从 SD1.5 到 FLUX:一文搞懂扩散模型数学本质、采样器演化与 Flow Matching 范式革命
本文系统梳理了生成式 AI 领域最核心也最容易混淆的技术概念,从 SD1.5 的 SDE/ODE 兼容性问题出发,逐层深入讲解马尔可夫链、随机微分方程、采样器原理、少步生成技术的本质,最终到 Flow Matching 的范式革命。所有核心结论均有原始学术论文支撑,文末附完整文献索引。

一、引言
自 2022 年 Stable Diffusion 1.5 发布以来,扩散模型彻底改变了生成式 AI 的格局。但随着技术的快速迭代,大量概念层出不穷,不禁让人发问:
- 为什么基于 SDE 训练的 SD1.5 可以用 ODE 求解器采样?
- DPM-Solver、Euler a 这些采样器到底在做什么?
- LCM、SDXL Turbo 是采样器吗?为什么它们能实现 1 步生成?
- Flow Matching 为什么能取代扩散模型成为下一代主流?
本文从最基础的数学原理出发,完整梳理从 DDPM 到 Flow Matching 的技术演化路线,澄清所有核心概念的本质区别。
二、核心问题:SD1.5 的 SDE 与 ODE 采样兼容性
我们从最经典的问题开始:SD1.5 明明是基于 SDE(随机微分方程)训练的,为什么可以用 DDIM、DPM-Solver 这些 ODE(常微分方程)求解器进行采样?
2.1 SD1.5 的数学本质
SD1.5 属于 **VP-SDE(方差保持随机微分方程)** 框架,其前向扩散过程可以用以下 SDE 描述:
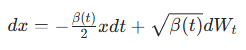
其中:
- β(t) 是随时间变化的噪声调度函数
- dWt 是标准布朗运动,代表随机噪声项
原始 DDPM 的祖先采样,本质上就是对这个逆 SDE 的一阶 Euler-Maruyama 数值求解,这也是早期 SD 需要 1000 步采样的根本原因。
2.2 概率流 ODE:SDE 的确定性等价
2021 年 Song 等人在 ICML 2021 的杰出论文中证明了一个决定性的数学定理:
对于任何扩散 SDE,都存在一个唯一的确定性 ODE,它在所有时间步t上都与 SDE 具有完全相同的边缘概率分布pt(x)。
这个 ODE 就叫做概率流 ODE(Probability Flow ODE),其公式为:![]()
对于 SD1.5 的 VP-SDE,代入漂移项![]() 和扩散项
和扩散项![]() ,得到:
,得到: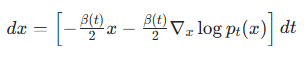
2.3 训练目标的通用性
SD1.5 的训练目标是预测噪声εθ(x,t),而分数函数与噪声预测之间存在严格的数学关系: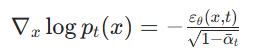
将其代入概率流 ODE 的公式,最终得到的更新规则正是 DDIM 在η=0时的更新公式。这意味着:同一个训练好的 UNet 模型,可以同时用于求解 SDE 和 ODE,不需要任何重新训练。
这就是 SD1.5 可以无缝切换各种 ODE 求解器的根本数学原因。
三、底层数学基石:从高斯分布到 SDE/ODE
所有生成模型的核心目标都是一致的:学习一个可逆变换,将简单的标准高斯分布N(0,1)映射到复杂的真实数据分布(如图片、视频)。不同模型的区别,仅在于实现这个映射的方式不同。
3.1 离散阶段:DDPM 的马尔可夫链框架
2020 年提出的 DDPM(Denoising Diffusion Probabilistic Models)是第一个实用的扩散模型,其数学基础是离散时间高斯马尔可夫链。
马尔可夫链的核心性质是马尔可夫性:系统的下一个状态只与当前状态有关,与更早的状态无关。这正是扩散模型 "一步一步加噪 / 去噪" 的理论依据。
DDPM 包含两个对称的过程:
- 前向过程(加噪):从真实图片x0开始,逐步加入高斯噪声,经过T步(通常 1000 步)后变成纯高斯噪声xT
- 反向过程(去噪):从纯高斯噪声xT开始,逐步预测并去除噪声,最终还原出真实图片x0
离散马尔可夫链的局限性非常明显:必须走满 1000 步,每一步只能去除一点点噪声,这导致早期扩散模型的采样速度极慢。
3.2 连续化:从马尔可夫链到 SDE
2021 年 Song 等人的里程碑工作将离散扩散过程连续化,证明了:当马尔可夫链的时间步长趋近于 0 时,离散的扩散过程就收敛为连续的随机微分方程(SDE)。
这一发现具有划时代的意义:
- 它将扩散模型与成熟的随机分析理论联系起来
- 它揭示了扩散模型与分数匹配模型的统一性
- 它为后续的采样加速技术奠定了数学基础
3.3 SDE 与 ODE 的本质区别
| 概念 | 数学本质 | 物理类比 | 生成结果特性 |
|---|---|---|---|
| ODE(常微分方程) | 描述确定性的运动,dtdx=f(x,t) | 行星的轨道 | 给定初始条件,结果唯一 |
| SDE(随机微分方程) | ODE + 随机项,dx=f(x,t)dt+g(t)dWt | 空气中的花粉颗粒 | 给定初始条件,结果是一个概率分布 |
四、传统采样器演化史:数值求解方法的优化
传统采样器的本质是:不改变模型权重,只改变数值积分算法,用不同的方法求解同一个 SDE 或 ODE。
同一个采样器可以用于任何同架构的 SD 模型,这是它与少步生成技术最核心的区别。采样器的演化史,就是人类不断寻找更高效的数值方法来求解扩散 SDE/ODE 的历史。
4.1 第一代:DDPM(2020)
- 本质:逆 SDE 的一阶 Euler-Maruyama 求解
- 步数:1000 步
- 特点:每步加入随机噪声,多样性好,但速度极慢
- 地位:所有采样器的基础
4.2 第二代:DDIM(2020 年底)
- 本质:概率流 ODE 的一阶离散化
- 步数:50-100 步
- 特点:完全确定性,相同种子结果一致,速度比 DDPM 快 10 倍
- 意义:第一次证明了 "不需要随机噪声也能采样",打开了加速的大门
4.3 第三代:通用 ODE 高阶求解器(2021-2022)
人们发现,既然扩散采样本质上是解 ODE,那么数学上所有成熟的 ODE 求解器都可以直接应用:
- Heun:二阶 ODE 求解器,比 DDIM 更精确,20-50 步
- DPM-Solver:专门为扩散 ODE 半线性结构设计的高阶指数积分器,10-20 步
- DPM-Solver++:优化了无分类器引导(CFG)下的稳定性,成为 SD1.5 时代的黄金标准
4.4 第四代:SDE 加速求解器(2022 至今)
ODE 采样虽然快,但多样性不如 SDE。于是人们又回到 SDE 框架,设计了更快的 SDE 求解器:
- Euler a:带祖先采样的一阶 Euler 求解器,加入少量噪声,平衡速度和多样性
- DPM++ 2M SDE:目前综合性能最好的采样器之一,10-20 步,兼顾速度、质量和多样性
4.5 传统采样器的物理极限
受限于扩散 ODE 本身的两个固有缺陷,传统采样器的步数很难少于 10 步:
- 向量场奇异性:扩散 ODE 在t=0附近梯度非常大,高阶求解器容易不稳定
- 轨迹弯曲:扩散过程的轨迹是一条指数曲线,需要更多步数才能准确求解
五、少步生成技术:向量场修改而非采样器
LCM、SDXL Turbo 绝对不是采样器,它们是模型本身的修改 / 蒸馏技术,改变了模型的权重和 ODE 的向量场。 这是行业内最普遍也最关键的认知误区。
5.1 本质区别对比
| 类别 | 传统采样器(DPM-Solver、Euler 等) | 少步生成技术(LCM、SDXL Turbo) |
|---|---|---|
| 修改对象 | 不改变模型权重,只改变数值积分算法 | 改变模型权重本身,修改 ODE 的向量场 |
| 数学本质 | 用不同的方法求解同一个 ODE | 训练一个全新的 ODE,让它天生就可以用极少步数求解 |
| 兼容性 | 同一个采样器可用于任何同架构 SD 模型 | 必须使用专门训练的 checkpoint,不能直接用于普通 SD 模型 |
| 速度上限 | 最少需要 10-20 步 | 理论上可以做到 1 步生成 |
直观类比:
- 传统采样器:同一个司机,用不同的驾驶技术走同一条盘山公路
- LCM/SDXL Turbo:直接炸掉盘山公路,重新修一条直达高速公路,然后训练一个新司机专门开这条高速路
5.2 一致性模型(CM):少步生成的理论基础
2023 年 Yang Song 等人提出的一致性模型,开创了少步生成的新范式。其核心思想是一致性函数:
对于扩散 ODE 的任意一条轨迹xT→xT−1→⋯→x0,存在一个函数fθ(xt,t),能将轨迹上的任意一点xt直接映射到这条轨迹的终点x0。
换句话说,一致性模型不需要按顺序一步步走,而是从任意一点直接瞄准终点。这就是它能跳步的根本原因。
5.3 潜在一致性模型(LCM)
LCM 将一致性模型扩展到潜在空间,实现了 SD1.5/SDXL 的 2-4 步高质量采样:
- 训练过程:以普通 SD 模型为教师,生成大量 ODE 轨迹,训练学生模型满足一致性约束
- 配套组件:LCM 调度器(采样器),专门用于配合修改后的模型权重
- 常见误区:将 LCM 调度器用在普通 SD 模型上只会得到垃圾结果
5.4 SDXL Turbo:1 步生成的实现
SDXL Turbo 基于 ** 对抗扩散蒸馏(ADD)** 技术,在 LCM 基础上解决了单步生成模糊的问题:
- 双损失函数:分数蒸馏采样(SDS)损失 + 对抗性(AD)损失
- 关键特性:不需要 CFG(guidance_scale 必须设为 0),必须使用特定的时间步间距
- 性能:1 步生成的质量已经接近普通 SDXL 20-30 步的水平
六、范式革命:Flow Matching 为什么取代扩散模型
2022 年底提出的 Flow Matching,是生成式建模领域的一次彻底的范式革命。它完全抛弃了扩散模型的 SDE 框架,从根本上解决了扩散模型的所有固有缺陷。
6.1 扩散模型的致命痛点
- 训练目标是下界:噪声预测目标是对数似然的一个下界,不是精确值,限制了模型的性能上限
- 向量场奇异性:如前所述,扩散 ODE 在t=0附近梯度极大
- 轨迹弯曲:指数曲线轨迹需要更多步数求解
- 数学复杂:涉及 SDE、伊藤积分等复杂数学,不利于理论研究和工程实现
6.2 Flow Matching 的核心思想
Flow Matching 不基于马尔可夫链或 SDE,而是直接学习一个从简单分布到数据分布的连续流。
想象一条河流:
- 上游是标准高斯分布(源头)
- 下游是复杂的真实数据分布(入海口)
- 河流中的每一滴水,都沿着一条平滑的轨迹从上游流到下游
Flow Matching 的目标就是学习这个河流的速度场(向量场),让所有水滴都能沿着正确的轨迹流动。
6.3 整流流(Rectified Flow):Flow Matching 的最优实现
整流流是一种特殊的 Flow Matching,它使用直线轨迹连接源分布和目标分布,进一步简化了训练和采样过程:
- 轨迹是直线,曲率为 0,高阶求解器极其有效
- 向量场处处平滑,没有奇异性
- 训练目标是精确的,不是下界
目前 SD3、FLUX 等最新的主流生成模型,全部基于整流流框架。
6.4 扩散模型 vs Flow Matching
| 特性 | 扩散模型 | Flow Matching(整流流) |
|---|---|---|
| 数学框架 | SDE + ODE | 纯 ODE |
| 训练目标 | 噪声预测(下界) | 向量场匹配(精确) |
| 向量场 | 奇异,t=0 附近梯度大 | 平滑,处处连续 |
| 采样轨迹 | 弯曲的指数曲线 | 直线 |
| 最少步数 | 10 步左右 | 1-4 步 |
| 理论复杂度 | 高 | 低 |
6.5 FLUX:基于 Rectified Flow 2 的新一代生成模型标杆
FLUX 是 Black Forest Labs 于 2024 年 8 月发布的开源文本到图像生成模型,它是Flow Matching 范式的集大成者,也是第一个在生成质量、速度、文本对齐能力上全面超越 SDXL 的开源模型。FLUX 完全抛弃了扩散模型的 SDE 框架,基于改进的 Rectified Flow 2 构建,标志着生成式 AI 正式从扩散时代进入纯 ODE 时代。
6.5.1 核心数学基础:Rectified Flow 2
FLUX 的底层数学框架是Rectified Flow 2,它是原始 Rectified Flow 的重大改进版本,解决了早期 Flow Matching 模型在分布匹配精度和轨迹直线性上的不足。
标题:Rectified Flow 2: Learning Straight Flows with Refined Transport作者:Xingchao Liu, Chengyue Gong, Qiang Liu发表信息:arXiv 预印本 arXiv:2310.05559 (2023)官方链接:https://arxiv.org/abs/2310.05559核心改进:
- 引入 ** 精炼传输(Refined Transport)** 技术,通过两阶段训练让生成轨迹更接近完美直线
- 提出流匹配损失的最优传输变体,提升了目标分布的匹配精度
- 证明了 Rectified Flow 2 的向量场比扩散模型和原始 Flow Matching 更平滑、更易于数值求解
6.5.2 架构创新:全 Transformer U-Net
FLUX 彻底抛弃了 SD 系列沿用多年的 "卷积 + Transformer" 混合架构,采用了纯 Transformer 的 U 型架构,这是它生成质量大幅提升的关键原因之一:
- 主干结构:由多个 Transformer 块组成 U 型网络,保留了跳跃连接以保留细粒度信息
- 双向交叉注意力:同时处理文本 token 和图像 token,实现了更精细的文本 - 图像对齐
- 并行注意力层:将自注意力和交叉注意力并行计算,大幅提升了训练和推理效率
- 改进的编码系统:使用 T5-v1.1-XXL 作为文本编码器,显著提升了对复杂提示词的理解能力;采用 16 倍下采样的 VAE,在保留图像细节的同时将潜在空间尺寸缩小了 4 倍,大幅降低了计算量
6.6.3 采样特性与性能表现
得益于 Rectified Flow 2 的完美直线轨迹和平滑向量场,FLUX 实现了前所未有的采样效率和质量:
- FLUX.1 [schnell]:专门为少步生成优化,4 步采样即可达到甚至超过 SDXL 50 步的生成质量,在 A100 GPU 上生成 1024×1024 图像仅需约 0.3 秒
- FLUX.1 [dev]:面向高质量生成的版本,20 步采样达到当前开源模型的最高水平,细节丰富度和文本对齐能力远超 SDXL
- 采样稳定性:不同步数之间的生成质量差异极小,不需要复杂的调度器调优;支持 CFG(无分类器引导),可以通过调整 guidance_scale 灵活平衡生成质量和多样性
6.5.4 技术意义
FLUX 的发布具有里程碑式的意义:
- 它第一次从实践上证明了纯 ODE 框架在所有维度上全面超越扩散模型,彻底终结了扩散模型在生成式 AI 领域的统治地位
- 它验证了全 Transformer 架构在图像生成任务上的优越性,为后续图像、视频、3D 等多模态生成模型指明了统一的架构方向
- 它将少步生成的质量提升到了实用水平,推动了实时生成式 AI 应用的普及
目前,FLUX 已经成为行业内的事实标准,后续的 Sora、CogVideo 3 等顶级视频生成模型,也都采用了基于 Rectified Flow 的纯 ODE 框架。
七、核心文献完整索引
所有核心结论均来自以下学术论文,按主题分类整理:
7.1 基础扩散模型框架
-
Deep Unsupervised Learning using Nonequilibrium Thermodynamics作者:Jascha Sohl-Dickstein 等发表:arXiv:1503.03585 (2015)链接:https://arxiv.org/abs/1503.03585贡献:扩散模型思想的首次提出
-
Denoising Diffusion Probabilistic Models作者:Jonathan Ho 等发表:NeurIPS 2020 (Oral)链接:https://arxiv.org/abs/2006.11239贡献:现代扩散模型的奠基之作
-
Denoising Diffusion Implicit Models作者:Jiaming Song 等发表:ICLR 2021 (Oral)链接:https://arxiv.org/abs/2010.02502贡献:首次提出确定性采样
7.2 连续扩散与 SDE/ODE 统一理论
- Score-Based Generative Modeling through Stochastic Differential Equations作者:Yang Song 等发表:ICML 2021 (杰出论文提名)链接:https://arxiv.org/abs/2011.13456贡献:SDE 与概率流 ODE 等价性证明
7.3 传统采样器
-
DPM-Solver: A Fast ODE Solver for Diffusion Probabilistic Model Sampling in Around 10 Steps作者:Cheng Lu 等发表:NeurIPS 2022 (Oral)链接:https://arxiv.org/abs/2206.00927代码:https://github.com/LuChengTHU/dpm-solver贡献:扩散模型专用高阶采样器
-
DPM-Solver++: Fast Solver for Guided Sampling of Diffusion Probabilistic Models作者:Cheng Lu 等发表:arXiv:2211.01095 (2022)链接:https://arxiv.org/abs/2211.01095贡献:引导采样优化
7.4 少步生成技术
-
Consistency Models作者:Yang Song 等发表:ICML 2023链接:https://arxiv.org/abs/2303.01469贡献:一致性模型框架
-
Latent Consistency Models: Synthesizing High-Resolution Images with Few-Step Inference作者:Simian Luo 等发表:arXiv:2310.04378 (2023)链接:https://arxiv.org/abs/2310.04378代码:https://github.com/luosiallen/latent-consistency-model贡献:潜在空间一致性模型
-
Adversarial Diffusion Distillation作者:Axel Sauer 等发表:ECCV 2024链接:https://arxiv.org/abs/2311.17042贡献:1 步高质量生成技术
7.5 Flow Matching 范式
-
Flow Matching for Generative Modeling作者:Yaron Lipman 等发表:ICLR 2023 (Oral)链接:https://arxiv.org/abs/2210.02747贡献:Flow Matching 原始框架
-
Rectified Flow: A Simple Approach to Flow-Based Generative Models作者:Xingchao Liu 等发表:arXiv:2209.03003 (2022)链接:https://arxiv.org/abs/2209.03003贡献:直线流生成范式,SD3、FLUX 的理论基础
八、总结
本文完整梳理了生成式建模从 DDPM 到 Flow Matching 的完整技术演化路线,澄清了行业内最容易混淆的三个核心概念:
- 采样器:求解 ODE/SDE 的数值计算工具,不改变模型权重,仅优化积分算法
- LCM:通过一致性蒸馏技术修改模型向量场,使普通扩散模型支持 2-4 步生成
- SDXL Turbo:在 LCM 基础上引入对抗扩散蒸馏,首次实现了实用级的 1 步生成
整个技术演化可以清晰地划分为三个逻辑递进的阶段:
-
第一阶段(2020-2023):扩散模型时代的数值求解优化在不改变模型架构和权重的前提下,通过不断改进 ODE/SDE 的数值求解方法,将采样步数从 DDPM 的 1000 步压缩到 10-20 步,最终达到了扩散模型传统采样器的物理极限。
-
第二阶段(2023-2024):扩散模型时代的向量场修改突破数值求解的局限,通过蒸馏技术直接修改模型的 ODE 向量场,让模型天生就适合极少步数求解,实现了 1-4 步甚至 1 步生成,将扩散模型的推理速度推向了极致。
-
第三阶段(2024 至今):Flow Matching 纯 ODE 时代以 FLUX 为代表的新一代模型彻底抛弃了扩散模型的 SDE 框架,基于 Rectified Flow 2 纯 ODE 范式构建,在生成质量、速度、文本对齐能力等所有维度上全面超越了扩散模型,标志着生成式 AI 正式进入纯 ODE 时代。
Flow Matching 不仅是一次数学框架的升级,更是一次彻底的范式革命。它从根本上解决了扩散模型训练目标不精确、向量场奇异、轨迹弯曲等固有缺陷,为生成式 AI 提供了更简洁、更稳定、更高效的理论基础。2024 年发布的 FLUX 作为 Flow Matching 范式的集大成者,第一次从实践上证明了纯 ODE 框架的优越性,成为了当前生成式 AI 领域的事实标准。未来的生成式 AI,无论是图像、视频、3D 还是多模态生成,都将基于 Flow Matching 及其衍生技术持续演进。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 12
12 0
0- 0



 已为社区贡献20条内容
已为社区贡献20条内容

所有评论(0)