
// 创建异步结果对象
CompletableFuture<Map<String, Object>> result = new CompletableFuture<>();
try {
// 执行同步逻辑,完成异步结果
result.complete(syncAction.apply(state));
}
catch (Exception e) {
// 异常捕获,传递异常信息
result.completeExceptionally(e);
}
return result;
};
}
}
AsyncNodeAction 源码如下:
/**
* 支持运行时配置的异步节点操作接口
* 继承 BiFunction,接收 全局状态 + 运行配置,返回异步状态更新结果
*/
public interface AsyncNodeActionWithConfig
extends BiFunction<OverAllState, RunnableConfig, CompletableFuture<Map<String, Object>>> {
/**
* 执行节点操作(核心方法)
* @param state 全局状态(OverAllState)
* @param config 运行时配置(RunnableConfig),传递执行参数、上下文配置
* @return 异步执行结果:包装为 CompletableFuture 的状态更新数据
*/
CompletableFuture<Map<String, Object>> apply(OverAllState state, RunnableConfig config);
/**
* 同步转异步适配器:将带配置的同步节点转为异步节点
* @param syncAction 同步节点动作 NodeActionWithConfig
* @return 异步节点动作 AsyncNodeActionWithConfig
*/
static AsyncNodeActionWithConfig node_async(NodeActionWithConfig syncAction) {
return (state, config) -> {
Context context = Context.current();
CompletableFuture<Map<String, Object>> result = new CompletableFuture<>();
try {
// 执行同步逻辑,完成异步结果
result.complete(syncAction.apply(state, config));
} catch (Exception e) {
// 异常捕获并包装到异步结果中
result.completeExceptionally(e);
}
return result;
};
}
/**
* 适配器:将普通 AsyncNodeAction 适配为支持配置的 AsyncNodeActionWithConfig
* @param action 基础异步节点
* @return 兼容配置的异步节点
*/
static AsyncNodeActionWithConfig of(AsyncNodeAction action) {
// 如果是可中断节点,使用专属包装器
if (action instanceof InterruptableAction) {
return new InterruptableAsyncNodeActionWrapper(action, (InterruptableAction) action);
}
// 忽略配置,直接执行原节点逻辑
return (state, config) -> action.apply(state);
}
/**
* 可中断异步节点包装器
* 同时支持 AsyncNodeActionWithConfig 与 中断能力(InterruptableAction)
*/
class InterruptableAsyncNodeActionWrapper implements AsyncNodeActionWithConfig, InterruptableAction {
private final AsyncNodeAction delegate;
private final InterruptableAction interruptable;
public InterruptableAsyncNodeActionWrapper(AsyncNodeAction delegate, InterruptableAction interruptable) {
this.delegate = delegate;
this.interruptable = interruptable;
}
// 执行节点逻辑
@Override
public CompletableFuture<Map<String, Object>> apply(OverAllState state, RunnableConfig config) {
return delegate.apply(state);
}
// 节点中断逻辑
@Override
public Optional<InterruptionMetadata> interrupt(String nodeId, OverAllState state, RunnableConfig config) {
return interruptable.interrupt(nodeId, state, config);
}
// 节点执行后中断逻辑
@Override
public Optional<InterruptionMetadata> interruptAfter(String nodeId, OverAllState state,
Map<String, Object> actionResult, RunnableConfig config) {
return interruptable.interruptAfter(nodeId, state, actionResult, config);
}
}
}
2.3 Edge
边(Edge)定义了工作流的逻辑路由规则与图执行终止条件,是节点间通信与智能体工作的核心部分。
有几种关键类型的边:
- 普通边(
Normal Edges):直接定义从一个节点到下一个节点的固定路由。 - 条件边(
Conditional Edges):通过调用路由函数,动态决策下一个执行节点。 - 入口点(
Entry Point):定义用户输入到达时,首个执行的节点。 - 条件入口点(
Conditional Entry Point):通过调用路由函数,动态决策用户输入的首个执行节点。
StateGraph 中添加【普通边】的方法:
/**
* 向状态图中添加一条【普通边】,建立源节点到目标节点的固定路由关系
* @param sourceId 源节点ID(路由起点)
* @param targetId 目标节点ID(路由终点)
* @return 当前StateGraph实例,支持链式调用
* @throws GraphStateException 边ID非法、或路由配置异常时抛出
*/
public StateGraph addEdge(String sourceId, String targetId) throws GraphStateException {
// 1. 核心校验:禁止将 END(结束节点) 作为源节点,结束节点无法向外发起路由
if (Objects.equals(sourceId, END)) {
throw Errors.invalidEdgeIdentifier.exception(END);
}
// 2. 创建新的边对象:单目标节点的普通边
var newEdge = new Edge(sourceId, new EdgeValue(targetId));
// 3. 检查是否已存在【同来源节点】的边(Edge的equals仅判断sourceId)
int index = edges.elements.indexOf(newEdge);
if (index >= 0) {
// 场景:已存在同源节点的边 → 合并目标节点,自动升级为【并行边】
// 获取原有的目标节点列表
var newTargets = new ArrayList<>(edges.elements.get(index).targets());
// 追加新的目标节点
newTargets.add(newEdge.target());
// 替换原边,生成包含多个目标的并行边
edges.elements.set(index, new Edge(sourceId, newTargets));
}
else {
// 场景:无同源节点的边 → 直接添加新的普通边
edges.elements.add(newEdge);
}
// 4. 返回当前对象,支持链式调用(如:graph.addEdge(a,b).addEdge(c,d))
return this;
}
StateGraph 中添加【条件边】的方法:
/**
* 向状态图中添加【条件边】,根据动态条件决定路由目标节点
* @param sourceId 源节点ID(路由起点)
* @param condition 路由条件函数(根据状态计算出路由结果)
* @param mappings 路由结果映射表(key=条件返回值, value=目标节点ID)
* @return 当前StateGraph实例,支持链式调用
* @throws GraphStateException 边ID非法、映射为空、或条件边重复时抛出
*/
public StateGraph addConditionalEdges(String sourceId, AsyncCommandAction condition, Map<String, String> mappings)
throws GraphStateException {
// 1. 合法性校验:禁止将 END(结束节点) 作为源节点,结束节点无法向外发起路由
if (Objects.equals(sourceId, END)) {
throw Errors.invalidEdgeIdentifier.exception(END);
}
// 2. 合法性校验:条件边的路由映射规则不能为空
if (mappings == null || mappings.isEmpty()) {
throw Errors.edgeMappingIsEmpty.exception(sourceId);
}
// 3. 创建条件边对象:封装 源节点ID + 路由条件 + 映射规则
var newEdge = new Edge(sourceId, new EdgeValue(EdgeCondition.single(condition, mappings)));
// 4. 校验:同一个源节点不允许重复添加条件边(避免路由冲突)
if (edges.elements.contains(newEdge)) {
throw Errors.duplicateConditionalEdgeError.exception(sourceId);
}
else {
// 5. 无重复则将条件边添加到图的边集合中
edges.elements.add(newEdge);
}
// 6. 返回当前对象,支持链式调用
return this;
}
StateGraph 中添加【并行条件边】的方法:
/**
* 向状态图中添加【并行条件边】,支持根据路由结果动态转发到**多个节点并行执行**
* 适用于条件动作可返回多个目标节点,且这些目标节点需要并发执行的场景
*
* @param sourceId 源节点ID(路由起点)
* @param condition 多输出路由条件函数(可计算出多个路由结果)
* @param mappings 路由结果映射表(key=条件返回值, value=目标节点ID)
* @return 当前StateGraph实例,支持链式调用
* @throws GraphStateException 边ID非法、映射为空、或并行条件边重复时抛出
*/
public StateGraph addParallelConditionalEdges(String sourceId, AsyncMultiCommandAction condition, Map<String, String> mappings)
throws GraphStateException {
// 1. 合法性校验:禁止将 END(结束节点) 作为源节点,结束节点无法向外发起路由
if (Objects.equals(sourceId, END)) {
throw Errors.invalidEdgeIdentifier.exception(END);
}
// 2. 合法性校验:并行条件边的路由映射规则不能为空
if (mappings == null || mappings.isEmpty()) {
throw Errors.edgeMappingIsEmpty.exception(sourceId);
}
// 3. 创建【并行条件边】对象:封装 源节点ID + 多输出路由条件 + 映射规则
// EdgeCondition.multi 标记为并行条件路由(支持返回多个目标节点)
var newEdge = new Edge(sourceId, new EdgeValue(EdgeCondition.multi(condition, mappings)));
// 4. 唯一性校验:同一个源节点不允许重复添加并行条件边(避免路由冲突)
if (edges.elements.contains(newEdge)) {
throw Errors.duplicateConditionalEdgeError.exception(sourceId);
}
else {
// 5. 无重复则将并行条件边添加到图的边集合中
edges.elements.add(newEdge);
}
// 6. 返回当前对象,支持链式调用
return this;
}
2.4 OverAllState
State 是图计算中所有节点(Nodes)和边(Edges)共享的唯一数据源,存储计算过程中的所有中间结果、最终结果,是整个图的「数据中心」。
由两个强制部分组成:
Key:状态的唯一标识(字符串 / 枚举 / 自定义类型),定义了State能存储哪些数据KeyStrategy函数:冲突处理策略,当多个节点同时更新同一个Key时,决定多个值如何合并(覆盖 / 求和 / 取最大 / 自定义聚合)
Spring AI Alibaba 中使用 OverAllState 类表示表示图计算或工作流执行的全局状态。作为核心容器,OverAllState 用于持有和管理基于图的处理流水线中所有节点的共享数据。它支持键值对数据存储,且每个键均可配置自定义更新策略(KeyStrategy),实现灵活的数据合并与替换逻辑。该类支持序列化,适用于数据持久化、断点检查点保存以及跨节点通信场景。
核心特性:
- 数据管理:通过映射结构存储任意强类型数据。
- 键策略支持:为每个键绑定专属策略,控制新值与旧值的合并/更新规则。
- 恢复模式:支持恢复标记,用于标识当前状态是否用于恢复执行。
- 不可变视图:通过
data()和keyStrategies()提供数据与策略的只读不可修改视图。 - 快照功能:支持通过
snapShot()创建当前状态的快照。 - 人工反馈:支持在执行过程中集成人工反馈与执行中断消息。
构造方式:
- 无参构造器:自动注册默认输入键与替换策略。
- 带数据参数的构造器:基于已有的状态数据映射初始化实例。
- 带恢复标记的构造器:创建标记为「执行恢复」的状态实例。
- 全参构造器:支持对数据、策略、恢复状态进行完全自定义配置。
注意:该类非线程安全。若需并发访问,必须通过外部同步机制保证线程安全。
核心源码:
public final class OverAllState implements Serializable {
// 移除标记对象:用于标识对应键的值需要被删除
public static final Object MARK_FOR_REMOVAL = new Object();
/**
* 存储实际状态数据的内部映射集合。
* 所有状态值的获取、赋值操作均通过该集合执行。
*/
private final Map<String, Object> data;
/**
* 键与对应更新策略的映射集合。
* 决定每个键对应的值该如何合并或更新。
*/
private final Map<String, KeyStrategy> keyStrategies;
/**
* 存储实例:用于跨多次执行的长期记忆存储。
*/
private Store store;
/**
* 向状态中注入标准输入的默认键。
* 通常用于用户输入/外部输入初始化状态时使用。
*/
public static final String DEFAULT_INPUT_KEY = "input";
}
3.入门案例
3.1 简单顺序工作流
定义两个处理节点,按顺序执行数据处理,最终输出链式处理后的结果。
工作流执行流程:
START
↓
nodeA(读取input → 生成result_a)
↓
nodeB(读取result_a → 生成result_b)
↓
END
定义节点 A 的处理逻辑:
// 1. 定义节点A的处理逻辑:读取输入,生成结果a
NodeAction nodeA = state -> {
// 从全局状态中获取input字段,转为字符串,为空则默认空串
String input = state.value("input").map(Object::toString).orElse("");
// 返回新的键值对,更新全局状态
return Map.of("result_a", "处理A: " + input);
};
定义节点 B 的处理逻辑:
// 2. 定义节点B的处理逻辑:读取节点A的结果,生成结果b
NodeAction nodeB = state -> {
// 从全局状态中获取节点A生成的result_a
String resultA = state.value("result_a").map(Object::toString).orElse("");
// 返回新的键值对,继续更新全局状态
return Map.of("result_b", "处理B: " + resultA);
};
创建 StateGraph 实例:
// 3. 创建StateGraph实例:定义工作流名称 + 键冲突策略
StateGraph graph = new StateGraph("simple_workflow", () -> {
Map<String, KeyStrategy> strategies = new HashMap<>();
// 所有字段都使用【替换策略】:新值直接覆盖旧值
strategies.put("input", new ReplaceStrategy());
strategies.put("result_a", new ReplaceStrategy());
strategies.put("result_b", new ReplaceStrategy());
return strategies;
});
组装工作流:
// 4. 组装工作流:添加节点 + 定义执行路径(边)
graph.addNode("node_a", node_async(nodeA)) // 添加异步节点A
.addNode("node_b", node_async(nodeB)) // 添加异步节点B
.addEdge(START, "node_a") // 起始点 → 节点A
.addEdge("node_a", "node_b") // 节点A → 节点B
.addEdge("node_b", END); // 节点B → 结束
编译工作流 + 执行:
// 5. 编译工作流 + 执行
CompiledGraph compiled = graph.compile();
// 传入初始状态:input=Hello
Optional<OverAllState> result = compiled.invoke(Map.of("input", "Hello"));
// 打印最终的全局状态数据
System.out.println(result.get().data());
3.2 条件路由工作流
根据输入内容是否包含 urgent,自动选择「快速处理」或「标准处理」分支执行。
工作流执行流程:
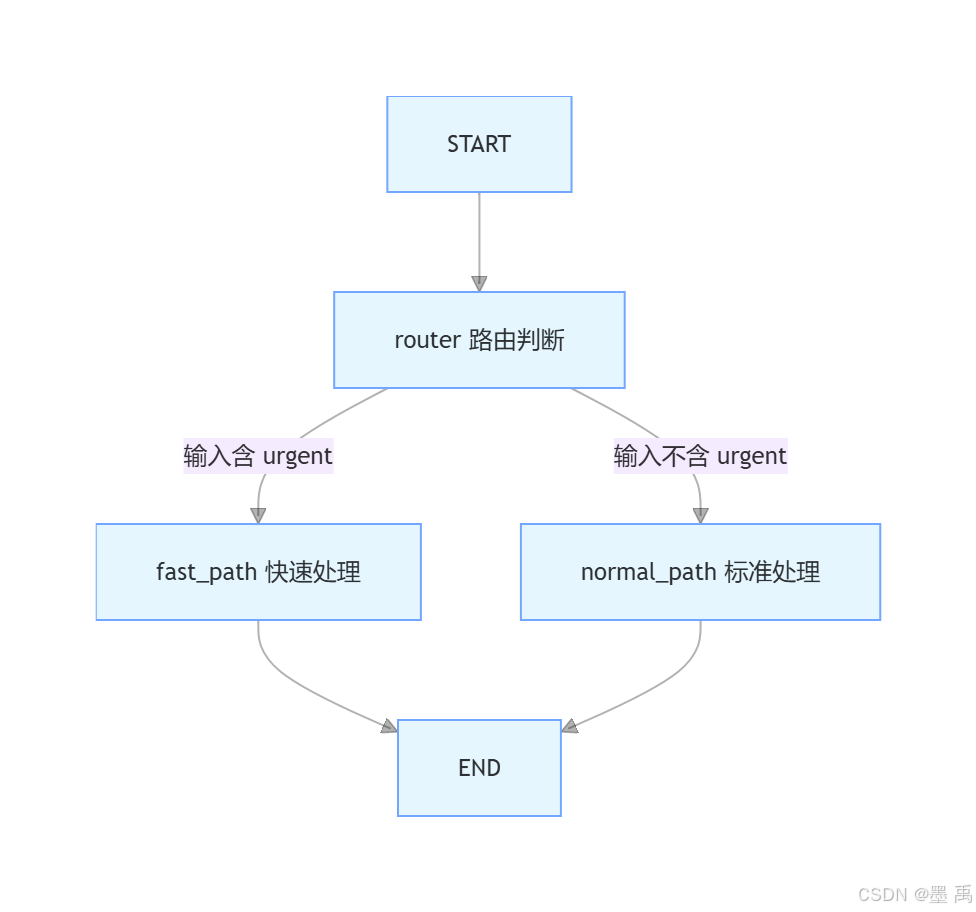
创建状态图:
// 1. 创建状态图:定义工作流名称 + 所有状态键的合并策略
StateGraph graph = new StateGraph("conditional_workflow", () -> {
Map<String, KeyStrategy> strategies = new HashMap<>();
// 所有键均使用【替换策略】:新值直接覆盖旧值
strategies.put("input", new ReplaceStrategy());
strategies.put("output", new ReplaceStrategy());
strategies.put("route_decision", new ReplaceStrategy());
return strategies;
});
路由节点:
// 2. 路由节点:核心逻辑 -> 根据输入判断走哪条分支
NodeAction routerNode = state -> {
// 从全局状态获取输入值
String input = state.value("input").map(Object::toString).orElse("");
// 判断逻辑:包含 urgent → 快速通道,否则 → 标准通道
String decision = input.contains("urgent") ? "fast_path" : "normal_path";
// 将决策结果存入全局状态(键:route_decision)
return Map.of("route_decision", decision);
};
条件边函数:
// 3. 条件边函数:读取路由决策,返回下一个要执行的节点名称
EdgeAction conditionFunc = state -> {
// 从状态中获取路由决策
String decision = state.value("route_decision").map(Object::toString).orElse("normal_path");
return decision; // 返回:fast_path / normal_path
};
组装工作流:
// 4. 组装状态图:节点 + 普通边 + 条件边
graph.addNode("router", node_async(routerNode)) // 路由节点
.addNode("fast_path", node_async(state -> Map.of("output", "快速处理"))) // 快速分支节点
.addNode("normal_path", node_async(state -> Map.of("output", "标准处理"))) // 标准分支节点
.addEdge(START, "router") // 起始点 → 路由节点
// 核心:给路由节点添加【条件边】
.addConditionalEdges("router", conditionFunc, Map.of(
"fast_path", "fast_path", // 决策=fast_path → 执行 fast_path 节点
"normal_path", "normal_path"// 决策=normal_path → 执行 normal_path 节点
))
.addEdge("fast_path", END) // 快速分支 → 结束
.addEdge("normal_path", END); // 标准分支 → 结束
编译并执行工作流:
// 5. 编译并执行工作流
CompiledGraph compiled = graph.compile();
// 输入包含 urgent → 走快速分支
compiled.invoke(Map.of("input", "urgent task"));
3.3 并行工作流
实现多分支并行执行 → 所有分支完成后自动汇聚 → 合并处理结果。
工作流执行流程:
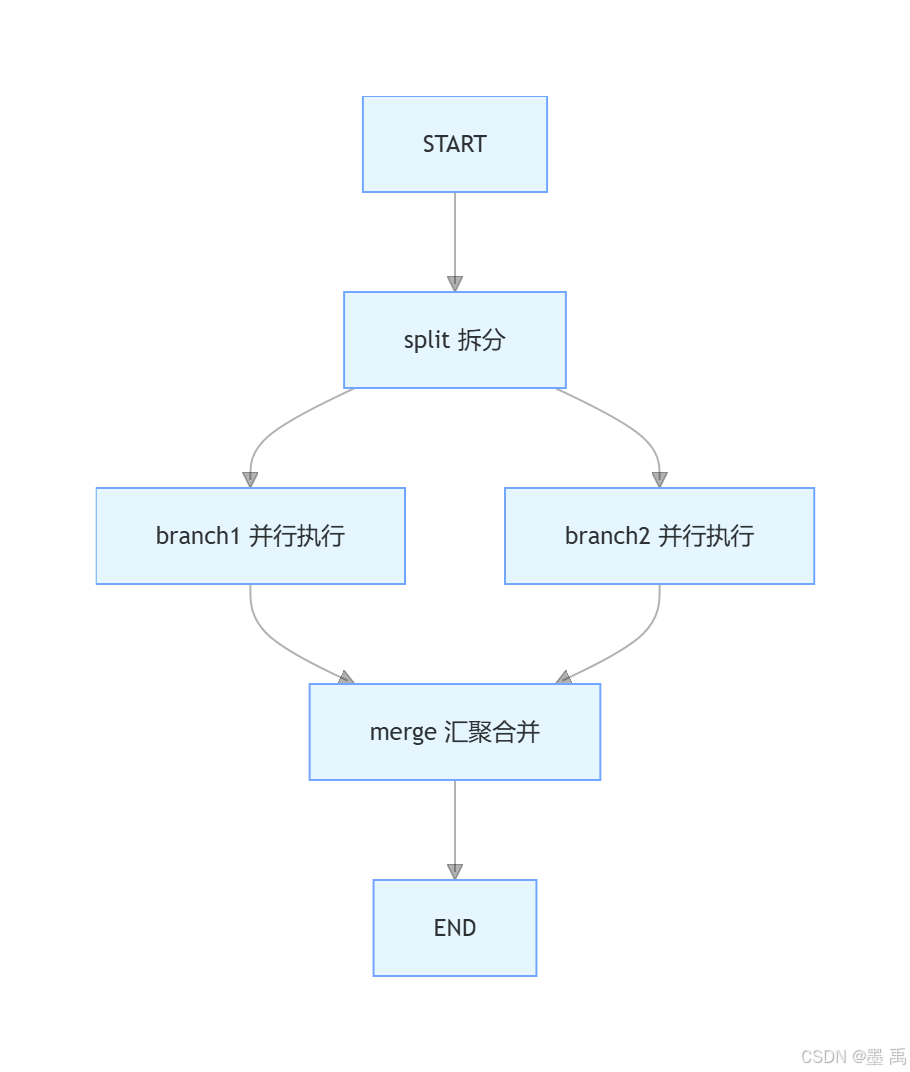
配置键策略:
// 1. 配置键策略工厂:定义全局数据合并规则
KeyStrategyFactory keyStrategyFactory = KeyStrategy.builder()
// 默认策略:新值覆盖旧值(REPLACE)
.defaultStrategy(KeyStrategy.REPLACE)
// 自定义策略:results 键使用追加策略(APPEND),并行结果会合并为列表
.addStrategy("results", KeyStrategy.APPEND)
.build();
构建并行工作流:
// 2. 构建并行工作流
StateGraph workflow = new StateGraph(keyStrategyFactory)
// 节点1:拆分节点(并行入口)
.addNode("split", node_async(state -> Map.of("step", "split")))
// 节点2:并行分支1(模拟耗时1秒的业务)
.addNode("branch1", node_async(state -> {
Thread.sleep(1000);
return Map.of("results", "result from branch 1");
}))
// 节点3:并行分支2(模拟耗时0.5秒的业务)
.addNode("branch2", node_async(state -> {
Thread.sleep(500);
return Map.of("results", "result from branch 2");
}))
// 节点4:汇聚节点(合并并行结果)
.addNode("merge", node_async(state -> {
// 获取追加后的结果列表
List<String> results = state.value("results", List.of());
// 拼接结果
return Map.of("merged", String.join(", ", results));
}))
// 3. 定义边:普通边 + 并行边 + 汇聚边
.addEdge(START, "split")
.addEdge("split", List.of("branch1", "branch2")) // 核心:拆分 → 并行执行两个分支
.addEdge(List.of("branch1", "branch2"), "merge") // 核心:两个分支都完成 → 汇聚到merge
.addEdge("merge", END);
编译工作流 + 运行:
// 4. 编译工作流
CompiledGraph app = workflow.compile();
// 5. 流式执行,收集所有执行过的节点
List<String> executedNodes = app.stream(Map.of())
.map(NodeOutput::node)
.collectList()
.block();
// 打印执行节点顺序
System.out.println("Executed nodes: " + executedNodes);
// 输出:[START, split, branch1, branch2, merge, END]
3.4 工作流可视化
3.4.1 Mermaid 图表
使用 StateGraph 内置的可视化能力,能自动生成工作流的 Mermaid 流程图文本:
GraphRepresentation mermaid = graph.getGraph(GraphRepresentation.Type.MERMAID);
System.out.println(mermaid.content());
输出示例:
flowchart TD
__START__((start))
__END__((stop))
split("split")
branch1("branch1")
branch2("branch2")
merge("merge")
__START__:::__START__ --> split:::split
split:::split --> branch1:::branch1
split:::split --> branch2:::branch2
branch1:::branch1 --> merge:::merge
branch2:::branch2 --> merge:::merge
merge:::merge --> __END__:::__END__
classDef __START__ fill:black,stroke-width:1px,font-size:xx-small;
classDef __END__ fill:black,stroke-width:1px,font-size:xx-small;
使用在线工具进行可视化:
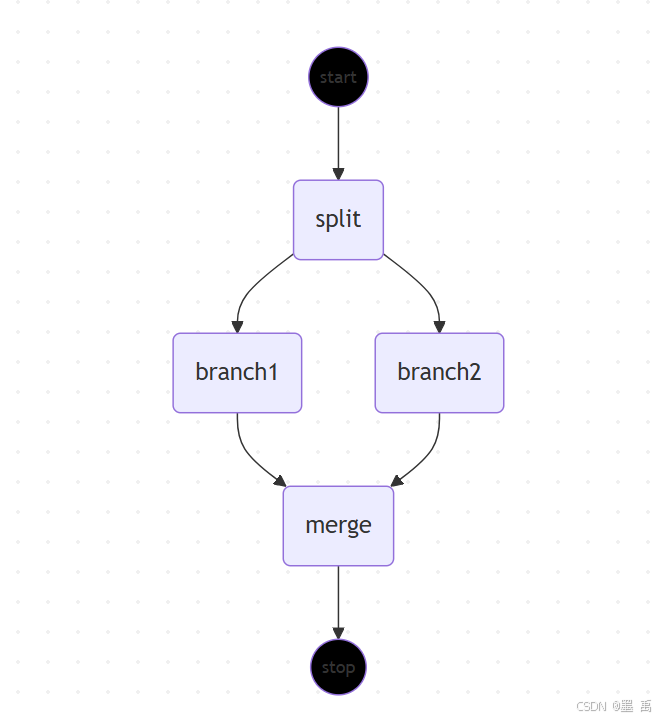
3.4.1 PlantUML 图表
使用 StateGraph 内置的可视化能力,能自动生成工作流的 PlantUML 流程图文本:
GraphRepresentation representation = graph.getGraph(GraphRepresentation.Type.PLANTUML);
System.out.println(representation.content());
输出示例:
@startuml unnamed
skinparam usecaseFontSize 14
skinparam usecaseStereotypeFontSize 12
skinparam hexagonFontSize 14
skinparam hexagonStereotypeFontSize 12
title "null"
footer
powered by spring-ai-alibaba
end footer
circle start<<input>> as __START__
circle stop as __END__
usecase "split"<<Node>>
usecase "branch1"<<Node>>
usecase "branch2"<<Node>>
usecase "merge"<<Node>>
"__START__" -down-> "split"
"split" -down-> "branch1"
"split" -down-> "branch2"
"branch1" -down-> "merge"
"branch2" -down-> "merge"
"merge" -down-> "__END__"
@enduml

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 10
10 0
0- 0



 已为社区贡献123条内容
已为社区贡献123条内容

所有评论(0)