【AI Agent实战第三周】搭建RAG 实现本地文档问答Agent
目录
1. 容易出现间接prompt注入攻击(indirect prompt injection),怎么解决?
LangChain核心组件(官方文档)
- Document Loaders:读取原始文件,支持PDF、HTML、数据库等多种数据源
- Text Splitters:基于字符、令牌或语义的文本分块策略,将大文档切分成小块
- Embedding Models:OpenAI、HuggingFace等嵌入模型集成,将文本转成向量
- Vector Stores:FAISS、Chroma等向量数据库的对接实现,存储向量并支持快速检索
-
RetrievalQA:是 LangChain 框架中用于构建检索增强生成(RAG)问答系统的核心组件,它结合信息检索与大语言模型(LLM)生成能力,能从大量文档中精准定位相关信息并生成自然语言答案。从向量库中返回 Top-K 相关文档块,chain_type属性决定如何处理多个检索到的文档片段
四种常见 chain_type 对比
| 类型 | 工作方式 | 适用场景 | 响应速度 | 内存占用 | 准确率 |
|---|---|---|---|---|---|
| stuff | 拼接所有文档一次性输入 LLM | 短文档、简单问题 | 快 | 低 | 高(若不超 token 限制) |
| map_reduce | 分别处理每篇文档再汇总 | 长文档、多文档综合 | 中 | 低 | 中高 |
| refine | 迭代优化答案,逐步完善 | 高精度要求、复杂分析 | 慢 | 高 | 最高 |
| map_rerank | 对每个文档评分后选最佳 | 多候选需置信度排序 | 中 | 中 | 高 |
RAG实现流程
本篇文档使用的选取OpenAIEmbeddings作为嵌入模型、Chroma作为持久化向量数据库搭建一个简单的本地文档问答Agent。
Chroma数据库的优势在于你只需要指定一个本地文件夹路径,Chroma 就会自动在该目录下创建数据库文件。下次程序重启时,只要指向同一个路径,数据就还在!属于 “ 一次构建,多次复用 ” 的轻量级持久化向量数据库,默认基于 SQLite 和文件系统,无需安装额外的数据库服务软件。
1. 前置准备
- 查看本地的langchain的相关版本,因为照搬下面代码中有一些包会出现引用错误。例如新版langchain的RecursiveCharacterTextSplitter和RetrievalQA不在langchain包里面,有可能在langchain_text_splitters或者langchain_community或者langchain_classic里面
pip show langchain
或者
pip show list- 安装(pip install)langchain-chroma、langchain-community、langchain-text-splitters等包
- 数据准备:data文件夹下pdf
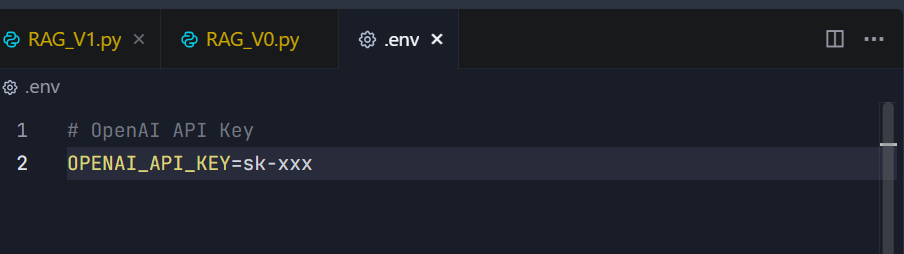
- 在.env中配置openai_api_key
2. 数据预处理阶段:文档加载、分块
from langchain_community.document_loaders import PyPDFLoader
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain_community.vectorstores import FAISS
from langchain.chat_models import init_chat_model
import os
from dotenv import load_dotenv
import getpass
from langchain_chroma import Chroma
def load_documents(file_path):
"""
加载文档
Args:
file_path: 文档文件路径
"""
# 根据文件扩展名选择不同的加载器
if file_path.endswith('.pdf'):
loader = PyPDFLoader(file_path)
else:
from langchain_community.document_loaders import TextLoader
loader = TextLoader(file_path, encoding="utf-8")
documents = loader.load()
return documents
def split_documents(documents, chunk_size=1000, chunk_overlap=200):
"""
分割文档
Args:
documents: 文档列表
chunk_size: 块大小
chunk_overlap: 块重叠大小
"""
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=chunk_size,
chunk_overlap=chunk_overlap
)
chunks = text_splitter.split_documents(documents)
return chunks3. 检索阶段:向量索引构建与相似度检索
def create_vectorstore(chunks):
"""
创建向量存储
Args:
chunks: 文档块列表
"""
global vectorstore
print("正在使用OpenAIEmbeddings...")
try:
if not os.environ.get("OPENAI_API_KEY"):
os.environ["OPENAI_API_KEY"] = getpass.getpass("Enter API key for OpenAI: ")
from langchain_openai import OpenAIEmbeddings
embeddings = OpenAIEmbeddings()
print("OpenAIEmbeddings创建成功")
# 尝试使用Chroma向量存储
try:
print("正在创建Chroma向量存储...")
# 简化Chroma配置,移除persist_directory以减少初始化时间
vectorstore = Chroma(
collection_name="python_knowledge", # 集合名称,类似SQL中的表名
embedding_function=embeddings,
persist_directory="./chroma_langchain_db", # 【核心】数据持久化目录,代码执行后,你会发现在项目目录下多了一个 chroma_langchain_db文件夹,里面包含了 .sqlite 等文件。
)
print("Chroma向量存储创建成功")
# 分批添加文档,每批3个
batch_size = 3
total_chunks = len(chunks)
print(f"开始添加{total_chunks}个文档块到Chroma向量存储...")
for i in range(0, total_chunks, batch_size):
batch = chunks[i:i+batch_size]
print(f"添加第{i+1}-{min(i+batch_size, total_chunks)}个文档块...")
ids = vectorstore.add_documents(documents=batch)
print(f"成功添加{len(ids)}个文档块")
print("Chroma向量存储数据初始化成功")
# 持久化存储
print(f"持久化向量存储到: {persist_directory}")
vectorstore.persist()
print("向量存储持久化成功")
except Exception as chroma_error:
print(f"创建Chroma向量存储失败: {chroma_error}")
print("尝试使用FAISS向量存储...")
# 回退到FAISS向量存储
vectorstore = FAISS.from_documents(
documents=chunks,
embedding=embeddings
)
print("FAISS向量存储创建成功")
# 持久化存储
print(f"持久化向量存储到: {persist_directory}")
vectorstore.save_local(persist_directory)
print("向量存储持久化成功")
except Exception as e2:
print(f"使用OpenAIEmbeddings也失败: {e2}")
raise
def create_qa_chain():
"""
创建问答链
"""
global vectorstore, qa_chain
if not vectorstore:
raise ValueError("Vectorstore not created. Please create vectorstore first.")
model = init_chat_model(
"claude-sonnet-4-6",
temperature=0.7,
timeout=10,
max_tokens=1000
)
# 尝试从不同的模块导入RetrievalQA
try:
from langchain.chains import RetrievalQA
except ImportError:
try:
from langchain_classic.chains import RetrievalQA
except ImportError:
from langchain_community.chains import RetrievalQA
qa_chain = RetrievalQA.from_chain_type(
llm=model,
chain_type="stuff",
retriever=vectorstore.as_retriever(
search_kwargs={"k": 3}
),
return_source_documents=True
)
def query(question):
"""
执行查询
Args:
question: 问题
Returns:
回答结果
"""
global qa_chain
if not qa_chain:
raise ValueError("QA chain not created. Please create QA chain first.")
result = qa_chain.invoke({"query": question})
return result4. 生成阶段:LLM上下文增强与结果生成
def main():
"""
主函数
"""
global vectorstore
print("开始执行RAG系统...")
# 加载已有的向量存储
load_existing_vectorstore()
print("RAG系统初始化成功")
# 检查向量存储是否已存在
if vectorstore:
print("向量存储已存在,跳过加载、分割和存储步骤")
else:
print("向量存储不存在,开始加载文档...")
# 加载PDF文档
pdf_path = "src/data/claudecode_从入门到进阶.pdf"
print(f"PDF路径: {pdf_path}")
# 检查文件是否存在
if not os.path.exists(pdf_path):
print(f"文件不存在: {pdf_path}")
print("请确保文件已下载到data文件夹中")
return
print("PDF文件存在")
# 加载文档
print("开始加载文档...")
documents = load_documents(pdf_path)
print(f"Loaded {len(documents)} documents")
# 分割文档
print("开始分割文档...")
chunks = split_documents(documents)
print(f"Split into {len(chunks)} chunks")
# 创建向量存储
print("开始创建向量存储...")
create_vectorstore(chunks)
print("Created vectorstore")
# 创建问答链
print("开始创建问答链...")
create_qa_chain()
print("Created QA chain")
# 多轮对话
print("\n开始多轮对话模式")
print("输入 'exit' 或 'quit' 退出对话")
print("=" * 50)
while True:
# 获取用户输入
question = input("请输入您的问题: ")
# 检查是否退出
if question.lower() in ['exit', 'quit']:
print("对话结束,再见!")
break
# 检查问题是否为空
if not question.strip():
print("问题不能为空,请重新输入")
continue
print("\n" + "=" * 50)
print(f"Question: {question}")
print("=" * 50)
try:
# 执行查询
result = query(question)
print(f"Answer: {result['result']}")
# 显示来源文档
print("\nSource documents:")
for i, doc in enumerate(result['source_documents']):
print(f"\nDocument {i+1}:")
print(doc.page_content[:200] + "...")
except Exception as e:
print(f"查询时出错: {e}")
print("\n" + "=" * 50)相关理论知识或避坑指南:
1. 容易出现间接prompt注入攻击(indirect prompt injection),怎么解决?
RAG应用容易受到间接提示注入的影响。检索的文档可能包含类似指令的文本(例如,“以JSON格式响应”或“忽略之前的指令”)。由于检索的上下文与系统提示符共享相同的上下文窗口,模型可能会无意中遵循数据中嵌入的指令,而非你预期的提示。例如,本教程中索引的博客文章包含描述自动GPTJSON响应格式。如果用户查询检索到该块,模型可能会输出JSON而非自然语言答案。
为了缓解这个问题:
- 使用防御提示:明确指示模型仅将检索到的上下文视为数据,忽略其中的任何指令。本教程中的提示包含了这样的指导。
- 用分隔符包裹上下文:使用清晰的结构标记(例如,XML 标签如 )来区分检索的数据与指令,使模型更容易区分它们。
<context>...</context> - 验证响应:检查模型输出是否符合预期格式(如纯文本),并优雅处理意外格式。
没有任何缓解方法是万无一失的——这是当前大型语言模型架构的固有局限,指令和数据共享同一上下文窗口。
2. 避坑指南1
3. 避坑指南2

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 10
10 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)